
 Technology peripherals
AI
Reversal after explosion? KAN who 'killed an MLP in one night': Actually, I am also an MLP
Technology peripherals
AI
Reversal after explosion? KAN who 'killed an MLP in one night': Actually, I am also an MLP
Reversal after explosion? KAN who 'killed an MLP in one night': Actually, I am also an MLP

Multi-layer perceptron (MLP), also known as fully connected feed-forward neural network, is the basic building block of today's deep learning models. The importance of MLPs cannot be overstated, as they are the default method in machine learning for approximating nonlinear functions.
But recently, researchers from MIT and other institutions have proposed a very promising alternative method-KAN . This method outperforms MLP in terms of accuracy and interpretability. Furthermore, it is able to outperform MLPs run with a much larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to rediscover the mathematical laws in knot theory and reproduce DeepMind's results with smaller networks and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters.
The fine-tuning content is as follows: These amazing research results made KAN quickly become popular and attracted many people to study it. Soon, some people raised some doubts. Among them, a Colab document titled "KAN is just MLP" became the focus of discussion.
KAN JUST A REGULAR MLP?
The author of the above document stated that you can write KAN as an MLP by adding some repetitions and shifts before ReLU.
In a short example, the author shows how to rewrite the KAN network into a normal MLP with the same number of parameters and a slightly nonlinear structure.
What needs to be remembered is that KAN has activation functions on the edges. They use B-splines. In the examples shown, the authors will only use piece-wise linear functions for simplicity. This does not change the modeling capabilities of the network.
The following is an example of a piece-wise linear function:
1 |
|
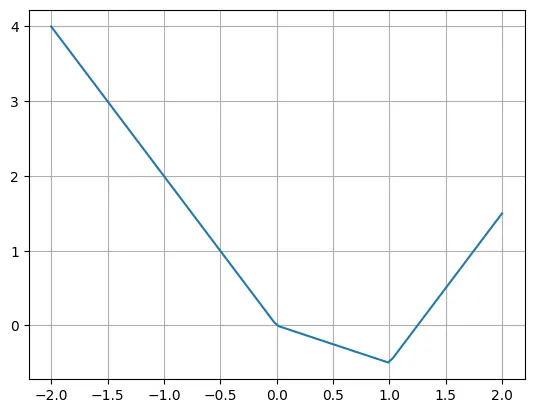
The author states that we can easily rewrite this function using multiple ReLU and linear functions. Note that sometimes it is necessary to move the input of ReLU.
1 |
|
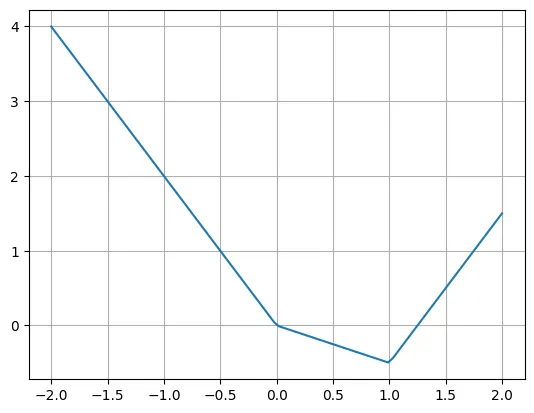
#The real question is how to rewrite the KAN layer into a typical MLP layer. Suppose there are n input neurons, m output neurons, and the piece-wise function has k pieces. This requires n*m*k parameters (k parameters per edge, and you have n*m edges).
Now consider a KAN edge. To do this, the input needs to be copied k times, each copy shifted by a constant, and then run through ReLU and linear layers (except for the first layer). Graphically it looks like this (C is the constant and W is the weight):
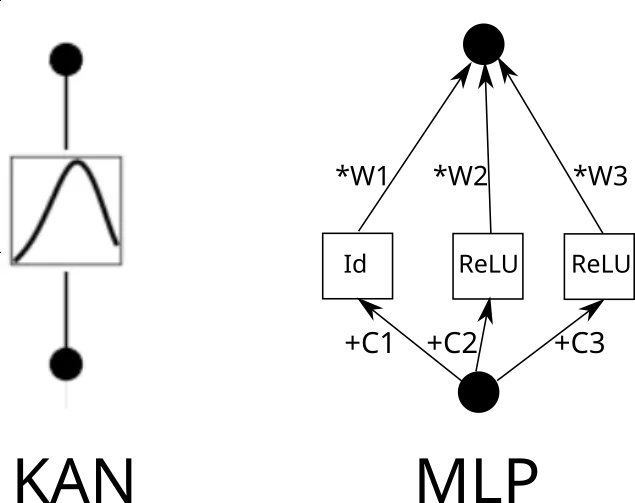
Now, you can repeat this process for each edge. But one thing to note is that if the piece-wise linear function grid is the same everywhere, we can share the intermediate ReLU output and just blend the weights on it. Like this:
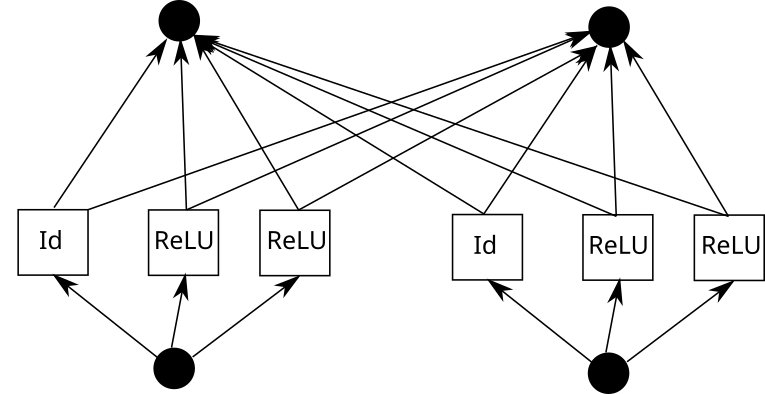
## In Pytorch, this translates to:
1 |
|
Now our layer looks like this:
- Expand shift ReLU
- Linear
Consider the three layers one after another:
- Expand shift ReLU (Layer 1 starts here)
- Linear
- Expand shift ReLU (Layer 2 starts here)
- Linear
- Expand shift ReLU (Layer 3 starts here)
- Linear
Ignore input expansion , we can rearrange:
- Linear (Layer 1 starts here)
- Expand shift ReLU
- Linear (Layer 2 starts here)
- Expand shift ReLU
The following layers are basically It can be called MLP. You can also make the linear layer larger and remove expand and shift to obtain better modeling capabilities (albeit at a higher parameter cost).
- Linear (Layer 2 starts here)
- Expand shift ReLU
Through this example, the author shows that KAN is a kind of MLP. This statement triggered everyone to rethink the two types of methods.

Re-examination of KAN ideas, methods and results
In fact, in addition to ignoring MLP KAN has also been questioned by many other parties over its relationship with the Qing Dynasty.
In summary, the researchers’ discussion mainly focused on the following points.
First, the main contribution of KAN lies in interpretability, not in expansion speed, accuracy, etc.
The author of the paper once said:
- KAN expands faster than MLP. KAN has better accuracy than MLP with fewer parameters.
- KAN can be visualized intuitively. KAN provides interpretability and interactivity that MLP cannot. We can potentially discover new scientific laws using KANs.
Among them, the importance of network interpretability for models to solve real-life problems is self-evident:

But the question is: "I think their claim is just that it learns faster and is interpretable, and nothing else. If KAN has much fewer parameters than the equivalent NN, then the former is Meaningful. I still feel that training KAN is very unstable. "
#So can KAN have much fewer parameters than the equivalent NN? ?
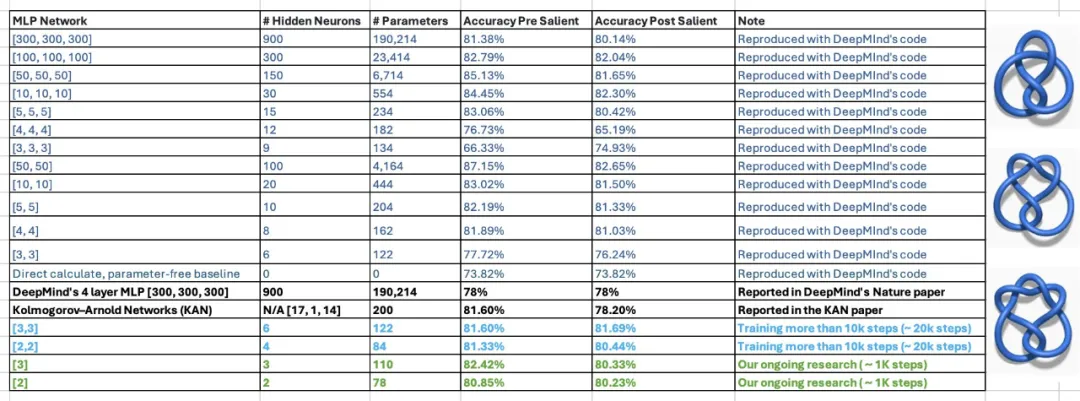
There are still doubts about this statement. In the paper, the authors of KAN stated that they were able to reproduce DeepMind's research on mathematical theorems using an MLP of 300,000 parameters using only 200 parameters of KAN. After seeing the results, two students of Georgia Tech associate professor Humphrey Shi re-examined DeepMind's experiments and found that with only 122 parameters, DeepMind's MLP could match KAN's 81.6% accuracy. Moreover, they did not make any major changes to the DeepMind code. To achieve this result, they only reduced the network size, used random seeds, and increased training time.

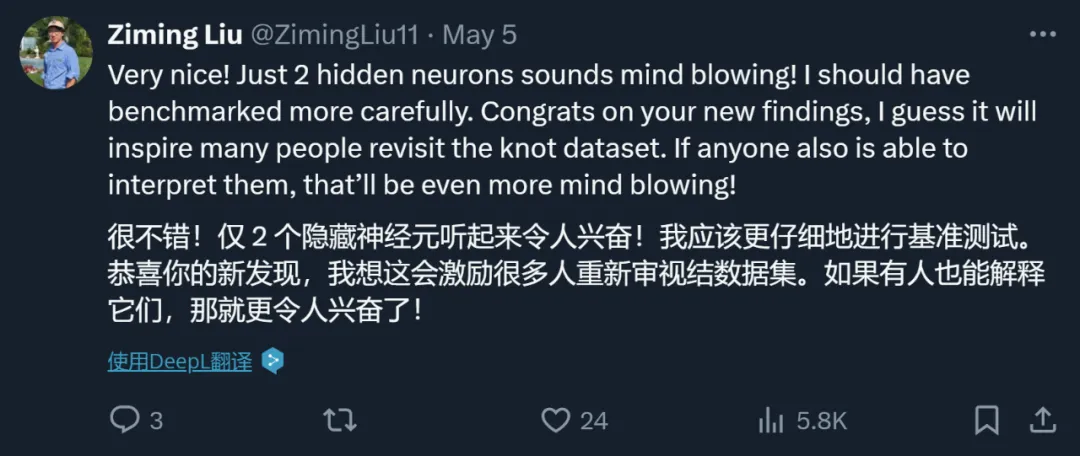
To this, the author of the paper also gave a positive response:
Second, KAN and MLP are not fundamentally different in approach.

"Yes, this is obviously the same thing. In KAN they do activation first and then linear combination, while in MLP they do linear combination first and then Then do the activation. Amplifying it is basically the same thing. As far as I know, the main reasons for using KAN are interpretability and symbolic regression. ##In addition to questioning the method, the researcher also called for a return to rationality in the evaluation of this paper:
##Third, some researchers said that KAN’s idea is not new.
"This was studied in the 1980s. A Hacker News discussion mentioned an Italian paper discussing this issue. So it’s nothing new at all. 40 years later, it’s just something that has either come back or been rejected and is being revisited.”
 But what you can see is. , the authors of the KAN paper did not gloss over the issue either.
But what you can see is. , the authors of the KAN paper did not gloss over the issue either.
"These ideas are not new, but I don't think the author is shying away from that. He just packaged everything up nicely and did some nice work on the toy data Experiment. But it is also a contribution."
##At the same time, Ian Goodfellow and Yoshua Bengio's paper MaxOut (https://arxiv.org/pdf/ 1302.4389) has also been mentioned, and some researchers believe that the two "although slightly different, the ideas are somewhat similar."
Author: The original research goal was indeed interpretability
As a result of the heated discussion, one of the authors, Sachin Vaidya, came forward.
As one of the authors of this paper, I would like to say a few words. The attention KAN is receiving is amazing, and this discussion is exactly what is needed to push new technologies to their limits and find out what works and what doesn’t.
I thought I’d share some background on motivation. Our main idea for implementing KAN stems from our search for interpretable AI models that can "learn" the insights that physicists discover about natural laws. Therefore, as others have realized, we are entirely focused on this goal because traditional black-box models cannot provide insights critical to fundamental discoveries in science. We then show through examples related to physics and mathematics that KAN significantly outperforms traditional methods in terms of interpretability. We certainly hope that the usefulness of KAN will extend far beyond our initial motivations. 
On the GitHub homepage, Liu Ziming, one of the authors of the paper, also responded to the evaluation of this research:
I was asked recently The most common question I get is whether KAN will become the next generation LLM. I don't have a clear judgment on this.
KAN is designed for applications that care about high accuracy and interpretability. We do care about the interpretability of LLMs, but interpretability can mean very different things for LLMs and science. Do we care about high accuracy of LLM? The scaling laws seem to imply so, but perhaps not very accurately. Furthermore, accuracy can also mean different things for LLM and science.
I welcome people to criticize KAN, practice is the only criterion for testing truth. There are many things we don’t know in advance until they are actually tried and proven to be a success or a failure. While I'd love to see KAN succeed, I'm equally curious about KAN's failure.
KAN and MLP are not substitutes for each other. They each have advantages in some situations and limitations in some situations. I would be interested in theoretical frameworks that encompass both, and maybe even come up with new alternatives (physicists love unified theories, sorry).
KAN The first author of the paper is Liu Ziming. He is a physicist and machine learning researcher and is currently a third-year PhD student at MIT and IAIFI under Max Tegmark. His research interests focus on the intersection of artificial intelligence and physics.
The above is the detailed content of Reversal after explosion? KAN who 'killed an MLP in one night': Actually, I am also an MLP. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
1205
24
52
1205
24

 How to update code in git
Apr 17, 2025 pm 04:45 PM
How to update code in git
Apr 17, 2025 pm 04:45 PM
Steps to update git code: Check out code: git clone https://github.com/username/repo.git Get the latest changes: git fetch merge changes: git merge origin/master push changes (optional): git push origin master
 How to download git projects to local
Apr 17, 2025 pm 04:36 PM
How to download git projects to local
Apr 17, 2025 pm 04:36 PM
To download projects locally via Git, follow these steps: Install Git. Navigate to the project directory. cloning the remote repository using the following command: git clone https://github.com/username/repository-name.git
 What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
Resolve: When Git download speed is slow, you can take the following steps: Check the network connection and try to switch the connection method. Optimize Git configuration: Increase the POST buffer size (git config --global http.postBuffer 524288000), and reduce the low-speed limit (git config --global http.lowSpeedLimit 1000). Use a Git proxy (such as git-proxy or git-lfs-proxy). Try using a different Git client (such as Sourcetree or Github Desktop). Check for fire protection
 How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
To delete a Git repository, follow these steps: Confirm the repository you want to delete. Local deletion of repository: Use the rm -rf command to delete its folder. Remotely delete a warehouse: Navigate to the warehouse settings, find the "Delete Warehouse" option, and confirm the operation.
 How to use git commit
Apr 17, 2025 pm 03:57 PM
How to use git commit
Apr 17, 2025 pm 03:57 PM
Git Commit is a command that records file changes to a Git repository to save a snapshot of the current state of the project. How to use it is as follows: Add changes to the temporary storage area Write a concise and informative submission message to save and exit the submission message to complete the submission optionally: Add a signature for the submission Use git log to view the submission content
 How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
When developing an e-commerce website, I encountered a difficult problem: How to achieve efficient search functions in large amounts of product data? Traditional database searches are inefficient and have poor user experience. After some research, I discovered the search engine Typesense and solved this problem through its official PHP client typesense/typesense-php, which greatly improved the search performance.
 How to merge code in git
Apr 17, 2025 pm 04:39 PM
How to merge code in git
Apr 17, 2025 pm 04:39 PM
Git code merge process: Pull the latest changes to avoid conflicts. Switch to the branch you want to merge. Initiate a merge, specifying the branch to merge. Resolve merge conflicts (if any). Staging and commit merge, providing commit message.
 How to submit empty folders in git
Apr 17, 2025 pm 04:09 PM
How to submit empty folders in git
Apr 17, 2025 pm 04:09 PM
To submit an empty folder in Git, just follow the following steps: 1. Create an empty folder; 2. Add the folder to the staging area; 3. Submit changes and enter a commit message; 4. (Optional) Push the changes to the remote repository. Note: The name of an empty folder cannot start with . If the folder already exists, you need to use git add --force to add.
