
 Technology peripherals
AI
CVPR 2024 | With the help of neural structured light, Zhejiang University realizes real-time acquisition and reconstruction of dynamic three-dimensional phenomena
Technology peripherals
AI
CVPR 2024 | With the help of neural structured light, Zhejiang University realizes real-time acquisition and reconstruction of dynamic three-dimensional phenomena
CVPR 2024 | With the help of neural structured light, Zhejiang University realizes real-time acquisition and reconstruction of dynamic three-dimensional phenomena


The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Efficient and high-quality reconstruction of dynamic three-dimensional physical phenomena such as smoke is an important issue in related scientific research. It has broad application prospects in aerodynamic design verification, meteorological three-dimensional observation and other fields. . By collectively reconstructing three-dimensional density sequences that change over time, scientists can better understand and verify various complex physical phenomena in the real world.

Figure 1 shows the importance of observing dynamic three-dimensional physical phenomena for scientific research. The picture shows the world's largest wind tunnel NFAC conducting aerodynamic experiments on commercial truck entities.
However, it is quite difficult to quickly acquire and reconstruct dynamic three-dimensional density fields with high quality in the real world. First, three-dimensional information is difficult to measure directly through common two-dimensional image sensors (such as cameras). In addition, high-speed changing dynamic phenomena place high demands on physical acquisition capabilities: a complete sampling of a single three-dimensional density field needs to be intercepted in a very short time, otherwise the three-dimensional density field itself will change. The fundamental challenge here is how to resolve the information gap between the measurement sample itself and the dynamic three-dimensional density field reconstruction results.
Current mainstream research work uses prior knowledge to make up for the lack of information in measurement samples. The calculation cost is high, and the reconstruction quality is poor when the prior conditions are not met. Different from the mainstream research ideas, the research team of the National Key Laboratory of Computer-Aided Design and Graphics Systems of Zhejiang University believes that the key to solving the problem lies in increasing the information content of the unit measurement sample.
The research team not only uses AI to optimize the reconstruction algorithm, but also uses AI to help design physical collection methods to achieve fully automatic software and hardware joint optimization driven by the same goal, essentially improving the amount of information about the target object in the unit measurement sample. . By simulating physical optical phenomena in the real world, artificial intelligence can decide how to project structured light, how to collect corresponding images, and how to reconstruct a dynamic three-dimensional density field from the sample book. In the end, the research team only used a lightweight hardware prototype containing a single projector and a small number of cameras (1 or 3) to reduce the number of structured light patterns to model a single three-dimensional density field (spatial resolution 128x128x128) to 6, achieving Efficient acquisition set of 40 three-dimensional density fields per second.
The team innovatively proposed a lightweight one-dimensional decoder in the reconstruction algorithm, using local input light as part of the decoder input, and shared decoder parameters under different materials captured by different cameras, significantly improving Reduce network complexity and increase calculation speed. In order to fuse the decoding results of different cameras, a 3D U-Net fusion network with a simple structure is designed. The final reconstruction of a single three-dimensional density field only takes 9.2 milliseconds. Compared with SOTA research work, the reconstruction speed is increased by 2-3 orders of magnitude, achieving real-time high-quality reconstruction of the three-dimensional density field. The related research paper "Real-time Acquisition and Reconstruction of Dynamic Volumes with Neural Structured Illumination" has been accepted by CVPR 2024, the top international academic conference in the field of computer vision.

Paper link: https://svbrdf.github.io/publications/realtimedynamic/realtimedynamic.pdf
-
Research homepage: https://svbrdf.github.io/publications/realtimedynamic/project.html


Related work can be divided into the following two categories according to whether the lighting is controlled during the collection process.
The first type of work based on non-controllable lighting does not require a special light source and does not control the lighting during the collection process, so the requirements for collection conditions are looser [2,3]. Since a single-view camera captures a two-dimensional projection of a three-dimensional structure, it is difficult to distinguish different three-dimensional structures with high quality. In this regard, one idea is to increase the number of collected viewing angle samples, such as using dense camera arrays or light field cameras, which will lead to high hardware costs. Another idea is still to sparsely sample the perspective domain and fill the information gap through various types of prior information, such as heuristic priors, physical rules or prior knowledge learned from existing data. Once the a priori conditions are not met in practice, the quality of the reconstruction results of this type of method will deteriorate. Furthermore, its computational overhead is too expensive to support real-time reconstruction.
The second type of work uses controllable lighting to actively control lighting conditions during the collection process [4,5]. Such work encodes lighting to more actively probe the physical world and also relies less on priors, resulting in higher reconstruction quality. Depending on whether a single lamp or multiple lamps are used simultaneously, related work can be further classified into scanning methods and illumination multiplexing methods. For dynamic physical objects, the former must achieve high scanning speeds by using expensive hardware, or sacrifice the integrity of the results to reduce the acquisition burden. The latter significantly improves collection efficiency by programming multiple light sources simultaneously. However, for high-quality fast real-time density fields, the sampling efficiency of existing methods is still insufficient [5].
The work of the Zhejiang University team falls into the second category. Different from most existing work, this research work uses artificial intelligence to jointly optimize physical acquisition (i.e., neural structured light) and computational reconstruction, thereby achieving efficient and high-quality dynamic three-dimensional density field modeling.
Hardware prototype
The research team built a single commercial projector (BenQ X3000: resolution 1920×1080, speed 240fps) and three industrial cameras (Basler acA1440- 220umQGR: a simple hardware prototype composed of 1440×1080 resolution and 240fps speed (as shown in Figure 3). Six pre-trained structured light patterns are cyclically projected through the projector, and the three cameras shoot simultaneously, and dynamic three-dimensional density field reconstruction is performed based on the images collected by the cameras. The angles of the four devices relative to the collection object are the optimal arrangements selected after simulations from different simulation experiments.
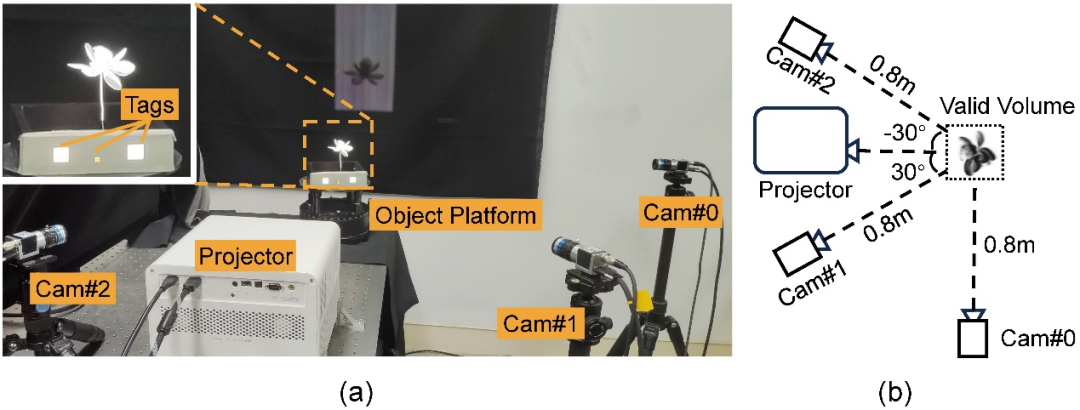
Figure 3: Acquisition hardware prototype. (a) Real shot of the hardware prototype, with three white tags on the stage used to synchronize the camera and projector. (b) Schematic diagram of the geometric relationship between camera, projector and subject (top view).
Software processing
The R&D team designs a deep neural network composed of encoders, decoders and aggregation modules. The weights in its encoder directly correspond to the structured light intensity distribution during acquisition. The decoder takes a sample measured on a single pixel as input, predicts a one-dimensional density distribution and interpolates it into a three-dimensional density field. The aggregation module combines the multiple three-dimensional density fields predicted by the decoder corresponding to each camera into the final result. By using trainable structured light and a lightweight one-dimensional decoder, this study can more easily learn the essential relationship between structured light patterns, two-dimensional photos and three-dimensional density fields, making it less likely to overfit to the training data. middle. Figure 4 below shows the overall pipeline, and Figure 5 shows the relevant network structure.

Figure 4: Global acquisition and reconstruction pipeline (a), and from structured light pattern to one-dimensional local incident light (b) and from predicted The resampling process of the one-dimensional density distribution back to the three-dimensional density field (c). The study starts with a simulated/real three-dimensional density field, onto which pre-optimized structured light patterns (i.e. weights in the encoder) are first projected. For each valid pixel in each camera view, all its measurements and the resampled local incident light are fed to the decoder to predict the one-dimensional density distribution on the corresponding camera ray. All density distributions from one camera are then collected and resampled into a single three-dimensional density field. In the multi-camera case, this study fuses the predicted density fields of each camera to obtain the final result.
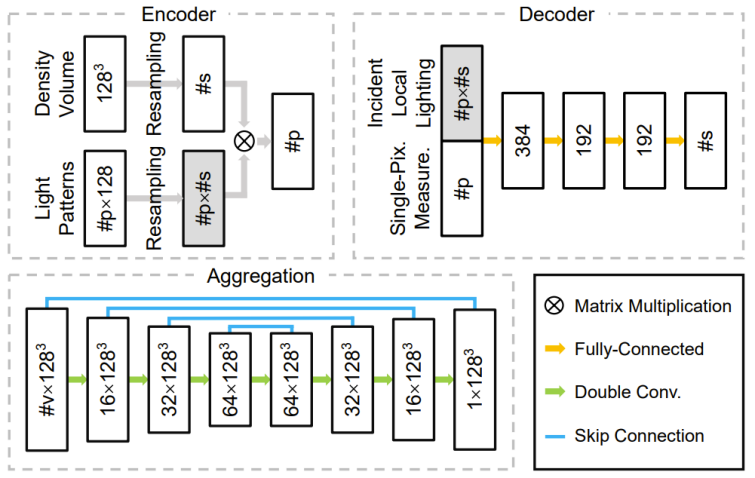
# Figure 5: Architecture of the 3 main components of the network: encoder, decoder and aggregation module.
Result display
Figure 6 shows the partial reconstruction results of four different dynamic scenes using this method. To generate dynamic water mist, the researchers added dry ice to bottles containing liquid water to create water mist, and controlled the flow through valves and used rubber tubes to guide it further to the collection device.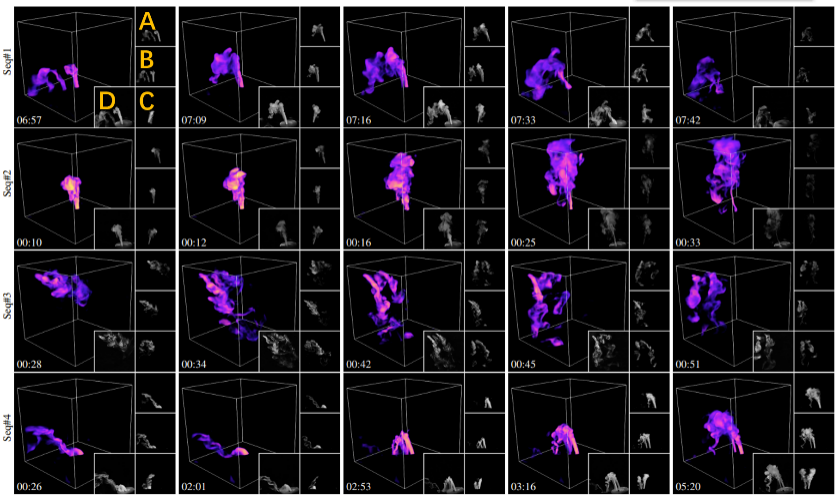
# Figure 6: Reconstruction results of different dynamic scenes. Each row is the visualization result of a selected part of the reconstructed frame in a certain water mist sequence. The number of water mist sources in the scene from top to bottom is: 1, 1, 3 and 2 respectively. As shown in the orange mark on the upper left, A, B, and C respectively correspond to the images collected by the three input cameras, and D is a real-shot reference image similar to the reconstruction result rendering perspective. The timestamp is displayed in the lower left corner. For detailed dynamic reconstruction results, please see the paper video.
In order to verify the correctness and quality of this research, the research team compared this method with related SOTA methods on real static objects (as shown in Figure 7). Figure 7 also compares the reconstruction quality under different camera numbers. All reconstruction results are plotted under the same new unacquired perspective and quantitatively evaluated by three evaluation metrics. As can be seen from Figure 7, thanks to the optimization of acquisition efficiency, the reconstruction quality of this method is better than the SOTA method.

Figure 7: Comparison of different techniques on real static objects. From left to right are the optical layer cutting method [4], this method (three cameras), this method (double camera), this method (single camera), using hand-designed structured light under a single camera [5], SOTA's PINF Visualization of reconstruction results of [3] and GlobalTrans [2] methods. Taking the optical slice results as a benchmark, and for all other results, their quantitative errors are listed in the lower right corner of the corresponding images, evaluated with three metrics SSIM/PSNR/RMSE (×0.01). All reconstructed density fields are rendered using non-input views, #v represents the number of views acquired and #p represents the number of structured light patterns used.
The research team also quantitatively compared the reconstruction quality of different methods on dynamic simulation data. Figure 8 shows the reconstruction quality comparison of simulated smoke sequences. For detailed frame-by-frame reconstruction results, please see the paper video.

Figure 8: Comparison of different methods on simulated smoke sequences. From left to right are the real values, reconstruction results of this method, PINF [3] and GlobalTrans [2]. The rendering results of the input view and new view are shown in the first and second rows respectively. The quantitative error SSIM/PSNR/RMSE (×0.01) is shown in the lower right corner of the corresponding image. For the average error of the entire reconstructed sequence, please refer to the supplementary material of the paper. In addition, please see the paper video for the dynamic reconstruction results of the entire sequence.
Future Outlook
The research team plans to apply this method on more advanced acquisition equipment (such as light field projectors [6]) Dynamic acquisition and reconstruction. The team also hopes to further reduce the number of structured light patterns and cameras required for collection by collecting richer optical information (such as polarization state). In addition, combining this method with neural expressions (such as NeRF) is also one of the future development directions that the team is interested in. Finally, allowing AI to more actively participate in the design of physical acquisition and computational reconstruction, and not be limited to post-processing software, may provide new ideas for further improving physical perception capabilities, and ultimately achieve efficient and high-quality modeling of different complex physical phenomena. .
Reference:
[1]. Inside the World's Largest Wind Tunnel https://youtu.be /ubyxYHFv2qw?si=KK994cXtARP3Atwn
[2]. Erik Franz, Barbara Solenthaler, and Nils Thuerey. Global transport for fluid reconstruction with learned selfsupervision. In CVPR, pages 1632–1642, 2021.
[3]. Mengyu Chu, Lingjie Liu, Quan Zheng, Erik Franz, HansPeter Seidel, Christian Theobalt, and Rhaleb Zayer . Physics informed neural fields for smoke reconstruction with sparse data. ACM Transactions on Graphics, 41 (4):1–14, 2022.
[4]. Tim Hawkins, Per Einarsson, and Paul Debevec. Acquisition of time-varying participating media. ACM Transactions on Graphics, 24 (3):812–815, 2005.
[5]. Jinwei Gu, Shree K. Nayar, Eitan Grinspun, Peter N. Belhumeur, and Ravi Ramamoorthi. Compressive structured light for recovering inhomogeneous participating media. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35 (3):1 –1, 2013.
[6]. Xianmin Xu, Yuxin Lin, Haoyang Zhou, Chong Zeng, Yaxin Yu, Kun Zhou, and Hongzhi Wu. A Unified spatial-angular structured light for single-view acquisition of shape and reflectance. In CVPR, pages 206–215, 2023.
The above is the detailed content of CVPR 2024 | With the help of neural structured light, Zhejiang University realizes real-time acquisition and reconstruction of dynamic three-dimensional phenomena. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to install deepseek
Feb 19, 2025 pm 05:48 PM
How to install deepseek
Feb 19, 2025 pm 05:48 PM
There are many ways to install DeepSeek, including: compile from source (for experienced developers) using precompiled packages (for Windows users) using Docker containers (for most convenient, no need to worry about compatibility) No matter which method you choose, Please read the official documents carefully and prepare them fully to avoid unnecessary trouble.
 Summary of FAQs for DeepSeek usage
Feb 19, 2025 pm 03:45 PM
Summary of FAQs for DeepSeek usage
Feb 19, 2025 pm 03:45 PM
DeepSeekAI Tool User Guide and FAQ DeepSeek is a powerful AI intelligent tool. This article will answer some common usage questions to help you get started quickly. FAQ: The difference between different access methods: There is no difference in function between web version, App version and API calls, and App is just a wrapper for web version. The local deployment uses a distillation model, which is slightly inferior to the full version of DeepSeek-R1, but the 32-bit model theoretically has 90% full version capability. What is a tavern? SillyTavern is a front-end interface that requires calling the AI model through API or Ollama. What is breaking limit
 What are the Grayscale Encryption Trust Funds? Common Grayscale Encryption Trust Funds Inventory
Mar 05, 2025 pm 12:33 PM
What are the Grayscale Encryption Trust Funds? Common Grayscale Encryption Trust Funds Inventory
Mar 05, 2025 pm 12:33 PM
Grayscale Investment: The channel for institutional investors to enter the cryptocurrency market. Grayscale Investment Company provides digital currency investment services to institutions and investors. It allows investors to indirectly participate in cryptocurrency investment through the form of trust funds. The company has launched several crypto trusts, which has attracted widespread market attention, but the impact of these funds on token prices varies significantly. This article will introduce in detail some of Grayscale's major crypto trust funds. Grayscale Major Crypto Trust Funds Available at a glance Grayscale Investment (founded by DigitalCurrencyGroup in 2013) manages a variety of crypto asset trust funds, providing institutional investors and high-net-worth individuals with compliant investment channels. Its main funds include: Zcash (ZEC), SOL,
 Delphi Digital: How to change the new AI economy by parsing the new ElizaOS v2 architecture?
Mar 04, 2025 pm 07:00 PM
Delphi Digital: How to change the new AI economy by parsing the new ElizaOS v2 architecture?
Mar 04, 2025 pm 07:00 PM
ElizaOSv2: Empowering AI and leading the new economy of Web3. AI is evolving from auxiliary tools to independent entities. ElizaOSv2 plays a key role in it, which gives AI the ability to manage funds and operate Web3 businesses. This article will dive into the key innovations of ElizaOSv2 and how it shapes an AI-driven future economy. AI Automation: Going to independently operate ElizaOS was originally an AI framework focusing on Web3 automation. v1 version allows AI to interact with smart contracts and blockchain data, while v2 version achieves significant performance improvements. Instead of just executing simple instructions, AI can independently manage workflows, operate business and develop financial strategies. Architecture upgrade: Enhanced A
 As top market makers enter the crypto market, what impact will Castle Securities have on the industry?
Mar 04, 2025 pm 08:03 PM
As top market makers enter the crypto market, what impact will Castle Securities have on the industry?
Mar 04, 2025 pm 08:03 PM
The entry of top market maker Castle Securities into Bitcoin market maker is a symbol of the maturity of the Bitcoin market and a key step for traditional financial forces to compete for future asset pricing power. At the same time, for retail investors, it may mean the gradual weakening of their voice. On February 25, according to Bloomberg, Citadel Securities is seeking to become a liquidity provider for cryptocurrencies. The company aims to join the list of market makers on various exchanges, including exchanges operated by CoinbaseGlobal, BinanceHoldings and Crypto.com, people familiar with the matter said. Once approved by the exchange, the company initially planned to set up a market maker team outside the United States. This move is not only a sign
 Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Researchers from Shanghai Jiaotong University, Shanghai AILab and the Chinese University of Hong Kong have launched the Visual-RFT (Visual Enhancement Fine Tuning) open source project, which requires only a small amount of data to significantly improve the performance of visual language big model (LVLM). Visual-RFT cleverly combines DeepSeek-R1's rule-based reinforcement learning approach with OpenAI's reinforcement fine-tuning (RFT) paradigm, successfully extending this approach from the text field to the visual field. By designing corresponding rule rewards for tasks such as visual subcategorization and object detection, Visual-RFT overcomes the limitations of the DeepSeek-R1 method being limited to text, mathematical reasoning and other fields, providing a new way for LVLM training. Vis
 Bitwise: Businesses Buy Bitcoin A Neglected Big Trend
Mar 05, 2025 pm 02:42 PM
Bitwise: Businesses Buy Bitcoin A Neglected Big Trend
Mar 05, 2025 pm 02:42 PM
Weekly Observation: Businesses Hoarding Bitcoin – A Brewing Change I often point out some overlooked market trends in weekly memos. MicroStrategy's move is a stark example. Many people may say, "MicroStrategy and MichaelSaylor are already well-known, what are you going to pay attention to?" This is true, but many investors regard it as a special case and ignore the deeper market forces behind it. This view is one-sided. In-depth research on the adoption of Bitcoin as a reserve asset in recent months shows that this is not an isolated case, but a major trend that is emerging. I predict that in the next 12-18 months, hundreds of companies will follow suit and buy large quantities of Bitcoin
 The latest tutorial on how to install the ios version installation package of Ouyi
Feb 21, 2025 pm 07:36 PM
The latest tutorial on how to install the ios version installation package of Ouyi
Feb 21, 2025 pm 07:36 PM
This guide will provide a comprehensive overview of how to install the latest installation packages from EV Exchange on iOS devices. Ouyi Exchange is a leading cryptocurrency trading platform that provides a wide range of cryptocurrency trading, asset management and investment services. By following the step-by-step instructions provided in this guide, users can easily and easily install the Euyi Exchange app on their iPhone or iPad. This guide is suitable for all iOS devices, from older models to the latest generation, and includes clear screenshots and detailed instructions to ensure a seamless installation process.
