
 Technology peripherals
AI
Under the leadership of Yan Shuicheng, Kunlun Wanwei 2050 Global Research Institute jointly released Vitron with NUS and NTU, establishing the ultimate form of general visual multi-modal large models.
Technology peripherals
AI
Under the leadership of Yan Shuicheng, Kunlun Wanwei 2050 Global Research Institute jointly released Vitron with NUS and NTU, establishing the ultimate form of general visual multi-modal large models.
Under the leadership of Yan Shuicheng, Kunlun Wanwei 2050 Global Research Institute jointly released Vitron with NUS and NTU, establishing the ultimate form of general visual multi-modal large models.

Recently, led by Professor Yan Shuicheng, the Kunlun Wanwei 2050 Global Research Institute, National University of Singapore, and Nanyang Technological University of Singapore teams jointly released and open sourced itVitron universal pixel-level visual multi-modal large language model.
This is a heavy-duty general visual multi-modal model that supports a series of visual tasks from visual understanding to visual generation, from low level to high level, solving problems. The image / long-standing problem in the large language model industry provides a pixel-level pixel-level solution that comprehensively unifies the understanding, generation, segmentation, and editing of static images and dynamic video content. The general vision multi-modal large model lays the foundation for the ultimate form of the next generation general vision large model, and also marks the step towards general artificial intelligence(#AGI)Another big step.
Vitron, as a unified pixel-level visual multi-modal large language model, achieves comprehensive support for visual tasks from low-level to high-level ,Able to handle complex visual tasks, andunderstand and generate image and video content, providing powerful visual understanding and task execution capabilities. At the same time, Vitron supports continuous operations with users, enabling flexible human-computer interaction, demonstrating the great potential towards a more unified visual multi-modal universal model.
Vitron-related papers, codes and Demo have all been made public. They are comprehensive, technological innovation, The unique advantages and potential demonstrated in human-computer interaction and application potential not only promote the development of multi-modal large models, but also provide a new direction for future visual large model research.
Kunlun Wanwei2050 Global Research Institute has always been committed to building a excellent company for the future world Scientific research institutions, together with the scientific communitycross" singularity", Explore the unknown world,create a better future. Previously, Kunlun Wanwei2050 Global Research Institute has released and open sourced the digital agent research and development toolkitAgentStudio, In the future, the institute will continue to promote artificial intelligencetechnical breakthroughs, and contribute to China'sartificial intelligence ecological constructionContribute. The current development of visual large language models (LLMs) has made gratifying progress. The community increasingly believes that building more general and powerful multimodal large models (MLLMs) will be the only way to achieve general artificial intelligence (AGI). However, there are still some key challenges in the process of moving towards a multi-modal general model (Generalist). For example, a large part of the work does not achieve fine-grained pixel-level visual understanding, or lacks unified support for images and videos. Or the support for various visual tasks is insufficient, and it is far from a universal large model.
In order to fill this gap, recently, the Kunlun Worldwide 2050 Global Research Institute, the National University of Singapore, and the Nanyang Technological University of Singapore team jointly released the open source Vitron universal pixel-level visual multi-modal large language model. Vitron supports a series of visual tasks from visual understanding to visual generation, from low level to high level, including comprehensive understanding, generation, segmentation and editing of static images and dynamic video content.
Vitron comprehensively describes the functional support for four major vision-related tasks. and its key advantages. Vitron also supports continuous operation with users to achieve flexible human-machine interaction. This project demonstrates the great potential for a more unified vision multi-modal general model, laying the foundation for the ultimate form of the next generation of general vision large models.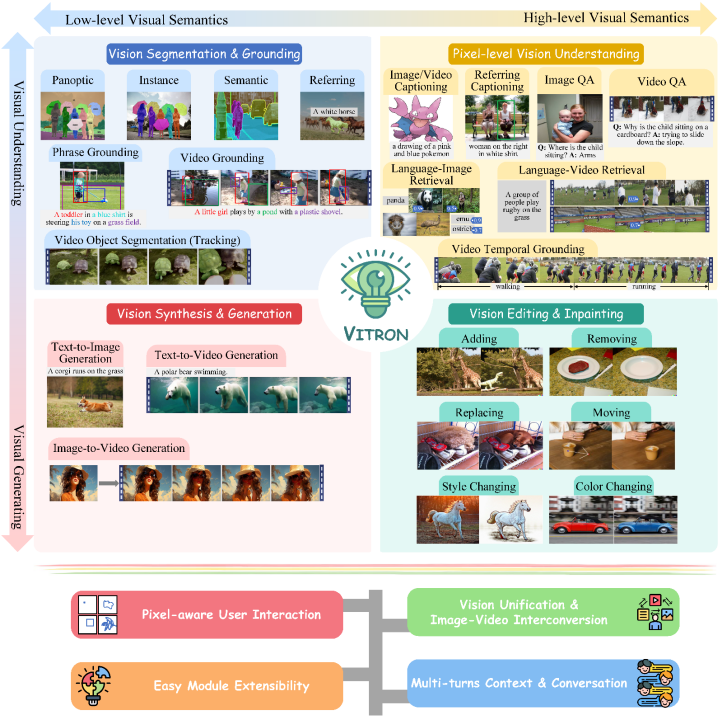 Vitron related papers, codes, and demos are now all public.
Vitron related papers, codes, and demos are now all public.
- Paper link: https://is.gd/aGu0VV
- Open source code: https://github.com/SkyworkAI/Vitron
0
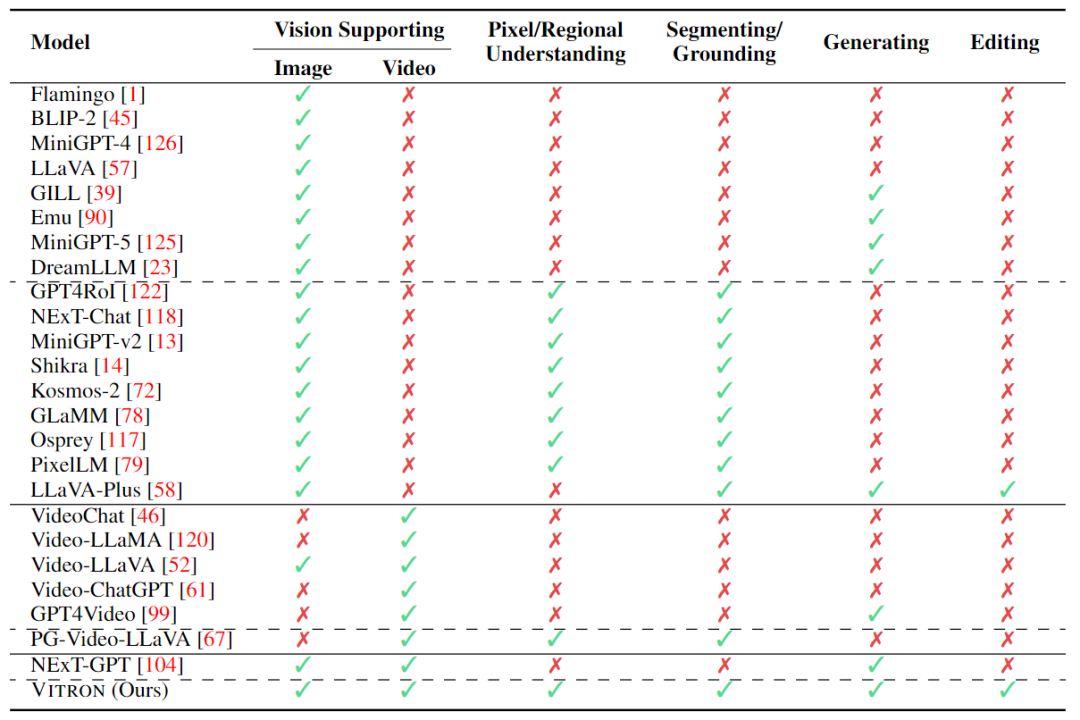
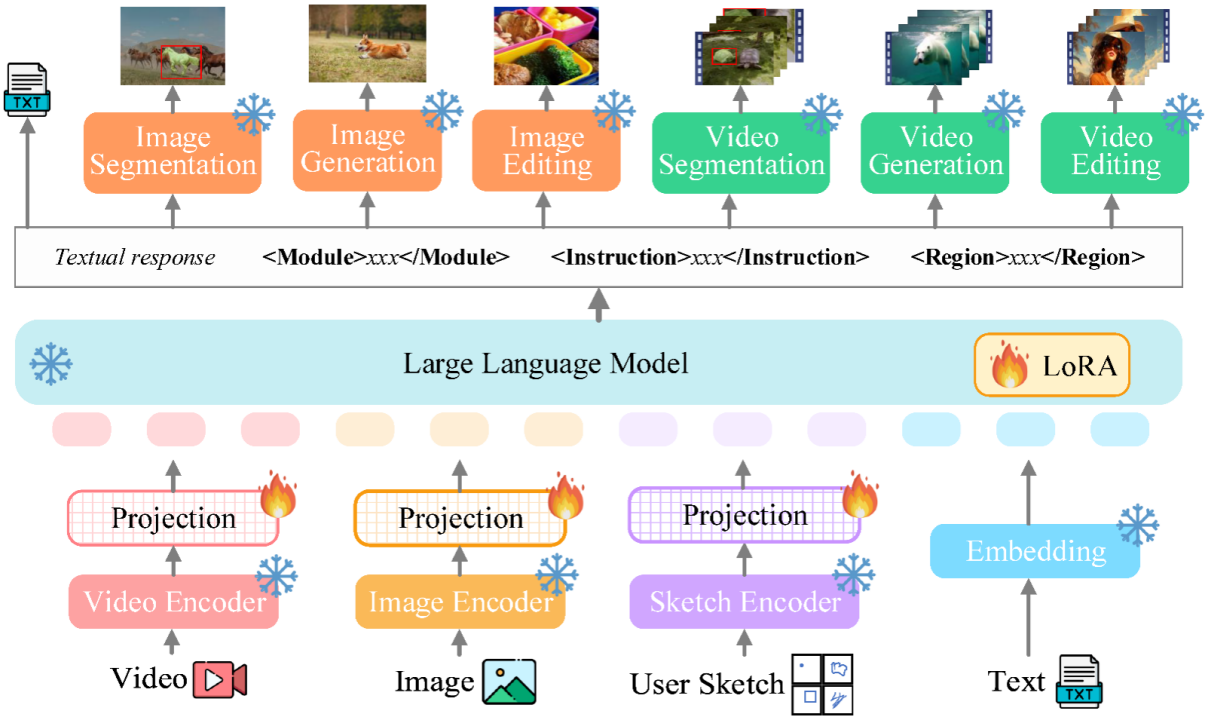
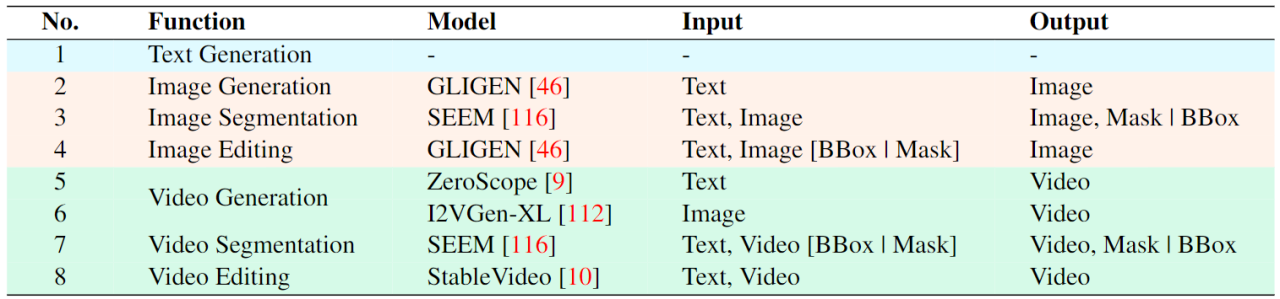
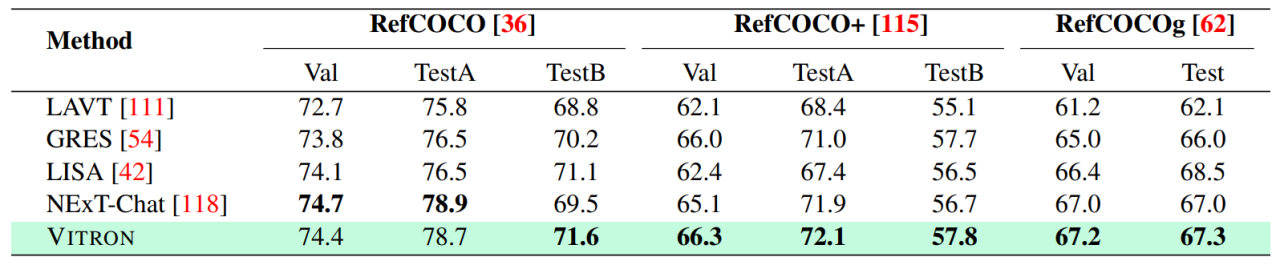
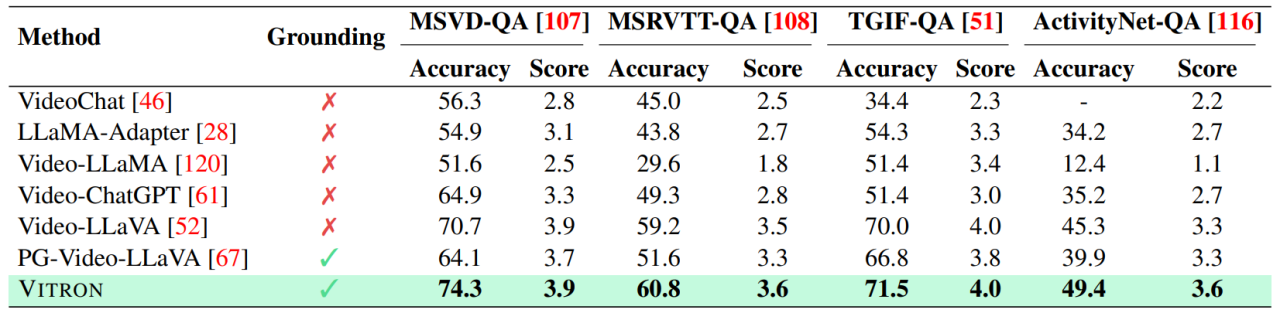
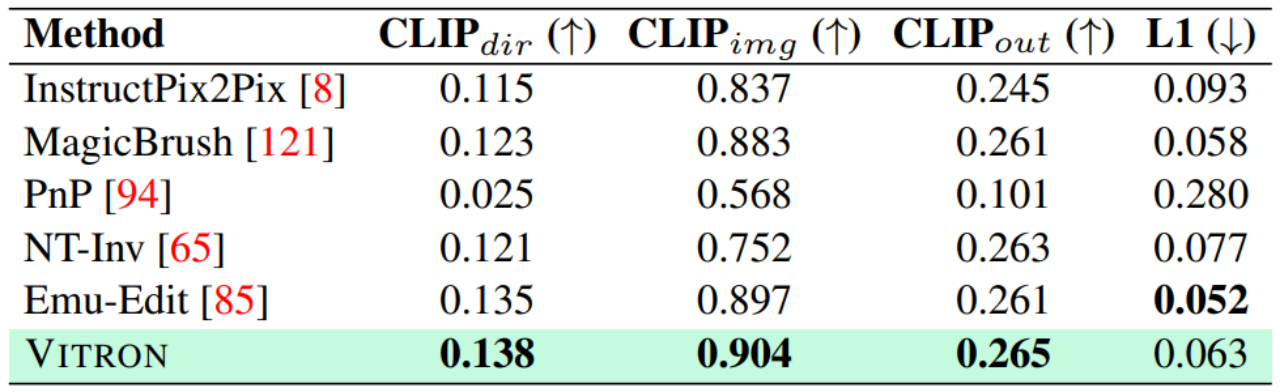
. The ultimate unified multi-modal language model In recent years, large language models (LLMs) have demonstrated unprecedented powerful capabilities, and they have been gradually verified as the technical route to AGI. Multimodal large language models (MLLMs) are developing rapidly in many communities and are rapidly emerging. By introducing modules that can perform visual perception, pure language-based LLMs are extended to MLLMs. Many MLLMs that are powerful and excellent in image understanding have been developed. , such as BLIP-2, LLaVA, MiniGPT-4, etc. At the same time, MLLMs focusing on video understanding have also been launched, such as VideoChat, Video-LLaMA, Video-LLaVA, etc. Subsequently, researchers mainly tried to further expand the capabilities of MLLMs from two dimensions. On the one hand, researchers are trying to deepen MLLMs' understanding of vision, transitioning from rough instance-level understanding to pixel-level fine-grained understanding of images, so as to achieve visual region positioning (Regional Grounding) capabilities, such as GLaMM, PixelLM, NExT-Chat and MiniGPT-v2 etc. On the other hand, researchers try to expand the visual functions that MLLMs can support. Some research has begun to study how MLLMs not only understand input visual signals, but also support the generation of output visual content. For example, MLLMs such as GILL and Emu can flexibly generate image content, and GPT4Video and NExT-GPT realize video generation. At present, the artificial intelligence community has gradually reached a consensus that the future trend of visual MLLMs will inevitably develop in the direction of highly unified and stronger capabilities. However, despite the numerous MLLMs developed by the community, a clear gap still exists. The above table simply summarizes the capabilities of existing visual MLLM (only representatively includes some models, and the coverage is incomplete). To bridge these gaps, the team proposes Vitron, a general pixel-level visual MLLM. 02. Vitron system architecture: three key modules Vitron overall framework As shown below. Vitron adopts a similar architecture to existing related MLLMs, including three key parts: 1) front-end visual & language encoding module, 2) central LLM understanding and text generation module, and 3) back-end user response and module calls for visual control module. 03. VitronThree stages of model training Based on the above architecture, Vitron is trained and fine-tuned to give it powerful visual understanding and task execution capabilities. Model training mainly includes three different stages. 1) User response output , directly reply to the user's input. 2) Module name, indicating the function or task to be performed. 3) Call the command to trigger the meta-instruction of the task module. 4) Region (optional output) that specifies fine-grained visual features required for certain tasks, such as in video tracking or visual editing, where backend modules require this information. For regions, based on LLM's pixel-level understanding, a bounding box described by coordinates will be output. 04. Evaluation Experiment Researchers conducted extensive experimental evaluations on 22 common benchmark data sets and 12 image/video vision tasks based on Vitron. Vitron demonstrates strong capabilities in four major visual task groups (segmentation, understanding, content generation and editing), while at the same time it has flexible human-computer interaction capabilities. The following representatively shows some qualitative comparison results: Results of image referring image segmentation Results of image referring expression comprehension. Results on video QA. Image editing results For more detailed experimental content and details, please move here step thesis. 05. Future Directions Overall, this work demonstrates The huge potential of developing a unified visual multi-modal general large model has laid a new form for the research of the next generation of visual large models and taken the first step in this direction. Although the Vitron system proposed by the team shows strong general capabilities, it still has its own limitations. The following researchers list some directions that could be further explored in the future. The Vitron system still uses a semi-joint, semi-agent approach to call external tools. Although this call-based method facilitates the expansion and replacement of potential modules, it also means that the back-end modules of this pipeline structure do not participate in the joint learning of the front-end and LLM core modules. This limitation is not conducive to the overall learning of the system, which means that the performance upper limit of different vision tasks will be limited by the back-end modules. Future work should integrate various vision task modules into a unified unit. Achieving unified understanding and output of images and videos while supporting generation and editing capabilities through a single generative paradigm remains a challenge. Currently, a promising approach is to combine modularity-persistent tokenization to improve the unification of the system on different inputs and outputs and various tasks. Unlike previous models that focused on a single vision task (e.g., Stable Diffusion and SEEM), Vitron aims to facilitate The in-depth interaction between LLM and users is similar to OpenAI’s DALL-E series, Midjourney, etc. in the industry. Achieving optimal user interactivity is one of the core goals of this work. Vitron leverages existing language-based LLMs, combined with appropriate instruction adjustments, to achieve a certain level of interactivity. For example, the system can flexibly respond to any expected message input by the user and produce corresponding visual operation results without requiring the user input to exactly match the back-end module conditions. However, this work still has a lot of room for improvement in terms of enhancing interactivity. For example, drawing inspiration from the closed-source Midjourney system, no matter what decision LLM makes at each step, the system should actively provide feedback to users to ensure that its actions and decisions are consistent with user intentions. Modal capabilities Currently, Vitron integrates a 7B Vicuna model, which may have the ability to understand language, images and videos Certain restrictions will apply. Future exploration directions could be to develop a comprehensive end-to-end system, such as expanding the scale of the model to achieve a more thorough and comprehensive understanding of vision. Furthermore, efforts should be made to enable LLM to fully unify the understanding of image and video modalities.



The above is the detailed content of Under the leadership of Yan Shuicheng, Kunlun Wanwei 2050 Global Research Institute jointly released Vitron with NUS and NTU, establishing the ultimate form of general visual multi-modal large models.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to install deepseek
Feb 19, 2025 pm 05:48 PM
How to install deepseek
Feb 19, 2025 pm 05:48 PM
There are many ways to install DeepSeek, including: compile from source (for experienced developers) using precompiled packages (for Windows users) using Docker containers (for most convenient, no need to worry about compatibility) No matter which method you choose, Please read the official documents carefully and prepare them fully to avoid unnecessary trouble.
 Summary of FAQs for DeepSeek usage
Feb 19, 2025 pm 03:45 PM
Summary of FAQs for DeepSeek usage
Feb 19, 2025 pm 03:45 PM
DeepSeekAI Tool User Guide and FAQ DeepSeek is a powerful AI intelligent tool. This article will answer some common usage questions to help you get started quickly. FAQ: The difference between different access methods: There is no difference in function between web version, App version and API calls, and App is just a wrapper for web version. The local deployment uses a distillation model, which is slightly inferior to the full version of DeepSeek-R1, but the 32-bit model theoretically has 90% full version capability. What is a tavern? SillyTavern is a front-end interface that requires calling the AI model through API or Ollama. What is breaking limit
 How to download deepseek
Feb 19, 2025 pm 05:45 PM
How to download deepseek
Feb 19, 2025 pm 05:45 PM
Make sure to access official website downloads and carefully check the domain name and website design. After downloading, scan the file. Read the protocol during installation and avoid the system disk when installing. Test the function and contact customer service to solve the problem. Update the version regularly to ensure the security and stability of the software.
 What are the Grayscale Encryption Trust Funds? Common Grayscale Encryption Trust Funds Inventory
Mar 05, 2025 pm 12:33 PM
What are the Grayscale Encryption Trust Funds? Common Grayscale Encryption Trust Funds Inventory
Mar 05, 2025 pm 12:33 PM
Grayscale Investment: The channel for institutional investors to enter the cryptocurrency market. Grayscale Investment Company provides digital currency investment services to institutions and investors. It allows investors to indirectly participate in cryptocurrency investment through the form of trust funds. The company has launched several crypto trusts, which has attracted widespread market attention, but the impact of these funds on token prices varies significantly. This article will introduce in detail some of Grayscale's major crypto trust funds. Grayscale Major Crypto Trust Funds Available at a glance Grayscale Investment (founded by DigitalCurrencyGroup in 2013) manages a variety of crypto asset trust funds, providing institutional investors and high-net-worth individuals with compliant investment channels. Its main funds include: Zcash (ZEC), SOL,
 Delphi Digital: How to change the new AI economy by parsing the new ElizaOS v2 architecture?
Mar 04, 2025 pm 07:00 PM
Delphi Digital: How to change the new AI economy by parsing the new ElizaOS v2 architecture?
Mar 04, 2025 pm 07:00 PM
ElizaOSv2: Empowering AI and leading the new economy of Web3. AI is evolving from auxiliary tools to independent entities. ElizaOSv2 plays a key role in it, which gives AI the ability to manage funds and operate Web3 businesses. This article will dive into the key innovations of ElizaOSv2 and how it shapes an AI-driven future economy. AI Automation: Going to independently operate ElizaOS was originally an AI framework focusing on Web3 automation. v1 version allows AI to interact with smart contracts and blockchain data, while v2 version achieves significant performance improvements. Instead of just executing simple instructions, AI can independently manage workflows, operate business and develop financial strategies. Architecture upgrade: Enhanced A
 As top market makers enter the crypto market, what impact will Castle Securities have on the industry?
Mar 04, 2025 pm 08:03 PM
As top market makers enter the crypto market, what impact will Castle Securities have on the industry?
Mar 04, 2025 pm 08:03 PM
The entry of top market maker Castle Securities into Bitcoin market maker is a symbol of the maturity of the Bitcoin market and a key step for traditional financial forces to compete for future asset pricing power. At the same time, for retail investors, it may mean the gradual weakening of their voice. On February 25, according to Bloomberg, Citadel Securities is seeking to become a liquidity provider for cryptocurrencies. The company aims to join the list of market makers on various exchanges, including exchanges operated by CoinbaseGlobal, BinanceHoldings and Crypto.com, people familiar with the matter said. Once approved by the exchange, the company initially planned to set up a market maker team outside the United States. This move is not only a sign
 Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Researchers from Shanghai Jiaotong University, Shanghai AILab and the Chinese University of Hong Kong have launched the Visual-RFT (Visual Enhancement Fine Tuning) open source project, which requires only a small amount of data to significantly improve the performance of visual language big model (LVLM). Visual-RFT cleverly combines DeepSeek-R1's rule-based reinforcement learning approach with OpenAI's reinforcement fine-tuning (RFT) paradigm, successfully extending this approach from the text field to the visual field. By designing corresponding rule rewards for tasks such as visual subcategorization and object detection, Visual-RFT overcomes the limitations of the DeepSeek-R1 method being limited to text, mathematical reasoning and other fields, providing a new way for LVLM training. Vis
 Bitwise: Businesses Buy Bitcoin A Neglected Big Trend
Mar 05, 2025 pm 02:42 PM
Bitwise: Businesses Buy Bitcoin A Neglected Big Trend
Mar 05, 2025 pm 02:42 PM
Weekly Observation: Businesses Hoarding Bitcoin – A Brewing Change I often point out some overlooked market trends in weekly memos. MicroStrategy's move is a stark example. Many people may say, "MicroStrategy and MichaelSaylor are already well-known, what are you going to pay attention to?" This is true, but many investors regard it as a special case and ignore the deeper market forces behind it. This view is one-sided. In-depth research on the adoption of Bitcoin as a reserve asset in recent months shows that this is not an isolated case, but a major trend that is emerging. I predict that in the next 12-18 months, hundreds of companies will follow suit and buy large quantities of Bitcoin
