
 Technology peripherals
AI
LeCun forwarded, AI allows aphasic people to speak again! NYU releases new 'neural-speech” decoder
Technology peripherals
AI
LeCun forwarded, AI allows aphasic people to speak again! NYU releases new 'neural-speech” decoder
LeCun forwarded, AI allows aphasic people to speak again! NYU releases new 'neural-speech” decoder

The development of brain-computer interface (BCI) in the field of scientific research and application has recently received widespread attention. People are generally curious about the application prospects of BCI.
Aphasia caused by neurological defects not only severely hinders patients' daily life, but may also limit their career development and social activities. With the rapid development of deep learning and brain-computer interface technology, modern science is moving in the direction of assisting aphasic people to regain communication abilities through neural voice prostheses.
The human brain has made a series of exciting developments, and there have been many breakthroughs in decoding signals such as speech and operations. It is particularly worth mentioning that Elon Musk’s Neuralink company has also made breakthrough progress in this field, with their disruptive development of brain interface technology.
The company successfully implanted electrodes in the brain of a test subject, enabling typing, gaming and other functions through simple cursor operations. This marks another step towards higher complexity neuro-speech/motor decoding. Compared with other brain-computer interface technologies, neuro-speech decoding is more complex, and its research and development work mainly relies on a special data source-electrocorticogram (ECoG).
The bed mainly takes care of the electrodermal chart data received during the patient's recovery process. The researchers used these electrodes to collect data on brain activity during vocalizations. These data not only have a high degree of temporal and spatial resolution, but have also achieved remarkable results in speech decoding research, greatly promoting the development of brain-computer interface technology. With the help of these advanced technologies, we are expected to see more people with neurological disorders regain the freedom to communicate in the future.
A breakthrough was achieved in a recent study published in Nature, which used quantified HuBERT features as an intermediate representation in a patient with an implanted device, combined with A pre-trained speech synthesizer converts these features into speech, an approach that not only improves the naturalness of speech but also maintains high accuracy.
However, HuBERT features cannot capture the unique acoustic characteristics of the speaker, and the generated sound is usually a unified speaker's voice, so additional models are still needed to combine this universal sound Convert to a specific patient's voice.
Another noteworthy point is that this study and most previous attempts adopted a non-causal architecture, which may limit its practical use in brain-computer interface applications that require causal operations. use.
On April 8, 2024, New York University VideoLab and Flinker Lab jointly published a breakthrough research in the magazine "Nature Machine Intelligence".
 Picture
Picture
Paper link: https://www.nature.com/articles/s42256-024-00824-8
Research related code open source is at https://github.com/flinkerlab/neural_speech_decoding
More generated speech examples are at: https://xc1490.github.io/nsd/
This research titled "A neural speech decoding framework leveraging deep learning and speech synthesis" introduces an innovative differentiable speech synthesizer.
The synthesizer combines a lightweight convolutional neural network to encode speech into a series of interpretable speech parameters such as pitch, loudness and formant frequency, and Re-synthesize speech using differentiable techniques.
This study successfully constructed a neural speech decoding system that is highly interpretable and applicable to small data sets by mapping neural signals to these specific speech parameters. This system can not only reconstruct high-fidelity and natural-sounding speech, but also provide an empirical basis for high accuracy in future brain-computer interface applications.
The research team collected a total of data from 48 subjects, and on this basis made an attempt to decode speech, providing a basis for the practical application and development of high-precision brain-computer interface technology. A solid foundation was laid.
Turing Award winner Lecun also forwarded the research progress.
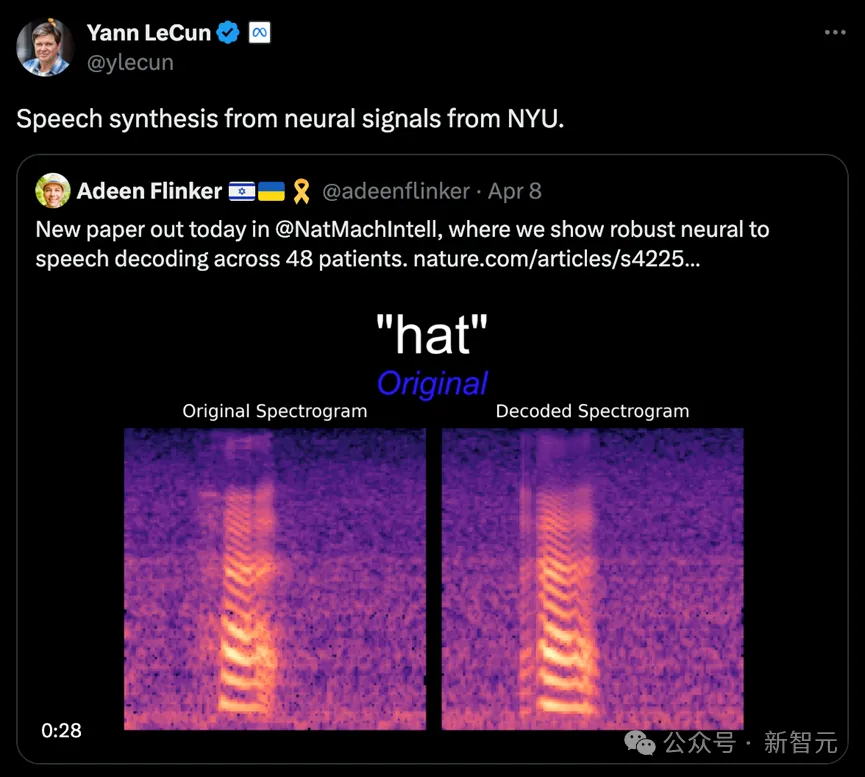 Picture
Picture
Research status
In the current neural signal to speech decoding During the research, we faced two core challenges.
The first is the limitation of the amount of data: in order to train a personalized neural-to-speech decoding model, the total amount of data available for each patient is usually only about ten minutes, which makes it difficult to rely on a large amount of training Data is a significant constraint for deep learning models.
Secondly, the high diversity of human speech also increases the complexity of modeling. Even if the same person pronounces and spells the same word repeatedly, factors such as his speaking speed, intonation, and pitch may change, adding additional difficulty to the construction of the model.
In early attempts, researchers mainly used linear models to decode neural signals into speech. This type of model does not require the support of a huge data set and has strong interpretability, but its accuracy is usually low.
Recently, with the advancement of deep learning technology, especially the application of convolutional neural network (CNN) and recurrent neural network (RNN), researchers are simulating the intermediate latent representation of speech. Extensive attempts have been made to improve the quality of synthesized speech.
For example, some studies decode cerebral cortex activity into mouth movements and then convert them into speech. Although this method is more powerful in decoding performance, the reconstructed sounds often sound Not natural enough.
In addition, some new methods try to use Wavenet vocoder and generative adversarial network (GAN) to reconstruct natural-sounding speech. Although these methods can improve the naturalness of the sound, they are There are still limitations in accuracy.
Main model framework
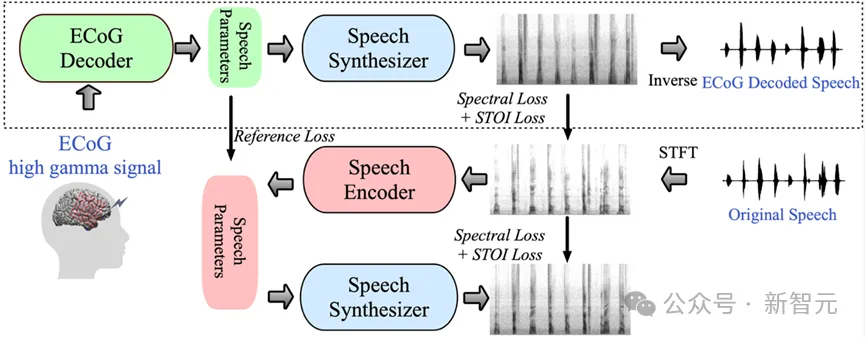
In this study, the research team demonstrated an innovative decoding framework from electroencephalogram (ECoG) signals to speech. They constructed a low-dimensional latent representation space generated by a lightweight speech encoding and decoding model using only speech signals.
This framework contains two core parts: The first is the ECoG decoder, which is responsible for converting the ECoG signal into a series of understandable acoustic speech parameters, such as pitch, whether to pronounce, Loudness and formant frequency, etc.; followed by the speech synthesizer part, which is responsible for converting these parameters into spectrograms.
By building a differentiable speech synthesizer, the researchers were able to train the ECoG decoder while also optimizing the speech synthesizer to jointly reduce the error in spectrogram reconstruction. The strong interpretability of this low-dimensional latent space, combined with the reference speech parameters generated by the lightweight pre-trained speech encoder, makes the entire neural speech decoding framework efficient and adaptable, effectively solving the problem of data scarcity in this field. .
In addition, this framework can not only generate natural speech that is very close to the speaker, but also supports the insertion of multiple deep learning model architectures in the ECoG decoder part and can perform causal operations.
The research team processed the ECoG data of 48 neurosurgery patients and used a variety of deep learning architectures (including convolution, recurrent neural network and Transformer) to achieve ECoG decoding.
These models have shown high accuracy in experiments, especially those using the ResNet convolutional architecture. This research framework not only achieves high accuracy through causal operations and a relatively low sampling rate (10mm interval), but also demonstrates the ability to effectively decode speech from both the left and right hemispheres of the brain, thereby extending the scope of applications of neural speech decoding To the right side of the brain.
 Picture
Picture
One of the core innovations of this research is the development of a differentiable speech Synthesizer, which greatly improves the efficiency of speech re-synthesis and can synthesize high-fidelity audio close to the original sound.
The design of this speech synthesizer is inspired by the human vocal system and subdivides speech into two parts: Voice (mainly used for vowel simulation) and Unvoice (mainly used for vowel simulation) for the simulation of consonants).
In the Voice part, the fundamental frequency signal is first used to generate harmonics, and then passed through a filter composed of F1 to F6 formants to obtain the spectral characteristics of the vowels.
For the Unvoice part, the corresponding spectrum is generated by performing specific filtering on the white noise. A learnable parameter controls the mixing ratio of the two parts at each time point.
Finally, the final speech spectrum is generated by adjusting the loudness signal and adding background noise.
Based on this speech synthesizer, the research team designed an efficient speech resynthesis framework and neural-speech decoding framework. For detailed frame structure, please refer to Figure 6 of the original article.
Research results
1. Speech decoding results with temporal causality
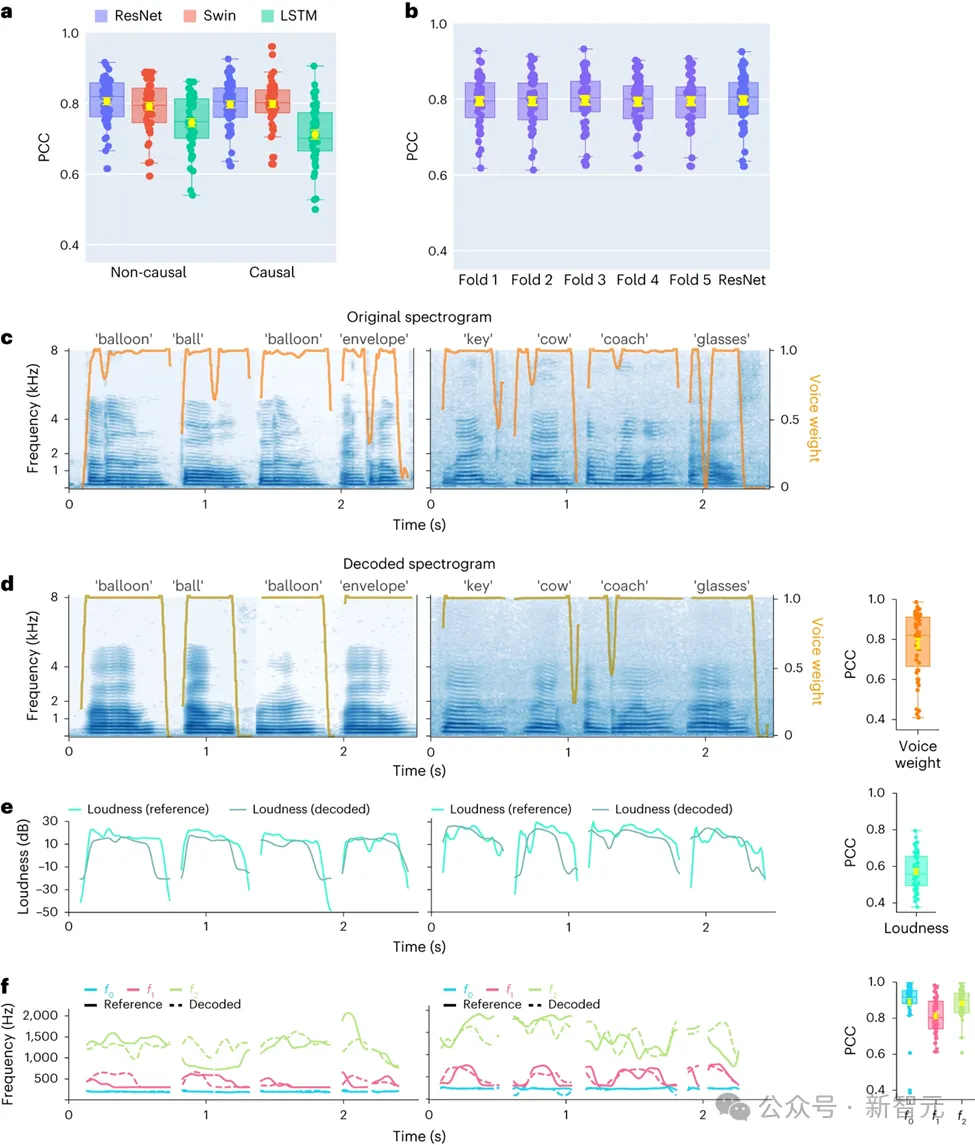
In this study, the researchers First, a direct comparison of different model architectures, including convolutional networks (ResNet), recurrent neural networks (LSTM), and Transformer architectures (3D Swin), was conducted to evaluate their differences in speech decoding performance.
It is worth noting that these models can perform non-causal or causal operations on time series.
 Picture
Picture
Decoding the cause and effect of models in applications of brain-computer interfaces (BCI) This has important implications: Causal models only use past and current neural signals to generate speech, while acausal models also refer to future neural signals, which is not feasible in practice.
Therefore, the focus of the research is to compare the performance of the same model when performing causal and non-causal operations. The results show that even the causal version of the ResNet model has performance comparable to the non-causal version, with no significant performance difference between the two.
Similarly, the causal and non-causal versions of the Swin model perform similarly, but the causal version of the LSTM performs significantly lower than its non-causal version. The study also demonstrated average decoding accuracy (total number of 48 samples) for several key speech parameters, including sound weight (the parameter that distinguishes vowels from consonants), loudness, fundamental frequency f0, first formant f1 and second formant f1. Formant f2.
Accurate reconstruction of these speech parameters, particularly the fundamental frequency, sound weight, and first two formants, is critical to achieving accurate speech decoding and natural reproduction of participant voices .
The research results show that both non-causal and causal models can provide reasonable decoding effects, which provides positive inspiration for future related research and applications.
2. Research on speech decoding and spatial sampling rate of left and right brain neural signals
In the latest study, researchers further explored the left and right brain Hemispheric performance differences in speech decoding.
Traditionally, most research has focused on the left hemisphere, which is closely related to speech and language functions.
 Picture
Picture
However, what we know about the right brain hemisphere’s ability to decode verbal information is Still very limited. To explore this area, the research team compared the decoding performance of the participants' left and right hemispheres, verifying the feasibility of using the right hemisphere for speech recovery.
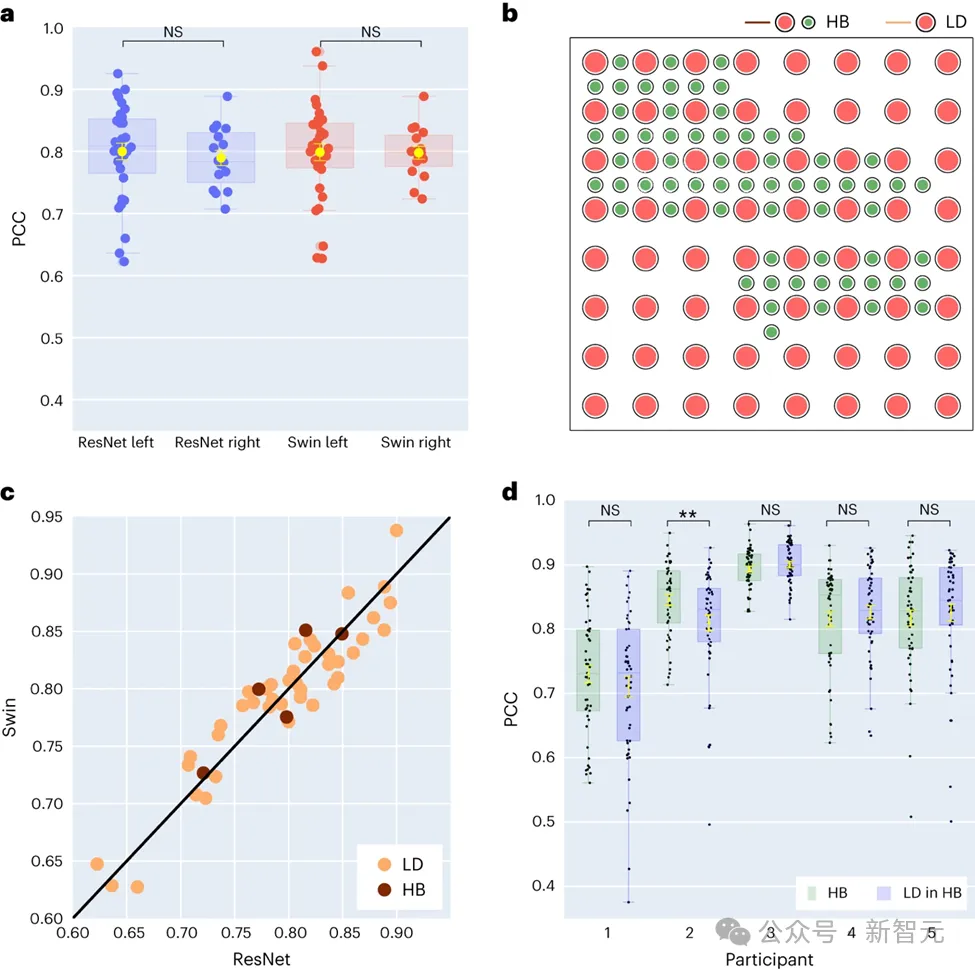
Of the 48 subjects collected in the study, 16 had ECoG signals from the right brain. By comparing the performance of ResNet and Swin decoders, researchers found that the right hemisphere can also effectively decode speech, and its effect is similar to that of the left hemisphere. The discovery provides a possible language restoration option for patients with damage to the left side of the brain who have lost language function.
The research also involves the impact of electrode sampling density on the speech decoding effect. Previous studies mostly used higher density electrode grids (0.4 mm), while the density of electrode grids commonly used in clinical practice is lower (1 cm).
Five participants in this study used hybrid-type (HB) electrode grids, which are primarily low-density but with some additional electrodes added. Low-density sampling was used for the remaining forty-three participants.
The results show that the decoding performance of these hybrid sampling (HB) is similar to that of traditional low-density sampling (LD), indicating that the model can effectively extract data from cerebral cortex electrode grids of different densities. Learn voice information. This finding suggests that electrode sampling densities commonly used in clinical settings may be sufficient to support future brain-computer interface applications.
3. Research on the contribution of different brain areas of the left and right brain to speech decoding
The researchers also explored speech-related areas in the brain role in the speech decoding process, which has important implications for the possible future implantation of speech restoration devices in the left and right brain hemispheres. To evaluate the impact of different brain regions on speech decoding, the research team used occlusion analysis.
By comparing the causal and non-causal models of ResNet and Swin decoders, the study found that in the non-causal model, the role of the auditory cortex is more significant. This result highlights the need to use causal models in real-time speech decoding applications that cannot rely on future neurofeedback signals.
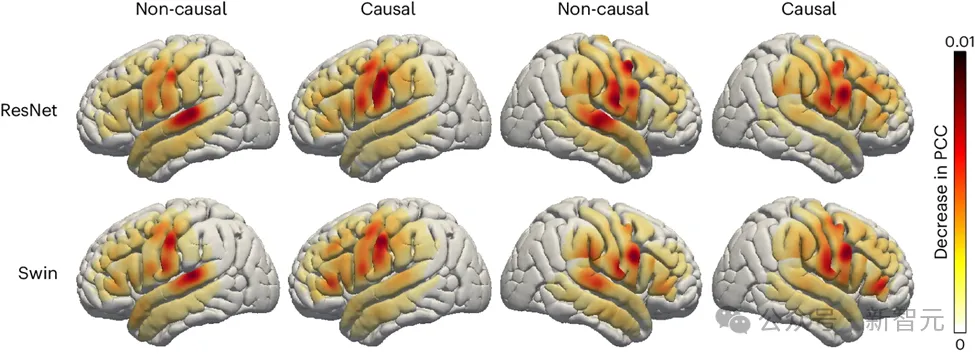 picture
picture
In addition, research also shows that the contribution of the sensorimotor cortex, especially the abdominal area, to speech decoding is similar whether in the left or right hemisphere of the brain. This finding suggests that implanting a neurological prosthesis in the right hemisphere to restore speech may be a viable option, providing important insights into future treatment strategies.
Conclusion (Inspiring Outlook)
The research team developed a new type of differentiable speech synthesizer that uses lightweight volume The product neural network encodes speech into a series of interpretable parameters such as pitch, loudness and formant frequency, and resynthesizes the speech using the same differentiable synthesizer.
By mapping neural signals to these parameters, the researchers built a neural speech decoding system that is highly interpretable and applicable to small data sets, capable of generating natural-sounding speech. .
This system demonstrated a high degree of reproducibility among 48 participants, was able to process data with different spatial sampling densities, and was able to process both left and right brain hemispheres simultaneously. electrical signals, demonstrating its strong potential in speech decoding.
Despite the significant progress, the researchers also pointed out some current limitations of the model, such as the fact that the decoding process relies on speech training data paired with ECoG recordings, which may be difficult for people with aphasia. not applicable.
In the future, the research team hopes to establish a model architecture that can handle non-grid data and more effectively utilize multi-patient and multi-modal EEG data. With the continuous advancement of hardware technology and the rapid development of deep learning technology, research in the field of brain-computer interface is still in its early stages, but as time goes by, the brain-computer interface vision in science fiction movies will gradually become a reality.
Reference:
https://www.nature.com/articles/s42256-024-00824-8
The first author of this article: Xupeng Chen (xc1490@nyu.edu), Ran Wang, corresponding author: Adeen Flinker
For more discussion of causality in neural speech decoding, you can Refer to another paper by the authors:
https://www.pnas.org/doi/10.1073/pnas.2300255120
The above is the detailed content of LeCun forwarded, AI allows aphasic people to speak again! NYU releases new 'neural-speech” decoder. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What are the types of return values of c language function? Summary of types of return values of c language function?
Apr 03, 2025 pm 11:18 PM
What are the types of return values of c language function? Summary of types of return values of c language function?
Apr 03, 2025 pm 11:18 PM
The return value types of C language function include int, float, double, char, void and pointer types. int is used to return integers, float and double are used to return floats, and char returns characters. void means that the function does not return any value. The pointer type returns the memory address, be careful to avoid memory leakage.结构体或联合体可返回多个相关数据。
 Concept of c language function
Apr 03, 2025 pm 10:09 PM
Concept of c language function
Apr 03, 2025 pm 10:09 PM
C language functions are reusable code blocks. They receive input, perform operations, and return results, which modularly improves reusability and reduces complexity. The internal mechanism of the function includes parameter passing, function execution, and return values. The entire process involves optimization such as function inline. A good function is written following the principle of single responsibility, small number of parameters, naming specifications, and error handling. Pointers combined with functions can achieve more powerful functions, such as modifying external variable values. Function pointers pass functions as parameters or store addresses, and are used to implement dynamic calls to functions. Understanding function features and techniques is the key to writing efficient, maintainable, and easy to understand C programs.
 How to calculate c-subscript 3 subscript 5 c-subscript 3 subscript 5 algorithm tutorial
Apr 03, 2025 pm 10:33 PM
How to calculate c-subscript 3 subscript 5 c-subscript 3 subscript 5 algorithm tutorial
Apr 03, 2025 pm 10:33 PM
The calculation of C35 is essentially combinatorial mathematics, representing the number of combinations selected from 3 of 5 elements. The calculation formula is C53 = 5! / (3! * 2!), which can be directly calculated by loops to improve efficiency and avoid overflow. In addition, understanding the nature of combinations and mastering efficient calculation methods is crucial to solving many problems in the fields of probability statistics, cryptography, algorithm design, etc.
 distinct function usage distance function c usage tutorial
Apr 03, 2025 pm 10:27 PM
distinct function usage distance function c usage tutorial
Apr 03, 2025 pm 10:27 PM
std::unique removes adjacent duplicate elements in the container and moves them to the end, returning an iterator pointing to the first duplicate element. std::distance calculates the distance between two iterators, that is, the number of elements they point to. These two functions are useful for optimizing code and improving efficiency, but there are also some pitfalls to be paid attention to, such as: std::unique only deals with adjacent duplicate elements. std::distance is less efficient when dealing with non-random access iterators. By mastering these features and best practices, you can fully utilize the power of these two functions.
 What are the differences and connections between c and c#?
Apr 03, 2025 pm 10:36 PM
What are the differences and connections between c and c#?
Apr 03, 2025 pm 10:36 PM
Although C and C# have similarities, they are completely different: C is a process-oriented, manual memory management, and platform-dependent language used for system programming; C# is an object-oriented, garbage collection, and platform-independent language used for desktop, web application and game development.
 What does the c language function return pointer output?
Apr 03, 2025 pm 11:36 PM
What does the c language function return pointer output?
Apr 03, 2025 pm 11:36 PM
The C language function returns a pointer to output a memory address. The pointing content depends on the operation inside the function, which may point to local variables (be careful, memory has been released after the function ends), dynamically allocated memory (must be allocated with malloc and free), or global variables.
 What are the pointer parameters in the parentheses of the C language function?
Apr 03, 2025 pm 11:48 PM
What are the pointer parameters in the parentheses of the C language function?
Apr 03, 2025 pm 11:48 PM
The pointer parameters of C language function directly operate the memory area passed by the caller, including pointers to integers, strings, or structures. When using pointer parameters, you need to be careful to modify the memory pointed to by the pointer to avoid errors or memory problems. For double pointers to strings, modifying the pointer itself will lead to pointing to new strings, and memory management needs to be paid attention to. When handling pointer parameters to structures or arrays, you need to carefully check the pointer type and boundaries to avoid out-of-bounds access.
 What are the formats of function definition in C language?
Apr 03, 2025 pm 11:51 PM
What are the formats of function definition in C language?
Apr 03, 2025 pm 11:51 PM
The key elements of C function definition include: return type (defining the value returned by the function), function name (following the naming specification and determining the scope), parameter list (defining the parameter type, quantity and order accepted by the function) and function body (implementing the logic of the function). It is crucial to clarify the meaning and subtle relationship of these elements, and can help developers avoid "pits" and write more efficient and elegant code.
