

解决进程间共享内存,由于某个进程异常退出导致死锁问题

发现问题 继这篇Blog 解决Nginx和Fpm-Php等内部多进程之间共享数据问题 发完后,进程间共享内存又遇到了新的问题 昨天晚上QP同学上线后,早上看超时报表发现有一台前端机器访问QP超时,比其他前端机器高出了几个数量级,前端的机器都是同构的 难道是这台机器
发现问题
继这篇Blog 解决Nginx和Fpm-Php等内部多进程之间共享数据问题 发完后,进程间共享内存又遇到了新的问题
昨天晚上QP同学上线后,早上看超时报表发现有一台前端机器访问QP超时,比其他前端机器高出了几个数量级,前端的机器都是同构的
难道是这台机器系统不正常?查看系统状态也没有任何异常,统计了一下超时日志,发现超时都发生在早上QP服务重启的过程中,正常情况下服务重启时,ClusterMap 会保证流量的正常分配
难道是ClusterMap有问题?去ClusterMap Server端看了一下,一切正常
难道是订阅者客户端有问题吗?随便找了一台正常的机器和有问题的这台机器对比,查看下日志也没有发现问题,使用查询工具检查这两台机器订阅者代理写的共享内存,发现工具读取共享内存返回的结果不一致,这就更奇怪了,都是相同的订阅者,一台机器有问题一台没问题
难道Server端给他们的消息不一致?去Server端把订阅者的机器列表都打了出来,发现了有问题的机器根本不在订阅者列表里面,说明这台机器没有订阅,貌似有点线索了,我下线了一台它订阅的QP机器验证,发现共享内部数据没有更新,pstack一下这个进程,发现内部的更新线程一直在等锁,导致共享内存数据一直无法更新,gdb跟进去之后,_lock.data.nr_readers一直为1,说明一直有一个读进程占着锁导致写进程无法进入,遍历了所有fpm-php的读进程发现都没有占着锁,这说明在读进程在获得锁后没来得及释放就挂掉了
测试
现在问题已经确认就是获得读锁后进程异常退出导致的,我写个测试程序复现这个问题
(! 2293)-> cat test/read_shared.cpp
#include
SharedUpdateData* _sharedUpdateData = NULL;
cm_sub::CMMapFile* _mmapFile = NULL;
int32_t initSharedMemRead(const std::string& mmap_file_path)
{
_mmapFile = new (std::nothrow) cm_sub::CMMapFile();
if (_mmapFile == NULL || !_mmapFile->open(mmap_file_path.c_str(), FILE_OPEN_WRITE) )
{
return -1;
}
_sharedUpdateData = (SharedUpdateData*)_mmapFile->offset2Addr(0);
return 0;
}
int main(int argc, char** argv)
{
if (initSharedMemRead(argv[1]) != 0) return -1;
int cnt = 100;
while (cnt > 0)
{
pthread_rwlock_rdlock( &(_sharedUpdateData->_lock));
fprintf(stdout, "version = %ld, readers = %u\n",
_sharedUpdateData->_version, _sharedUpdateData->_lock.__data.__nr_readers);
if (cnt == 190)
{
exit(0);
}
sleep(1);
pthread_rwlock_unlock( &(_sharedUpdateData->_lock));
-- cnt;
usleep(100*1000);
}
delete _mmapFile;
}
(! 2293)-> cat test/write_shared.cpp
#include
SharedUpdateData* _sharedUpdateData = NULL;
cm_sub::CMMapFile* _mmapFile = NULL;
int32_t initSharedMemWrite(const char* mmap_file_path)
{
_mmapFile = new (std::nothrow) cm_sub::CMMapFile();
if ( _mmapFile == NULL || !_mmapFile->open(mmap_file_path, FILE_OPEN_WRITE, 1024) )
{
return -1;
}
_sharedUpdateData = (SharedUpdateData *)_mmapFile->offset2Addr(0);
madvise(_sharedUpdateData, 1024, MADV_SEQUENTIAL);
pthread_rwlockattr_t attr;
memset(&attr, 0x0, sizeof(pthread_rwlockattr_t));
if (pthread_rwlockattr_init(&attr) != 0 || pthread_rwlockattr_setpshared(&attr, PTHREAD_PROCESS_SHARED) != 0)
{
return -1;
}
pthread_rwlock_init( &(_sharedUpdateData->_lock), &attr);
_sharedUpdateData->_updateTime = autil::TimeUtility::currentTime();
_sharedUpdateData->_version = 0;
return 0;
}
int main()
{
if (initSharedMemWrite("data.mmap") != 0) return -1;
int cnt = 200;
while (cnt > 0)
{
pthread_rwlock_wrlock( &(_sharedUpdateData->_lock));
++ _sharedUpdateData->_version;
fprintf(stdout, "version = %ld, readers = %u\n",
_sharedUpdateData->_version, _sharedUpdateData->_lock.__data.__nr_readers);
sleep(1);
pthread_rwlock_unlock( &(_sharedUpdateData->_lock));
-- cnt;
usleep(100*1000);
}
delete _mmapFile;
}
无论是读进程还是写进程,获取锁后来不及释放就挂掉都会有这样的问题
如何解决
问题已经复现,想想如何用一个好的办法解决,在网上找了一遍,针对读写锁没有什么好的解决办法,只能在逻辑上自己解决,能想到的是使用超时机制,即写进程内部增加一个超时时间,如果写进程到了这个时间还是不能获得锁,就认为死锁,将读进程的计数减1,这是一个暴力的解决办法,不解释了,如果谁有好的解决办法指导我下
看下读写锁的代码,读写锁和互斥锁相比,更适合用在读多写少的场景,如果读进程需要锁住时间久,就更合适使用读写锁了,我的应该场景是,读多写少,读写时间都非常短;暂时认为互斥锁和读写锁性能差别应该不大,其实读写锁内部同样使用了互斥锁,只不过是锁的时间比较短,锁住互斥区,进去看下是否有人正在写,然后就释放了,
需要注意的是,读写锁默认是写优先的,也就是说当正在写,或者进入写队列准备写时,读锁都是加不上的,需要等待
好,那我们看看互斥锁能否解决我们的问题,互斥锁内部有一个属性叫Robust锁
设置锁为Robust锁: pthread_mutexattr_setrobust_np
The robustness attribute defines the behavior when the owner
of a mutex dies. The value of robustness could be either
PTHREAD_MUTEX_ROBUST_NP or PTHREAD_MUTEX_STALLED_NP, which
are defined by the header . The default value of
the robustness attribute is PTHREAD_MUTEX_STALLED_NP.
When the owner of a mutex with the PTHREAD_MUTEX_STALLED_NP
robustness attribute dies, all future calls to
pthread_mutex_lock(3C) for this mutex will be blocked from
progress in an unspecified manner.
修复非一致的Robust锁: pthread_mutex_consistent_np
A consistent mutex becomes inconsistent and is unlocked if
its owner dies while holding it, or if the process contain-
ing the owner of the mutex unmaps the memory containing the
mutex or performs one of the exec(2) functions. A subsequent
owner of the mutex will acquire the mutex with
pthread_mutex_lock(3C), which will return EOWNERDEAD to
indicate that the acquired mutex is inconsistent.
The pthread_mutex_consistent_np() function should be called
while holding the mutex acquired by a previous call to
pthread_mutex_lock() that returned EOWNERDEAD.
Since the critical section protected by the mutex could have
been left in an inconsistent state by the dead owner, the
caller should make the mutex consistent only if it is able
to make the critical section protected by the mutex con-
sistent.
简单来说就是当发现EOWNERDEAD时,pthread_mutex_consistent_np函数内部会判断这个互斥锁是不是Robust锁,如果是,并且他OwnerDie了,那么他会把锁的owner设置成自己的进程ID,这样这个锁又可以恢复可用,很简单吧
锁释放是可以解决了,但是通过共享内存在进程间共享数据时,还有一点是需要注意的,就是数据的正确性,即完整性,进程共享不同与线程,如果是一个进程中的多个线程,那么进程异常退出了,其他线程也同时退出了,进程间共享都是独立的,如果一个写线程在写共享数据的过程中,异常退出,导致写入的数据不完整,读进程读取时就会有读到不完整数据的问题,其实数据完整性非常好解决,只需要在共享内存中加一个完成标记就好了,锁住共享区后,写数据,写好之后标记为完成,就可以了,读进程在读取时判断一下完成标记
测试代码见:
(! 2295)-> cat test/read_shared_mutex.cpp
#include
SharedUpdateData* _sharedUpdateData = NULL;
cm_sub::CMMapFile* _mmapFile = NULL;
int32_t initSharedMemRead(const std::string& mmap_file_path)
{
_mmapFile = new (std::nothrow) cm_sub::CMMapFile();
if (_mmapFile == NULL || !_mmapFile->open(mmap_file_path.c_str(), FILE_OPEN_WRITE) )
{
return -1;
}
_sharedUpdateData = (SharedUpdateData*)_mmapFile->offset2Addr(0);
return 0;
}
int main(int argc, char** argv)
{
if (argc != 2) return -1;
if (initSharedMemRead(argv[1]) != 0) return -1;
int cnt = 10000;
int ret = 0;
while (cnt > 0)
{
ret = pthread_mutex_lock( &(_sharedUpdateData->_lock));
if (ret == EOWNERDEAD)
{
fprintf(stdout, "%s: version = %ld, lock = %d, %u, %d\n",
strerror(ret),
_sharedUpdateData->_version,
_sharedUpdateData->_lock.__data.__lock,
_sharedUpdateData->_lock.__data.__count,
_sharedUpdateData->_lock.__data.__owner);
ret = pthread_mutex_consistent_np( &(_sharedUpdateData->_lock));
if (ret != 0)
{
fprintf(stderr, "%s\n", strerror(ret));
pthread_mutex_unlock( &(_sharedUpdateData->_lock));
continue;
}
}
fprintf(stdout, "version = %ld, lock = %d, %u, %d\n",
_sharedUpdateData->_version,
_sharedUpdateData->_lock.__data.__lock,
_sharedUpdateData->_lock.__data.__count,
_sharedUpdateData->_lock.__data.__owner);
sleep(5);
pthread_mutex_unlock( &(_sharedUpdateData->_lock));
usleep(500*1000);
-- cnt;
}
fprintf(stdout, "go on\n");
delete _mmapFile;
}
(! 2295)-> cat test/write_shared_mutex.cpp
#include
SharedUpdateData* _sharedUpdateData = NULL;
cm_sub::CMMapFile* _mmapFile = NULL;
int32_t initSharedMemWrite(const char* mmap_file_path)
{
_mmapFile = new (std::nothrow) cm_sub::CMMapFile();
if ( _mmapFile == NULL || !_mmapFile->open(mmap_file_path, FILE_OPEN_WRITE, 1024) )
{
return -1;
}
_sharedUpdateData = (SharedUpdateData *)_mmapFile->offset2Addr(0);
madvise(_sharedUpdateData, 1024, MADV_SEQUENTIAL);
pthread_mutexattr_t attr;
memset(&attr, 0x0, sizeof(pthread_mutexattr_t));
if (pthread_mutexattr_init(&attr) != 0 || pthread_mutexattr_setpshared(&attr, PTHREAD_PROCESS_SHARED) != 0)
{
return -1;
}
if (pthread_mutexattr_setrobust_np(&attr, PTHREAD_MUTEX_ROBUST_NP) != 0)
{
return -1;
}
pthread_mutex_init( &(_sharedUpdateData->_lock), &attr);
_sharedUpdateData->_version = 0;
return 0;
}
int main()
{
if (initSharedMemWrite("data.mmap") != 0) return -1;
int cnt = 200;
int ret = 0;
while (cnt > 0)
{
ret = pthread_mutex_lock( &(_sharedUpdateData->_lock));
if (ret == EOWNERDEAD)
{
fprintf(stdout, "%s: version = %ld, lock = %d, %u, %d\n",
strerror(ret),
_sharedUpdateData->_version,
_sharedUpdateData->_lock.__data.__lock,
_sharedUpdateData->_lock.__data.__count,
_sharedUpdateData->_lock.__data.__owner);
ret = pthread_mutex_consistent_np( &(_sharedUpdateData->_lock));
if (ret != 0)
{
fprintf(stderr, "%s\n", strerror(ret));
pthread_mutex_unlock( &(_sharedUpdateData->_lock));
continue;
}
}
++ _sharedUpdateData->_version;
fprintf(stdout, "version = %ld, lock = %d, %u, %d\n", _sharedUpdateData->_version,
_sharedUpdateData->_lock.__data.__lock,
_sharedUpdateData->_lock.__data.__count,
_sharedUpdateData->_lock.__data.__owner);
usleep(1000*1000);
pthread_mutex_unlock( &(_sharedUpdateData->_lock));
-- cnt;
usleep(500*1000);
}
delete _mmapFile;
}
BTW:我们都知道加锁是有开销的,不仅仅是互斥导致的等待开销,还有加锁过程都是有系统调用到内核态的,这个过程开销也很大,有一种互斥锁叫Futex锁(Fast User Mutex),Linux从2.5.7版本开始支持Futex,快速的用户层面的互斥锁,Fetux锁有更好的性能,是用户态和内核态混合使用的同步机制,如果没有锁竞争的时候,在用户态就可以判断返回,不需要系统调用,
当然任何锁都是有开销的,能不用尽量不用,使用双Buffer,释放链表,引用计数,都可以在一定程度上替代锁的使用
原文地址:解决进程间共享内存,由于某个进程异常退出导致死锁问题, 感谢原作者分享。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 Large memory optimization, what should I do if the computer upgrades to 16g/32g memory speed and there is no change?
Jun 18, 2024 pm 06:51 PM
Large memory optimization, what should I do if the computer upgrades to 16g/32g memory speed and there is no change?
Jun 18, 2024 pm 06:51 PM
For mechanical hard drives or SATA solid-state drives, you will feel the increase in software running speed. If it is an NVME hard drive, you may not feel it. 1. Import the registry into the desktop and create a new text document, copy and paste the following content, save it as 1.reg, then right-click to merge and restart the computer. WindowsRegistryEditorVersion5.00[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\MemoryManagement]"DisablePagingExecutive"=d
 Samsung announced the completion of 16-layer hybrid bonding stacking process technology verification, which is expected to be widely used in HBM4 memory
Apr 07, 2024 pm 09:19 PM
Samsung announced the completion of 16-layer hybrid bonding stacking process technology verification, which is expected to be widely used in HBM4 memory
Apr 07, 2024 pm 09:19 PM
According to the report, Samsung Electronics executive Dae Woo Kim said that at the 2024 Korean Microelectronics and Packaging Society Annual Meeting, Samsung Electronics will complete the verification of the 16-layer hybrid bonding HBM memory technology. It is reported that this technology has passed technical verification. The report also stated that this technical verification will lay the foundation for the development of the memory market in the next few years. DaeWooKim said that Samsung Electronics has successfully manufactured a 16-layer stacked HBM3 memory based on hybrid bonding technology. The memory sample works normally. In the future, the 16-layer stacked hybrid bonding technology will be used for mass production of HBM4 memory. ▲Image source TheElec, same as below. Compared with the existing bonding process, hybrid bonding does not need to add bumps between DRAM memory layers, but directly connects the upper and lower layers copper to copper.
 Sources say Samsung Electronics and SK Hynix will commercialize stacked mobile memory after 2026
Sep 03, 2024 pm 02:15 PM
Sources say Samsung Electronics and SK Hynix will commercialize stacked mobile memory after 2026
Sep 03, 2024 pm 02:15 PM
According to news from this website on September 3, Korean media etnews reported yesterday (local time) that Samsung Electronics and SK Hynix’s “HBM-like” stacked structure mobile memory products will be commercialized after 2026. Sources said that the two Korean memory giants regard stacked mobile memory as an important source of future revenue and plan to expand "HBM-like memory" to smartphones, tablets and laptops to provide power for end-side AI. According to previous reports on this site, Samsung Electronics’ product is called LPWide I/O memory, and SK Hynix calls this technology VFO. The two companies have used roughly the same technical route, which is to combine fan-out packaging and vertical channels. Samsung Electronics’ LPWide I/O memory has a bit width of 512
 Lexar launches Ares Wings of War DDR5 7600 16GB x2 memory kit: Hynix A-die particles, 1,299 yuan
May 07, 2024 am 08:13 AM
Lexar launches Ares Wings of War DDR5 7600 16GB x2 memory kit: Hynix A-die particles, 1,299 yuan
May 07, 2024 am 08:13 AM
According to news from this website on May 6, Lexar launched the Ares Wings of War series DDR57600CL36 overclocking memory. The 16GBx2 set will be available for pre-sale at 0:00 on May 7 with a deposit of 50 yuan, and the price is 1,299 yuan. Lexar Wings of War memory uses Hynix A-die memory chips, supports Intel XMP3.0, and provides the following two overclocking presets: 7600MT/s: CL36-46-46-961.4V8000MT/s: CL38-48-49 -1001.45V In terms of heat dissipation, this memory set is equipped with a 1.8mm thick all-aluminum heat dissipation vest and is equipped with PMIC's exclusive thermal conductive silicone grease pad. The memory uses 8 high-brightness LED beads and supports 13 RGB lighting modes.
 MIT's latest masterpiece: using GPT-3.5 to solve the problem of time series anomaly detection
Jun 08, 2024 pm 06:09 PM
MIT's latest masterpiece: using GPT-3.5 to solve the problem of time series anomaly detection
Jun 08, 2024 pm 06:09 PM
Today I would like to introduce to you an article published by MIT last week, using GPT-3.5-turbo to solve the problem of time series anomaly detection, and initially verifying the effectiveness of LLM in time series anomaly detection. There is no finetune in the whole process, and GPT-3.5-turbo is used directly for anomaly detection. The core of this article is how to convert time series into input that can be recognized by GPT-3.5-turbo, and how to design prompts or pipelines to let LLM solve the anomaly detection task. Let me introduce this work to you in detail. Image paper title: Largelanguagemodelscanbezero-shotanomalydete
 Kingbang launches new DDR5 8600 memory, offering CAMM2, LPCAMM2 and regular models to choose from
Jun 08, 2024 pm 01:35 PM
Kingbang launches new DDR5 8600 memory, offering CAMM2, LPCAMM2 and regular models to choose from
Jun 08, 2024 pm 01:35 PM
According to news from this site on June 7, GEIL launched its latest DDR5 solution at the 2024 Taipei International Computer Show, and provided SO-DIMM, CUDIMM, CSODIMM, CAMM2 and LPCAMM2 versions to choose from. ▲Picture source: Wccftech As shown in the picture, the CAMM2/LPCAMM2 memory exhibited by Jinbang adopts a very compact design, can provide a maximum capacity of 128GB, and a speed of up to 8533MT/s. Some of these products can even be stable on the AMDAM5 platform Overclocked to 9000MT/s without any auxiliary cooling. According to reports, Jinbang’s 2024 Polaris RGBDDR5 series memory can provide up to 8400
 The impact of the AI wave is obvious. TrendForce has revised up its forecast for DRAM memory and NAND flash memory contract price increases this quarter.
May 07, 2024 pm 09:58 PM
The impact of the AI wave is obvious. TrendForce has revised up its forecast for DRAM memory and NAND flash memory contract price increases this quarter.
May 07, 2024 pm 09:58 PM
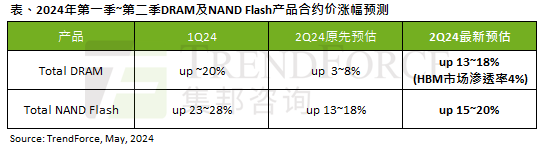
According to a TrendForce survey report, the AI wave has a significant impact on the DRAM memory and NAND flash memory markets. In this site’s news on May 7, TrendForce said in its latest research report today that the agency has increased the contract price increases for two types of storage products this quarter. Specifically, TrendForce originally estimated that the DRAM memory contract price in the second quarter of 2024 will increase by 3~8%, and now estimates it at 13~18%; in terms of NAND flash memory, the original estimate will increase by 13~18%, and the new estimate is 15%. ~20%, only eMMC/UFS has a lower increase of 10%. ▲Image source TrendForce TrendForce stated that the agency originally expected to continue to
 Lexar God of War Wings ARES RGB DDR5 8000 Memory Picture Gallery: Colorful White Wings supports RGB
Jun 25, 2024 pm 01:51 PM
Lexar God of War Wings ARES RGB DDR5 8000 Memory Picture Gallery: Colorful White Wings supports RGB
Jun 25, 2024 pm 01:51 PM
When the prices of ultra-high-frequency flagship memories such as 7600MT/s and 8000MT/s are generally high, Lexar has taken action. They have launched a new memory series called Ares Wings ARES RGB DDR5, with 7600 C36 and 8000 C38 is available in two specifications. The 16GB*2 sets are priced at 1,299 yuan and 1,499 yuan respectively, which is very cost-effective. This site has obtained the 8000 C38 version of Wings of War, and will bring you its unboxing pictures. The packaging of Lexar Wings ARES RGB DDR5 memory is well designed, using eye-catching black and red color schemes with colorful printing. There is an exclusive &quo in the upper left corner of the packaging.
