
 Technology peripherals
AI
Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent
Technology peripherals
AI
Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent
Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent

The latest large-scale domestic open source MoE model has become popular just after its debut.
DeepSeek-V2's performance reaches GPT-4 level, but it is open source, free for commercial use, and the API price is only one percent of GPT-4-Turbo.
So once it was released, it immediately triggered a lot of discussion.
 Picture
Picture
Judging from the published performance indicators, DeepSeek V2’s comprehensive Chinese capabilities surpass those of many open source models. At the same time, GPT-4 Turbo, Wenkuai Closed source models such as 4.0 are also in the first echelon.
The comprehensive English ability is also in the first echelon with LLaMA3-70B, and surpasses Mixtral 8x22B, which is also a MoE.
also shows good performance in knowledge, mathematics, reasoning, programming, etc. And supports 128K context.
 Picture
Picture
These capabilities can be used directly by ordinary users for free. The closed beta is now open, you can experience it immediately after registering.
 Picture
Picture
API is even more price-breaking: 1 yuan for input and 2 yuan for output per million tokens (32K context). The price is only nearly one percent of GPT-4-Turbo.
At the same time, the model architecture is also innovated, and the self-developed MLA (Multi-head Latent Attention) and Sparse structures are adopted, which can greatly reduce the amount of model calculation and inference memory.
Netizens lamented: DeepSeek always brings surprises to people!
 Picture
Picture
We have been the first to experience the specific effect!
Test it
Currently, the V2 internal beta version can experience the universal dialogue and code assistant.
 Picture
Picture
In the general dialogue, you can test the logic, knowledge, generation, mathematics and other abilities of the large model.
For example, you can ask it to imitate the style of "The Legend of Zhen Huan" to write lipstick planting copywriting.
 Picture
Picture
It can also explain in a popular way what quantum entanglement is.
 Picture
Picture
In terms of mathematics, you can answer high-level calculus questions, such as:
Use calculus to prove natural pairs The infinite series representation of the base e of a number.
 Picture
Picture
can also avoid some language logic traps.
 Picture
Picture
The test shows that the knowledge content of DeepSeek-V2 has been updated to 2023.
 Picture
Picture
In terms of code, the internal test page shows that DeepSeek-Coder-33B is used to answer questions.
In terms of generating simpler codes, there were no errors in several actual tests.
 Pictures
Pictures
can also explain and analyze the given code.
 Picture
Picture
 Picture
Picture
However, there are also cases of wrong answers in the test.
For the following logical question, during the calculation process of DeepSeek-V2, the time it takes for a candle to be lit from both ends at the same time and burn out is calculated as one-quarter of the time it takes for it to burn out from one end.
 Picture
Picture
What upgrades does it bring?
According to the official introduction, DeepSeek-V2 uses 236B total parameters and 21B activation, roughly reaching the model capability of 70B~110B Dense.
 Picture
Picture
Compared with the previous DeepSeek 67B, it has stronger performance and lower training cost, which can save 42.5% of the training cost and reduce With 93.3% KV cache, the maximum throughput is increased to 5.76 times.
Officially stated that this means that the video memory (KV Cache) consumed by DeepSeek-V2 is only 1/5~1/100 of the Dense model of the same level, and the cost per token is significantly reduced.
A lot of communication optimization has been done specifically for H800 specifications. It is actually deployed on an 8-card H800 machine. The input throughput exceeds 100,000 tokens per second and the output exceeds 50,000 tokens per second.
 Picture
Picture
On some basic Benchmarks, the performance of the DeepSeek-V2 basic model is as follows:
 Picture
Picture
DeepSeek-V2 adopts an innovative architecture.
Proposed MLA (Multi-head Latent Attention) architecture to significantly reduce the amount of calculation and inference memory.
At the same time, the Sparse structure is self-developed to further reduce the calculation amount.
 Picture
Picture
Some people have said that these upgrades may be very helpful for large-scale computing in data centers.
 Picture
Picture
And in terms of API pricing, DeepSeek-V2 is almost lower than all star models on the market.
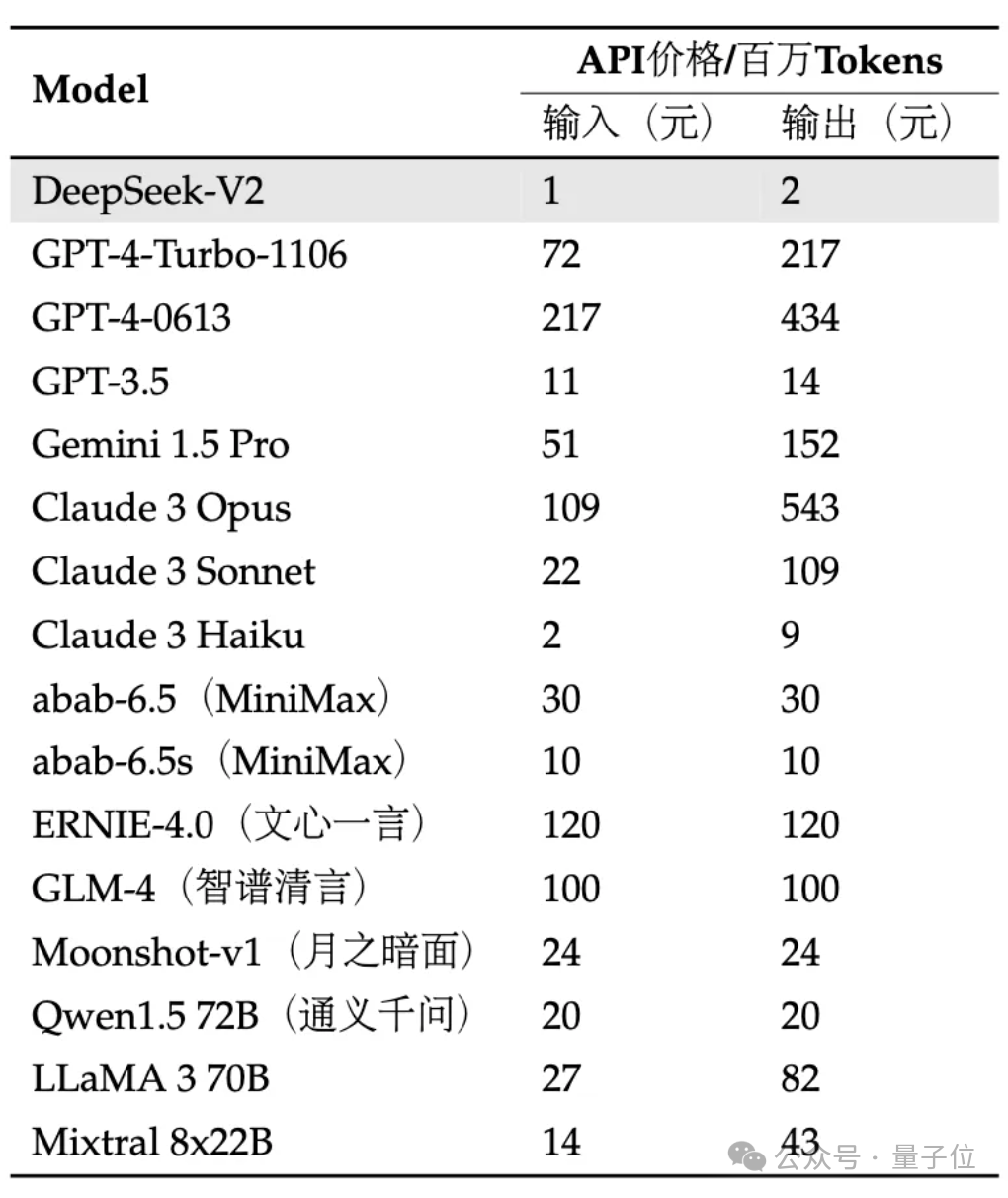 Picture
Picture
The team stated that the DeepSeek-V2 model and paper will also be fully open source. Model weights and technical reports are given.
Log in to the DeepSeek API open platform now and register to get 10 million input/5 million output Tokens as a gift. The normal trial is completely free.
The above is the detailed content of Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Text annotation is the work of corresponding labels or tags to specific content in text. Its main purpose is to provide additional information to the text for deeper analysis and processing, especially in the field of artificial intelligence. Text annotation is crucial for supervised machine learning tasks in artificial intelligence applications. It is used to train AI models to help more accurately understand natural language text information and improve the performance of tasks such as text classification, sentiment analysis, and language translation. Through text annotation, we can teach AI models to recognize entities in text, understand context, and make accurate predictions when new similar data appears. This article mainly recommends some better open source text annotation tools. 1.LabelStudiohttps://github.com/Hu
 15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
Image annotation is the process of associating labels or descriptive information with images to give deeper meaning and explanation to the image content. This process is critical to machine learning, which helps train vision models to more accurately identify individual elements in images. By adding annotations to images, the computer can understand the semantics and context behind the images, thereby improving the ability to understand and analyze the image content. Image annotation has a wide range of applications, covering many fields, such as computer vision, natural language processing, and graph vision models. It has a wide range of applications, such as assisting vehicles in identifying obstacles on the road, and helping in the detection and diagnosis of diseases through medical image recognition. . This article mainly recommends some better open source and free image annotation tools. 1.Makesens
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 The source code of 25 AI agents is now public, inspired by Stanford's 'Virtual Town' and 'Westworld'
Aug 11, 2023 pm 06:49 PM
The source code of 25 AI agents is now public, inspired by Stanford's 'Virtual Town' and 'Westworld'
Aug 11, 2023 pm 06:49 PM
Audiences familiar with "Westworld" know that this show is set in a huge high-tech adult theme park in the future world. The robots have similar behavioral capabilities to humans, and can remember what they see and hear, and repeat the core storyline. Every day, these robots will be reset and returned to their initial state. After the release of the Stanford paper "Generative Agents: Interactive Simulacra of Human Behavior", this scenario is no longer limited to movies and TV series. AI has successfully reproduced this scene in Smallville's "Virtual Town" 》Overview map paper address: https://arxiv.org/pdf/2304.03442v1.pdf
 Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Face detection and recognition technology is already a relatively mature and widely used technology. Currently, the most widely used Internet application language is JS. Implementing face detection and recognition on the Web front-end has advantages and disadvantages compared to back-end face recognition. Advantages include reducing network interaction and real-time recognition, which greatly shortens user waiting time and improves user experience; disadvantages include: being limited by model size, the accuracy is also limited. How to use js to implement face detection on the web? In order to implement face recognition on the Web, you need to be familiar with related programming languages and technologies, such as JavaScript, HTML, CSS, WebRTC, etc. At the same time, you also need to master relevant computer vision and artificial intelligence technologies. It is worth noting that due to the design of the Web side
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
 Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Let me introduce to you the latest AIGC open source project-AnimagineXL3.1. This project is the latest iteration of the anime-themed text-to-image model, aiming to provide users with a more optimized and powerful anime image generation experience. In AnimagineXL3.1, the development team focused on optimizing several key aspects to ensure that the model reaches new heights in performance and functionality. First, they expanded the training data to include not only game character data from previous versions, but also data from many other well-known anime series into the training set. This move enriches the model's knowledge base, allowing it to more fully understand various anime styles and characters. AnimagineXL3.1 introduces a new set of special tags and aesthetics
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
