
 Technology peripherals
AI
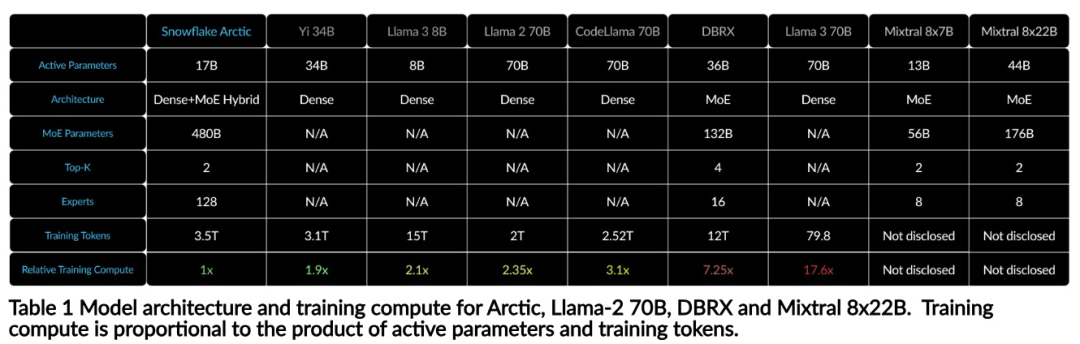
With only 1/17 the training cost of Llama3, Snowflake open source 128x3B MoE model
Technology peripherals
AI
With only 1/17 the training cost of Llama3, Snowflake open source 128x3B MoE model
With only 1/17 the training cost of Llama3, Snowflake open source 128x3B MoE model

Snowflake joins the LLM melee.
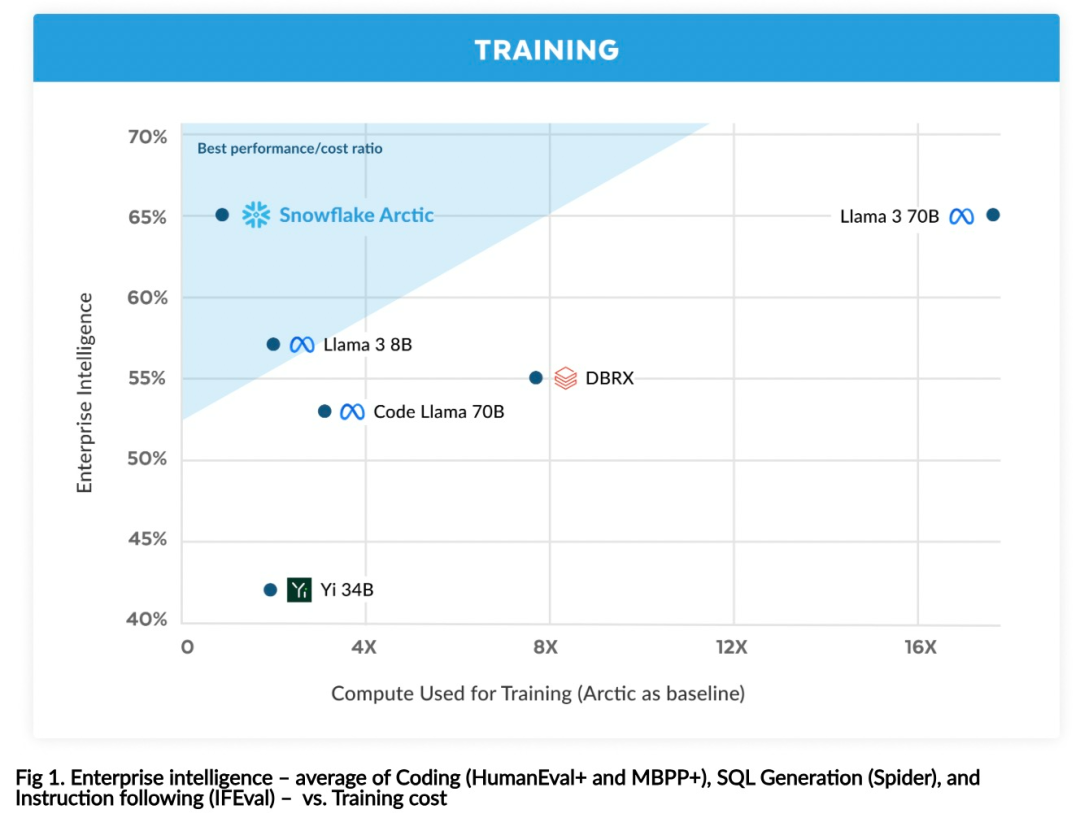
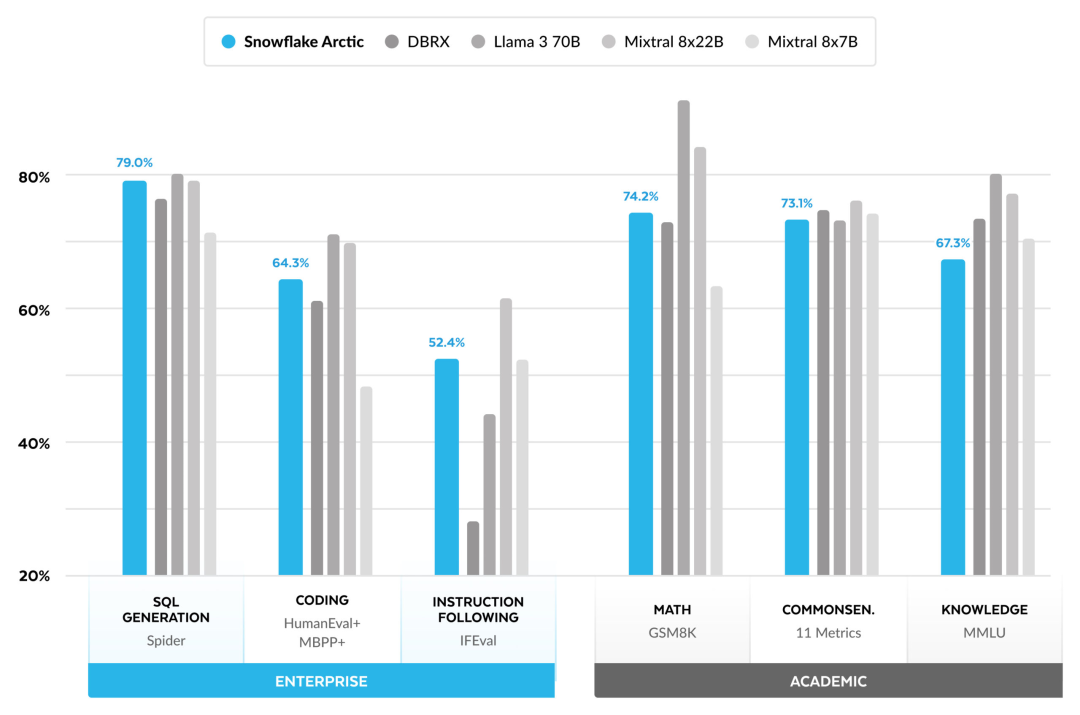
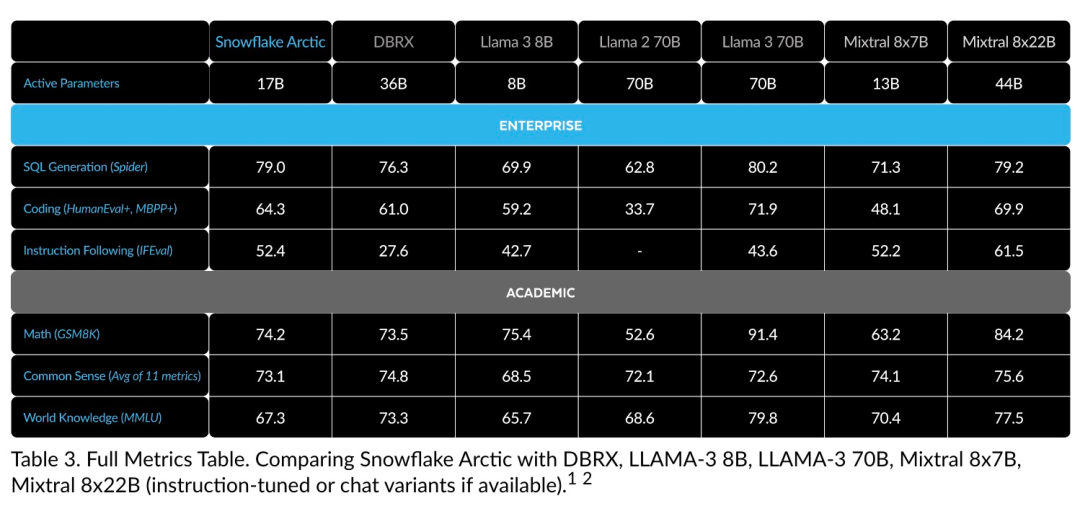
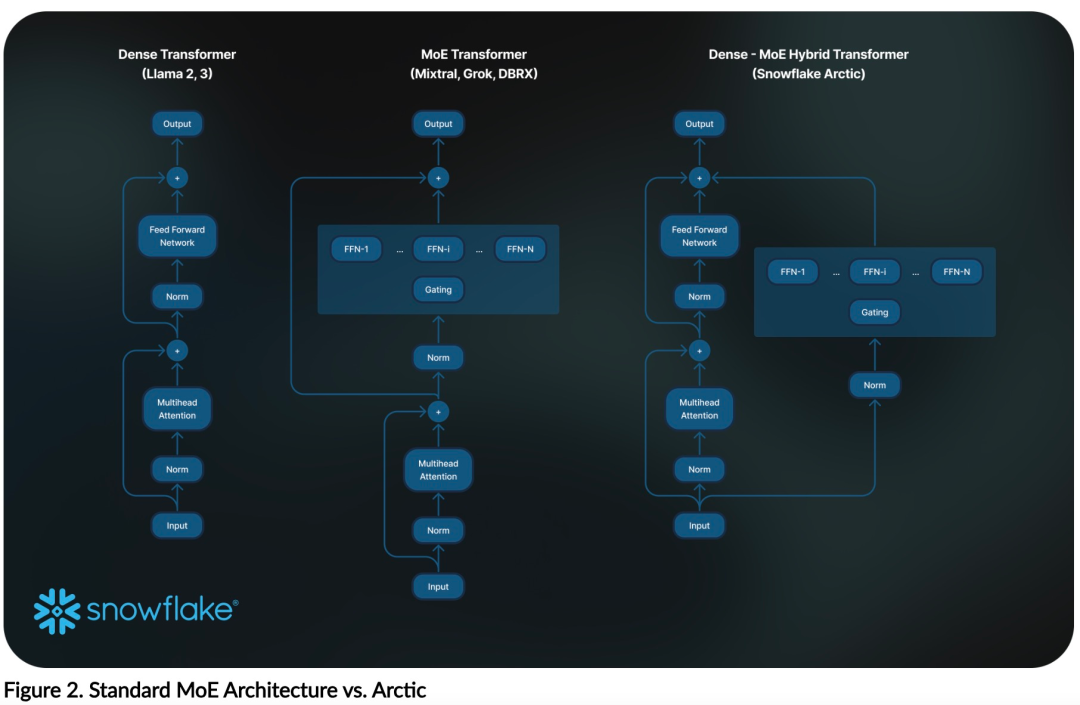
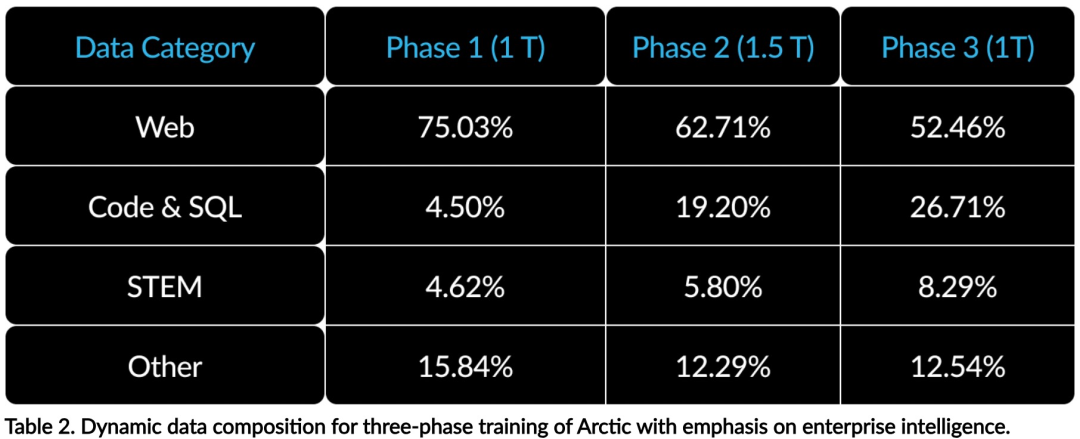
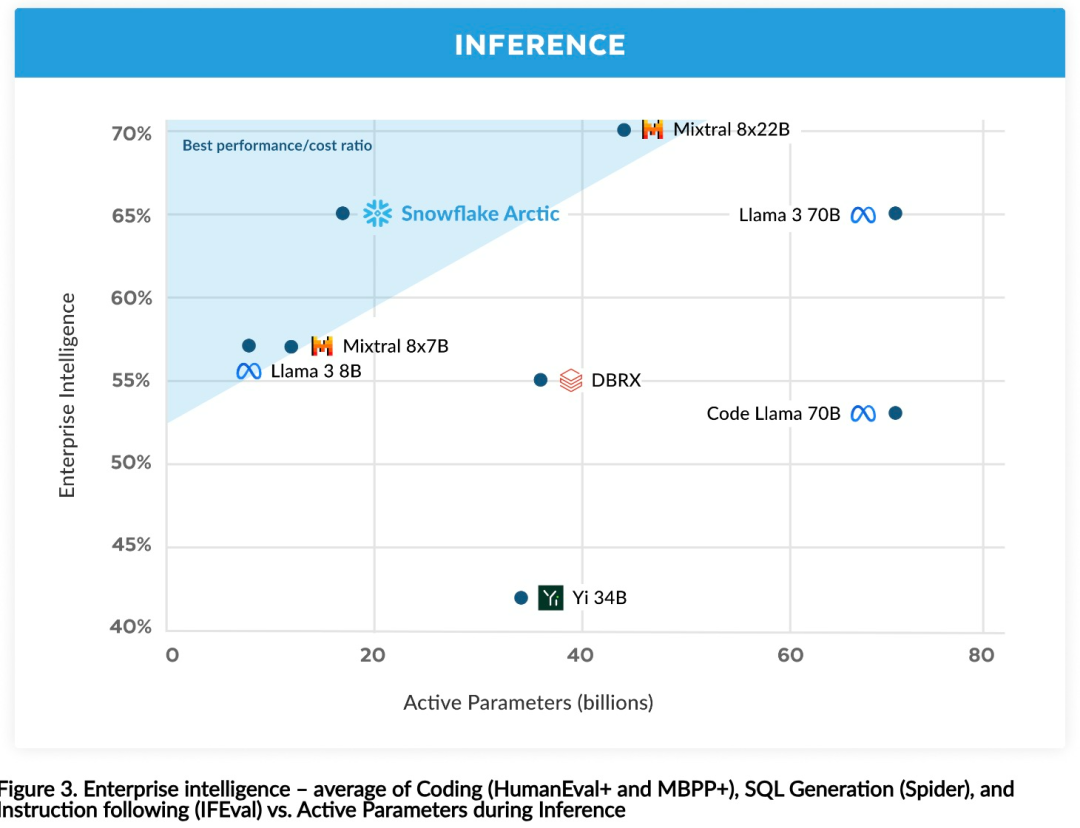
Efficient intelligence: Arctic excels at enterprise tasks such as SQL generation, programming, and instruction following, even competing with open source models trained with higher computational costs. Arctic sets a new baseline for cost-effective training, enabling Snowflake customers to create high-quality custom models at low cost for their enterprise needs. Open source: Arctic adopts the Apache 2.0 license, providing open access to weights and code, and Snowflake will also open source all data solutions and research findings.
The above is the detailed content of With only 1/17 the training cost of Llama3, Snowflake open source 128x3B MoE model. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1384
1384
 52
52

 How to set the cgi directory in apache
Apr 13, 2025 pm 01:18 PM
How to set the cgi directory in apache
Apr 13, 2025 pm 01:18 PM
To set up a CGI directory in Apache, you need to perform the following steps: Create a CGI directory such as "cgi-bin", and grant Apache write permissions. Add the "ScriptAlias" directive block in the Apache configuration file to map the CGI directory to the "/cgi-bin" URL. Restart Apache.
 How to start apache
Apr 13, 2025 pm 01:06 PM
How to start apache
Apr 13, 2025 pm 01:06 PM
The steps to start Apache are as follows: Install Apache (command: sudo apt-get install apache2 or download it from the official website) Start Apache (Linux: sudo systemctl start apache2; Windows: Right-click the "Apache2.4" service and select "Start") Check whether it has been started (Linux: sudo systemctl status apache2; Windows: Check the status of the "Apache2.4" service in the service manager) Enable boot automatically (optional, Linux: sudo systemctl
 How to check Debian OpenSSL configuration
Apr 12, 2025 pm 11:57 PM
How to check Debian OpenSSL configuration
Apr 12, 2025 pm 11:57 PM
This article introduces several methods to check the OpenSSL configuration of the Debian system to help you quickly grasp the security status of the system. 1. Confirm the OpenSSL version First, verify whether OpenSSL has been installed and version information. Enter the following command in the terminal: If opensslversion is not installed, the system will prompt an error. 2. View the configuration file. The main configuration file of OpenSSL is usually located in /etc/ssl/openssl.cnf. You can use a text editor (such as nano) to view: sudonano/etc/ssl/openssl.cnf This file contains important configuration information such as key, certificate path, and encryption algorithm. 3. Utilize OPE
 How to use Debian Apache logs to improve website performance
Apr 12, 2025 pm 11:36 PM
How to use Debian Apache logs to improve website performance
Apr 12, 2025 pm 11:36 PM
This article will explain how to improve website performance by analyzing Apache logs under the Debian system. 1. Log Analysis Basics Apache log records the detailed information of all HTTP requests, including IP address, timestamp, request URL, HTTP method and response code. In Debian systems, these logs are usually located in the /var/log/apache2/access.log and /var/log/apache2/error.log directories. Understanding the log structure is the first step in effective analysis. 2. Log analysis tool You can use a variety of tools to analyze Apache logs: Command line tools: grep, awk, sed and other command line tools.
 How to delete more than server names of apache
Apr 13, 2025 pm 01:09 PM
How to delete more than server names of apache
Apr 13, 2025 pm 01:09 PM
To delete an extra ServerName directive from Apache, you can take the following steps: Identify and delete the extra ServerName directive. Restart Apache to make the changes take effect. Check the configuration file to verify changes. Test the server to make sure the problem is resolved.
 How to view your apache version
Apr 13, 2025 pm 01:15 PM
How to view your apache version
Apr 13, 2025 pm 01:15 PM
There are 3 ways to view the version on the Apache server: via the command line (apachectl -v or apache2ctl -v), check the server status page (http://<server IP or domain name>/server-status), or view the Apache configuration file (ServerVersion: Apache/<version number>).
 How to optimize CentOS HDFS configuration
Apr 14, 2025 pm 07:15 PM
How to optimize CentOS HDFS configuration
Apr 14, 2025 pm 07:15 PM
Improve HDFS performance on CentOS: A comprehensive optimization guide to optimize HDFS (Hadoop distributed file system) on CentOS requires comprehensive consideration of hardware, system configuration and network settings. This article provides a series of optimization strategies to help you improve HDFS performance. 1. Hardware upgrade and selection resource expansion: Increase the CPU, memory and storage capacity of the server as much as possible. High-performance hardware: adopts high-performance network cards and switches to improve network throughput. 2. System configuration fine-tuning kernel parameter adjustment: Modify /etc/sysctl.conf file to optimize kernel parameters such as TCP connection number, file handle number and memory management. For example, adjust TCP connection status and buffer size
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
