
 Technology peripherals
AI
LeCun on the moon? Nankai and Byte open source StoryDiffusion to make multi-picture comics and long videos more coherent
Technology peripherals
AI
LeCun on the moon? Nankai and Byte open source StoryDiffusion to make multi-picture comics and long videos more coherent
LeCun on the moon? Nankai and Byte open source StoryDiffusion to make multi-picture comics and long videos more coherent

Two days ago, Turing Award winner Yann LeCun reprinted the long comic "Go to the Moon and Explore Yourself", which aroused heated discussion among netizens.

In the paper "Story Diffusion: Consistent Self-Attention for long-range image and video generation", the research team proposed a method called Story Diffusion's new approach to generating consistent images and videos depicting complex situations. The research on these comics comes from institutions such as Nankai University and ByteDance.

- ##Paper address: https://arxiv.org/pdf/2405.01434v1
- Project homepage: https://storydiffusion.github.io/
The related project has obtained 1k Stars on GitHub.
GitHub address: https://github.com/HVision-NKU/StoryDiffusion
Based on Project demonstration, StoryDiffusion can generate comics of various styles, telling a coherent story while maintaining the consistency of character style and clothing.

StoryDiffusion can maintain the identity of multiple characters simultaneously and generate consistent characters across a series of images.

In addition, StoryDiffusion can generate high-quality videos conditioned on generated consistent images or user-entered images.


We know how, for diffusion-based generative models, in a series of generated images Maintaining content consistency, especially images that contain complex themes and details, is a significant challenge.
Therefore, the research team proposed a new self-attention calculation method, called Consistent Self-Attention (Consistent Self-Attention), by establishing batches when generating images. The connection between images within the image is maintained to maintain the consistency of the characters, and thematically consistent images can be generated without training.
In order to extend this method to long video generation, the research team introduced a semantic motion predictor (Semantic Motion Predictor), which encodes images into semantic space and predicts motion in semantic space. motion to generate videos. This is more stable than motion prediction based only on the latent space.
Then perform framework integration, combining consistent self-attention and semantic motion predictors to generate consistent videos and tell complex stories. StoryDiffusion can generate smoother and more coherent videos than existing methods.

Figure 1: Images and videos generated by the team’s StroyDiffusion
Overview of the method
The research team’s method can be divided into two stages, as shown in Figures 2 and 3.
In the first stage, StoryDiffusion uses Consistent Self-Attention to generate topic-consistent images in a training-free manner. These consistent images can be used directly in storytelling or as input to a second stage. In the second stage, StoryDiffusion creates consistent transition videos based on these consistent images.
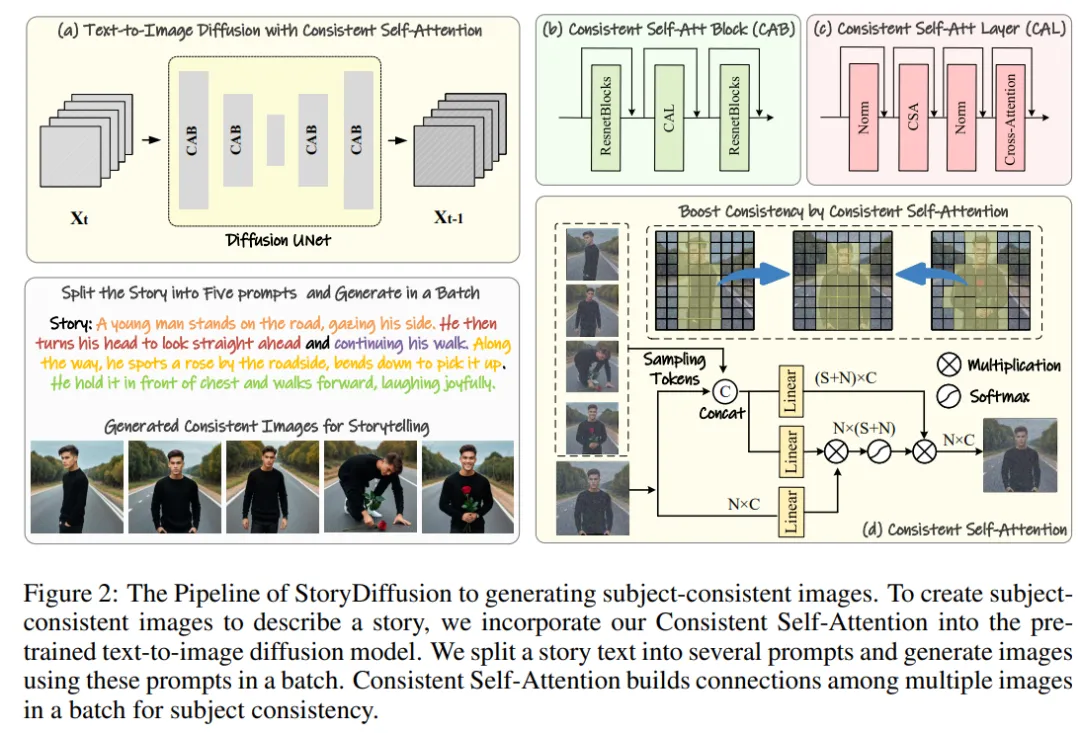
Figure 2: StoryDiffusion process overview for generating theme-consistent images
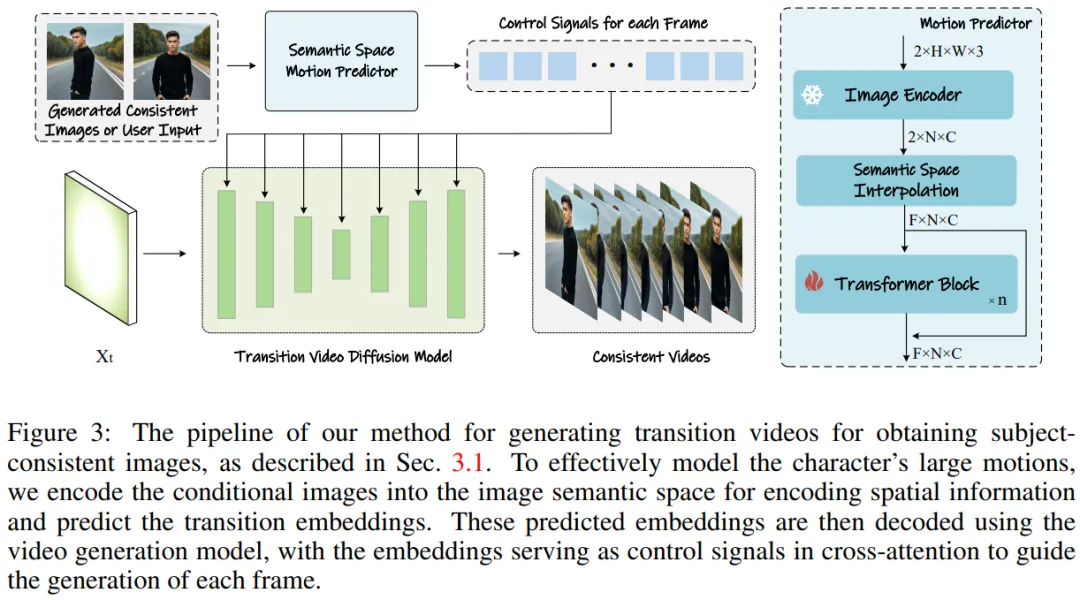 Figure 3: Generate transition video to obtain approach to thematically consistent images.
Figure 3: Generate transition video to obtain approach to thematically consistent images.
Consistent image generation without training
The research team introduced the method of "how to generate thematically consistent images without training". The key to solving the above problem is how to maintain the consistency of the characters in a batch of images. This means that during the generation process, they need to establish connections between a batch of images.
After re-examining the role of different attention mechanisms in the diffusion model, they were inspired to explore the use of self-attention to maintain image consistency within a batch of images, and proposed Consistent Self-Attention.
The research team inserted consistent self-attention into the original self-attention position in the U-Net architecture of the existing image generation model, and reused the original self-attention weights. To maintain no training and plug-and-play features.
Given paired tokens, the research team’s method performs self-attention on a batch of images, promoting interactions between different image features. This type of interaction drives the model's convergence on characters, faces, and clothing during generation. Although the consistent self-attention method is simple and requires no training, it can effectively generate thematically consistent images.
To illustrate more clearly, the research team shows pseudocode in Algorithm 1.

Semantic motion predictor for video generation
Research Team A Semantic Motion Predictor is proposed, which encodes images into image semantic space to capture spatial information, thereby achieving more accurate motion prediction from a given start frame and end frame.
More specifically, in the semantic motion predictor proposed by the team, they first use a function E to establish a mapping from the RGB image to the image semantic space vector. Information is encoded.
The team did not directly use the linear layer as the function E. Instead, it used a pre-trained CLIP image encoder as the function E to take advantage of its zero samples (zero- shot) capability to improve performance.
Using function E, the given start frame F_s and end frame F_e are compressed into image semantic space vectors K_s and K_e.

Experimental results
In terms of generating subject-consistent images, since the team’s method requires no training And it is plug-and-play, so they have implemented this method in both versions of Stable Diffusion XL and Stable Diffusion 1.5. To be consistent with the compared models, they used the same pre-trained weights on the Stable-XL model for comparison.
To generate consistent videos, the researchers implemented their research method based on the Stable Diffusion 1.5 specialized model and integrated a pre-trained temporal module to support video generation. All compared models use a 7.5 classifier-free guidance score and 50-step DDIM sampling.
Consistency Image Generation Comparison
The team achieved this by working with two of the latest ID preservation methods - IP- Adapter and Photo Maker - Comparison, evaluating their methods of generating thematically consistent images.
To test performance, they used GPT-4 to generate twenty role instructions and one hundred activity instructions to describe specific activities.
Qualitative results are shown in Figure 4: "StoryDiffusion is able to generate highly consistent images. While other methods, such as IP-Adapter and PhotoMaker, may produce inconsistent clothing or controllable text Lowered image."

Figure 4: Comparison results with current methods on consistent image generation
The researchers are in Table 1 Results of quantitative comparisons are presented. The results show: "The team's StoryDiffusion achieved the best performance on both quantitative metrics, indicating that the method can fit the prompt description well while maintaining character characteristics, and shows its robustness."
 Table 1: Quantitative comparison results of consistent image generation
Table 1: Quantitative comparison results of consistent image generation
Comparison of transition video generation
In terms of transition video generation, the research team compared it with two state-of-the-art methods - SparseCtrl and SEINE - to evaluate performance.
They conducted a qualitative comparison of transition video generation and displayed the results in Figure 5. The results show: "The team's StoryDiffusion is significantly better than SEINE and SparseCtrl, and the generated transition video is smooth and consistent with physical principles."

Figure 5: Comparison of transition video generation currently using various state-of-the-art methods
They also compared this method with SEINE and SparseCtrl, and used LPIPSfirst, LPIPS- The four quantitative indicators including frames, CLIPSIM-first and CLIPSIM-frames are shown in Table 2.
 Table 2: Quantitative comparison with the current state-of-the-art transition video generation model
Table 2: Quantitative comparison with the current state-of-the-art transition video generation model
For more technical and experimental details, please refer to Original paper.
The above is the detailed content of LeCun on the moon? Nankai and Byte open source StoryDiffusion to make multi-picture comics and long videos more coherent. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to do Oracle security settings on Debian
Apr 02, 2025 am 07:48 AM
How to do Oracle security settings on Debian
Apr 02, 2025 am 07:48 AM
To strengthen the security of Oracle database on the Debian system, it requires many aspects to start. The following steps provide a framework for secure configuration: 1. Oracle database installation and initial configuration system preparation: Ensure that the Debian system has been updated to the latest version, the network configuration is correct, and all required software packages are installed. It is recommended to refer to official documents or reliable third-party resources for installation. Users and Groups: Create a dedicated Oracle user group (such as oinstall, dba, backupdba) and set appropriate permissions for it. 2. Security restrictions set resource restrictions: Edit /etc/security/limits.d/30-oracle.conf
 What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
The library used for floating-point number operation in Go language introduces how to ensure the accuracy is...
 How to monitor system performance through Debian logs
Apr 02, 2025 am 08:00 AM
How to monitor system performance through Debian logs
Apr 02, 2025 am 08:00 AM
Mastering Debian system log monitoring is the key to efficient operation and maintenance. It can help you understand the system's operating conditions in a timely manner, quickly locate faults, and optimize system performance. This article will introduce several commonly used monitoring methods and tools. Monitoring system resources with the sysstat toolkit The sysstat toolkit provides a series of powerful command line tools for collecting, analyzing and reporting various system resource metrics, including CPU load, memory usage, disk I/O, network throughput, etc. The main tools include: sar: a comprehensive system resource statistics tool, covering CPU, memory, disk, network, etc. iostat: disk and CPU statistics. mpstat: Statistics of multi-core CPUs. pidsta
 How to troubleshoot Debian Syslog
Apr 02, 2025 am 09:00 AM
How to troubleshoot Debian Syslog
Apr 02, 2025 am 09:00 AM
Syslog for Debian systems is a key tool for system administrators to diagnose problems. This article provides some steps and commands to troubleshoot common Syslog problems: 1. Log viewing real-time viewing of the latest log: tail-f/var/log/syslog viewing kernel logs (start errors and driver problems): dmesg uses journalctl (Debian8 and above, systemd system): journalctl-b (viewing after startup logs), journalctl-f (viewing new logs in real-time). 2. System resource monitoring and viewing process and resource usage: psaux (find high resource occupancy process) real-time monitoring
 What are the efficient techniques for Debian file management
Apr 02, 2025 am 08:48 AM
What are the efficient techniques for Debian file management
Apr 02, 2025 am 08:48 AM
Debian system efficient file management skills help you improve efficiency and quickly and conveniently operate files and directories. The following are some practical tips: 1. Proficient in using the following command line tools will greatly improve your file management efficiency: ls: View directory contents. cd: Switch directory. cp: Copy file or directory. mv: Move or rename a file or directory. rm: Delete a file or directory. mkdir: Create a directory. rmdir: Delete empty directory. touch: Create an empty file or update the file timestamp. find: Find files and directories. grep: Search for text in a file. tar: Package and unzip the file. 2. The magical use of wildcard characters, using wildcard characters, you can more accurately
 Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
Which libraries in Go are developed by large companies or well-known open source projects? When programming in Go, developers often encounter some common needs, ...
 What is the rotation strategy for Golang logs on Debian
Apr 02, 2025 am 08:39 AM
What is the rotation strategy for Golang logs on Debian
Apr 02, 2025 am 08:39 AM
In Debian systems, Go's log rotation usually relies on third-party libraries, rather than the features that come with Go standard libraries. lumberjack is a commonly used option. It can be used with various log frameworks (such as zap and logrus) to realize automatic rotation and compression of log files. Here is a sample configuration using the lumberjack and zap libraries: packagemainimport("gopkg.in/natefinch/lumberjack.v2""go.uber.org/zap""go.uber.org/zap/zapcor
 How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
Under the BeegoORM framework, how to specify the database associated with the model? Many Beego projects require multiple databases to be operated simultaneously. When using Beego...
