
 Technology peripherals
AI
Xiaohongshu interprets information retrieval from the memory mechanism and proposes a new paradigm to obtain EACL Oral
Technology peripherals
AI
Xiaohongshu interprets information retrieval from the memory mechanism and proposes a new paradigm to obtain EACL Oral
Xiaohongshu interprets information retrieval from the memory mechanism and proposes a new paradigm to obtain EACL Oral


Recently, the paper "Generative Dense Retrieval: Memory Can Be a Burden" from the Xiaohongshu search algorithm team was accepted by EACL 2024, an international conference in the field of natural language processing. For Oral, the acceptance rate is 11.32% (144/1271).
In their paper, they proposed a novel information retrieval paradigm - Generative Dense Retrieval (GDR). This paradigm can well solve the challenges faced by traditional generative retrieval (GR) when dealing with large-scale data sets. It is inspired by the memory mechanism.
#In past practice, GR relied on its unique memory mechanism to achieve in-depth interaction between queries and document libraries. However, this method that relies on language model autoregressive coding has obvious limitations when processing large-scale data, including fuzzy fine-grained document features, limited document library size, and difficulty in index update.
The GDR proposed by Xiaohongshu adopts a two-stage retrieval idea from coarse to fine. First, it uses the limited memory capacity of the language model to realize the mapping of queries to documents, and then The precise mapping of documents to documents is completed through the vector matching mechanism. GDR effectively alleviates the inherent drawbacks of GR by introducing a vector matching mechanism for dense set retrieval.
In addition, the team also designed a "memory-friendly document cluster identifier construction strategy" and a "document cluster adaptive negative sampling strategy". The retrieval performance of the two stages is improved respectively. Under multiple settings of the Natural Questions data set, GDR not only demonstrated SOTA's Recall@k performance, but also achieved good scalability while retaining the advantages of deep interaction, opening up new possibilities for future research on information retrieval. sex.
1. Background
Text search tools have important research and application value. Traditional search paradigms, such as sparse retrieval (SR) based on word matching and dense retrieval (DR) based on semantic vector matching, although each has its own merits, with the rise of pre-trained language models, based on this The generative retrieval paradigm began to emerge. The beginnings of the generative retrieval paradigm were primarily based on semantic matches between queries and candidate documents. By mapping queries and documents into the same semantic space, the retrieval problem of candidate documents is transformed into a dense retrieval of vector matching degrees. This groundbreaking retrieval paradigm takes advantage of pre-trained language models and brings new opportunities to the field of text search. However, the generative retrieval paradigm still faces challenges. On the one hand, existing pre-training
During the training process, the model uses the given query as the context to autoregressively generate identifiers of relevant documents. This process enables the model to memorize the candidate corpus. After the query enters the model, it interacts with the model parameters and is autoregressively decoded, which implicitly produces deep interaction between the query and the candidate corpus, and this deep interaction is exactly what SR and DR lack. Therefore, GR can show excellent retrieval performance when the model can accurately memorize candidate documents.
Although GR's memory mechanism is not impeccable. Through comparative experiments between the classic DR model (AR2) and the GR model (NCI), we have confirmed that the memory mechanism will bring at least three major challenges:
1) Fine-grained document features Fuzzy:
We separately calculated the probability of an error for NCI and AR2 when decoding each bit of the document identifier from coarse to fine. For AR2, we find the identifier corresponding to the most relevant document for a given query through vector matching, and then count the first error steps of the identifier to obtain the step-by-step decoding error rate corresponding to AR2. As shown in Table 1, NCI performs well in the first half of decoding, while the error rate is higher in the second half, and the opposite is true for AR2. This shows that NCI can better complete the coarse-grained mapping of the semantic space of candidate documents through the overall memory database. However, since the selected features during the training process are determined by search, its fine-grained mapping is difficult to remember accurately, so it performs poorly in fine-grained mapping.

2) The size of the document library is limited:
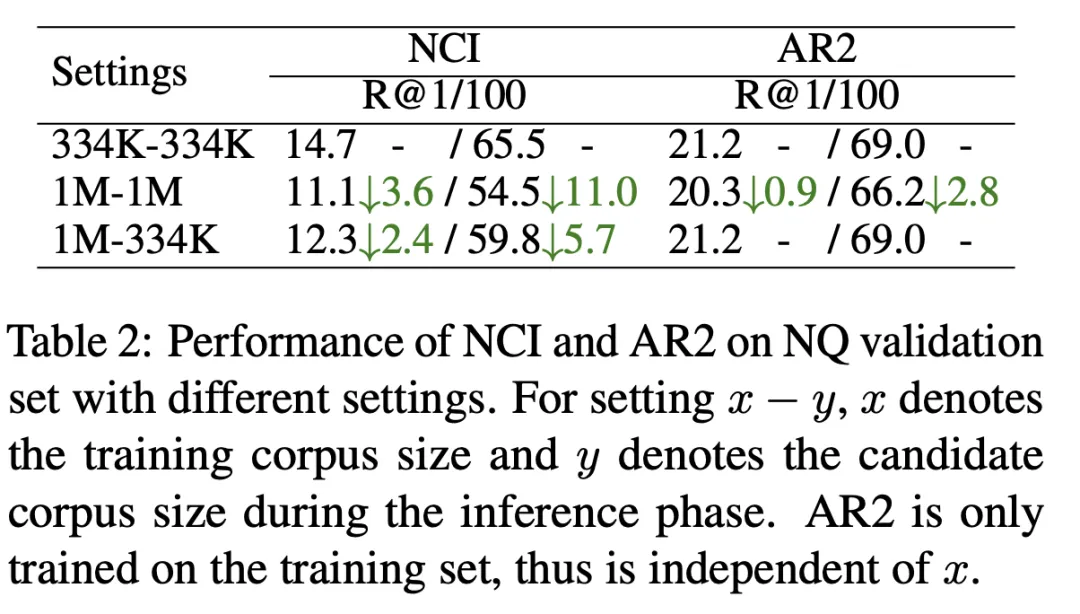
As shown in Table 2, we use 334K candidate document library size (first row) and 1M candidate Document size (second row) NCI model trained and tested with R@k metric. The results show that NCI dropped 11 points on R@100, compared to AR2 which only dropped 2.8 points. In order to explore the reason why NCI performance significantly decreases as the size of the candidate document library increases, we further tested the test results of the NCI model trained on the 1M document library when using 334K as the candidate document library (third row). Compared to the first line, NCI's burden of memorizing more documents results in a significant decrease in its recall performance, indicating that the model's limited memory capacity limits its ability to memorize large-scale candidate document libraries.
3) Index update difficulty:
When new When a document needs to be added to the candidate library, the document identifier needs to be updated, and the model needs to be retrained to re-memorize all documents. Otherwise, outdated mappings (query to document identifier and document identifier to document) will significantly reduce retrieval performance.
The above problems hinder the application of GR in real scenarios. For this reason, after analysis, we believe that the matching mechanism of DR has a complementary relationship with the memory mechanism, so we consider introducing it into GR to retain the memory mechanism while suppressing its disadvantages. We proposed a new paradigm of generative dense retrieval (Generative Dense Retrieval, GDR):
- We designed an overall two-stage retrieval from coarse to fine The framework uses the memory mechanism to achieve inter-cluster matching (mapping of queries to document clusters), and uses the vector matching mechanism to complete intra-cluster matching (mapping of document clusters to documents).
- In order to assist the model in memorizing the candidate document library, we have constructed a memory-friendly document cluster identifier construction strategy, using the model memory capacity as the benchmark to control the division granularity of document clusters and increase inter-cluster matching. Effect.
- In the training phase, we propose an adaptive negative sampling strategy for document clusters based on the characteristics of two-stage retrieval, which enhances the weight of negative samples within the cluster and increases the matching effect within the cluster.
2.1 Inter-cluster matching based on memory mechanism
Taking the query as input, we use the language model Memorize the candidate document library and autoregressively generate k relevant document clusters (CID) to complete the following mapping:
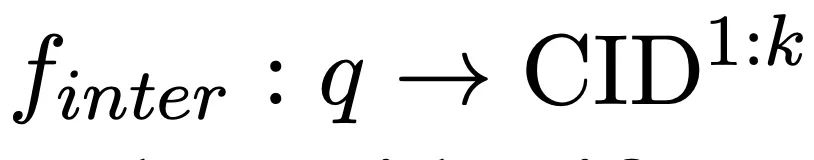
In this process, CID The generation probability is:
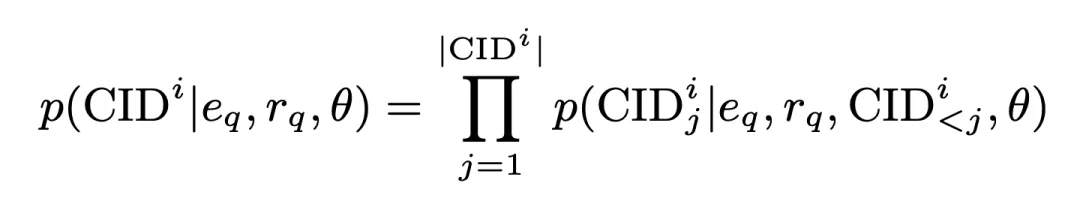
where
is all query embeddings generated by the encoder,
is the one-dimensional query representation produced by the encoder. This probability is also stored as an inter-cluster matching score and participates in subsequent operations. Based on this, we use standard cross-entropy loss to train the model:
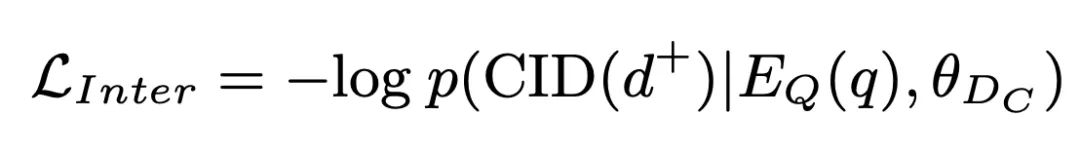
2.2 Intra-cluster matching based on vector matching mechanism
We further retrieve candidate documents from candidate document clusters and complete intra-cluster matching:
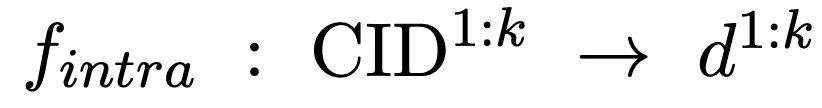
We introduce a document encoder to extract candidate documents Characterization, this process will be completed offline. Based on this, calculate the similarity between the documents in the cluster and the query as the within-cluster matching score:

In this process, NLL loss is used to train the model:
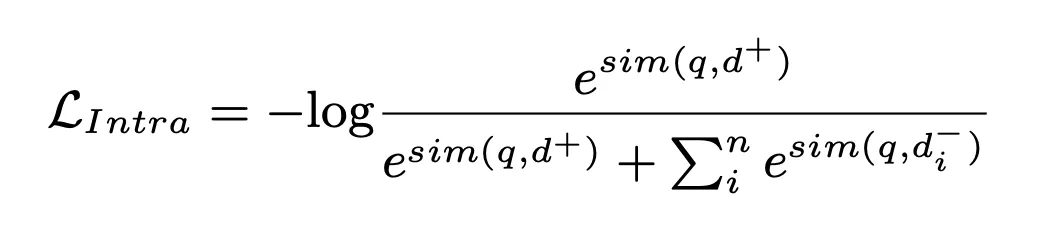
Finally, we calculate the weighted value of the inter-cluster matching score and the intra-cluster matching score of the document and sort them, Select the Top K among them as the retrieved relevant documents:
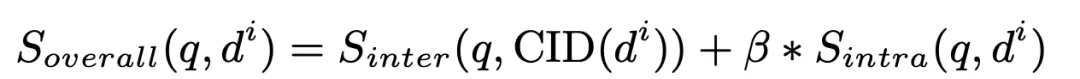
where beta is set to 1 in our experiment.
2.3 Memory-friendly document cluster identifier construction strategy
#In order to make full use of the limited memory capacity of the model to achieve deep interaction between the query and the candidate document library, we propose Memory-friendly document cluster identifier construction strategy. This strategy first uses the model memory capacity as the benchmark to calculate the upper limit of the number of documents in the cluster:
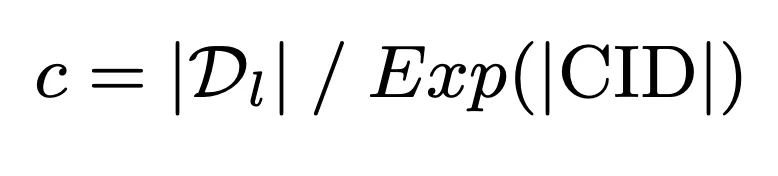
On this basis, it is further constructed through the K-means algorithm Document cluster identifier to ensure that the memory burden of the model does not exceed its memory capacity:

2.4 Negative sampling strategy for document cluster adaptation
The two-stage retrieval framework of GDR determines that the negative samples within the cluster account for a larger proportion during the intra-cluster matching process. To this end, in the second stage of training, we use document cluster division as the benchmark and explicitly enhance the weight of negative samples within the cluster to obtain better intra-cluster matching effect:
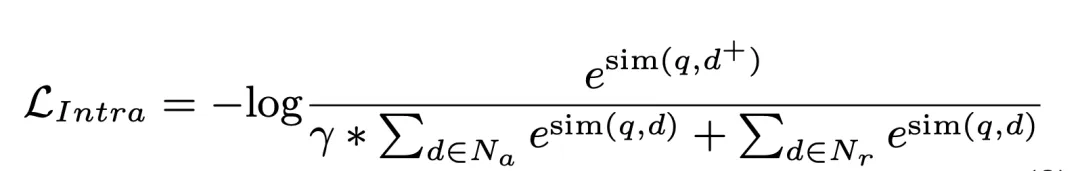
3. Experiment
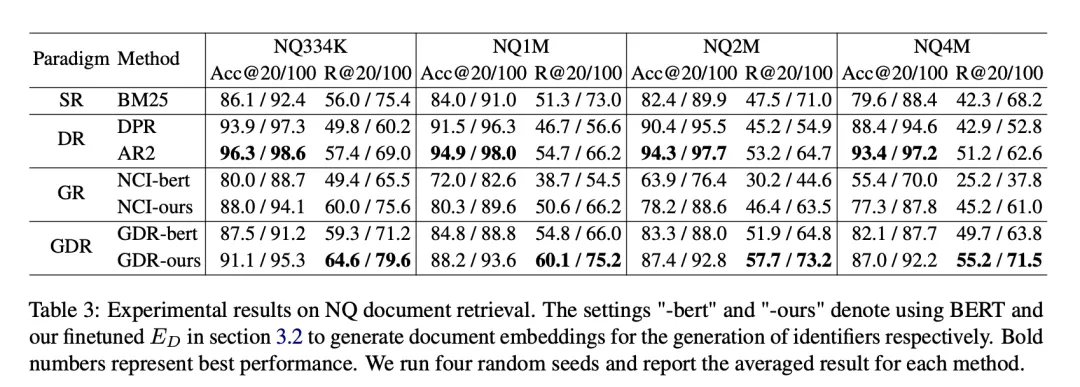
The data set used in the experiment is Natural Questions (NQ), It contains 58K training pairs (query and related documents) and 6K validation pairs, along with a library of 21M candidate documents. Each query has multiple related documents, which places higher requirements on the recall performance of the model. To evaluate the performance of GDR on document bases of different sizes, we constructed different settings such as NQ334K, NQ1M, NQ2M, and NQ4M by adding the remaining passages from the full 21M corpus to NQ334K. GDR generates CIDs on each dataset separately to prevent the semantic information of the larger candidate document library from leaking into the smaller corpus. We adopt BM25 (Anserini implementation) as the SR baseline, DPR and AR2 as the DR baseline, and NCI as the GR baseline. Evaluation metrics include R@k and Acc@k.
3.1 Main Experimental Results
On the NQ data set, GDR improves the R@k indicator by an average of 3.0, while on the Acc@ k index ranks second. This shows that GDR maximizes the advantages of the memory mechanism in deep interaction and the matching mechanism in fine-grained feature discrimination through a coarse-to-fine retrieval process.
3.2 Expansion to a larger corpus
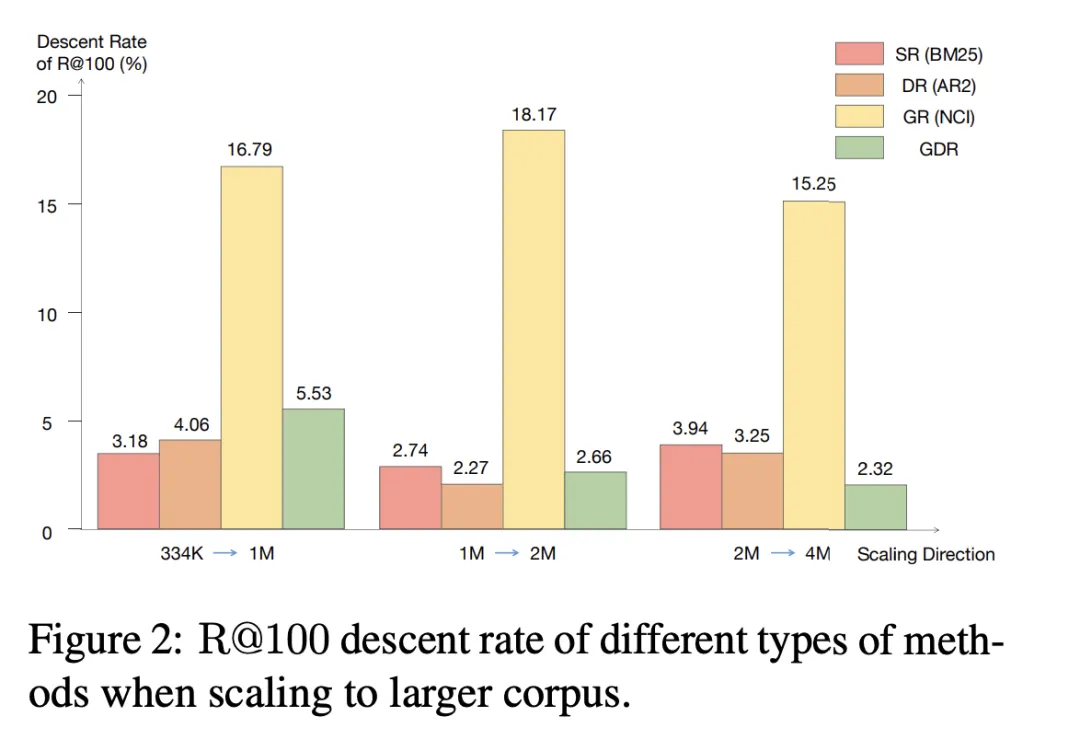
We noticed that when the candidate corpus is expanded to a larger At the scale, the R@100 decrease rate of SR and DR remains below 4.06%, while the decrease rate of GR exceeds 15.25% in all three expansion directions. In contrast, GDR achieves an average R@100 reduction rate of 3.50%, which is similar to SR and DR by focusing the memory content on a fixed volume of corpus coarse-grained features.
3.3 Ablation experiment
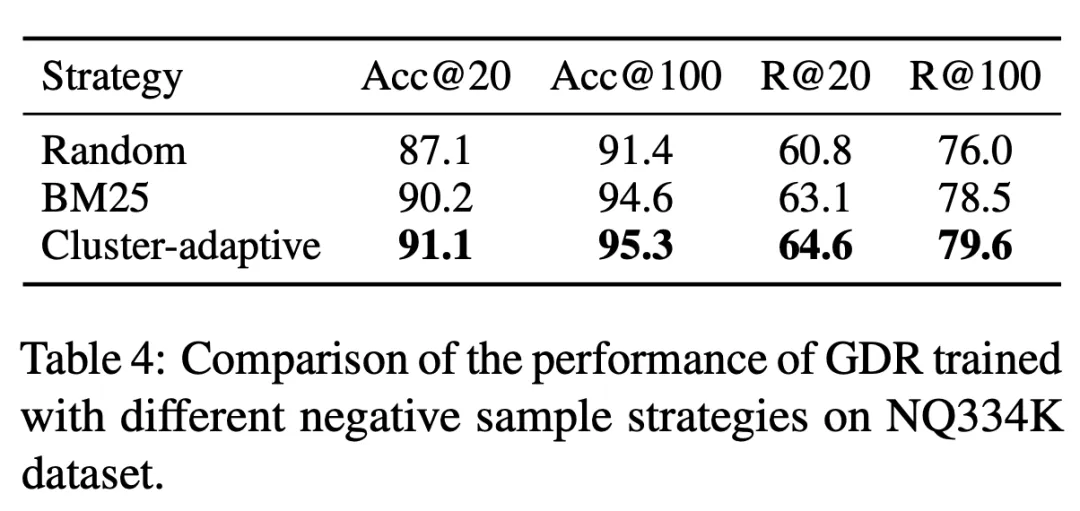
GDR- in Table 3 bert and GDR-ours respectively represent the corresponding model performance under the traditional and our CID construction strategies. Experiments have proven that using a memory-friendly document cluster identifier construction strategy can significantly reduce the memory burden, thereby leading to better retrieval performance. In addition, Table 4 shows that the document cluster adaptive negative sampling strategy used in GDR training enhances fine-grained matching capabilities by providing more discriminative signals within document clusters.
3.4 New document added
When there is a new document When adding the candidate document library, GDR adds the new document to the nearest document cluster cluster center and assigns it a corresponding identifier. At the same time, the document encoder extracts the vector representation and updates the vector index, thereby completing the rapid expansion of new documents. As shown in Table 6, in the setting of adding new documents to the candidate corpus, NCI's R@100 drops by 18.3 percentage points, while GDR's performance only drops by 1.9 percentage points. This shows that GDR alleviates the difficult scalability of the memory mechanism by introducing a matching mechanism and maintains good recall effects without retraining the model.
3.5 Limitations
Limited by the characteristics of language model autoregressive generation, although GDR introduces a vector matching mechanism in the second stage, compared with GR, it achieves The retrieval efficiency is significantly improved, but there is still a large room for improvement compared to DR and SR. We look forward to more research in the future to help alleviate the delay problem caused by the introduction of memory mechanisms into the retrieval framework.
4. Conclusion
In this study, we deeply explored the dual role of memory mechanism in information retrieval. Blade effect: On the one hand, this mechanism realizes in-depth interaction between the query and the candidate document library, making up for the shortcomings of intensive retrieval; on the other hand, the limited memory capacity of the model and the complexity of updating the index make it difficult to deal with large-scale and dynamic problems. It is difficult to change the candidate document library. In order to solve this problem, we innovatively combine the memory mechanism and the vector matching mechanism in a hierarchical manner to achieve the effect of leveraging the strengths and avoiding weaknesses of the two and complementing each other.
# We propose a new text retrieval paradigm, Generative Dense Retrieval (GDR). GDR This paradigm performs a two-stage retrieval from coarse to fine for a given query. First, the memory mechanism autoregressively generates document cluster identifiers to map the query to document clusters, and then uses vector matching. The mechanism calculates the similarity between the query and the document to complete the mapping of document clusters to documents.
The memory-friendly document cluster identifier construction strategy ensures that the memory burden of the model does not exceed its memory capacity and improves the inter-cluster matching effect. The document cluster adaptive negative sampling strategy enhances the training signal for distinguishing negative samples within the cluster and increases the matching effect within the cluster. Extensive experiments have proven that GDR can achieve excellent retrieval performance on large-scale candidate document libraries and can efficiently respond to document library updates.
As a successful attempt to integrate the advantages of traditional retrieval methods, the generative intensive retrieval paradigm has good recall performance, strong scalability, and robust performance in scenarios with massive candidate document libraries. advantage. As large language models continue to improve in their understanding and generation capabilities, the performance of generative intensive retrieval will be further improved, opening up a broader world for information retrieval.
Paper address: https://www.php.cn/link/9e69fd6d1c5d1cef75ffbe159c1f322e
5. Author introduction
-
Yuan Peiwen
Currently studying as a Ph.D. student at Beijing Institute of Technology, and an intern in the Xiaohongshu community search team. He has published many first-author papers in NeurIPS, ICLR, AAAI, EACL, etc. The main research directions are large language model reasoning and evaluation, and information retrieval. -
王Xinglin
##Now a Ph.D. student at Beijing Institute of Technology, Xiaohong An intern in the book community search team, he published several papers in EACL, NeurIPS, ICLR, etc., and won the second place in the evaluation track at the International Dialogue Technology Challenge DSTC11. The main research directions are large language model reasoning and evaluation, and information retrieval. -
Feng Shaoxiong
Responsible for Xiaohongshu community search vector recall. Graduated from Beijing Institute of Technology with a Ph.D., he has published several papers in top conferences/journals in the field of machine learning and natural language processing such as ICLR, AAAI, ACL, EMNLP, NAACL, EACL, KBS, etc. The main research directions include large language model evaluation, inference distillation, generative retrieval, open domain dialogue generation, etc. -
Daoxuan
Head of the Xiaohongshu transaction search team. Graduated from Zhejiang University with a Ph.D., he has published several first-author papers at top conferences in the field of machine learning such as NeurIPS and ICML, and has been a reviewer for many top conferences/journals for a long time. The main business covers content search, e-commerce search, live broadcast search, etc. - ##Zeng Shu# graduated from the Department of Electronics of Tsinghua University with a master's degree and is engaged in natural language processing, recommendation, search and other related fields in the Internet field Algorithm work in the direction of Xiaohongshu Community Search is currently responsible for technical directions such as recall and vertical search.
The above is the detailed content of Xiaohongshu interprets information retrieval from the memory mechanism and proposes a new paradigm to obtain EACL Oral. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Understand Tokenization in one article!
Apr 12, 2024 pm 02:31 PM
Understand Tokenization in one article!
Apr 12, 2024 pm 02:31 PM
Language models reason about text, which is usually in the form of strings, but the input to the model can only be numbers, so the text needs to be converted into numerical form. Tokenization is a basic task of natural language processing. It can divide a continuous text sequence (such as sentences, paragraphs, etc.) into a character sequence (such as words, phrases, characters, punctuation, etc.) according to specific needs. The units in it Called a token or word. According to the specific process shown in the figure below, the text sentences are first divided into units, then the single elements are digitized (mapped into vectors), then these vectors are input to the model for encoding, and finally output to downstream tasks to further obtain the final result. Text segmentation can be divided into Toke according to the granularity of text segmentation.
 Three secrets for deploying large models in the cloud
Apr 24, 2024 pm 03:00 PM
Three secrets for deploying large models in the cloud
Apr 24, 2024 pm 03:00 PM
Compilation|Produced by Xingxuan|51CTO Technology Stack (WeChat ID: blog51cto) In the past two years, I have been more involved in generative AI projects using large language models (LLMs) rather than traditional systems. I'm starting to miss serverless cloud computing. Their applications range from enhancing conversational AI to providing complex analytics solutions for various industries, and many other capabilities. Many enterprises deploy these models on cloud platforms because public cloud providers already provide a ready-made ecosystem and it is the path of least resistance. However, it doesn't come cheap. The cloud also offers other benefits such as scalability, efficiency and advanced computing capabilities (GPUs available on demand). There are some little-known aspects of deploying LLM on public cloud platforms
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Efficient parameter fine-tuning of large-scale language models--BitFit/Prefix/Prompt fine-tuning series
Oct 07, 2023 pm 12:13 PM
Efficient parameter fine-tuning of large-scale language models--BitFit/Prefix/Prompt fine-tuning series
Oct 07, 2023 pm 12:13 PM
In 2018, Google released BERT. Once it was released, it defeated the State-of-the-art (Sota) results of 11 NLP tasks in one fell swoop, becoming a new milestone in the NLP world. The structure of BERT is shown in the figure below. On the left is the BERT model preset. The training process, on the right is the fine-tuning process for specific tasks. Among them, the fine-tuning stage is for fine-tuning when it is subsequently used in some downstream tasks, such as text classification, part-of-speech tagging, question and answer systems, etc. BERT can be fine-tuned on different tasks without adjusting the structure. Through the task design of "pre-trained language model + downstream task fine-tuning", it brings powerful model effects. Since then, "pre-training language model + downstream task fine-tuning" has become the mainstream training in the NLP field.
 RoSA: A new method for efficient fine-tuning of large model parameters
Jan 18, 2024 pm 05:27 PM
RoSA: A new method for efficient fine-tuning of large model parameters
Jan 18, 2024 pm 05:27 PM
As language models scale to unprecedented scale, comprehensive fine-tuning for downstream tasks becomes prohibitively expensive. In order to solve this problem, researchers began to pay attention to and adopt the PEFT method. The main idea of the PEFT method is to limit the scope of fine-tuning to a small set of parameters to reduce computational costs while still achieving state-of-the-art performance on natural language understanding tasks. In this way, researchers can save computing resources while maintaining high performance, bringing new research hotspots to the field of natural language processing. RoSA is a new PEFT technique that, through experiments on a set of benchmarks, is found to outperform previous low-rank adaptive (LoRA) and pure sparse fine-tuning methods using the same parameter budget. This article will go into depth
 Meta launches AI language model LLaMA, a large-scale language model with 65 billion parameters
Apr 14, 2023 pm 06:58 PM
Meta launches AI language model LLaMA, a large-scale language model with 65 billion parameters
Apr 14, 2023 pm 06:58 PM
According to news on February 25, Meta announced on Friday local time that it will launch a new large-scale language model based on artificial intelligence (AI) for the research community, joining Microsoft, Google and other companies stimulated by ChatGPT to join artificial intelligence. Intelligent competition. Meta's LLaMA is the abbreviation of "Large Language Model MetaAI" (LargeLanguageModelMetaAI), which is available under a non-commercial license to researchers and entities in government, community, and academia. The company will make the underlying code available to users, so they can tweak the model themselves and use it for research-related use cases. Meta stated that the model’s requirements for computing power
 Conveniently trained the biggest ViT in history? Google upgrades visual language model PaLI: supports 100+ languages
Apr 12, 2023 am 09:31 AM
Conveniently trained the biggest ViT in history? Google upgrades visual language model PaLI: supports 100+ languages
Apr 12, 2023 am 09:31 AM
The progress of natural language processing in recent years has largely come from large-scale language models. Each new model released pushes the amount of parameters and training data to new highs, and at the same time, the existing benchmark rankings will be slaughtered. ! For example, in April this year, Google released the 540 billion-parameter language model PaLM (Pathways Language Model), which successfully surpassed humans in a series of language and reasoning tests, especially its excellent performance in few-shot small sample learning scenarios. PaLM is considered to be the development direction of the next generation language model. In the same way, visual language models actually work wonders, and performance can be improved by increasing the scale of the model. Of course, if it is just a multi-tasking visual language model
 BLOOM can create a new culture for AI research, but challenges remain
Apr 09, 2023 pm 04:21 PM
BLOOM can create a new culture for AI research, but challenges remain
Apr 09, 2023 pm 04:21 PM
Translator | Reviewed by Li Rui | Sun Shujuan BigScience research project recently released a large language model BLOOM. At first glance, it looks like another attempt to copy OpenAI's GPT-3. But what sets BLOOM apart from other large-scale natural language models (LLMs) is its efforts to research, develop, train, and release machine learning models. In recent years, large technology companies have hidden large-scale natural language models (LLMs) like strict trade secrets, and the BigScience team has put transparency and openness at the center of BLOOM from the beginning of the project. The result is a large-scale language model that can be studied and studied, and made available to everyone. B
