
 Technology peripherals
AI
Beyond BEVFormer! CR3DT: RV fusion helps 3D detection & tracking of new SOTA (ETH)
Technology peripherals
AI
Beyond BEVFormer! CR3DT: RV fusion helps 3D detection & tracking of new SOTA (ETH)
Beyond BEVFormer! CR3DT: RV fusion helps 3D detection & tracking of new SOTA (ETH)

Written in front&The author’s personal understanding
This article introduces a camera-millimeter wave radar fusion method (CR3DT) for 3D target detection and multi-target tracking ). The lidar-based method has set a high standard for this field, but its high computing power and high cost have restricted the development of this solution in the field of autonomous driving; camera-based 3D target detection and tracking solutions are due to their high cost It is relatively low and has attracted the attention of many scholars, but due to its poor results. Therefore, the fusion of cameras and millimeter wave radar is becoming a promising solution. Under the existing camera framework BEVDet, the author fuses the spatial and velocity information of millimeter wave radar and combines it with the CC-3DT tracking head to significantly improve the accuracy of 3D target detection and tracking and neutralize the contradiction between performance and cost.
Main contribution
Sensor fusion architecture The CR3DT proposed uses intermediate fusion technology before and after the BEV encoder. Integrate millimeter wave radar data; for tracking, a quasi-dense appearance embedding head is used, using millimeter wave radar speed estimation for target association.
Detection Performance Evaluation CR3DT achieved 35.1% mAP and 45.6% nuScenes Detection Score (NDS) on the nuScenes 3D detection validation set. Taking advantage of the rich velocity information contained in radar data, the detector's mean velocity error (mAVE) is reduced by 45.3% compared to SOTA camera detectors.
Tracking performance evaluation CR3DT’s tracking performance on the nuScenes tracking validation set is 38.1% AMOTA, which is an improvement in AMOTA compared to the SOTA tracking model using only cameras 14.9%, the explicit use and further improvements of velocity information in the tracker significantly reduced the number of IDS by about 43%.
Model architecture
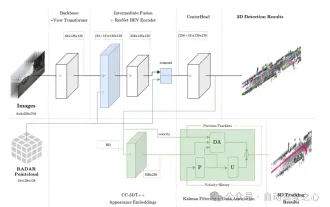
This method is based on the EV-Det framework, integrates RADAR’s spatial and velocity information, and combines the CC-3DT tracking head, which is included in its data association An improved millimeter-wave radar is explicitly used to enhance the detector's velocity estimation, ultimately enabling 3D target detection and tracking.
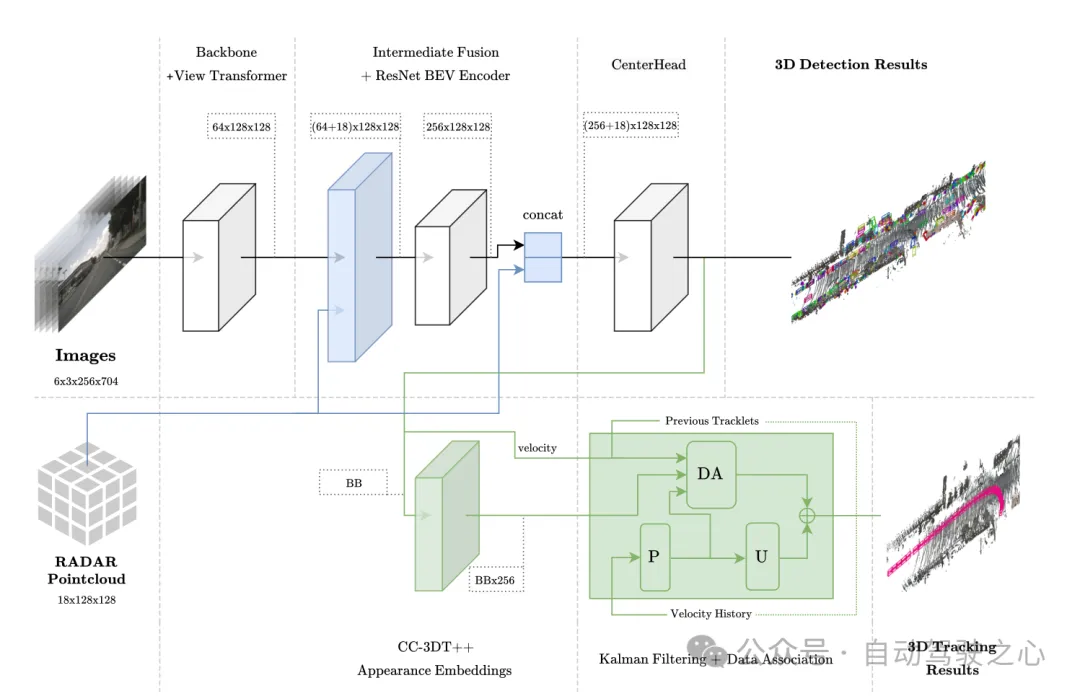 Figure 1 Overall architecture. Detection and tracking are highlighted in light blue and green respectively.
Figure 1 Overall architecture. Detection and tracking are highlighted in light blue and green respectively.
Sensor fusion in BEV space
This module adopts a fusion method similar to PointPillars, including aggregation and connection within it. The BEV grid is set to [-51.2, 51.2] with a resolution of 0.8, resulting in a (128×128) feature grid. Project the image features directly into the BEV space. The number of channels of each grid unit is 64, and then the image BEV features are (64×128×128); similarly, the 18-dimensional information of Radar is aggregated into each In the grid unit, this includes the x, y, and z coordinates of the point, and no enhancement is made to the Radar data. The author confirmed that the Radar point cloud already contains more information than the LiDAR point cloud, so the Radar BEV feature is (18×128×128). Finally, the image BEV features (64×128×128) and Radar BEV features (18×128×128) are directly connected ((64 18)×128×128) as the input of the BEV feature encoding layer. In subsequent ablation experiments, it was found that it is beneficial to add residual connections to the output of the BEV feature encoding layer with a dimension of (256×128×128), resulting in a final input size of the CenterPoint detection head of ((256 18) ×128×128).

Figure 2 Radar point cloud visualization aggregated into BEV space for fusion operation
Tracking module architecture
Tracking is to associate targets in two different frames based on motion correlation and visual feature similarity. During the training process, one-dimensional visual feature embedding vectors are obtained through quasi-dense multivariate positive contrast learning, and then detection and feature embedding are used simultaneously in the tracking stage of CC-3DT. The data association step (DA module in Figure 1) was modified to take advantage of improved CR3DT position detection and velocity estimation. The details are as follows:

Experiments and results
were completed based on the nuScenes data set, and all training did not use CBGS.
Restricted model
Because the author conducted the entire model on a computer with a 3090 graphics card, it is called a restricted model. The target detection part of this model uses BEVDet as the detection baseline, the image encoding backbone is ResNet50, and the image input is set to (3×256×704). Past or future time image information is not used in the model, and the batchsize is set to 8. To alleviate the sparsity of Radar data, five scans are used to enhance the data. No additional temporal information is used in the fusion model.
For target detection, use the scores of mAP, NDS, and mAVE to evaluate; for tracking, use AMOTA, AMOTP, and IDS to evaluate.
Object detection results
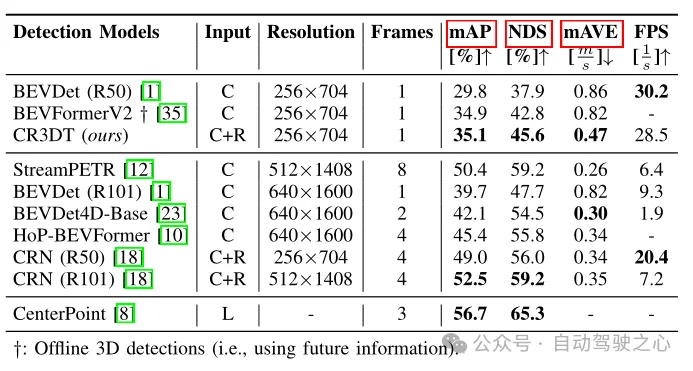
Table 1 Detection results on the nuScenes validation set
Table 1 shows the difference between CR3DT and only Detection performance compared to the baseline BEVDet (R50) architecture using cameras. It is obvious that the addition of Radar significantly improves the detection performance. Under the constraints of small resolution and time frame, CR3DT successfully achieves 5.3% mAP and 7.7% NDS improvement compared to camera-only BEVDet. However, due to limitations in computing power, the paper did not achieve experimental results of high resolution, merging time information, etc. In addition, the inference time is also given in the last column of Table 1.
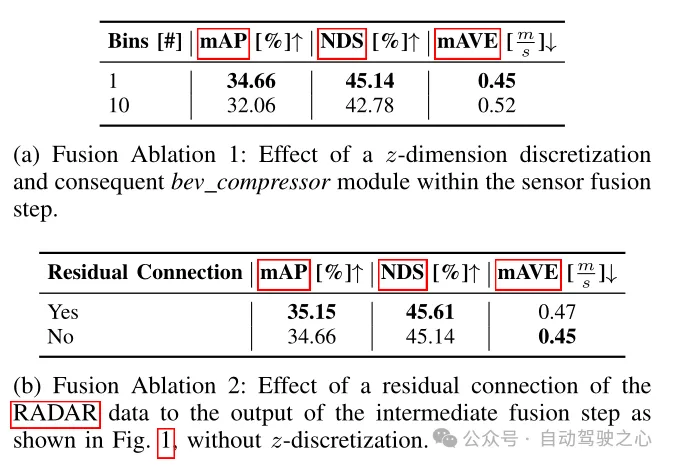
Table 2 Ablation experiment of detection framework
In Table 2, the impact of different fusion architectures on detection indicators is compared. The fusion methods here are divided into two types: the first one is mentioned in the paper, which abandons z-dimensional voxelization and subsequent 3D convolution, and directly aggregates the improved image features and pure RADAR data into columns, thus obtaining The known feature size is ((64 18) × 128 × 128); the other is to voxel the improved image features and pure RADAR data into a cube with a size of 0.8 × 0.8 × 0.8 m, thereby obtaining an alternative feature size is ((64 18) × 10 × 128 × 128), so the BEV compressor module needs to be used in the form of 3D convolution. As can be seen from Table 2(a), an increase in the number of BEV compressors will lead to a decrease in performance, and it can be seen that the first solution performs better. It can also be seen from Table 2(b) that adding the residual block of Radar data can also improve performance, which also confirms what was mentioned in the previous model architecture. Adding residual connections to the output of the BEV feature encoding layer is benefit.
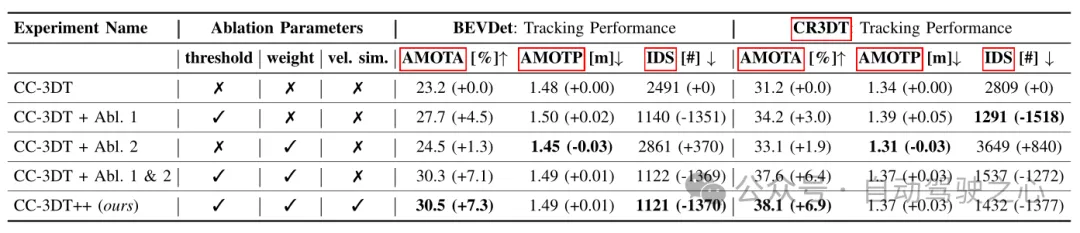 Table 3 Tracking results on the nuScenes validation set based on different configurations of baseline BEVDet and CR3DT
Table 3 Tracking results on the nuScenes validation set based on different configurations of baseline BEVDet and CR3DT
Table 3 shows the tracking of the improved CC3DT tracking model on the nuScenes validation set Results,The performance of the tracker on the baseline and on,the CR3DT detection model is given. The CR3DT model improves the performance of AMOTA by 14.9% over the baseline and decreases it by 0.11 m in AMOTP. Furthermore, it can be seen that IDS is reduced by approximately 43% compared to the baseline.
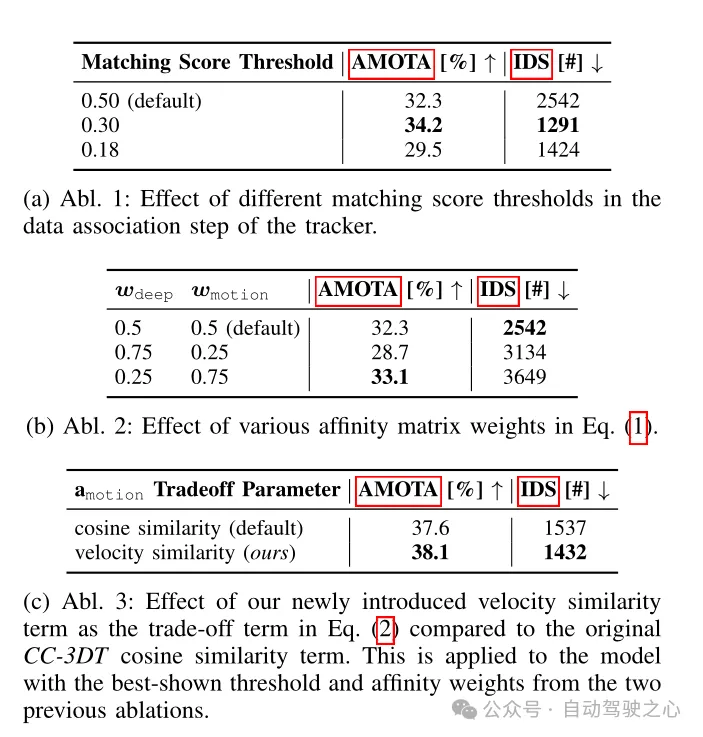
Table 4 Tracking architecture ablation experiment on CR3DT detection backbone

Conclusion
This work proposes an efficient camera-radar fusion model - CR3DT, specifically for 3D target detection and multi-target tracking. By integrating Radar data into the camera-only BEVDet architecture and introducing the CC-3DT tracking architecture, CR3DT has greatly improved 3D target detection and tracking accuracy, with mAP and AMOTA increasing by 5.35% and 14.9% respectively.
The camera and millimeter wave radar fusion solution has the advantage of low cost compared to pure LiDAR or LiDAR and camera fusion solution, and is close to the current development of autonomous vehicles. In addition, millimeter-wave radar has the advantage of being robust in bad weather and can face a variety of application scenarios. The current big problem is the sparseness of millimeter-wave radar point clouds and the inability to detect height information. However, with the continuous development of 4D millimeter wave radar, I believe that the future integration of cameras and millimeter wave radar solutions will reach a higher level and achieve even better results!
The above is the detailed content of Beyond BEVFormer! CR3DT: RV fusion helps 3D detection & tracking of new SOTA (ETH). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Easily understand 4K HD images! This large multi-modal model automatically analyzes the content of web posters, making it very convenient for workers.
Apr 23, 2024 am 08:04 AM
Easily understand 4K HD images! This large multi-modal model automatically analyzes the content of web posters, making it very convenient for workers.
Apr 23, 2024 am 08:04 AM
A large model that can automatically analyze the content of PDFs, web pages, posters, and Excel charts is not too convenient for workers. The InternLM-XComposer2-4KHD (abbreviated as IXC2-4KHD) model proposed by Shanghai AILab, the Chinese University of Hong Kong and other research institutions makes this a reality. Compared with other multi-modal large models that have a resolution limit of no more than 1500x1500, this work increases the maximum input image of multi-modal large models to more than 4K (3840x1600) resolution, and supports any aspect ratio and 336 pixels to 4K Dynamic resolution changes. Three days after its release, the model topped the HuggingFace visual question answering model popularity list. Easy to handle
 CVPR 2024 | LiDAR diffusion model for photorealistic scene generation
Apr 24, 2024 pm 04:28 PM
CVPR 2024 | LiDAR diffusion model for photorealistic scene generation
Apr 24, 2024 pm 04:28 PM
Original title: TowardsRealisticSceneGenerationwithLiDARDiffusionModels Paper link: https://hancyran.github.io/assets/paper/lidar_diffusion.pdf Code link: https://lidar-diffusion.github.io Author affiliation: CMU Toyota Research Institute University of Southern California Paper ideas : Diffusion models (DMs) excel at photorealistic image synthesis, but adapting them to lidar scene generation presents significant challenges. This is mainly because DMs operating in point space have difficulty
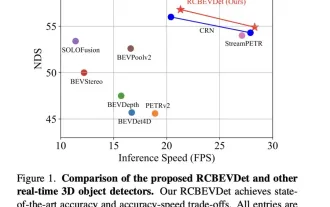 RV fusion performance is amazing! RCBEVDet: Radar also has spring, the latest SOTA!
Apr 02, 2024 am 11:49 AM
RV fusion performance is amazing! RCBEVDet: Radar also has spring, the latest SOTA!
Apr 02, 2024 am 11:49 AM
Written above & the author’s personal understanding is that the main issue this discussion paper focuses on is the application of 3D target detection technology in the process of autonomous driving. Although the development of environmental vision camera technology provides high-resolution semantic information for 3D object detection, this method is limited by issues such as the inability to accurately capture depth information and poor performance in bad weather or low-light conditions. In response to this problem, the discussion proposed a new multi-mode 3D target detection method-RCBEVDet that combines surround-view cameras and economical millimeter-wave radar sensors. This method provides richer semantic information and a solution to problems such as poor performance in bad weather or low-light conditions by comprehensively using information from multiple sensors. To address this issue, the discussion proposed a method that combines surround-view cameras
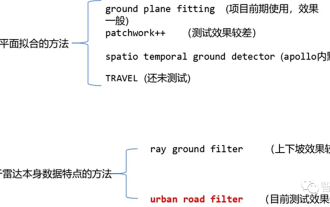 'In-depth Analysis': Exploring LiDAR Point Cloud Segmentation Algorithm in Autonomous Driving
Apr 23, 2023 pm 04:46 PM
'In-depth Analysis': Exploring LiDAR Point Cloud Segmentation Algorithm in Autonomous Driving
Apr 23, 2023 pm 04:46 PM
Currently, there are two common laser point cloud segmentation algorithms: methods based on plane fitting and methods based on the characteristics of laser point cloud data. The details are as follows: Point Cloud Ground Segmentation Algorithm 01 Method based on plane fitting - GroundPlaneFitting algorithm idea: A simple processing method is to divide the space into several sub-planes along the x direction (the direction of the car head), and then use The Ground Plane Fitting Algorithm (GPF) results in a ground segmentation method that can handle steep slopes. This method is to fit a global plane in a single frame point cloud. It works better when the number of point clouds is large. When the point cloud is sparse, it is easy to cause missed detections and false detections, such as 16-line lidar. Algorithm pseudocode: The pseudocode algorithm process is the final result of segmentation for a given point cloud P.
 New ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~
Apr 12, 2024 am 11:46 AM
New ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~
Apr 12, 2024 am 11:46 AM
Original title: LidarDM: GenerativeLiDARSimulationinaGeneratedWorld Paper link: https://arxiv.org/pdf/2404.02903.pdf Code link: https://github.com/vzyrianov/lidardm Author affiliation: University of Illinois, Massachusetts Institute of Technology Paper idea: Introduction to this article LidarDM, a novel lidar generation model capable of producing realistic, layout-aware, physically believable, and temporally coherent lidar videos. LidarDM has two unprecedented capabilities in lidar generative modeling: (1)
 Beyond BEVFormer! CR3DT: RV fusion helps 3D detection & tracking of new SOTA (ETH)
Apr 24, 2024 pm 06:07 PM
Beyond BEVFormer! CR3DT: RV fusion helps 3D detection & tracking of new SOTA (ETH)
Apr 24, 2024 pm 06:07 PM
Written above & the author’s personal understanding This article introduces a camera-millimeter wave radar fusion method (CR3DT) for 3D target detection and multi-target tracking. The lidar-based method has set a high standard for this field, but its high computing power and high cost have restricted the development of this solution in the field of autonomous driving; camera-based 3D target detection and tracking solutions are due to their high cost It is relatively low and has attracted the attention of many scholars, but due to its poor results. Therefore, the fusion of cameras and millimeter wave radar is becoming a promising solution. Under the existing camera framework BEVDet, the author fuses the spatial and velocity information of millimeter wave radar and combines it with the CC-3DT++ tracking head to significantly improve the accuracy of 3D target detection and tracking.
 LiDAR sensing technology solution under severe weather conditions
May 10, 2023 pm 04:07 PM
LiDAR sensing technology solution under severe weather conditions
May 10, 2023 pm 04:07 PM
01Abstract Self-driving cars rely on various sensors to collect information about the surrounding environment. The vehicle's behavior is planned based on environmental awareness, so its reliability is crucial for safety reasons. Active lidar sensors are capable of creating accurate 3D representations of scenes, making them a valuable addition to autonomous vehicles’ environmental awareness. LiDAR performance changes in adverse weather conditions such as fog, snow, or rain due to light scattering and occlusion. This limitation has recently spurred considerable research on methods to mitigate perceptual performance degradation. This paper collects, analyzes and discusses different aspects of LiDAR-based environmental sensing to cope with adverse weather conditions. and discusses topics such as the availability of appropriate data, raw point cloud processing and denoising, robust perception algorithms, and sensor fusion to alleviate
 Introduction to radar signal processing technology implemented in Java
Jun 18, 2023 am 10:15 AM
Introduction to radar signal processing technology implemented in Java
Jun 18, 2023 am 10:15 AM
Introduction: With the continuous development of modern science and technology, radar signal processing technology has been increasingly widely used. As one of the most popular programming languages at present, Java is widely used in the implementation of radar signal processing algorithms. This article will introduce the radar signal processing technology implemented in Java. 1. Introduction to radar signal processing technology Radar signal processing technology can be said to be the core and soul of the development of radar systems, and is the key technology to realize the automation and digitization of radar systems. Radar signal processing technology includes waveform processing, filtering, pulse compression, and adaptive beam shaping.
