
How does Ethereum Reth achieve 1GB gas per second? We started building Reth in 2022 to provide elasticity for Ethereum L1 while solving the execution layer scaling problem on L2. Today, we’re excited to share how Reth plans to achieve 1GB gas per second L2 throughput in 2024, and our long-term roadmap for how to exceed that goal. We invite the entire ecosystem to join us in pushing the performance frontier and rigorous benchmarking in crypto. Today, the editor of this website will give you a detailed introduction to how Reth achieves 1GB gas per second. Friends who like Ethereum Reth should not miss it!
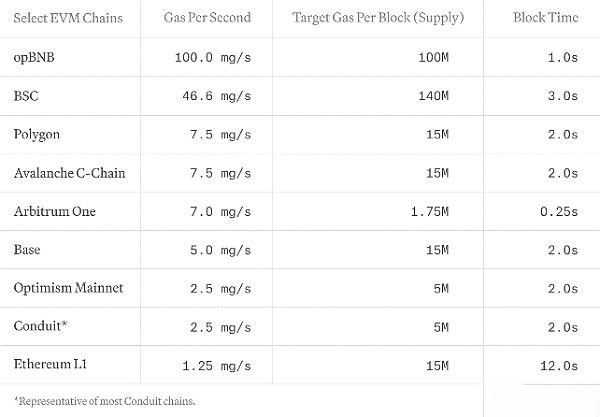
We emphasize gas per second and use it to comprehensively evaluate EVM network performance while capturing computing and storage costs. Networks such as Solana, Sui, or Aptos are not included due to their unique cost models. We encourage efforts to harmonize cost models across all blockchain networks to enable comprehensive and fair comparisons.
We are developing a set of non-stop benchmarking tools for Reth to replicate real workloads. Our requirement for nodes is to comply with the TPC benchmark.
Part of our motivation for creating Reth in 2022 was our desperate need for a client built specifically for web rollups. We believe our path forward is promising.
Reth has reached 100-200MB gas per second during real-time synchronization (including sender recovery, executing transactions and calculating the trie of each block); so, to achieve our short-term goal of 1GB gas per second, it needs to Expand it another 10 times.
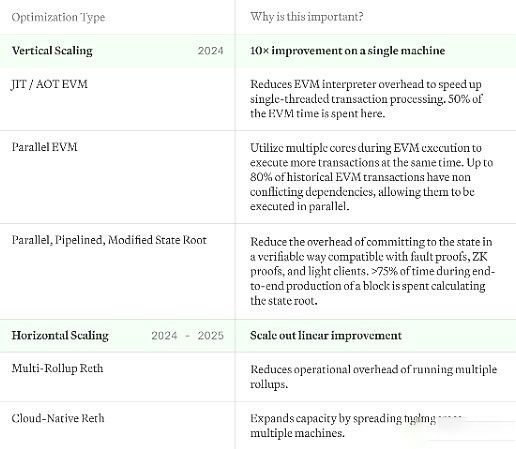
As Reth grows, our expansion plans must find a balance between scalability and efficiency:
Vertical expansion: Our goal is to maximize Utilize every "box" to its full potential. By optimizing how each individual system processes transactions and data, we can greatly improve overall performance while also making individual node operators more efficient.
Horizontal Scaling: Despite optimizations, the sheer transaction volume at web scale exceeds the processing capacity of any single server. To deal with this situation, we considered deploying a horizontal scaling architecture similar to the Kubernetes model of blockchain nodes. This means spreading the workload across multiple systems to ensure that no one node can become a bottleneck.
The optimizations we discuss here will not involve state growth solutions, which we will discuss separately in other articles. Here's an overview of our plans to achieve this:
Throughout the technology stack, we've also optimized IO and CPU using the actor model to support various parts of the stack All can be deployed as a service and have fine-grained control over their use. Finally, we are actively evaluating alternative databases but have not yet finalized one.
Our vertical scaling goal is to maximize the performance and efficiency of the server or laptop running Reth.
(1) Just-In-Time EVM and Ahead-of-Time EVM
In a blockchain environment like Ethereum Virtual Machine (EVM) , execution of bytecode occurs through an interpreter, which processes instructions sequentially. This method will bring some overhead, because the native assembly instructions are not executed directly, but the operation is performed through the VM layer.
Just-in-time (JIT) compilation solves this problem by converting bytecode into native machine code before execution, thereby improving performance by bypassing the VM's interpretation process. This technology can compile contracts into optimized machine code in advance and has been well used in other virtual machines such as Java and WebAssembly.
However, the JIT may be vulnerable to malicious code designed to exploit JIT process vulnerabilities or be too slow to run in real time during execution. Reth will compile the most demanding contracts ahead of time (AOT) and store them on disk, preventing untrusted bytecode from trying to abuse our native code compilation process during live execution.
We have been developing a JIT/AOT compiler for Revm and are currently integrating it with Reth. We will open source it as soon as we complete the benchmarks in the coming weeks. On average, about 50% of the execution time is spent in the EVM interpreter, so about a 2x improvement in EVM execution should be required, but in some cases with greater computational demands, the impact may be greater. Over the next few weeks we will share our benchmarks and integrate our own JIT EVM in Reth.
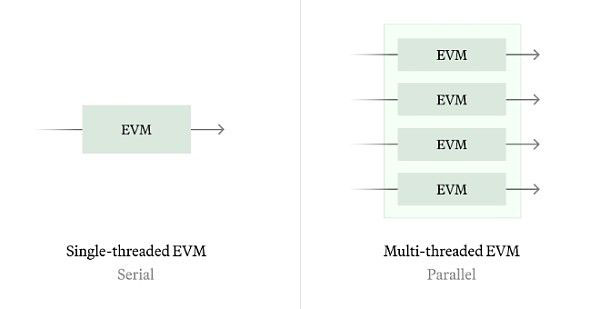
(2) Parallel EVM
The concept of Parallel Ethereum Virtual Machine (Parallel EVM) supports processing of multiple transactions at the same time, which is similar to the traditional EVM serial The execution model is different. We have the following two paths:
Historical synchronization: Historical synchronization allows us to calculate the best possible parallel schedule by analyzing historical transactions and identifying all historical state conflicts.
Real-time synchronization: For real-time synchronization, we can use technology similar to Block STM to perform speculative execution without any additional information (such as access lists). The algorithm performs poorly during periods of severe state contention, so we want to explore switching between serial and parallel execution based on workload conditions, as well as statically predict which storage slots will be accessed to improve parallelism quality.
According to our historical analysis, approximately 80% of Ethereum storage slots are independently accessible, which means that parallelism can increase EVM execution efficiency by 5 times.
(3) Optimizing state commitment
In the Reth model, calculating the state root is a process independent of executing transactions, allowing use without obtaining trie information Standard KV storage. This currently takes >75% of the end-to-end time to seal a block, which is a very exciting area of optimization.
We identified the following two “easy wins” paths to improve state root performance by 2-3x without any protocol changes:
Fully parallelize the state root: Right now we only recompute the storage tree for changed accounts in parallel, but we can go a step further and compute the account tree in parallel while the storage root job completes in the background.
Pipelined state root: During execution, intermediate trie nodes are prefetched from disk by notifying the state root service of the storage slots and accounts involved.
In addition to this, we can also explore some paths forward by deviating from the Ethereum L1 state root activity:
More frequent state root calculations : The state root is not calculated on every block, but once every T blocks. This reduces the total time spent investing in the state root of the entire system, which is probably the simplest and most effective solution.
Tracking the state root: Instead of computing the state root on the same block, let it lag a few blocks behind. This allows execution to advance without blocking state root computation.
Replace RLP encoder & Keccak256: It may be cheaper to merge bytes directly and use a faster hash function (such as Blake3) than to use RLP encoding.
Wider Trie: Increase the N-arity of child nodes of the tree to reduce the increase in IO due to the logN depth of the trie.
A few questions here:
The above changes have a heavy impact on light clients, L2, bridges, coprocessors and other dependent accounts and What are the secondary impacts of protocols that store proofs?
Can we optimize state commitments for SNARK proofs and native execution speed at the same time?
What is the broadest state commitment we can get with our existing tools? What are the secondary effects on witness size?
We will implement many of the above throughout 2024 to achieve the goal of 1GB gas per second.
However, vertical scaling eventually encounters physical and practical limitations. No single machine can handle the world's computing needs. We believe that there are two paths here that can support us to expand by introducing more boxes after the load increases:
(1) Multiple Rollup Reth
Today's L2 stack needs to run multiple Services to trace the chain: L1 CL, L1 EL, L1 -> L2 derived functions (possibly bundled with L2 EL), and L2 EL. While this is great for modularity, things get more complicated when running multiple node stacks. Imagine having to run 100 rollups!
We want to allow rollups to be released simultaneously as Reth evolves and reduce the operational costs of running thousands of rollups to almost zero.
We are already working on this in our Execution Scaling project, with more to come in the coming weeks.
(2) Cloud native Reth
High-performance sorters may have many demands on a single chain, they need to be scaled, and one machine cannot meet their needs. This is not possible with today's single-node deployments.
We hope to support running cloud-native Reth nodes, deploy them as a service stack that can automatically scale based on computing needs, and use seemingly unlimited cloud object storage for persistent storage. This is a common architecture in serverless database projects such as NeonDB, CockroachDB or Amazon Aurora.

We hope to gradually roll out this roadmap to all Reth users. Our mission is to make 1GB gas per second and higher accessible to everyone. We will be testing the optimization on Reth AlphaNet, and we hope people will use Reth as an SDK to build optimized high-performance nodes.
There are some questions we don’t have answers for yet.
How does Reth help improve the performance of the entire L2 ecosystem?
How do we properly measure the worst-case scenarios that may occur with some of our optimizations in general?
How do we deal with potential disagreements between L1 and L2?
We don’t have answers to many of these questions yet, but we have a lot of promising initial ideas that will keep us busy for a while, and we hope to see these efforts take off in the future. Months bear fruit.
The above is the detailed content of An article explaining how Ethereum Reth achieves 1GB gas per second. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



