
 Technology peripherals
AI
HKU's large open source graph basic model OpenGraph: strong generalization ability, forward propagation to predict new data
Technology peripherals
AI
HKU's large open source graph basic model OpenGraph: strong generalization ability, forward propagation to predict new data
HKU's large open source graph basic model OpenGraph: strong generalization ability, forward propagation to predict new data

The data starvation problem in the field of graph learning has new tricks that can alleviate it!
OpenGraph, a basic graph-based model specifically designed for zero-shot prediction on a variety of graph datasets.
Chao Huang’s team, head of the Data Intelligence Laboratory at the University of Hong Kong, also proposed improvement and adjustment techniques for the model to improve the model’s adaptability to new tasks.
Currently, this work has been posted on GitHub.
Introducing data augmentation technology, this work mainly explores in-depth strategies to enhance the generalization ability of graph models (especially when there are significant differences between training and test data).
OpenGraph is a general graph structure model that performs forward propagation through propagation prediction to achieve zero-sample prediction of new data.
In order to achieve the goal, the team solved the following 3 challenges:
- Token differences between data sets: Different graph data sets often have different graph token sets, and we need the model to be able to predict across data sets.
- Node relationship modeling: When building a general graph model, it is crucial to effectively model node relationships, which is related to the scalability and efficiency of the model.
- Data scarcity: Faced with the problem of data acquisition, we perform data enhancement through large language models to simulate complex graph structure relationships and improve the quality of model training.
Through a series of innovative methods, such as topology-aware BERT Tokenizer and anchor-based graph Transformer, OpenGraph effectively addresses the above challenges. Test results on multiple data sets demonstrate the model's excellent generalization ability and enable effective evaluation of the model's color generalization ability.
OpenGraph model
The OpenGraph model architecture mainly consists of 3 core parts:
- Unified graph Tokenizer.
- Extensible graph Transformer.
- Knowledge distillation technology based on large language model.
First let’s talk about the unified graph Tokenizer.
In order to adapt to the differences in nodes and edges in different data sets, the team developed a unified graph Tokenizer, which normalizes graph data into a token sequence.
This process includes high-order adjacency matrix smoothing and topology-aware mapping.
High-order adjacency matrix smoothing uses the high-order power of the adjacency matrix to solve the problem of sparse connections, while topology-aware mapping converts the adjacency matrix into a node sequence and uses fast singular value decomposition (SVD) Minimize information loss and retain more graph structure information.
The second is the extensible graph Transformer.
After tokenization, OpenGraph uses the Transformer architecture to simulate the dependencies between nodes, and mainly uses the following technologies to optimize model performance and efficiency:
First, token sequence sampling, reducing model needs through sampling technology The number of relations processed thereby reduces the time and space complexity of training.
The second is the self-attention mechanism of anchor point sampling. This method further reduces the computational complexity and effectively improves the training efficiency and stability of the model through the information transfer between learning nodes in stages.
The last step is knowledge distillation of large language models.
In order to deal with the data privacy and category diversity issues faced when training general graph models, the team drew inspiration from the knowledge and understanding capabilities of large language models (LLM) and used LLM to generate various graph structure data.
This data enhancement mechanism effectively improves the quality and practicality of data by simulating the characteristics of real-world graphs.
The team also first generated a set of nodes adapted to the specific application, with each node having a textual description in order to generate edges.
When faced with large-scale node sets such as e-commerce platforms, researchers deal with this by subdividing nodes into more specific subcategories.
For example, from "electronic products" to specific "mobile phones", "laptops", etc., this process is repeated until the nodes are refined enough to be close to real instances.
The prompt tree algorithm subdivides nodes according to the tree structure and generates more detailed entities.
Start from a general category such as "product", gradually refine it to specific subcategories, and finally form a node tree.
As for edge generation, using Gibbs sampling, researchers form edges based on the generated set of nodes.
In order to reduce the computational burden, we do not directly traverse all possible edges through LLM. Instead, we first use LLM to calculate the text similarity between nodes, and then use a simple algorithm to determine the node relationship.
On this basis, the team introduced several technical adjustments:
- Dynamic probability normalization: Through dynamic adjustment, the similarity is mapped to a probability range that is more suitable for sampling.
- Node locality: Introduces the concept of locality and only establishes connections between local subsets of nodes to simulate network locality in the real world.
- Graph topology mode injection: Use graph convolutional network to modify node representation to better adapt to graph structure characteristics and reduce distribution deviation.
The above steps ensure that the generated graph data is not only rich and diverse, but also close to the connection patterns and structural characteristics of the real world.
Experimental verification and performance analysis
It should be noted that this experiment focuses on training the OpenGraph model using a data set generated only by LLM, and testing it on a diverse real-life scenario data set, covering Node classification and link prediction tasks.
The experimental design is as follows:
Zero sample setting.
To evaluate OpenGraph's performance on unseen data, we train the model on a generated training set and then evaluate it on a completely different real-world test set. It ensures that the training and testing data have no overlap in nodes, edges and features.
Few sample settings.
Considering that it is difficult for many methods to effectively perform zero-sample prediction, we introduce a few-sample setting. After the baseline model is pre-trained on pre-training data, k-shot samples are used for fine-tuning.
Results on 2 tasks and 8 test sets show that OpenGraph significantly outperforms existing methods in zero-shot prediction.
Additionally, existing pre-trained models sometimes perform worse than models trained from scratch on cross-dataset tasks.
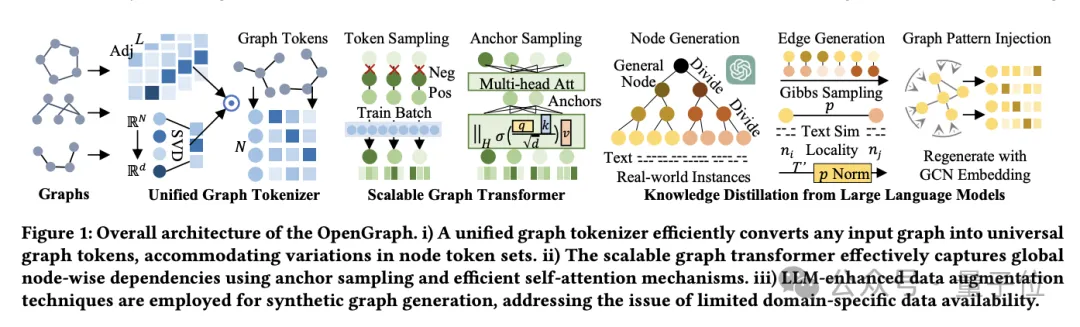
Study on the Impact of Graph Tokenizer Design
At the same time, the team explored how the design of graph Tokenizer affects model performance.
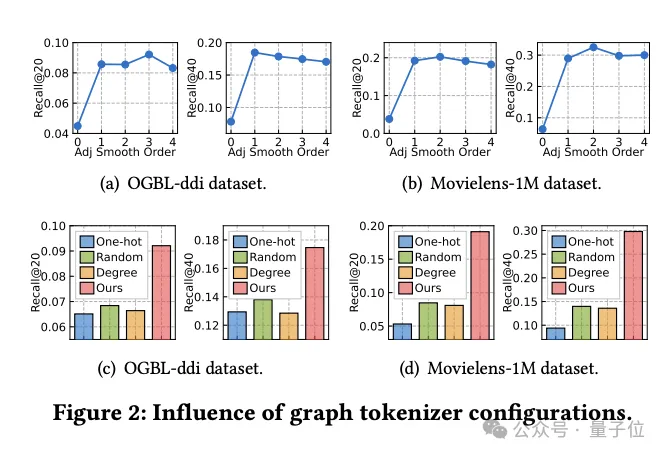
First of all, it was found through experiments that not smoothing the adjacency matrix (the smoothing order is 0) will significantly reduce the performance, indicating the necessity of smoothing.
The researchers then tried several simple topology-aware alternatives: one-hot encoded IDs across datasets, random mapping, and node degree-based representations.
Experimental results show that the performance of these alternatives is not ideal.
Specifically, ID representation across data sets is the worst, degree-based representation also performs poorly, and random mapping, although slightly better, has a significant performance gap compared with optimized topology-aware mapping.
Impact of data generation techniques
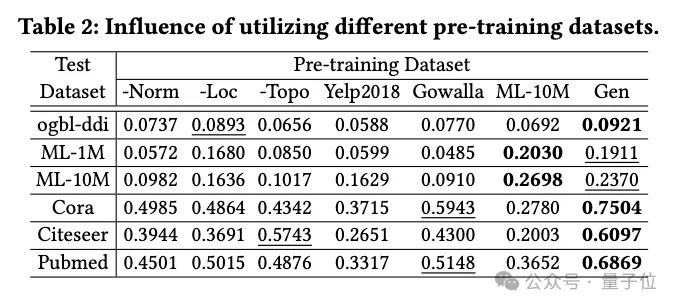
The team investigated the impact of different pre-training datasets on OpenGraph performance, including those generated using LLM-based knowledge distillation methods dataset, as well as several real datasets.
The pre-training data sets compared in the experiment include the data set after removing a certain technology from the team generation method, and 2 real data sets that have nothing to do with the test data set (Yelp2018 and Gowalla), 1 real data set (ML-10M) similar to the test data set.
The experimental results show that the generated data set shows good performance on all test sets; the removal of the three generation techniques significantly affects the performance, verifying the effectiveness of these techniques.
When training using real datasets that are independent of the test set (such as Yelp and Gowalla) Performance sometimes degrades, possibly due to distribution differences between different datasets.
The ML-10M dataset achieves the best performance on similar test datasets (such as ML-1M and ML-10M) , highlighting the similarity between the training and test datasets The importance of sex.
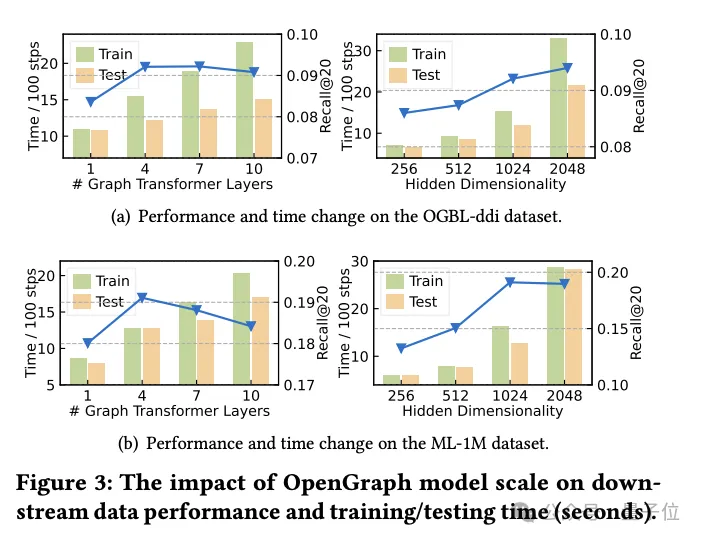
Research on Transformer sampling technology
In this part of the experiment, the research team explored two sampling techniques used in the graph Transformer module:
Token sequence sampling (Seq) and anchor sampling (Anc).
They conducted detailed ablation experiments on these two sampling methods to evaluate their specific impact on model performance.
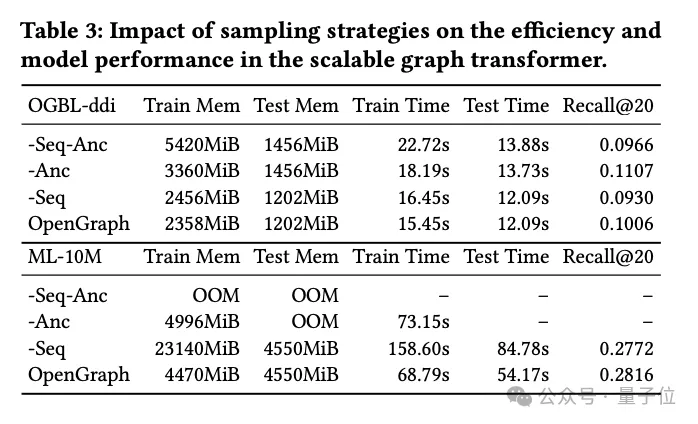
Experimental results show that whether it is token sequence sampling or anchor point sampling, both can effectively reduce the space and time complexity of the model during the training and testing phases. This is especially important for processing large-scale graph data and can significantly improve efficiency.
From a performance perspective, token sequence sampling has a positive impact on the overall performance of the model. This sampling strategy optimizes the representation of the graph by selecting key tokens, thereby improving the model's ability to handle complex graph structures.
In contrast, experiments on the ddi dataset show that anchor sampling may have a negative impact on model performance. Anchor sampling simplifies the graph structure by selecting specific nodes as anchor points, but this method may ignore some key graph structure information, thus affecting the accuracy of the model.
In summary, although both sampling techniques have their advantages, in practical applications, the appropriate sampling strategy needs to be carefully selected based on specific data sets and task requirements.
Research Conclusion
This research aims to develop a highly adaptable framework that can accurately identify and parse complex topological patterns of various graph structures.
The researchers' goal is to significantly enhance the model's generalization ability in zero-shot graph learning tasks, including a variety of downstream applications, by fully leveraging the capabilities of the proposed model.
The model is built with the support of a scalable graph Transformer architecture and LLM-enhanced data augmentation mechanism to improve the efficiency and robustness of OpenGraph.
Through extensive testing on multiple standard datasets, the team demonstrated the model’s excellent generalization performance.
It is understood that as an initial attempt to build a graph-based model, in the future, the team's work will focus on increasing the automation capabilities of the framework, including automatically identifying noisy connections and conducting counterfactuals study.
At the same time, the team plans to learn and extract common and transferable patterns of various graph structures to further promote the application scope and effect of the model.
Reference link:
[1] Paper: https://arxiv.org/pdf/2403.01121.pdf.
[2] Source code library: https://github.com/HKUDS/OpenGraph.
The above is the detailed content of HKU's large open source graph basic model OpenGraph: strong generalization ability, forward propagation to predict new data. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to install deepseek
Feb 19, 2025 pm 05:48 PM
How to install deepseek
Feb 19, 2025 pm 05:48 PM
There are many ways to install DeepSeek, including: compile from source (for experienced developers) using precompiled packages (for Windows users) using Docker containers (for most convenient, no need to worry about compatibility) No matter which method you choose, Please read the official documents carefully and prepare them fully to avoid unnecessary trouble.
 Summary of FAQs for DeepSeek usage
Feb 19, 2025 pm 03:45 PM
Summary of FAQs for DeepSeek usage
Feb 19, 2025 pm 03:45 PM
DeepSeekAI Tool User Guide and FAQ DeepSeek is a powerful AI intelligent tool. This article will answer some common usage questions to help you get started quickly. FAQ: The difference between different access methods: There is no difference in function between web version, App version and API calls, and App is just a wrapper for web version. The local deployment uses a distillation model, which is slightly inferior to the full version of DeepSeek-R1, but the 32-bit model theoretically has 90% full version capability. What is a tavern? SillyTavern is a front-end interface that requires calling the AI model through API or Ollama. What is breaking limit
 What are the AI tools?
Nov 29, 2024 am 11:11 AM
What are the AI tools?
Nov 29, 2024 am 11:11 AM
AI tools include: Doubao, ChatGPT, Gemini, BlenderBot, etc.
 What are the Grayscale Encryption Trust Funds? Common Grayscale Encryption Trust Funds Inventory
Mar 05, 2025 pm 12:33 PM
What are the Grayscale Encryption Trust Funds? Common Grayscale Encryption Trust Funds Inventory
Mar 05, 2025 pm 12:33 PM
Grayscale Investment: The channel for institutional investors to enter the cryptocurrency market. Grayscale Investment Company provides digital currency investment services to institutions and investors. It allows investors to indirectly participate in cryptocurrency investment through the form of trust funds. The company has launched several crypto trusts, which has attracted widespread market attention, but the impact of these funds on token prices varies significantly. This article will introduce in detail some of Grayscale's major crypto trust funds. Grayscale Major Crypto Trust Funds Available at a glance Grayscale Investment (founded by DigitalCurrencyGroup in 2013) manages a variety of crypto asset trust funds, providing institutional investors and high-net-worth individuals with compliant investment channels. Its main funds include: Zcash (ZEC), SOL,
 As top market makers enter the crypto market, what impact will Castle Securities have on the industry?
Mar 04, 2025 pm 08:03 PM
As top market makers enter the crypto market, what impact will Castle Securities have on the industry?
Mar 04, 2025 pm 08:03 PM
The entry of top market maker Castle Securities into Bitcoin market maker is a symbol of the maturity of the Bitcoin market and a key step for traditional financial forces to compete for future asset pricing power. At the same time, for retail investors, it may mean the gradual weakening of their voice. On February 25, according to Bloomberg, Citadel Securities is seeking to become a liquidity provider for cryptocurrencies. The company aims to join the list of market makers on various exchanges, including exchanges operated by CoinbaseGlobal, BinanceHoldings and Crypto.com, people familiar with the matter said. Once approved by the exchange, the company initially planned to set up a market maker team outside the United States. This move is not only a sign
 Delphi Digital: How to change the new AI economy by parsing the new ElizaOS v2 architecture?
Mar 04, 2025 pm 07:00 PM
Delphi Digital: How to change the new AI economy by parsing the new ElizaOS v2 architecture?
Mar 04, 2025 pm 07:00 PM
ElizaOSv2: Empowering AI and leading the new economy of Web3. AI is evolving from auxiliary tools to independent entities. ElizaOSv2 plays a key role in it, which gives AI the ability to manage funds and operate Web3 businesses. This article will dive into the key innovations of ElizaOSv2 and how it shapes an AI-driven future economy. AI Automation: Going to independently operate ElizaOS was originally an AI framework focusing on Web3 automation. v1 version allows AI to interact with smart contracts and blockchain data, while v2 version achieves significant performance improvements. Instead of just executing simple instructions, AI can independently manage workflows, operate business and develop financial strategies. Architecture upgrade: Enhanced A
 Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Researchers from Shanghai Jiaotong University, Shanghai AILab and the Chinese University of Hong Kong have launched the Visual-RFT (Visual Enhancement Fine Tuning) open source project, which requires only a small amount of data to significantly improve the performance of visual language big model (LVLM). Visual-RFT cleverly combines DeepSeek-R1's rule-based reinforcement learning approach with OpenAI's reinforcement fine-tuning (RFT) paradigm, successfully extending this approach from the text field to the visual field. By designing corresponding rule rewards for tasks such as visual subcategorization and object detection, Visual-RFT overcomes the limitations of the DeepSeek-R1 method being limited to text, mathematical reasoning and other fields, providing a new way for LVLM training. Vis
 Bitwise: Businesses Buy Bitcoin A Neglected Big Trend
Mar 05, 2025 pm 02:42 PM
Bitwise: Businesses Buy Bitcoin A Neglected Big Trend
Mar 05, 2025 pm 02:42 PM
Weekly Observation: Businesses Hoarding Bitcoin – A Brewing Change I often point out some overlooked market trends in weekly memos. MicroStrategy's move is a stark example. Many people may say, "MicroStrategy and MichaelSaylor are already well-known, what are you going to pay attention to?" This is true, but many investors regard it as a special case and ignore the deeper market forces behind it. This view is one-sided. In-depth research on the adoption of Bitcoin as a reserve asset in recent months shows that this is not an isolated case, but a major trend that is emerging. I predict that in the next 12-18 months, hundreds of companies will follow suit and buy large quantities of Bitcoin
