
 Technology peripherals
AI
Accelerate diffusion model, generate SOTA-level images in the fastest 1 step, Byte Hyper-SD is open source
Technology peripherals
AI
Accelerate diffusion model, generate SOTA-level images in the fastest 1 step, Byte Hyper-SD is open source
Accelerate diffusion model, generate SOTA-level images in the fastest 1 step, Byte Hyper-SD is open source

Recently, Diffusion Model has made significant progress in the field of image generation, bringing unprecedented development opportunities to image generation and video generation tasks. Despite the impressive results, the multi-step iterative denoising properties inherent in the inference process of diffusion models result in high computational costs. Recently, a series of diffusion model distillation algorithms have emerged to accelerate the inference process of diffusion models. These methods can be roughly divided into two categories: i) trajectory-preserving distillation; ii) trajectory reconstruction distillation. However, these two types of methods are limited by the limited effect ceiling or changes in the output domain.
In order to solve these problems, the ByteDance technical team proposed a trajectory segmentation consistency model called Hyper-SD. Hyper-SD's open source has also been recognized by Huggingface CEO Clem Delangue.
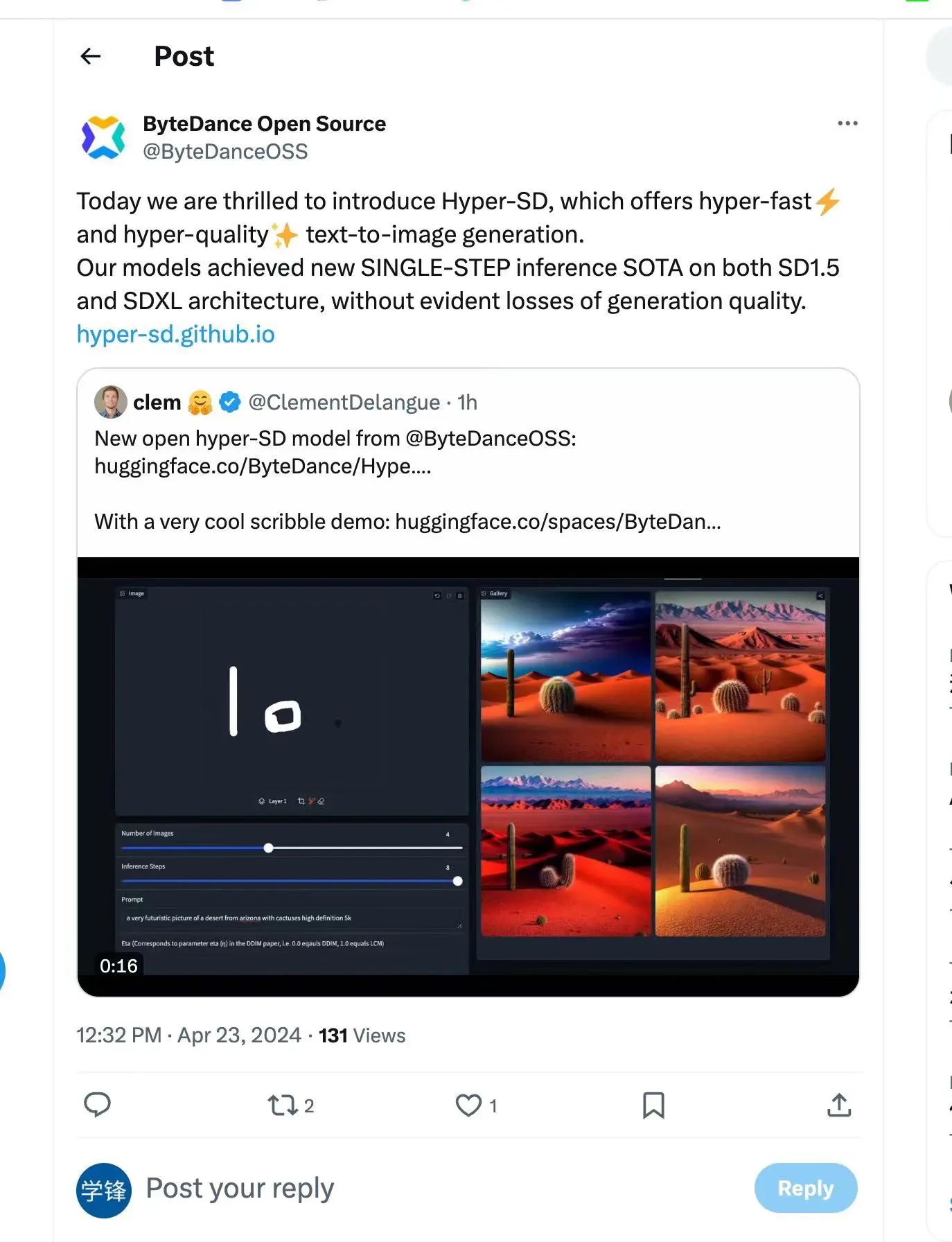
This model is a novel diffusion model distillation framework that combines the advantages of trajectory-preserving distillation and trajectory reconstruction distillation, while compressing the number of denoising steps. while maintaining near-lossless performance. Compared with existing diffusion model acceleration algorithms, this method achieves excellent acceleration results. Verified by extensive experiments and user reviews, Hyper-SD can achieve SOTA-level image generation performance in 1 to 8 steps of generation on both SDXL and SD1.5 architectures.

Project homepage: https://hyper-sd.github.io/
Paper link : https://arxiv.org/abs/2404.13686
Huggingface Link: https://huggingface.co/ByteDance/Hyper-SD
Single-step generated Demo link: https://huggingface.co/spaces/ByteDance/Hyper-SDXL-1Step-T2I
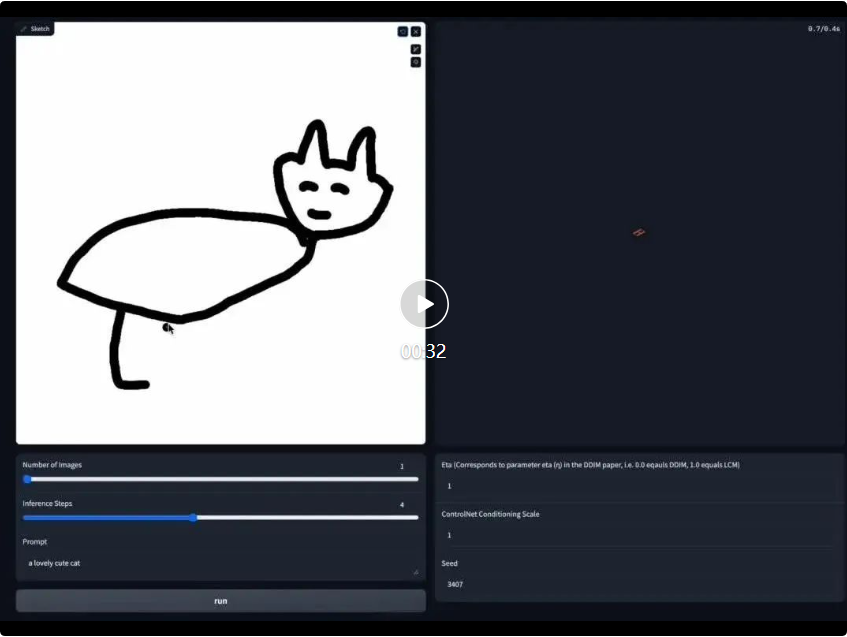
Real-time drawing board Demo link: https://huggingface. co/spaces/ByteDance/Hyper-SD15-Scribble

Method
1. Trajectory segmentation consistency distillation
Consistency Distillation (CD) [24] and Consistency Trajectory Model (CTM) [4] both aim to transform the diffusion model into a consistency model for the entire time step range [0, T] through one-shot distillation. However, these distillation models often fail to achieve optimality due to limitations in model fitting capabilities. Inspired by the soft consistency objective introduced in CTM, we refine the training process by dividing the entire time step range [0, T] into k segments and performing piecewise consistent model distillation step by step.
In the first stage, we set k=8 and use the original diffusion model to initialize 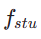 and
and 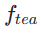 . The starting time step
. The starting time step 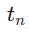 is uniformly randomly sampled from
is uniformly randomly sampled from  . We then sample the end time step
. We then sample the end time step 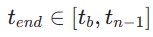 , where
, where 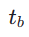 is calculated as follows:
is calculated as follows:
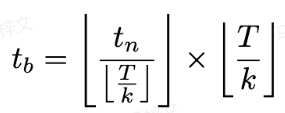
The training loss is calculated as follows:
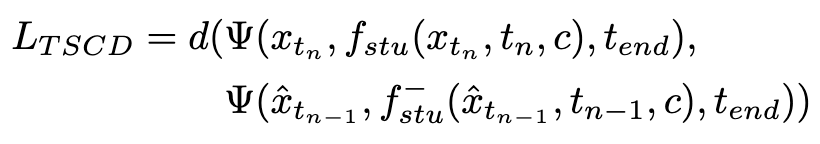
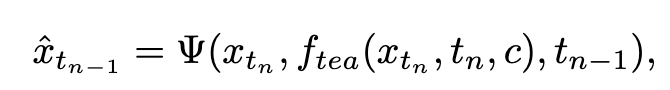
Where 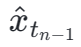 is calculated by formula 3,
is calculated by formula 3, 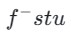 represents the exponential moving average (EMA) of the student model.
represents the exponential moving average (EMA) of the student model.
Subsequently, we restore the model weights from the previous stage and continue training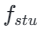 , gradually reducing k to [4,2,1]. It is worth noting that k=1 corresponds to the standard CTM training scheme. For the distance metric d, we employ a mixture of adversarial loss and mean squared error (MSE) loss. In experiments, we observed that the MSE loss is more effective when the predicted and target values are close (e.g., for k=8, 4), while the adversarial loss increases as the difference between the predicted and target values increases. becomes more precise (for example, for k=2, 1). Therefore, we dynamically increase the weight of the adversarial loss and decrease the weight of the MSE loss throughout the training phase. In addition, we also integrate a noise perturbation mechanism to enhance training stability. Take the two-stage Trajectory Segment Consensus Distillation (TSCD) process as an example. As shown in the figure below, we perform independent consistency distillation in the
, gradually reducing k to [4,2,1]. It is worth noting that k=1 corresponds to the standard CTM training scheme. For the distance metric d, we employ a mixture of adversarial loss and mean squared error (MSE) loss. In experiments, we observed that the MSE loss is more effective when the predicted and target values are close (e.g., for k=8, 4), while the adversarial loss increases as the difference between the predicted and target values increases. becomes more precise (for example, for k=2, 1). Therefore, we dynamically increase the weight of the adversarial loss and decrease the weight of the MSE loss throughout the training phase. In addition, we also integrate a noise perturbation mechanism to enhance training stability. Take the two-stage Trajectory Segment Consensus Distillation (TSCD) process as an example. As shown in the figure below, we perform independent consistency distillation in the 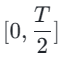 and
and 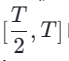 time periods in the first stage, and then perform global consistency trajectory distillation based on the consistency distillation results of the previous two periods.
time periods in the first stage, and then perform global consistency trajectory distillation based on the consistency distillation results of the previous two periods.
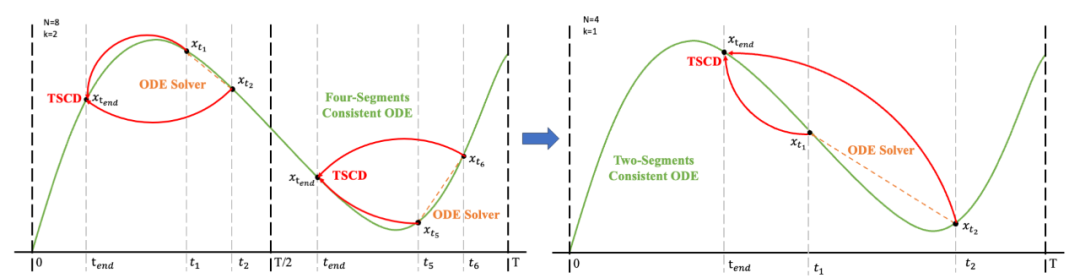
The complete algorithm process is as follows:

2. Human feedback learning
In addition to distillation, we further incorporate feedback learning to improve the performance of the accelerated diffusion model. Specifically, we improve the generation quality of accelerated models by leveraging human aesthetic preferences and feedback from existing visual perception models. For aesthetic feedback, we utilize the LAION aesthetic predictor and the aesthetic preference reward model provided in ImageReward to guide the model to generate more aesthetic images, as follows:
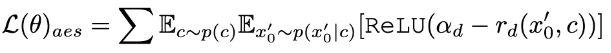
Where 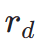 is the aesthetic reward model, including the aesthetic predictor of the LAION dataset and ImageReward model, c is the text prompt,
is the aesthetic reward model, including the aesthetic predictor of the LAION dataset and ImageReward model, c is the text prompt, 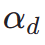 is used together with the ReLU function as the hinge loss. In addition to feedback from aesthetic preferences, we note that existing visual perception models embedding rich prior knowledge about images can also serve as good feedback providers. Empirically, we find that instance segmentation models can guide the model to generate well-structured objects. Specifically, we first diffuse the noise on image
is used together with the ReLU function as the hinge loss. In addition to feedback from aesthetic preferences, we note that existing visual perception models embedding rich prior knowledge about images can also serve as good feedback providers. Empirically, we find that instance segmentation models can guide the model to generate well-structured objects. Specifically, we first diffuse the noise on image 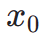 in the latent space to
in the latent space to 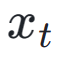 , after which, similar to ImageReward, we perform iterative denoising until a specific time step
, after which, similar to ImageReward, we perform iterative denoising until a specific time step 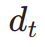 and predict
and predict 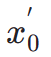 directly. We then leverage a perceptual instance segmentation model to evaluate the performance of structure generation by examining the difference between instance segmentation annotations for real images and instance segmentation predictions for denoised images, as follows:
directly. We then leverage a perceptual instance segmentation model to evaluate the performance of structure generation by examining the difference between instance segmentation annotations for real images and instance segmentation predictions for denoised images, as follows:
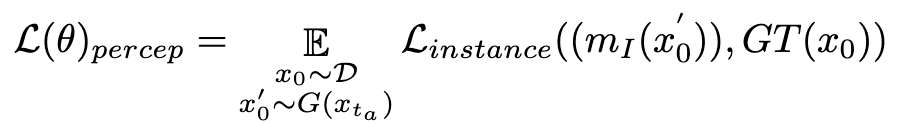
Where 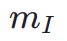 is the instance segmentation model (such as SOLO). Instance segmentation models can more accurately capture the structural defects of generated images and provide more targeted feedback signals. It is worth noting that in addition to instance segmentation models, other perceptual models are also applicable. These perceptual models can serve as complementary feedback to subjective aesthetics, focusing more on objective generative quality. Therefore, the diffusion model we use to optimize the feedback signal can be defined as:
is the instance segmentation model (such as SOLO). Instance segmentation models can more accurately capture the structural defects of generated images and provide more targeted feedback signals. It is worth noting that in addition to instance segmentation models, other perceptual models are also applicable. These perceptual models can serve as complementary feedback to subjective aesthetics, focusing more on objective generative quality. Therefore, the diffusion model we use to optimize the feedback signal can be defined as:
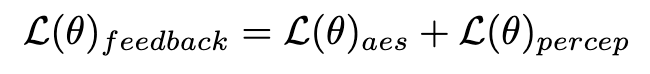
3. One-step generation of enhanced
due to consistency loss Inherent limitations, one-step generation within the consistency model framework are not ideal. As analyzed in CM, the consistent distillation model shows excellent accuracy in guiding the trajectory endpoint  at position
at position  . Therefore, fractional distillation is a suitable and effective method to further improve the one-step generation effect of our TSCD model. Specifically, we advance further generation through an optimized distribution matching distillation (DMD) technique. DMD enhances the model's output by utilizing two different scoring functions: distribution
. Therefore, fractional distillation is a suitable and effective method to further improve the one-step generation effect of our TSCD model. Specifically, we advance further generation through an optimized distribution matching distillation (DMD) technique. DMD enhances the model's output by utilizing two different scoring functions: distribution 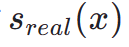 from the teacher model and
from the teacher model and 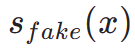 from the fake model. We combine mean squared error (MSE) loss with score-based distillation to improve training stability. In this process, the aforementioned human feedback learning techniques are also integrated to fine-tune our model to effectively generate images with high fidelity.
from the fake model. We combine mean squared error (MSE) loss with score-based distillation to improve training stability. In this process, the aforementioned human feedback learning techniques are also integrated to fine-tune our model to effectively generate images with high fidelity.
By integrating these strategies, our method can not only achieve excellent low-step inference results on both SD1.5 and SDXL (and without Classifier-Guidance), but also achieve an ideal global consistency model without targeting Each specific number of steps trains UNet or LoRA to implement a unified low-step reasoning model.
Experiment
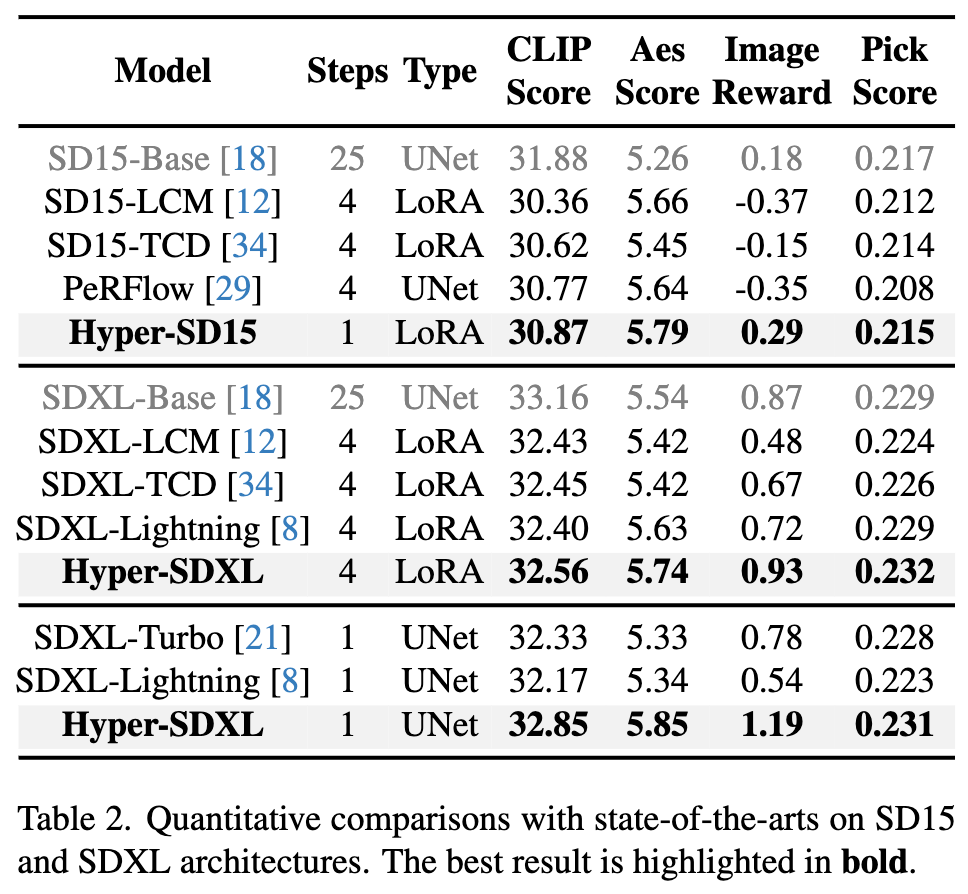
On SD1.5 and SDXL and the current existing A quantitative comparison of acceleration algorithms shows that Hyper-SD is significantly better than the current state-of-the-art methods
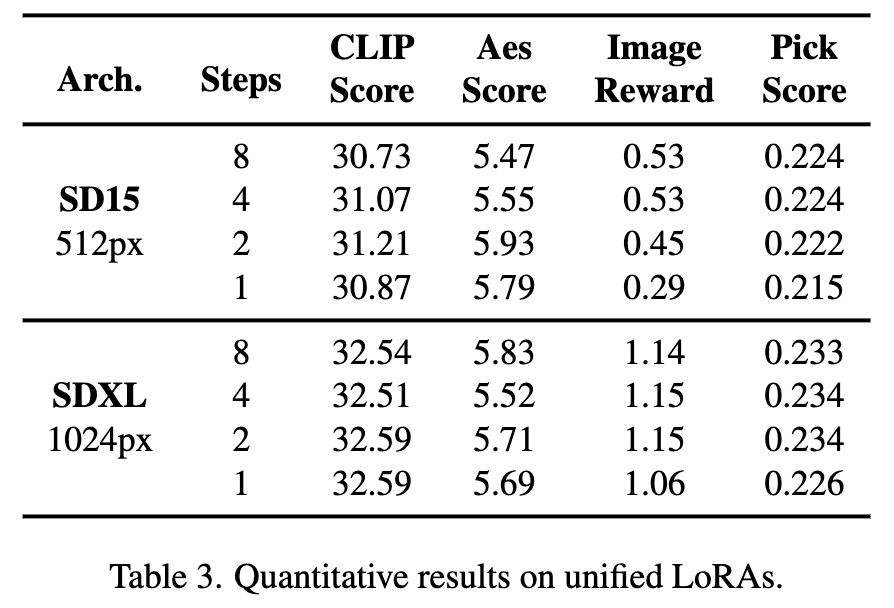
In addition, Hyper-SD can use one model to implement various Different from low-step inference, the above quantitative indicators also show the effect of our method when using unified model inference.


The visualization of the acceleration effect on SD1.5 and SDXL intuitively demonstrates the superiority of Hyper-SD in accelerating diffusion model inference sex.
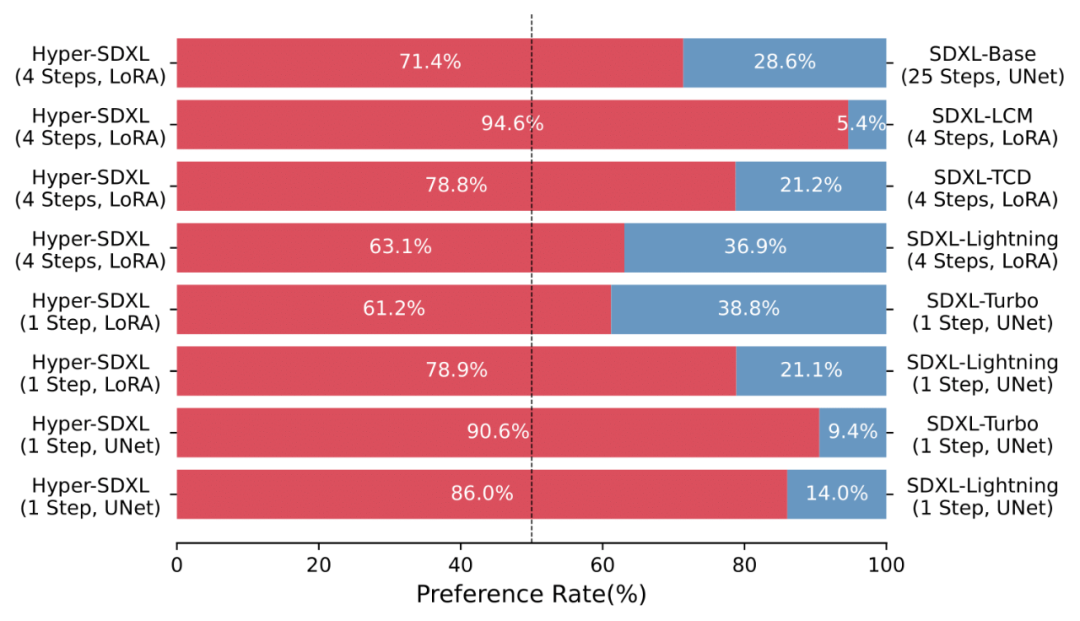
A large number of User-Study also shows the superiority of Hyper-SD compared to various existing acceleration algorithms.

The accelerated LoRA trained by Hyper-SD is well compatible with different styles of Vincent figure base models.
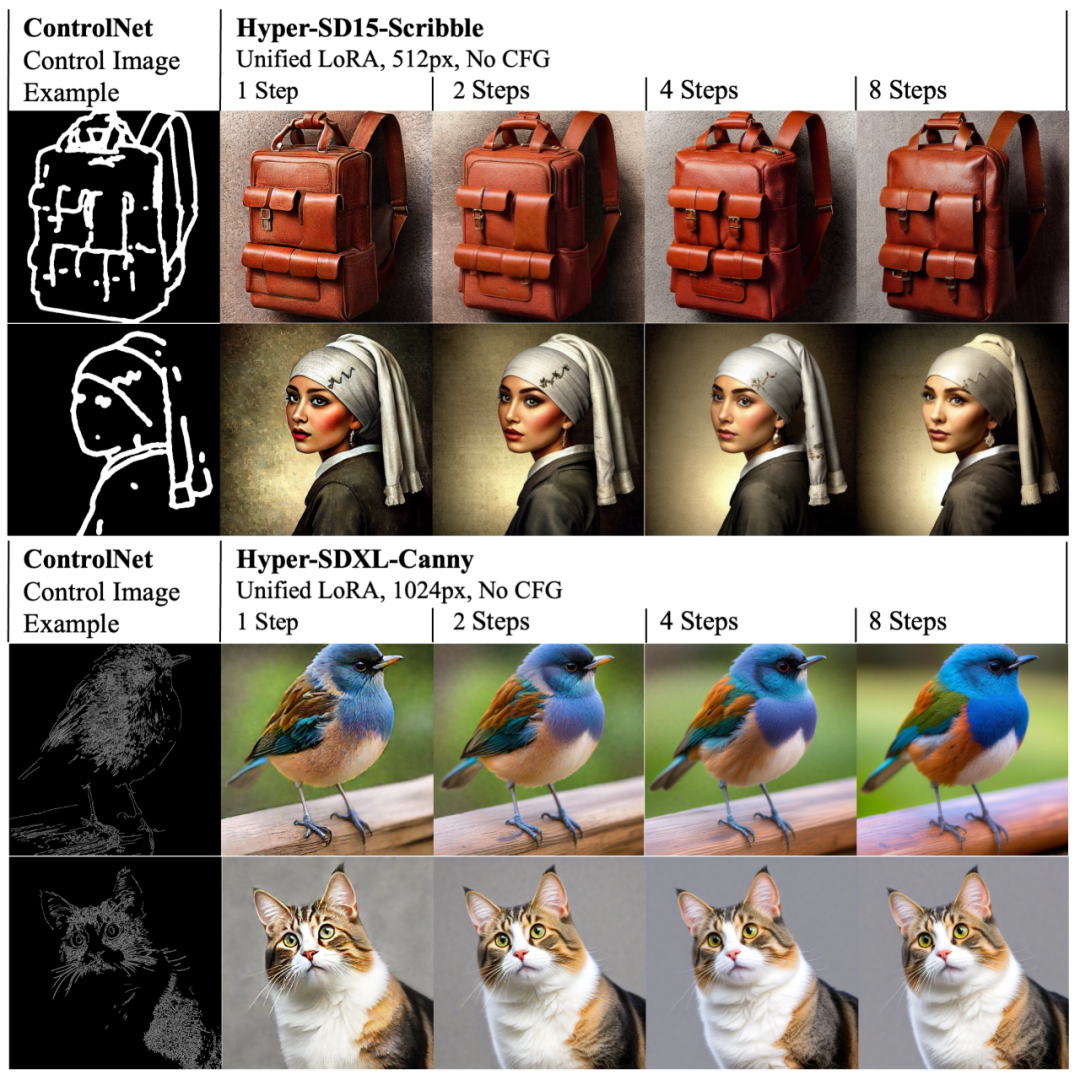
At the same time, Hyper-SD’s LoRA can also adapt to the existing ControlNet to achieve high-quality controllable image generation at a low number of steps.
Summary
The paper proposes Hyper-SD, a unified diffusion model acceleration framework that can significantly improve the generation ability of diffusion models in low-step situations. , realizing new SOTA performance based on SDXL and SD15. This method uses trajectory segmentation consistency distillation to enhance the trajectory preservation capability during the distillation process and achieve a generation effect close to the original model. Then, the potential of the model at extremely low step counts is improved by further leveraging human feedback learning and variational fractional distillation, resulting in more optimized and efficient model generation. The paper also open sourced the Lora plug-in for SDXL and SD15 from 1 to 8 steps inference, as well as a dedicated one-step SDXL model, aiming to further promote the development of the generative AI community.
The above is the detailed content of Accelerate diffusion model, generate SOTA-level images in the fastest 1 step, Byte Hyper-SD is open source. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to download git projects to local
Apr 17, 2025 pm 04:36 PM
How to download git projects to local
Apr 17, 2025 pm 04:36 PM
To download projects locally via Git, follow these steps: Install Git. Navigate to the project directory. cloning the remote repository using the following command: git clone https://github.com/username/repository-name.git
 How to update code in git
Apr 17, 2025 pm 04:45 PM
How to update code in git
Apr 17, 2025 pm 04:45 PM
Steps to update git code: Check out code: git clone https://github.com/username/repo.git Get the latest changes: git fetch merge changes: git merge origin/master push changes (optional): git push origin master
 How to use git commit
Apr 17, 2025 pm 03:57 PM
How to use git commit
Apr 17, 2025 pm 03:57 PM
Git Commit is a command that records file changes to a Git repository to save a snapshot of the current state of the project. How to use it is as follows: Add changes to the temporary storage area Write a concise and informative submission message to save and exit the submission message to complete the submission optionally: Add a signature for the submission Use git log to view the submission content
 What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
Resolve: When Git download speed is slow, you can take the following steps: Check the network connection and try to switch the connection method. Optimize Git configuration: Increase the POST buffer size (git config --global http.postBuffer 524288000), and reduce the low-speed limit (git config --global http.lowSpeedLimit 1000). Use a Git proxy (such as git-proxy or git-lfs-proxy). Try using a different Git client (such as Sourcetree or Github Desktop). Check for fire protection
 How to merge code in git
Apr 17, 2025 pm 04:39 PM
How to merge code in git
Apr 17, 2025 pm 04:39 PM
Git code merge process: Pull the latest changes to avoid conflicts. Switch to the branch you want to merge. Initiate a merge, specifying the branch to merge. Resolve merge conflicts (if any). Staging and commit merge, providing commit message.
 How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
To delete a Git repository, follow these steps: Confirm the repository you want to delete. Local deletion of repository: Use the rm -rf command to delete its folder. Remotely delete a warehouse: Navigate to the warehouse settings, find the "Delete Warehouse" option, and confirm the operation.
 How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
When developing an e-commerce website, I encountered a difficult problem: How to achieve efficient search functions in large amounts of product data? Traditional database searches are inefficient and have poor user experience. After some research, I discovered the search engine Typesense and solved this problem through its official PHP client typesense/typesense-php, which greatly improved the search performance.
 How to update local code in git
Apr 17, 2025 pm 04:48 PM
How to update local code in git
Apr 17, 2025 pm 04:48 PM
How to update local Git code? Use git fetch to pull the latest changes from the remote repository. Merge remote changes to the local branch using git merge origin/<remote branch name>. Resolve conflicts arising from mergers. Use git commit -m "Merge branch <Remote branch name>" to submit merge changes and apply updates.
