
 Technology peripherals
AI
Beyond BEVFusion! DifFUSER: Diffusion model enters autonomous driving multi-task (BEV segmentation + detection dual SOTA)
Technology peripherals
AI
Beyond BEVFusion! DifFUSER: Diffusion model enters autonomous driving multi-task (BEV segmentation + detection dual SOTA)
Beyond BEVFusion! DifFUSER: Diffusion model enters autonomous driving multi-task (BEV segmentation + detection dual SOTA)

Written in front&The author’s personal understanding
Currently, as autonomous driving technology becomes more mature and the demand for autonomous driving perception tasks increases, the industrial and academic circles The industry very much hopes for an ideal perception algorithm model that can simultaneously complete three-dimensional target detection and semantic segmentation tasks based on BEV space. For a vehicle capable of autonomous driving, it is usually equipped with surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect data in different modalities. This makes full use of the complementary advantages between different modal data, making the data complementary advantages between different modalities. For example, 3D point cloud data can provide information for 3D target detection tasks, while color image data can provide more information for semantic segmentation tasks. accurate information. In view of the complementary advantages between different modal data, by converting the effective information of different modal data into the same coordinate system, subsequent joint processing and decision-making are facilitated. For example, 3D point cloud data can be converted into point cloud data based on BEV space, and image data from surround-view cameras can be projected into 3D space through the calibration of internal and external parameters of the camera, thereby achieving unified processing of different modal data. By taking advantage of different modal data, more accurate perception results can be obtained than single modal data. Now, we can already deploy the multi-modal perception algorithm model on the car to output more robust and accurate spatial perception results. Through accurate spatial perception results, we can provide more reliable and safe guarantee for the realization of autonomous driving functions.
Although many 3D perception algorithms for multi-sensory and multi-modal data fusion based on the Transformer network framework have recently been proposed in academia and industry, they all use the cross-attention mechanism in Transformer to achieve multi-sensory and multi-modal data fusion. Fusion between modal data to achieve ideal 3D target detection results. However, this type of multi-modal feature fusion method is not completely suitable for semantic segmentation tasks based on BEV space. In addition, in addition to using the cross-attention mechanism to complete information fusion between different modalities, many algorithms use forward vector conversion in LSA to construct fused features, but there are also some problems as follows: (Limitations word count, detailed description follows).
- Due to the currently proposed 3D sensing algorithm related to multi-modal fusion, the design of the fusion method of different modal data features is not sufficient, resulting in the perception algorithm model being unable to accurately capture the relationship between sensor data complex connection relationships, thereby affecting the final perceptual performance of the model.
- In the process of collecting data from different sensors, irrelevant noise information will inevitably be introduced. This inherent noise between different modalities will also cause noise to be mixed into the process of fusion of different modal features, resulting in multiple Inaccurate modal feature fusion affects subsequent perception tasks.
In view of the many problems mentioned above in the multi-modal fusion process that may affect the perception ability of the final model, and taking into account the powerful performance recently demonstrated by the generative model, we have The model is explored for multi-modal fusion and denoising tasks between multiple sensors. Based on this, we propose a generative model perception algorithm DifFUSER based on conditional diffusion to implement multi-modal perception tasks. As can be seen from the figure below, the DifFUSER multi-modal data fusion algorithm we proposed can achieve a more effective multi-modal fusion process.  The DifFUSER multimodal data fusion algorithm can achieve a more effective multimodal fusion process. The method mainly includes two stages. First, we use generative models to denoise and enhance the input data, generating clean and rich multimodal data. Then, the data generated by the generative model is used for multi-modal fusion to achieve better perception effects. The experimental results of the DifFUSER algorithm show that the multi-modal data fusion algorithm we proposed can achieve a more effective multi-modal fusion process. When implementing multi-modal perception tasks, this algorithm can achieve a more effective multi-modal fusion process and improve the model's perception capabilities. In addition, the algorithm's multi-modal data fusion algorithm can achieve a more efficient multi-modal fusion process. In summary
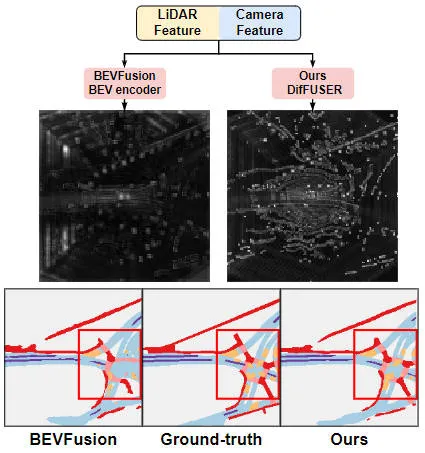
Visual comparison chart of the results of the proposed algorithm model and other algorithm models
Paper link: https://arxiv.org/pdf/2404.04629. pdf
Overall architecture & details of the network model
"Module details of the DifFUSER algorithm, a multi-task perception algorithm based on the conditional diffusion model" is a method used to solve Algorithms for task-aware problems. The figure below shows the overall network structure of our proposed DifFUSER algorithm. In this module, we propose a multi-task perception algorithm based on the conditional diffusion model to solve the task perception problem. The goal of this algorithm is to improve the performance of multi-task learning by spreading and aggregating task-specific information in the network. The integer of DifFUSER algorithm
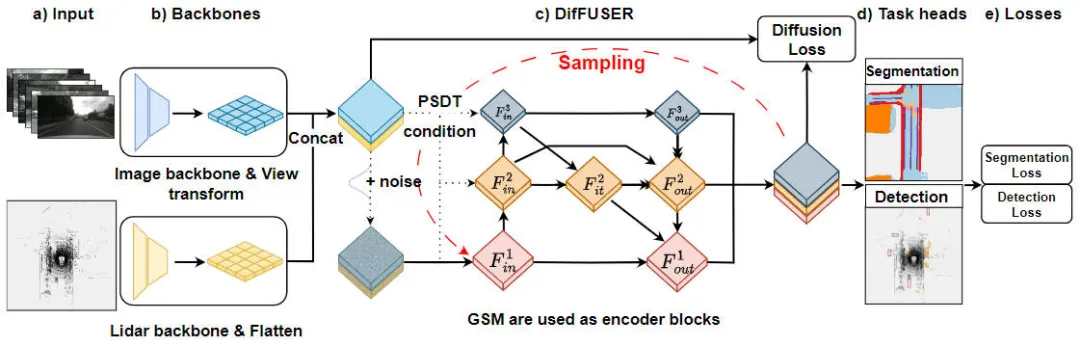 Proposed DifFUSER perception algorithm model network structure diagram
Proposed DifFUSER perception algorithm model network structure diagram
As can be seen from the above figure, the DifFUSER network structure we proposed mainly includes three sub-networks, namely the backbone network part and DifFUSER's multi-mode The state data fusion part and the final BEV semantic segmentation task head part. Head part of the 3D object detection perception task. In the backbone network part, we use existing deep learning network architectures, such as ResNet or VGG, to extract high-level features of the input data. The multi-modal data fusion part of DifFUSER uses multiple parallel branches, each branch is used to process different sensor data types (such as images, lidar and radar, etc.). Each branch has its own backbone network part
- : This part mainly extracts features from the 2D image data input to the network model and the 3D lidar point cloud data for output. Corresponding BEV semantic features. For the backbone network that extracts image features, it mainly includes a 2D image backbone network and a perspective conversion module. For the backbone network that extracts 3D lidar point cloud features, it mainly includes the 3D point cloud backbone network and the feature Flatten module.
- DifFUSER multi-modal data fusion part: The DifFUSER modules we proposed are linked together in the form of a hierarchical bidirectional feature pyramid network. We call this structure cMini-BiFPN. This structure provides an alternative structure to potential diffusion and can better handle the multi-scale and width-height detailed feature information from different sensor data.
- BEV semantic segmentation, 3D target detection perception task header part: Since our algorithm model can simultaneously output 3D target detection results and semantic segmentation results in BEV space, the 3D perception task header includes 3D detection head and semantic segmentation head. In addition, the losses involved in the algorithm model we proposed include diffusion loss, detection loss and semantic segmentation loss. By summing all losses, the parameters of the network model are updated through backpropagation.
Fusion architecture design (Conditional-Mini-BiFPN, cMini-BiFPN)
For the perception tasks in the autonomous driving system, the algorithm model can analyze the current external Real-time perception of the environment is crucial, so ensuring the performance and efficiency of the diffusion module is very important. Therefore, we are inspired by the bidirectional feature pyramid network and introduce a BiFPN diffusion architecture with similar conditions, which we call Conditional-Mini-BiFPN. Its specific network structure is shown in the figure above.

Progressive Sensor Dropout Training (PSDT)
For an autonomous car In other words, the performance of the autonomous driving acquisition sensors is very important. During the daily driving of autonomous vehicles, it is very likely that the camera sensor or lidar sensor will be blocked or malfunctioned, thus affecting the safety of the final autonomous driving system. performance and operational efficiency. Based on this consideration, we proposed a progressive sensor dropout training paradigm to enhance the robustness and adaptability of the proposed algorithm model in situations where the sensor may be blocked. Through the progressive sensor dropout training paradigm we proposed, the algorithm model can reconstruct the missing features by using the distribution of two modal data collected by the camera sensor and the lidar sensor, thereby achieving the best performance in harsh conditions. Excellent adaptability and robustness. Specifically, we exploit features from image data and lidar point cloud data in three different ways, as training targets, noise input to the diffusion module, and to simulate conditions in which a sensor is lost or malfunctioned. To simulate sensor Loss or failure conditions, we gradually increase the loss rate of camera sensor or lidar sensor input from 0 to a predefined maximum value a = 25 during training. The entire process can be expressed by the following formula: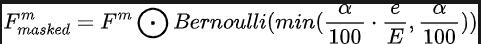
Among them, represents the number of training rounds in which the current model is in, and defines the probability of dropout to represent the probability that each feature in the feature is dropped. Through this progressive training process, the model is not only trained to effectively denoise and generate more expressive features, but also minimizes its dependence on any single sensor, thereby enhancing its handling of incomplete sensors with greater resilience. Data capabilities.
Gated Self-Conditioned Modulation Diffusion Module (GSM Diffusion Module)

Specifically, Gated Self-Conditioned Modulation Diffusion Module The network structure is shown in the figure below
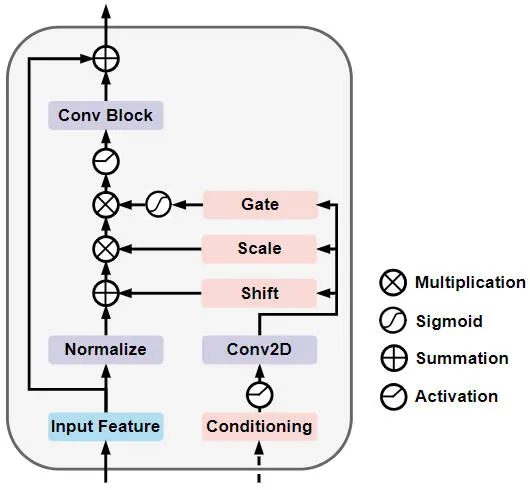
Schematic diagram of the network structure of the gated self-conditional modulation diffusion module

Experimental results & evaluation indicators
Quantitative analysis part
In order to verify the perceptual results of our proposed algorithm model DifFUSER on multi-tasks, we mainly used nuScenes data 3D target detection and semantic segmentation experiments based on BEV space were conducted on the set.
First, we compared the performance of the proposed algorithm model DifFUSER with other multi-modal fusion algorithms on semantic segmentation tasks. The specific experimental results are shown in the following table:
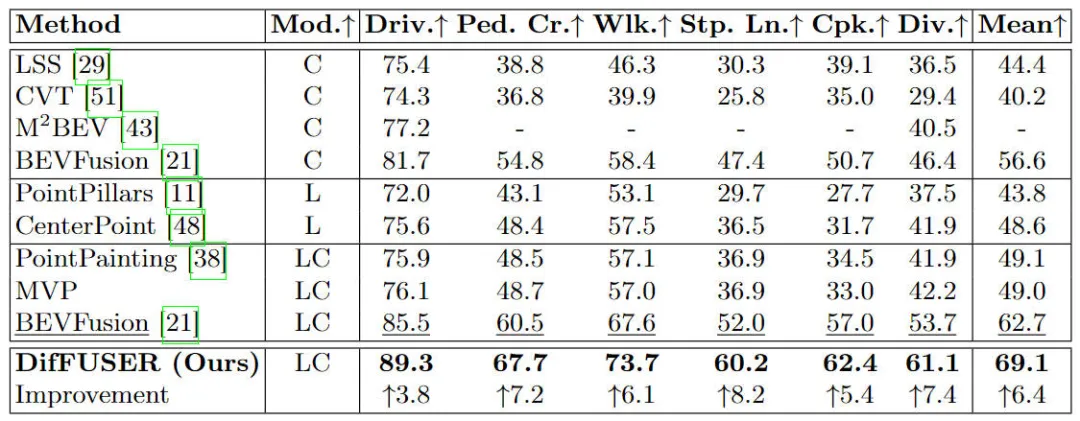 Comparison of experimental results of different algorithm models on the BEV space-based semantic segmentation task on the nuScenes dataset
Comparison of experimental results of different algorithm models on the BEV space-based semantic segmentation task on the nuScenes dataset
It can be seen from the experimental results that the algorithm model we proposed has better performance than the baseline model. There has been a significant improvement. Specifically, the mIoU value of the BEVFusion model is only 62.7%, while the algorithm model we proposed has reached 69.1%, with an improvement of 6.4% points, which shows that the algorithm we proposed has more advantages in different categories. In addition, the figure below also more intuitively illustrates the advantages of the algorithm model we proposed. Specifically, the BEVFusion algorithm will output poor segmentation results, especially in long-distance scenarios, where sensor misalignment is more obvious. In comparison, our algorithm model has more accurate segmentation results, with more obvious details and less noise.
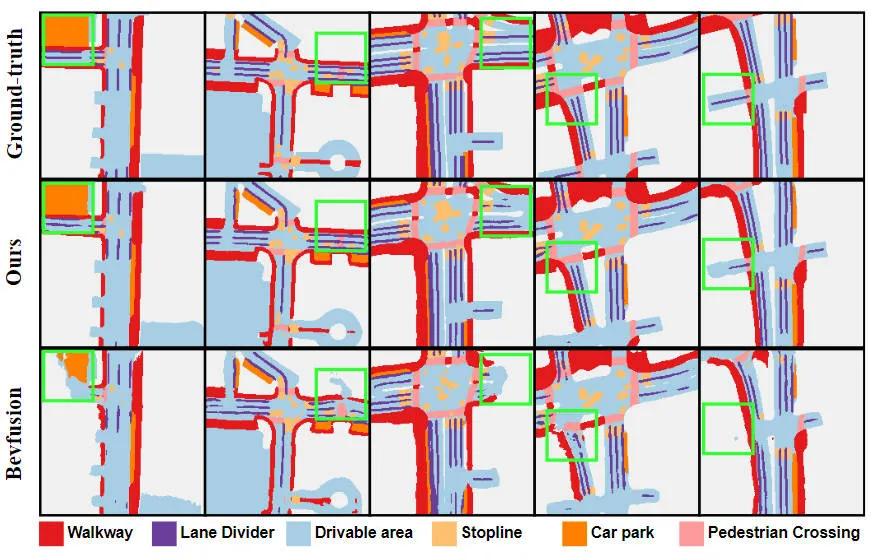
Comparison of segmentation visualization results between the proposed algorithm model and the baseline model
In addition, we will also compare the proposed algorithm model with other 3D target detection algorithm models For comparison, the specific experimental results are shown in the table below
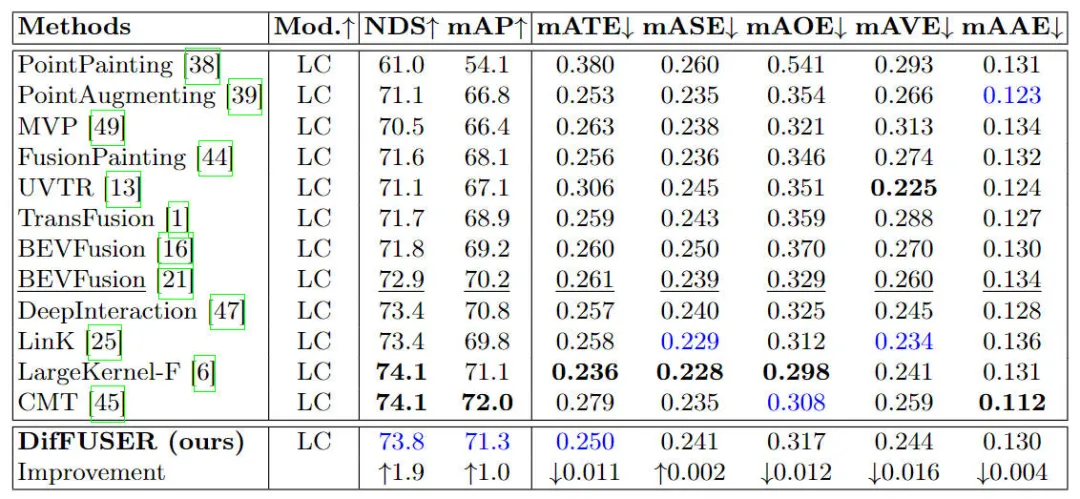
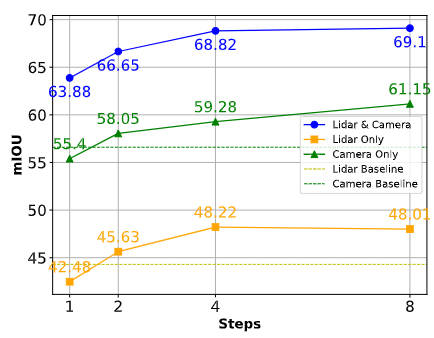
Qualitative analysis part
The following figure shows the visualization of the 3D target detection and semantic segmentation results of the BEV space of our proposed DifFUSER algorithm model. It can be seen from the visualization results that we The proposed algorithm model has good detection and segmentation effects.

Conclusion
This paper proposes a multi-modal perception algorithm model DifFUSER based on the diffusion model, by improving the fusion of network models architecture and utilize the denoising properties of the diffusion model to improve the fusion quality of the network model. The experimental results on the Nuscenes data set show that the algorithm model we proposed achieves SOTA segmentation performance in the semantic segmentation task of BEV space, and can achieve detection performance similar to the current SOTA algorithm model in the 3D target detection task.
The above is the detailed content of Beyond BEVFusion! DifFUSER: Diffusion model enters autonomous driving multi-task (BEV segmentation + detection dual SOTA). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1243
24
14
1423
52
1317
25
1268
29
1243
24

 A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion can not only imitate better, but also "create". The diffusion model (DiffusionModel) is an image generation model. Compared with the well-known algorithms such as GAN and VAE in the field of AI, the diffusion model takes a different approach. Its main idea is a process of first adding noise to the image and then gradually denoising it. How to denoise and restore the original image is the core part of the algorithm. The final algorithm is able to generate an image from a random noisy image. In recent years, the phenomenal growth of generative AI has enabled many exciting applications in text-to-image generation, video generation, and more. The basic principle behind these generative tools is the concept of diffusion, a special sampling mechanism that overcomes the limitations of previous methods.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 How to speed up BitGenie_How to speed up BitGenie download speed
Apr 29, 2024 pm 02:58 PM
How to speed up BitGenie_How to speed up BitGenie download speed
Apr 29, 2024 pm 02:58 PM
1. First of all, make sure that your BT seeds are healthy, have enough seeds, and are popular enough, so that they meet the prerequisites for BT downloading and the speed is fast. Open the "Select" column of your own BitComet, click "Network Connection" in the first column, and adjust the global maximum download speed to 1000 without limit (1000 for users below 2M is an unreachable number, but it is okay not to adjust this, who doesn't want to download it) Very fast). The maximum upload speed can be adjusted to 40 without any limit (choose appropriately based on personal circumstances, the computer will freeze if the speed is too fast). 3. Click Task Settings. You can adjust the default download directory inside. 4. Click Interface Appearance. Change the maximum number of displayed peers to 1000, which is to display the details of the users connected to you, so that you have peace of mind. 5. Click
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 How to use netsh command in win7
Apr 09, 2024 am 10:03 AM
How to use netsh command in win7
Apr 09, 2024 am 10:03 AM
The netsh command is used to manage networks in Windows 7 and is able to do the following: View network information Configure TCP/IP settings Manage wireless networks Set up network proxies
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
A purely visual annotation solution mainly uses vision plus some data from GPS, IMU and wheel speed sensors for dynamic annotation. Of course, for mass production scenarios, it doesn’t have to be pure vision. Some mass-produced vehicles will have sensors like solid-state radar (AT128). If we create a data closed loop from the perspective of mass production and use all these sensors, we can effectively solve the problem of labeling dynamic objects. But there is no solid-state radar in our plan. Therefore, we will introduce this most common mass production labeling solution. The core of a purely visual annotation solution lies in high-precision pose reconstruction. We use the pose reconstruction scheme of Structure from Motion (SFM) to ensure reconstruction accuracy. But pass
