

我现有有一个工作,需要从新浪新闻网站中获取数据,包括,标题,正文,和参与人数。 如图所示想得到 820,但是动态产生的。该新闻的url为 陕西眉县发红头文件:官员卖水泥买房纳入考核
如图所示想得到 820,但是动态产生的。该新闻的url为 陕西眉县发红头文件:官员卖水泥买房纳入考核
这段代码产生的参与人数820,使用什么工具来获取?我想使用简单点的,可以完成上述工作的代码或 模块?谢谢大家


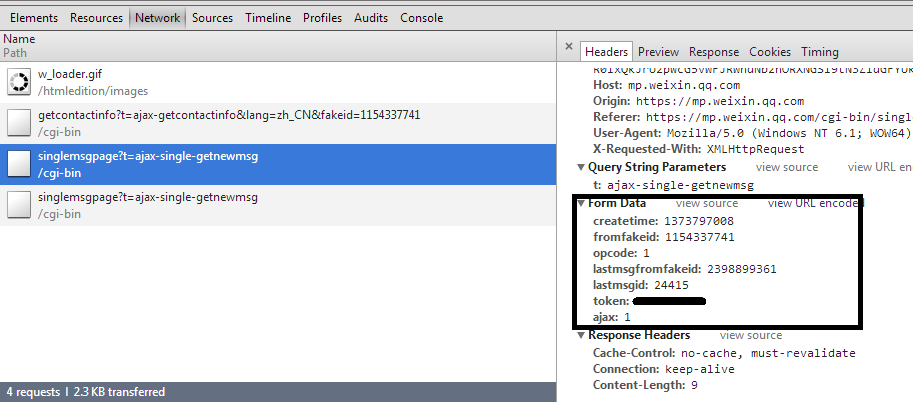 这是微信公众平台获取聊天信息的action,fromfakeid就是聊天对方的id。
这是微信公众平台获取聊天信息的action,fromfakeid就是聊天对方的id。<span class="kn">import</span> <span class="nn">selenium</span>
<span class="kn">from</span> <span class="nn">selenium</span> <span class="kn">import</span> <span class="n">webdriver</span>
<span class="kn">from</span> <span class="nn">selenium.common.exceptions</span> <span class="kn">import</span> <span class="n">NoSuchElementException</span>
<span class="kn">from</span> <span class="nn">selenium.webdriver.common.keys</span> <span class="kn">import</span> <span class="n">Keys</span>
<span class="kn">import</span> <span class="nn">time</span>
<span class="n">browser</span> <span class="o">=</span> <span class="n">webdriver</span><span class="o">.</span><span class="n">Firefox</span><span class="p">()</span> <span class="c"># Get local session of firefox</span>
<span class="n">browser</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="s">"http://news.sina.com.cn/c/2013-07-11/175827642839.shtml "</span><span class="p">)</span> <span class="c"># Load page</span>
<span class="n">time</span><span class="o">.</span><span class="n">sleep</span><span class="p">(</span><span class="mi">5</span><span class="p">)</span> <span class="c"># Let the page load</span>
<span class="k">try</span><span class="p">:</span>
<span class="n">element</span> <span class="o">=</span> <span class="n">browser</span><span class="o">.</span><span class="n">find_element_by_xpath</span><span class="p">(</span><span class="s">"//span[contains(@class,'f_red')]"</span><span class="p">)</span> <span class="c"># get element on page</span>
<span class="k">print</span> <span class="n">element</span><span class="o">.</span><span class="n">text</span> <span class="c"># get element text</span>
<span class="k">except</span> <span class="n">NoSuchElementException</span><span class="p">:</span>
<span class="k">assert</span> <span class="mi">0</span><span class="p">,</span> <span class="s">"can't find f_red"</span>
<span class="n">browser</span><span class="o">.</span><span class="n">close</span><span class="p">()</span>
<span class="x">>>> from selenium import webdriver</span>
<span class="x">>>> c = webdriver.Chrome()</span>
<span class="x">>>> c.get('http://news.sina.com.cn/c/2013-07-11/175827642839.shtml')</span>
<span class="x">>>> comment = c.find_element_by_id('media_comment')</span>
<span class="x">>>> count = comment.find_element_by_class_name('f_red')</span>
<span class="x">>>> count.text</span>
<span class="x">u'823'</span>
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



