
 Technology peripherals
AI
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Technology peripherals
AI
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source

FP8 and lower floating point quantification precision are no longer the "patent" of H100!
Lao Huang wanted everyone to use INT8/INT4, but the Microsoft DeepSpeed team forcedly started running FP6 on A100 without official support from NVIDIA.
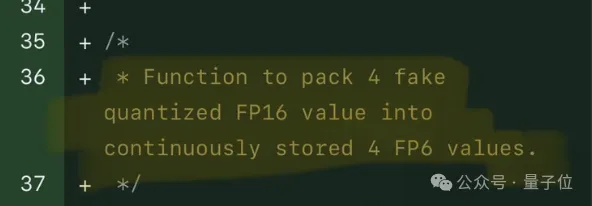
Test results show that the new method TC-FPx’s FP6 quantization speed on A100 is close to or even occasionally exceeding INT4, and has better performance than the latter High precision.
On this basis, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed.
This result also has an immediate effect on the acceleration of large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards.
After reading it, a machine learning researcher said that Microsoft’s research can be described as crazy.
emoticons were also launched immediately, be like:
NVIDIA: Only H100 supports FP8.
Microsoft: Fine, I’ll do it myself.

#So, what kind of effects can this framework achieve, and what kind of technology is used behind it?
Use FP6 to run Llama, a single card is faster than dual cards
Using FP6 precision on A100 brings kernel-level performance improvement.
The researchers selected linear layers in Llama models and OPT models of different sizes, and tested them using CUDA 11.8 on the NVIDIA A100-40GB GPU platform.
The results are compared to NVIDIA's official cuBLAS(W16A16) and TensorRT-LLM(W8A16), TC-FPx(W6A16) is faster The maximum value of degree improvement is 2.6 times and 1.9 times respectively.
Compared with the 4bit BitsandBytes(W4A16) method, the maximum speed increase of TC-FPx is 8.9 times.
(W and A represent the weight quantization bit width and activation quantization bit width respectively)
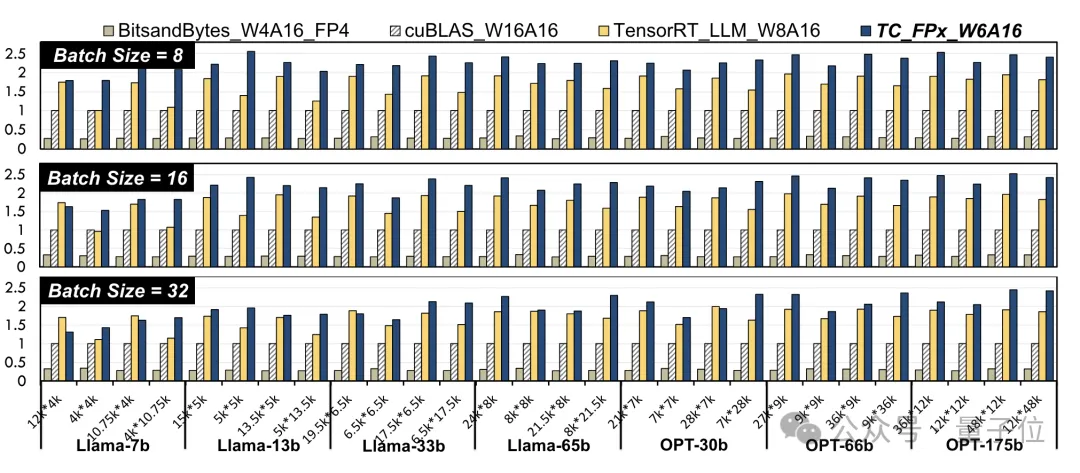
△Normalized data, with The cuBLAS result is 1
At the same time, the TC-FPx core also reduces access to DRAM memory and improves DRAM bandwidth utilization and Tensor Cores utilization, as well as ALU and FMA unit utilization.
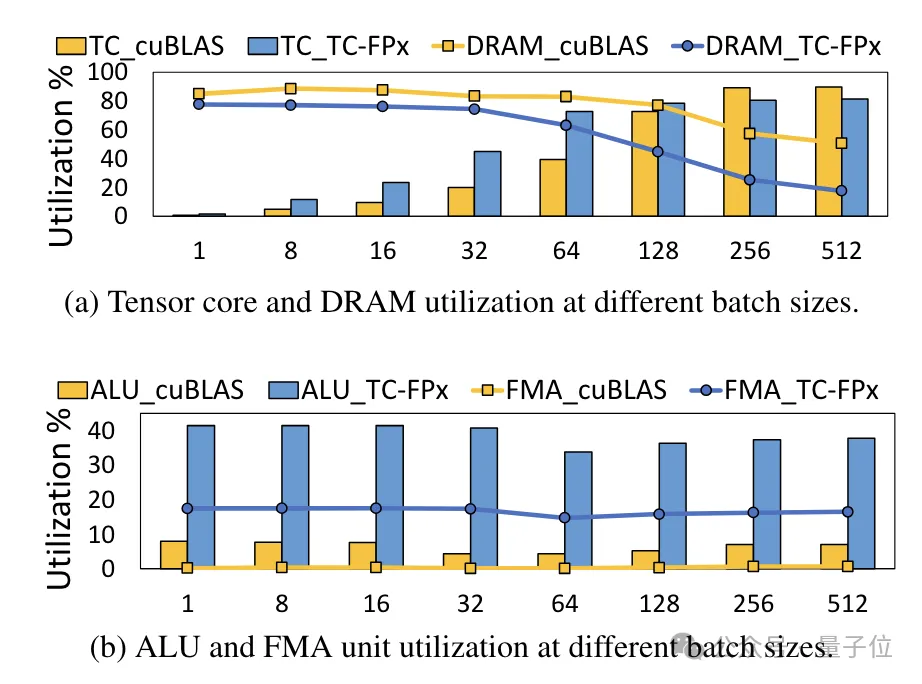
The end-to-end inference framework FP6-LLM designed on the basis of TC-FPx also brings benefits to large models. Comes significant performance improvements. Taking Llama-70B as an example, the throughput of using FP6-LLM on a single card is 2.65 times higher than that of FP16 on dual cards, and the latency in batch sizes below 16 is also lower. In FP16.
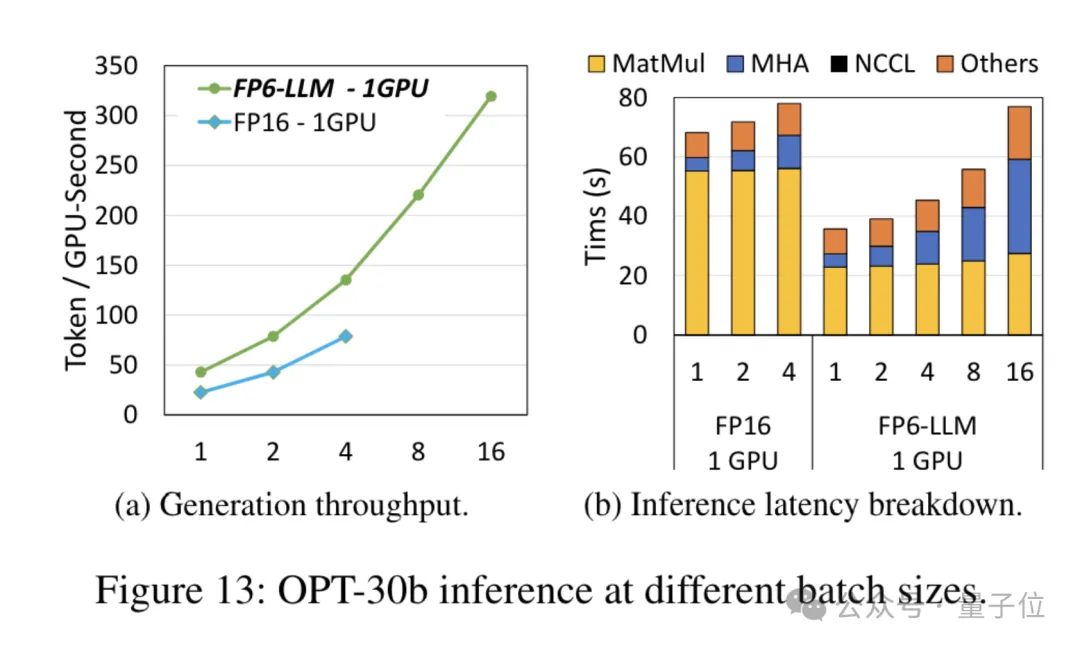
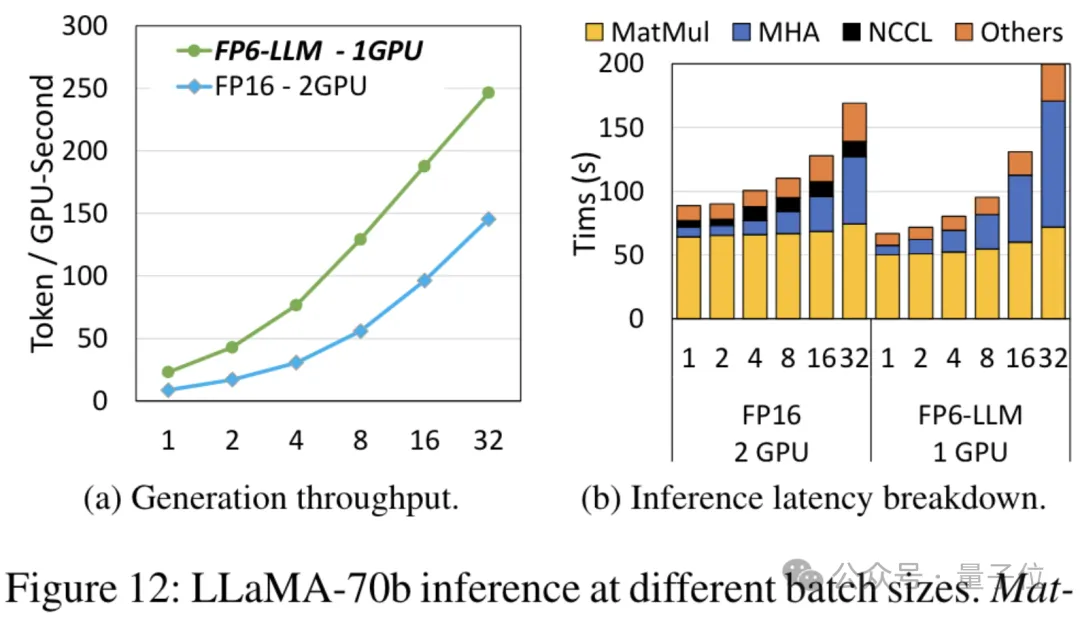 As for the model OPT-30B with a smaller number of parameters (FP16 also uses a single card), FP6-LLM also brings significant throughput improvement and latency reduction.
As for the model OPT-30B with a smaller number of parameters (FP16 also uses a single card), FP6-LLM also brings significant throughput improvement and latency reduction.
Moreover, the maximum batch size supported by a single card FP16 under this condition is only 4, but FP6-LLM can operate normally with a batch size of 16.
 So, how did the Microsoft team realize FP16 quantification running on A100?
So, how did the Microsoft team realize FP16 quantification running on A100?
Redesign the kernel solution
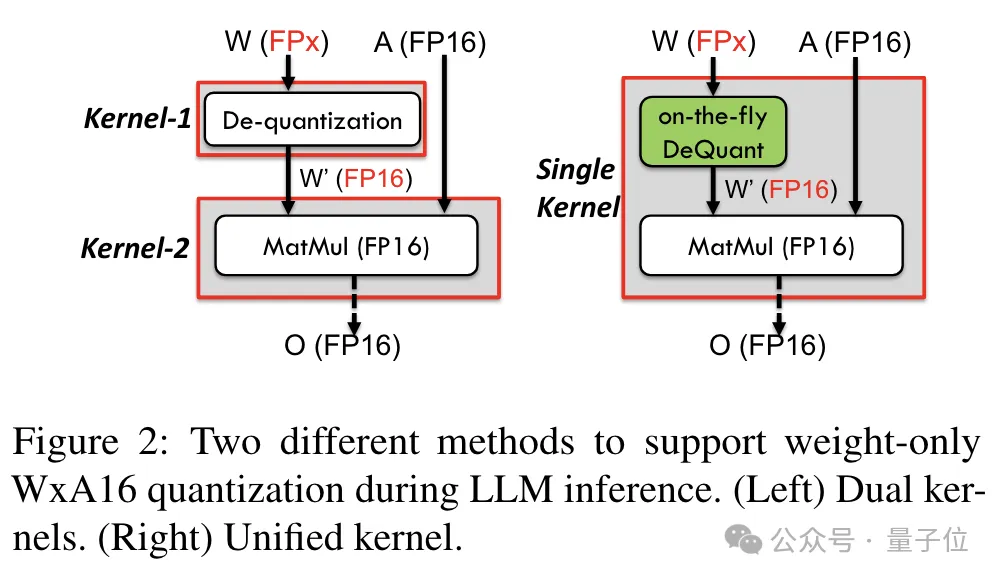
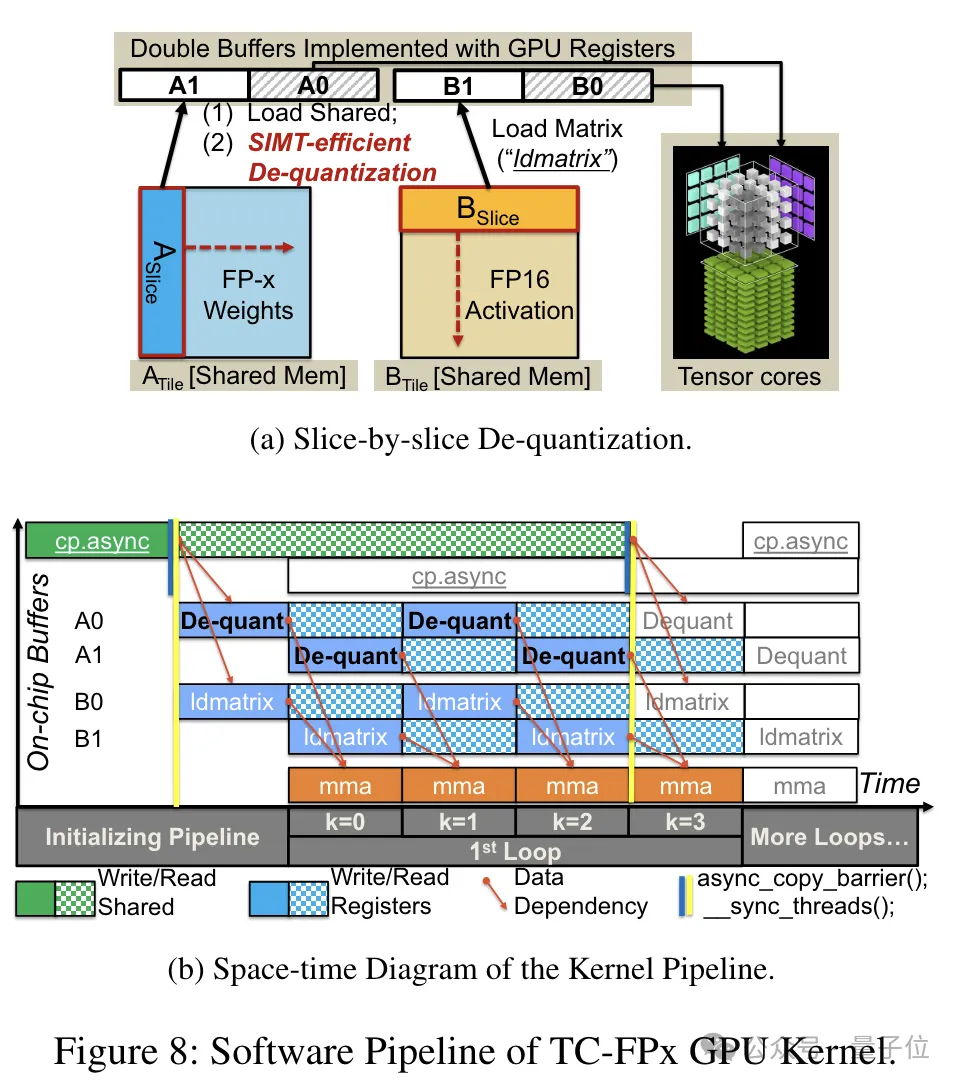
In order to support precision including 6bit, the TC-FPx team designed a unified kernel solution that can support quantization weights of different bit widths.
Compared with the traditional dual-core method, TC-FPx reduces the number of memory accesses and improves performance by integrating dequantization and matrix multiplication in a single core.
The core secret of achieving low-precision quantization is to "disguise" FP6-precision data as FP16 through de-quantization, and then hand it over to the GPU for calculation in the FP16 format.
At the same time, the team also used bit-level pre-packaging technology to solve the problem of GPU memory system for non-power of 2 bit width (such as 6 -bit) unfriendly question.
Specifically, bit-level pre-packing is the reorganization of weight data before model inference, including rearranging 6-bit quantized weights so that they can be accessed in a GPU memory system-friendly manner.
In addition, since GPU memory systems usually access data in 32-bit or 64-bit blocks, bit-level pre-packing technology will also pack 6-bit weights so that they can be stored in the form of these aligned blocks. and access.

After the pre-packaging is completed, the research team uses the parallel processing capabilities of the SIMT core to perform parallel dequantization on the FP6 weights in the register to generate weights in FP16 format.
The dequantized FP16 weights are reconstructed in the register and then sent to the Tensor Core. The reconstructed FP16 weights are used to perform matrix multiplication operations to complete the calculation of the linear layer.
In this process, the team took advantage of the bit-level parallelism of the SMIT core to improve the efficiency of the entire dequantization process.
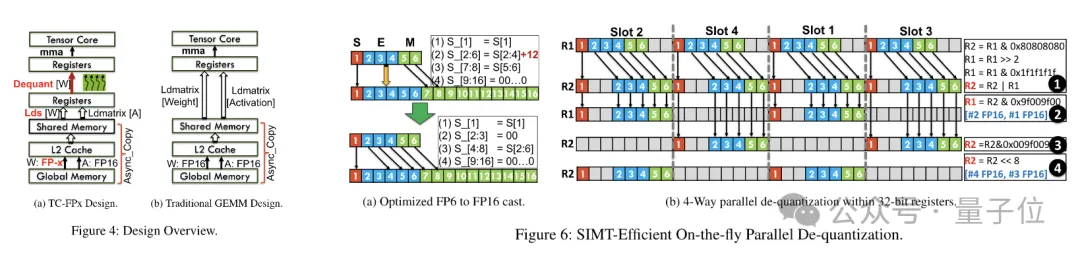
In order to enable the weight reconstruction task to run in parallel, the team also used a parallel weight splicing technology.
Specifically, each weight is divided into several parts, and the bit width of each part is a power of 2 (such as dividing 6 into 2 4 or 4 2) .
Before dequantizing, the weights are first loaded into registers from shared memory. Since each weight is split into multiple parts, the complete weight needs to be reconstructed at the register level at runtime.
In order to reduce runtime overhead, TC-FPx proposes a method of parallel extraction and splicing of weights. This approach uses two sets of registers to store segments of 32 FP6 weights, reconstructing these weights in parallel.
At the same time, in order to extract and splice weights in parallel, it is necessary to ensure that the initial data layout meets specific order requirements, so TC-FPx rearranges the weight fragments before running.
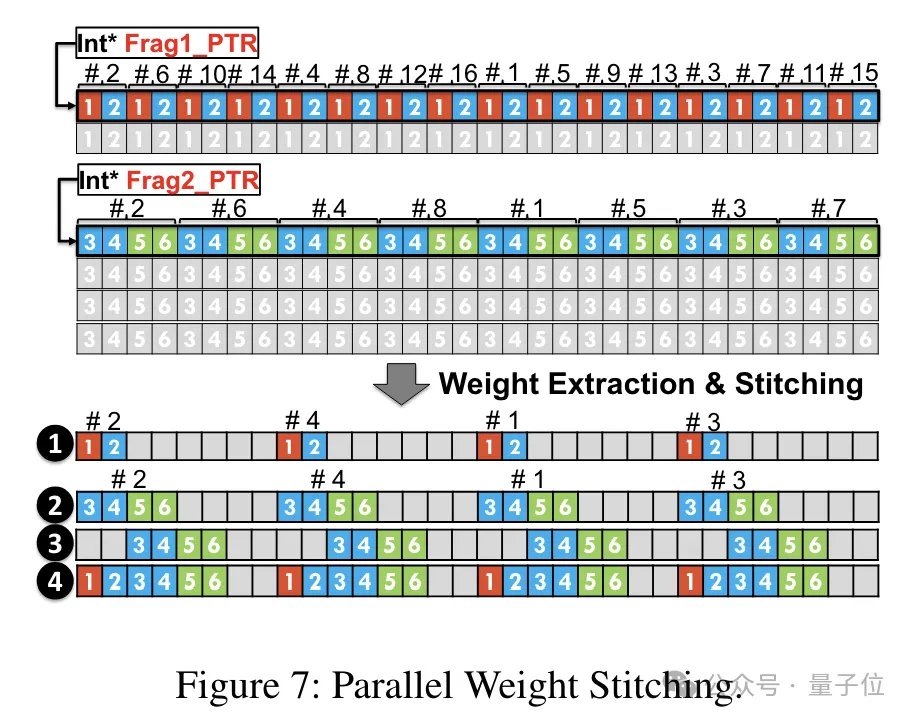
In addition, TC-FPx also designed a software pipeline, which combines the dequantization step with the matrix multiplication operation of Tensor Core Together, the overall execution efficiency is improved through instruction-level parallelism.
Paper address: https://arxiv.org/abs/2401.14112
The above is the detailed content of Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Do I need to use flexbox in the center of the Bootstrap picture?
Apr 07, 2025 am 09:06 AM
Do I need to use flexbox in the center of the Bootstrap picture?
Apr 07, 2025 am 09:06 AM
There are many ways to center Bootstrap pictures, and you don’t have to use Flexbox. If you only need to center horizontally, the text-center class is enough; if you need to center vertically or multiple elements, Flexbox or Grid is more suitable. Flexbox is less compatible and may increase complexity, while Grid is more powerful and has a higher learning cost. When choosing a method, you should weigh the pros and cons and choose the most suitable method according to your needs and preferences.
 How to calculate c-subscript 3 subscript 5 c-subscript 3 subscript 5 algorithm tutorial
Apr 03, 2025 pm 10:33 PM
How to calculate c-subscript 3 subscript 5 c-subscript 3 subscript 5 algorithm tutorial
Apr 03, 2025 pm 10:33 PM
The calculation of C35 is essentially combinatorial mathematics, representing the number of combinations selected from 3 of 5 elements. The calculation formula is C53 = 5! / (3! * 2!), which can be directly calculated by loops to improve efficiency and avoid overflow. In addition, understanding the nature of combinations and mastering efficient calculation methods is crucial to solving many problems in the fields of probability statistics, cryptography, algorithm design, etc.
 Can mysql and mariadb coexist
Apr 08, 2025 pm 02:27 PM
Can mysql and mariadb coexist
Apr 08, 2025 pm 02:27 PM
MySQL and MariaDB can coexist, but need to be configured with caution. The key is to allocate different port numbers and data directories to each database, and adjust parameters such as memory allocation and cache size. Connection pooling, application configuration, and version differences also need to be considered and need to be carefully tested and planned to avoid pitfalls. Running two databases simultaneously can cause performance problems in situations where resources are limited.
 How to implement adaptive layout of Y-axis position in web annotation?
Apr 04, 2025 pm 11:30 PM
How to implement adaptive layout of Y-axis position in web annotation?
Apr 04, 2025 pm 11:30 PM
The Y-axis position adaptive algorithm for web annotation function This article will explore how to implement annotation functions similar to Word documents, especially how to deal with the interval between annotations...
 distinct function usage distance function c usage tutorial
Apr 03, 2025 pm 10:27 PM
distinct function usage distance function c usage tutorial
Apr 03, 2025 pm 10:27 PM
std::unique removes adjacent duplicate elements in the container and moves them to the end, returning an iterator pointing to the first duplicate element. std::distance calculates the distance between two iterators, that is, the number of elements they point to. These two functions are useful for optimizing code and improving efficiency, but there are also some pitfalls to be paid attention to, such as: std::unique only deals with adjacent duplicate elements. std::distance is less efficient when dealing with non-random access iterators. By mastering these features and best practices, you can fully utilize the power of these two functions.
 How to elegantly solve the problem of too small spacing of Span tags after a line break?
Apr 05, 2025 pm 06:00 PM
How to elegantly solve the problem of too small spacing of Span tags after a line break?
Apr 05, 2025 pm 06:00 PM
How to elegantly handle the spacing of Span tags after a new line In web page layout, you often encounter the need to arrange multiple spans horizontally...
 How to make the height of adjacent columns in the Element UI automatically adapt to the content?
Apr 05, 2025 am 06:12 AM
How to make the height of adjacent columns in the Element UI automatically adapt to the content?
Apr 05, 2025 am 06:12 AM
How to make the height of adjacent columns of the same row automatically adapt to the content? In web design, we often encounter this problem: when there are many in a table or row...
 How to center images in containers for Bootstrap
Apr 07, 2025 am 09:12 AM
How to center images in containers for Bootstrap
Apr 07, 2025 am 09:12 AM
Overview: There are many ways to center images using Bootstrap. Basic method: Use the mx-auto class to center horizontally. Use the img-fluid class to adapt to the parent container. Use the d-block class to set the image to a block-level element (vertical centering). Advanced method: Flexbox layout: Use the justify-content-center and align-items-center properties. Grid layout: Use the place-items: center property. Best practice: Avoid unnecessary nesting and styles. Choose the best method for the project. Pay attention to the maintainability of the code and avoid sacrificing code quality to pursue the excitement
