
 Technology peripherals
AI
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Technology peripherals
AI
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks

Cry to death, the whole world is crazy about making big models, the data on the Internet is not enough, not enough at all.
The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these big data eaters.
This problem is particularly prominent in multi-modal tasks. When
was at a loss, the start-up team from the Department of Renmin University used its own new model to take the lead in China in turning "model-generated data to feed itself" into Reality.
Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself.
What is the model?
The multi-modal large model Awaker 1.0 just appeared on the Zhongguancun Forum. Who is the team?
Sophon engine. was founded by Gao Yizhao, a doctoral student at the Hillhouse School of Artificial Intelligence at Renmin University of China, with Professor Lu Zhiwu from the Hillhouse School of Artificial Intelligence serving as a consultant. When the company was founded in 2021, it entered the "no man's land" track of multi-modality early. MOE architecture, solving the conflict problem of multi-modal and multi-task training
This is not the first time that Sophon Engine has released a model.
On March 8 last year, the team that has devoted two years of research and development released the first self-developed multi-modal model, the ChatImg sequence model with tens of billions of parameters, and launched the world's first public evaluation based on this. Multimodal conversation application ChatImg
(元 multiply image). Later, ChatImg continued to iterate, and the research and development of the new model Awaker was also advanced in parallel. The latter also inherits the basic capabilities of the previous model.
Compared with the previous generation ChatImg sequence model, Awaker 1.0
adopts the MoE model architecture. The reason is that we want to solve the problem of serious conflicts in multi-modal and multi-task training.
Using the MoE model architecture, it can better learn multi-modal general capabilities and the unique capabilities required for each task, thereby further improving the capabilities of the entire Awaker 1.0 on multiple tasks.
Data is worth a thousand words:
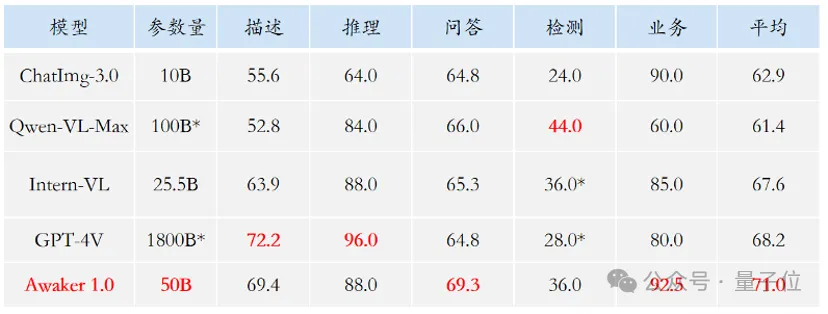 In view of the problem of evaluation data leakage in mainstream multi-modal evaluation lists, the Sophon team strictly constructed its own evaluation set. Most of the test images come from personal mobile phone photo albums.
In view of the problem of evaluation data leakage in mainstream multi-modal evaluation lists, the Sophon team strictly constructed its own evaluation set. Most of the test images come from personal mobile phone photo albums.
The table shows that the team evaluated Awaker 1.0 and the three most advanced multi-modal large models at home and abroad.
One more thing to mention, since GPT-4V and Intern-VL do not directly support detection tasks, their detection results are obtained by requiring the model to use language to describe the orientation of the object.
It can be seen that in visual question answering and business application tasks, the base model of Awaker 1.0 exceeds GPT-4V, Qwen-VL-Max and Intern-VL.
The base model of Awaker 1.0 achieved the second-best results on description, reasoning, and detection tasks.
Finally, looking at the average score, Awaker 1.0 has the highest value among them.
Therefore, the above results also confirm the effectiveness of the multi-task multi-modal model using the MoE architecture.
The data set evaluation results are available, but the real effect needs to be further experienced.
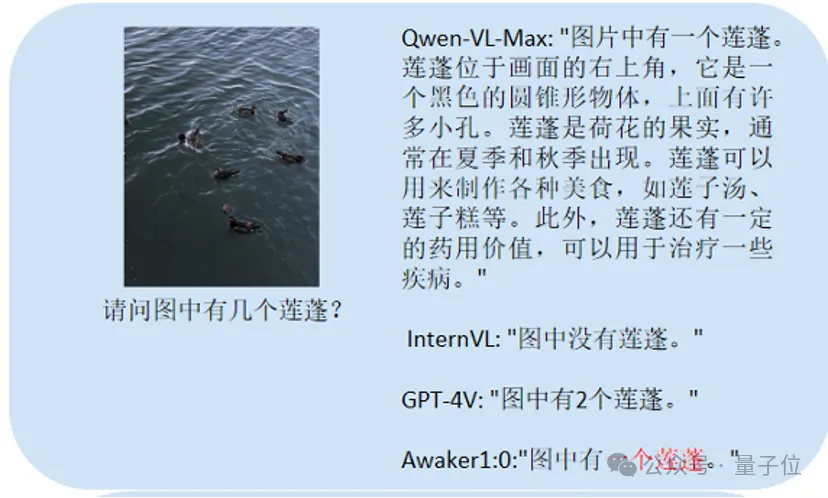
Here we mainly ask some questions about Chinese OCR
(picture text recognition)and counting issues, detailed description tasks, etc. compared with the large model. This main
test count:Awaker 1.0 can give the correct answer, while the other three models all answer incorrectly.
 This main test
This main test
Chinese OCR:The players who answered correctly are Qwen-VL-Max and Awaker 1.0.
 The last question tests the understanding of the
The last question tests the understanding of the
picture content. GPT-4V and Awaker 1.0 can not only describe the content of the picture in detail, but also accurately identify the details in the picture, such as Coca-Cola shown in the picture.
 It must be mentioned that Awaker 1.0 inherits some of the research results that the Sophon team has previously received much attention from.
It must be mentioned that Awaker 1.0 inherits some of the research results that the Sophon team has previously received much attention from.
I’m talking about you - the
generated side of Awaker 1.0. The generation side of Awaker 1.0 is the Sora-like video generation base VDT
(Video Diffusion Transformer)independently developed by Sophon Engine. VDT's academic paper preceded the release of OpenAI Sora
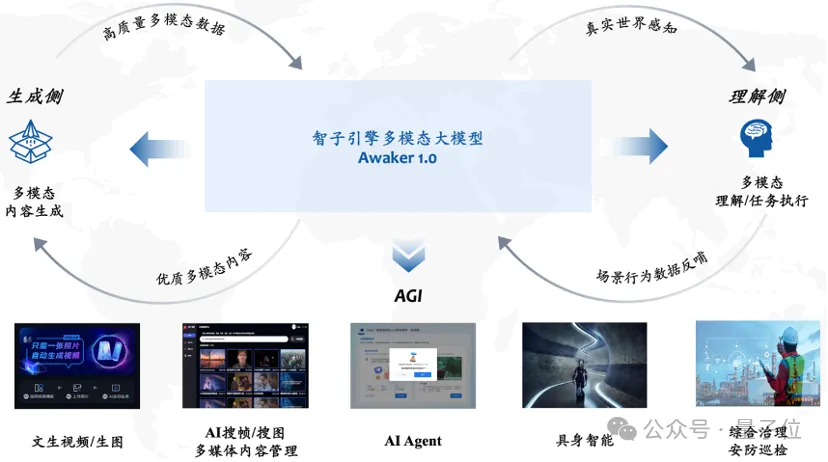
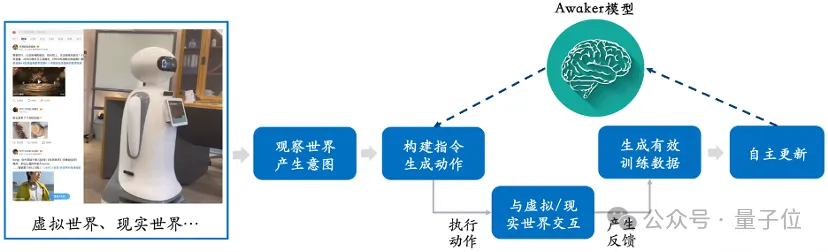
(last May), and has been accepted by the top conference ICLR 2024. VDT與眾不同的創新之處,主要有兩點。 一是在技術架構上採用Diffusion Transformer#,在OpenAI之前就展現了Transformer在影片產生領域的巨大潛力。 它的優勢在於其出色的時間依賴性捕獲能力,能夠產生時間上連貫的視訊幀,包括模擬三維物件隨時間的物理動態。 二是提出統一的時空遮罩建模機制,使VDT能夠處理多種視訊產生任務。 VDT靈活的條件資訊處理方式,如簡單的token空間拼接,有效地統一了不同長度和模態的資訊。 同時,透過與該工作提出的時空掩碼建模機制結合,VDT成為了一個通用的視訊擴散工具,在不修改模型結構的情況下可以應用於無條件生成、視訊後續幀預測、插幀、圖生影片、影片畫面補全等多種影片生成任務。 據了解,智子引擎團隊不僅探討了VDT對簡單物理規律的模擬,發現它能模擬物理過程: 也在超寫實人像影片產生任務上進行了深度探索。 因為肉眼對人臉及人的動態變化非常敏感,所以這個任務對影片產生品質的要求非常高。不過,智子引擎已經突破超寫實人像影片產生的大部分關鍵技術,比起Sora也沒在害怕的。 口說無憑。 這是智子引擎結合VDT和可控生成,對人像視頻生成質量提升後的效果: 據悉,智子引擎還將繼續優化人物可控的生成演算法,並積極進行商業化探索。 更值得關注的是,智子引擎團隊強調: Awaker 1.0是世界上首個能自主更新的多模態大模型。 換句話說,Awaker 1.0是「活」的,它的參數可以即時持續地更新-這就導致Awaker 1.0區別於所有其它多模態大模型, Awaker 1.0的自主更新機制,包含三大關鍵技術,分別是: 在理解側,Awaker 1.0與數位世界和現實世界互動。 在生成側,Awaker 1.0可以進行高品質的多模態內容生成,為理解側模型提供更多的訓練資料。 把新知識「記憶」在自個兒模型的參數上。 面對資料瓶頸的團隊們,一種可行、可用的新選擇,不就被Awaker 1.0送來了? 話說回來,正是由於實現了視覺理解與視覺生成的融合,當遇到「多模態大模型適配具身智能」的問題,Awaker 1.0的驕傲已經顯露無疑。 事情是這樣的: Awaker 1.0這類多模態大模型,其具有的視覺理解能力可以天然與具身智能的「眼睛」結合。 而主流聲音也認為,「多模態大模型 具身智慧」有可能大幅提升具身智慧的適應性和創造性,甚至是實現AGI的可行路徑。 理由不外乎兩點。 第一,人們期望具身智慧擁有適應性,即智能體能夠透過持續學習來適應不斷變化的應用環境。 這樣一來,具身智慧既能在已知多模態任務上越做越好,也能快速適應未知的多模態任務。 第二,人們也期望具身智慧具有真正的創造性,希望它透過對環境的自主探索,能夠發現新的策略和解決方案,並探索AI的能力邊界。 但是二者的適配,並不是簡簡單單把多模態大模型連結個身體,或直接給具身智能裝個腦子那麼簡單。 就拿多模態大模型來說,至少有兩個明顯的問題擺在眼前。 一是模型的迭代更新周期長,需要大量的人力投入; 二是模型的訓練資料都源自已有的數據,模型不能持續獲得大量的新知識。雖然透過RAG和擴長上下文視窗也可以注入持續出現的新知識,模型記不住,補救方式還會帶來額外的問題。 總之,目前的多模態大模型在實際應用場景中不具備很強的適應性,更不具備創造性,導致在行業落地時總是出現各種各樣的困難。 妙啊——還記得我們前面提到,Awaker 1.0不僅可以學習新知識,還能記住新知識,而這種學習是每天的、持續的、及時的。 從這張框架圖可以看出,Awaker 1.0能夠與各種智慧型裝置結合,透過智慧型裝置觀察世界,產生動作意圖,並自動建構指令控制智能設備完成各種動作。 在完成各種動作後,智慧型裝置會自動產生各種回饋,Awaker 1.0能夠從這些動作和回饋中獲得有效的訓練資料進行持續的自我更新,不斷強化模型的各種能力。 這就等於具身智能擁有一個活的大腦了。 誰看了不說一句how pay(狗頭)~ #尤其重要的是,因為具備自主更新能力,Awaker 1.0##不單單是可以和具身智能適配,它也適用於更廣泛的行業場景,能夠解決更複雜的實際任務。 

產生源源不絕的新互動資料
這三項技術,讓Awaker 1.0具備自主學習、自動反思和自主更新的能力,可以在這個世界自由探索,甚至與人類互動。 基於此,Awaker 1.0在理解側和生成側都能產生源源不絕的新交互資料。 怎麼做到的?

具身智能「活」的大腦

The above is the detailed content of The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
