
 Technology peripherals
AI
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
Technology peripherals
AI
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)

Written before&The author’s personal understanding
This paper is dedicated to solving the key problems of current multi-modal large language models (MLLMs) in autonomous driving applications The challenge is to extend MLLMs from 2D understanding to the problem of 3D space. This expansion is particularly important as autonomous vehicles (AVs) need to make accurate decisions about 3D environments. 3D spatial understanding is critical for AVs because it directly impacts the vehicle’s ability to make informed decisions, predict future states, and interact safely with the environment.
Current multi-modal large language models (such as LLaVA-1.5) can often only handle lower resolution image inputs (for example) due to the visual encoder The resolution limit and the LLM sequence length limit. However, autonomous driving applications require high-resolution multi-view video input to ensure that vehicles can perceive the environment and make safe decisions over long distances. Furthermore, many existing 2D model architectures struggle to efficiently handle these inputs because they require extensive computing and storage resources. To address these issues, researchers are working to develop new model architectures and storage resources.
In this context, this article proposes a new 3D MLLM architecture, drawing on Q-Former style design. The architecture employs a cross-attention decoder to compress high-resolution visual information into sparse queries, making it easier to scale to high-resolution inputs. This architecture has similarities with families of perspective models such as DETR3D, PETR(v2), StreamPETR, and Far3D, as they all leverage sparse 3D query mechanisms. By appending 3D positional encoding to these queries and interacting with multi-view input, our architecture achieves 3D spatial understanding and thereby better leverages pre-trained knowledge in 2D images.
In addition to the innovation of model architecture, this article also proposes a more challenging benchmark-OmniDrive-nuScenes. The benchmark covers a range of complex tasks requiring 3D spatial understanding and long-range reasoning, and introduces a counterfactual reasoning benchmark to evaluate results by simulating solutions and trajectories. This benchmark effectively makes up for the problem of biasing towards a single expert trajectory in current open-ended evaluations, thus avoiding overfitting on expert trajectories.
This article introduces OmniDrive, a comprehensive end-to-end autonomous driving framework, which provides an effective 3D reasoning and planning model based on LLM-agent and builds a more challenging benchmark, promoting further development in the field of autonomous driving. The specific contributions are as follows:
- Proposed a 3D Q-Former architecture, which is suitable for various driving-related tasks, including target detection, lane detection, 3D visual positioning, and decision making and planning.
- Introducing the OmniDrive-nuScenes benchmark, the first QA benchmark designed to address planning-related challenges, covering accurate 3D spatial information.
- Achieved the best performance on planning tasks.
Detailed explanation of OmniDrive
##Overall structure
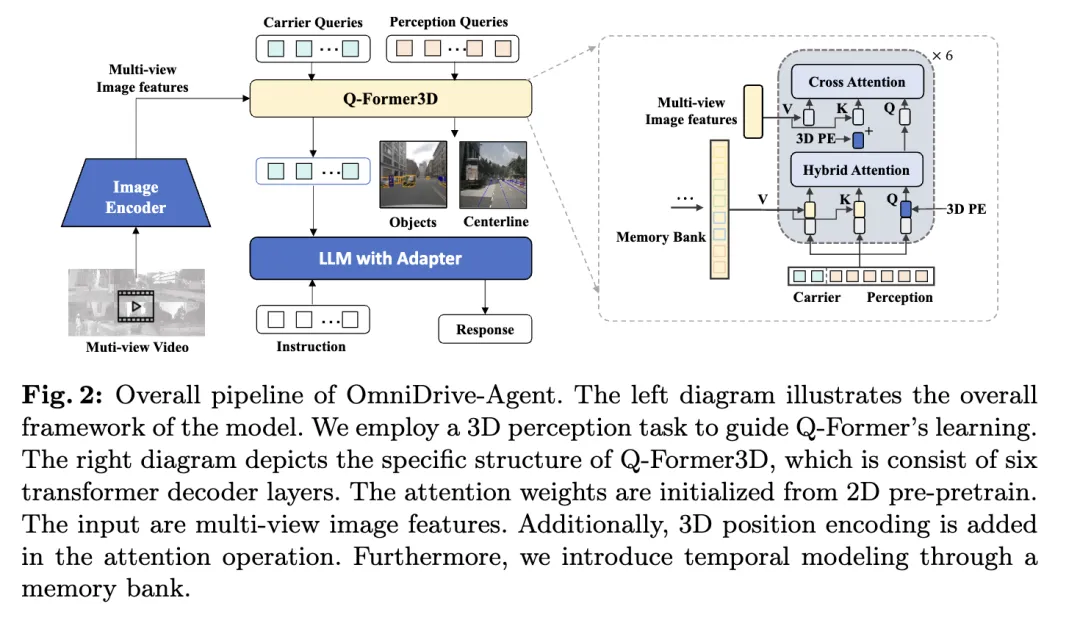
The OmniDrive proposed in this article -Agent combines the advantages of Q-Former and query-based 3D perception models to efficiently obtain 3D spatial information from multi-view image features and solve 3D perception and planning tasks in autonomous driving. The overall architecture is shown in the figure.- Visual Encoder: First, a shared visual encoder is used to extract multi-view image features.
- Position encoding : Input the extracted image features and position encoding into Q-Former3D.
- Q-Former3D module: Among them, represents the splicing operation. For the sake of brevity, positional encoding is omitted from the formula. After this step, the query collection becomes the interactive . Among them, represents 3D position coding, and is a multi-view image feature.
- Multi-view image feature collection: Next, these queries collect information from multi-view images:
- Query initialization and automatic Attention: In Q-Former3D, initialize the detection query and carrier query, and perform self-attention operations to exchange information between them:
- Output processing :
- Perceptual task prediction : Predict the category and coordinates of foreground elements using perceptual queries.
- Carrier query alignment and text generation: The carrier query is aligned to the dimensions of the LLM token (such as the 4096 dimension in LLaMA) through a single-layer MLP, and is further used for text generation.
- The role of carrier query
Multi-task and Temporal Modeling
The author’s method benefits from multi-task learning and temporal modeling. In multi-task learning, the author can integrate specific Q-Former3D modules for each perception task and adopt a unified initialization strategy (see \cref{Training Strategy}). In different tasks, carrier queries can collect information about different traffic elements. The author's implementation covers tasks such as centerline construction and 3D object detection. During training and inference phases, these modules share the same 3D position encoding. Our method enriches tasks such as centerline construction and 3D object detection. During training and inference phases, these modules share the same 3D position encoding. Our method enriches tasks such as centerline construction and 3D object detection. During training and inference phases, these modules share the same 3D position encoding.
Regarding temporal modeling, the authors store perceptual queries with top-k classification scores in the memory bank and propagate them frame by frame. The propagated query interacts with the perceptual query and carrier query of the current frame through cross-attention, thereby extending the model's processing capabilities for video input.
Training Strategy
The training strategy of OmniDrive-Agent is divided into two stages: 2D pre-training and 3D fine-tuning. In the initial stage, the authors first pre-trained multi-modal large models (MLLMs) on 2D image tasks to initialize Q-Former and vector queries. After removing the detection query, the OmniDrive model can be regarded as a standard visual language model, capable of generating text based on images. Therefore, the author used the training strategy and data of LLaVA v1.5 to pre-train OmniDrive on 558K image and text pairs. During pre-training, all parameters remain frozen except Q-Former. Subsequently, the MLLMs were fine-tuned using the instruction tuning dataset of LLaVA v1.5. During fine-tuning, the image encoder remains frozen and other parameters can be trained.
In the 3D fine-tuning stage, the goal is to enhance the 3D positioning capabilities of the model while retaining its 2D semantic understanding capabilities as much as possible. To this end, the author added 3D position encoding and timing modules to the original Q-Former. At this stage, the author uses LoRA technology to fine-tune the visual encoder and large language model with a small learning rate, and train Q-Former3D with a relatively large learning rate. In these two stages, OmniDrive-Agent’s loss calculation only includes the text generation loss, without considering the contrastive learning and matching losses in BLIP-2.
OmniDrive-nuScenes

#To benchmark driving multi-modal large model agents, the authors proposed OmniDrive-nuScenes, This is a novel benchmark based on the nuScenes dataset, containing high-quality visual question answering (QA) pairs covering perception, reasoning and planning tasks in the 3D domain.
The highlight of OmniDrive-nuScenes is its fully automated QA generation process, which uses GPT-4 to generate questions and answers. Similar to LLaVA, our pipeline provides 3D-aware annotations as contextual information to GPT-4. On this basis, the author further uses traffic rules and planning simulation as additional input to help GPT-4 better understand the 3D environment. The author's benchmark not only tests the model's perception and reasoning capabilities, but also challenges the model's real spatial understanding and planning capabilities in 3D space through long-term problems involving attention, counterfactual reasoning, and open-loop planning, as these problems require Driving planning in the next few seconds is simulated to arrive at the correct answer.
In addition to the generation process for offline question and answer, the author also proposes a process for online generation of diverse positioning questions. This process can be seen as an implicit data enhancement method to improve the model's 3D spatial understanding and reasoning capabilities.
Offline Question-Answering
In the offline QA generation process, the author uses contextual information to generate QA pairs on nuScenes. First, the author uses GPT-4 to generate a scene description, and splices the three-perspective front view and the three-perspective rear view into two independent images and inputs them into GPT-4. Through prompt input, GPT-4 can describe information such as weather, time, scene type, etc., and identify the direction of each viewing angle. At the same time, it avoids description by viewing angle, but describes the content relative to the position of the own vehicle.
Next, in order for GPT-4V to better understand the relative spatial relationship between traffic elements, the author represents the relationship between objects and lane lines into a file tree-like structure, and based on the 3D bounding box of the object , convert its information into natural language description.
The author then generated trajectories by simulating different driving intentions, including lane keeping, left lane changing, and right lane changing, and used a depth-first search algorithm to connect the lane center lines to generate all possible driving path. In addition, the author clustered the self-vehicle trajectories in the nuScenes data set, selected representative driving paths, and used them as part of the simulated trajectory.
Ultimately, by combining different contextual information in the offline QA generation process, the authors are able to generate multiple types of QA pairs, including scene description, attention object recognition, counterfactual reasoning, and decision planning. GPT-4 can identify threat objects based on simulations and expert trajectories, and give reasonable driving suggestions by reasoning about the safety of the driving path.

Online Question-Answering
In order to make full use of the 3D perceptual annotation in the autonomous driving data set, the author uses online method to generate a large number of positioning tasks. These tasks are designed to enhance the model's 3D spatial understanding and reasoning capabilities, including:
- 2D to 3D localization: Given a 2D bounding box on a specific camera, the model needs to provide a corresponding 3D properties of objects, including category, position, size, orientation and speed.
- 3D distance: Based on randomly generated 3D coordinates, identify traffic elements near the target location and provide their 3D attributes.
- Lane to Object: Based on a randomly selected lane centerline, list all objects on that lane and their 3D properties.
Metrics
The OmniDrive-nuScenes dataset involves scene description, open-loop planning and counterfactual reasoning tasks. Each task focuses on different aspects, making it difficult to evaluate using a single metric. Therefore, the authors designed different evaluation criteria for different tasks.
For scene description related tasks (such as scene description and attention object selection), the author uses commonly used language evaluation indicators, including METEOR, ROUGE and CIDEr to evaluate sentence similarity. In the open-loop planning task, the authors used collision rates and road boundary crossing rates to evaluate the performance of the model. For the counterfactual reasoning task, the authors use GPT-3.5 to extract keywords in predictions and compare these keywords with the ground truth to calculate precision and recall for different accident categories.
Experimental results
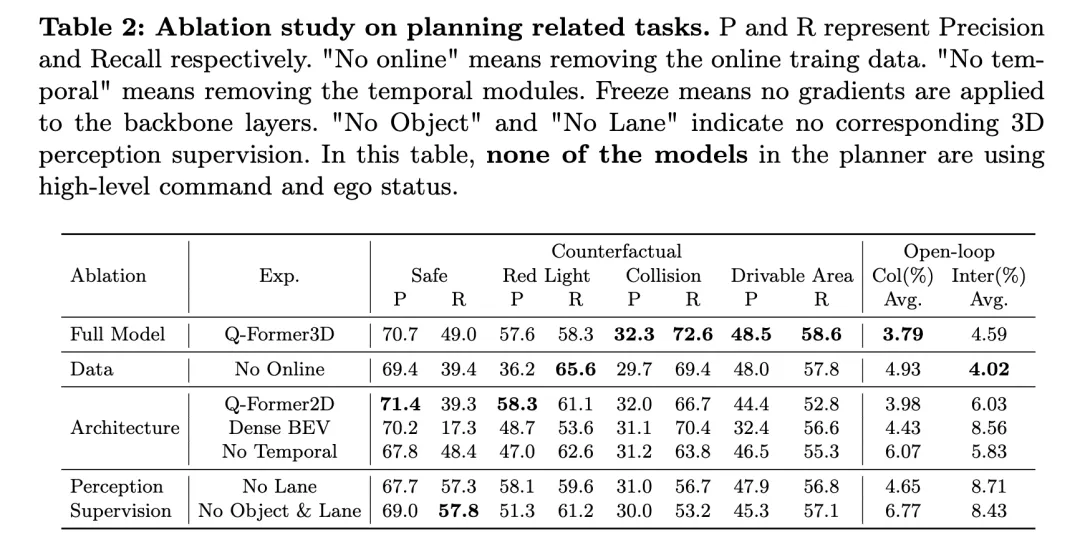
#The above table shows the results of ablation research on planning-related tasks, including counterfactual reasoning and open-loop planning performance evaluation.
The full model, Q-Former3D, performs well on both counterfactual reasoning and open-loop planning tasks. In the counterfactual reasoning task, the model demonstrated high precision and recall rates in both the "red light violation" and "accessible area violation" categories, which were 57.6%/58.3% and 48.5%/58.6% respectively. At the same time, the model achieved the highest recall rate (72.6%) in the "collision" category. In the open-loop planning task, Q-Former3D performed well in both the average collision rate and road boundary intersection rate, reaching 3.79% and 4.59% respectively.
After removing the online training data (No Online), the recall rate of the "red light violation" category in the counterfactual reasoning task increased (65.6%), but the overall performance decreased slightly. The precision rate and recall rate of collisions and passable area violations are slightly lower than those of the complete model, while the average collision rate of the open-loop planning task increased to 4.93%, and the average road boundary crossing rate dropped to 4.02%, which reflects the importance of online training data to The importance of improving the overall planning performance of the model.
In the architecture ablation experiment, the Q-Former2D version achieved the highest precision (58.3%) and high recall (61.1%) on the "red light violation" category, but the performance of other categories was not as good as the full model , especially the recall rates for the “collision” and “accessible area violation” categories dropped significantly. In the open-loop planning task, the average collision rate and road boundary intersection rate are higher than the full model, 3.98% and 6.03% respectively.
The model using Dense BEV architecture performs better on all categories of counterfactual reasoning tasks, but the overall recall rate is low. The average collision rate and road boundary intersection rate in the open-loop planning task reached 4.43% and 8.56% respectively.
When the temporal module is removed (No Temporal), the model's performance in the counterfactual reasoning task drops significantly, especially the average collision rate increases to 6.07% and the road boundary crossing rate reaches 5.83%.
In terms of perceptual supervision, after removing lane line supervision (No Lane), the recall rate of the model in the "collision" category dropped significantly, while the index performance of other categories of counterfactual reasoning tasks and open-loop planning tasks relatively stable. After completely removing the 3D perception supervision of objects and lane lines (No Object & Lane), the precision rate and recall rate of each category of the counterfactual reasoning task decreased, especially the recall rate of the "collision" category dropped to 53.2%. The average collision rate and road boundary intersection rate in the open-loop planning task increased to 6.77% and 8.43% respectively, which were significantly higher than the full model.
It can be seen from the above experimental results that the complete model performs well in counterfactual reasoning and open-loop planning tasks. Online training data, time modules, and 3D perception supervision of lane lines and objects play an important role in improving model performance. The complete model can effectively utilize multi-modal information for efficient planning and decision-making, and the results of the ablation experiment further verify the key role of these components in autonomous driving tasks.
At the same time, let’s look at the performance of NuScenes-QA: it demonstrates the performance of OmniDrive in open-loop planning tasks and compares it with other existing methods. The results show that OmniDrive (full version) achieves the best performance in all indicators, especially in the average error of open-loop planning, collision rate and road boundary intersection rate, which is better than other methods.
Performance of OmniDrive: The OmniDrive model has L2 average errors of 0.14, 0.29 and 0.55 meters in the prediction time of 1 second, 2 seconds and 3 seconds respectively, and the final average error is only 0.33 rice. In addition, the average collision rate and average road boundary intersection rate of this model also reached 0.30% and 3.00% respectively, which are much lower than other methods. Especially in terms of collision rate, OmniDrive achieved zero collision rate in both the 1 second and 2 second prediction time periods, fully demonstrating its excellent planning and obstacle avoidance capabilities.
Comparison with other methods: Compared with other advanced benchmark models, such as UniAD, BEV-Planner and Ego-MLP, OmniDrive outperforms on all key metrics. UniAD's L2 average error is 0.46 meters when using high-level commands and self-vehicle status information, while OmniDrive's error is even lower at 0.33 meters under the same settings. At the same time, OmniDrive's collision rate and road boundary intersection rate are also significantly lower than UniAD, especially the collision rate which is reduced by nearly half.
Compared with BEV-Planner, OmniDrive’s L2 error in all prediction time periods is significantly reduced, especially in the 3-second prediction time period, the error is reduced from 0.57 meters to 0.55 meters. At the same time, OmniDrive is also better than BEV-Planner in terms of collision rate and road boundary crossing rate. The collision rate dropped from 0.34% to 0.30%, and the road boundary crossing rate dropped from 3.16% to 3.00%.
Ablation experiment: In order to further evaluate the impact of key modules in the OmniDrive architecture on performance, the author also compared the performance of different versions of the OmniDrive model. OmniDrive (which does not use high-level commands and self-vehicle status information) is significantly inferior to the complete model in terms of prediction error, collision rate and road boundary intersection rate, especially the L2 error in the 3-second prediction period reaching 2.84 meters, with an average The collision rate is as high as 3.79%.
When only using the OmniDrive model (without high-level commands and self-vehicle status information), the prediction error, collision rate and road boundary intersection rate have improved, but there is still a gap compared with the complete model. This shows that integrating high-level commands and self-vehicle status information has a significant effect on improving the overall planning performance of the model.
Overall, the experimental results clearly demonstrate the excellent performance of OmniDrive on open-loop planning tasks. By integrating multi-modal information, high-level commands and self-vehicle status information, OmniDrive achieves more accurate path prediction and lower collision rate and road boundary intersection rate in complex planning tasks, providing information for autonomous driving planning and decision-making. strong support.
Discussion

The OmniDrive agent and OmniDrive-nuScenes dataset proposed by the author introduce a new method in the field of multi-modal large models. A new paradigm capable of solving driving problems in 3D environments and providing a comprehensive benchmark for the evaluation of such models. However, each new method and data set has its strengths and weaknesses.
The OmniDrive agent proposes a two-stage training strategy: 2D pre-training and 3D fine-tuning. In the 2D pre-training stage, better alignment between image features and large language models is achieved by pre-training Q-Former and carrier queries using the image-text paired dataset of LLaVA v1.5. In the 3D fine-tuning stage, 3D position information encoding and time modules are introduced to enhance the 3D positioning capabilities of the model. By leveraging LoRA to fine-tune the visual encoder and language model, OmniDrive maintains understanding of 2D semantics while enhancing its mastery of 3D localization. This staged training strategy fully unleashes the potential of the multi-modal large model, giving it stronger perception, reasoning and planning capabilities in 3D driving scenarios. On the other hand, OmniDrive-nuScenes serves as a new benchmark specifically designed for evaluating the ability to drive large models. Its fully automated QA generation process generates high-quality question-answer pairs via GPT-4, covering different tasks from perception to planning. In addition, the online generated positioning task also provides implicit data enhancement for the model, helping it better understand the 3D environment. The advantage of this dataset is that it not only tests the model's perception and reasoning capabilities, but also evaluates the model's spatial understanding and planning capabilities through long-term problems. This comprehensive benchmark provides strong support for the development of future multi-modal large models.
However, the OmniDrive agent and the OmniDrive-nuScenes dataset also have some shortcomings. First, since the OmniDrive agent needs to fine-tune the entire model in the 3D fine-tuning phase, the training resource requirements are high, which significantly increases training time and hardware costs. In addition, the data generation of OmniDrive-nuScenes completely relies on GPT-4. Although it ensures the quality and diversity of questions, it also causes the generated questions to be more inclined to models with strong natural language capabilities, which may make the model more dependent on benchmark testing. based on language characteristics rather than actual driving ability. Although OmniDrive-nuScenes provides a comprehensive QA benchmark, its coverage of driving scenarios is still limited. The traffic rules and planning simulations involved in the dataset are only based on the nuScenes dataset, which makes it difficult for the generated problems to fully represent various driving scenarios in the real world. Additionally, due to the highly automated nature of the data generation process, generated questions are inevitably affected by data bias and prompt design.
Conclusion
The OmniDrive agent and OmniDrive-nuScenes dataset proposed by the author bring new perspectives and evaluations to multi-modal large model research in 3D driving scenes. benchmark. The OmniDrive agent's two-stage training strategy successfully combines 2D pre-training and 3D fine-tuning, resulting in models that excel in perception, reasoning, and planning. OmniDrive-nuScenes, as a new QA benchmark, provides comprehensive indicators for evaluating large driving models. However, further research is still needed to optimize the training resource requirements of the model, improve the data set generation process, and ensure that the generated questions more accurately represent the real-life driving environment. Overall, the author's method and data set are of great significance in advancing multi-modal large model research in the field of driving, laying a solid foundation for future work.
The above is the detailed content of LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
