

Avant-propos
Ces dernières années, l'adaptation multi-terminal Web de divers sites bat son plein, et l'industrie a également développé des solutions qui s'appuient sur diverses technologies. Par exemple, du responsive design basé sur le CSS3 Media Query natif du navigateur, des solutions « d'adaptation cloud » basées sur le reflow intelligent du cloud, etc. Cet article traite principalement des solutions d'adaptation multi-terminaux basées sur la séparation front-end et back-end.
À propos de la séparation front-end et back-end
Concernant la solution de séparation front-end et back-end, il y a une explication très claire dans "Pensée et pratique de la séparation front-end et front-end basée sur NodeJS (1)". Nous introduisons NodeJS comme couche de rendu entre l'interface du serveur et le navigateur. Étant donné que la couche NodeJS est complètement séparée des données et n'a pas besoin de se soucier de beaucoup de logique métier, elle est très adaptée au travail d'adaptation multi-terminal dans ce domaine. couche.
Détection UA
La première chose à résoudre pour l'adaptation multi-terminal est le problème de détection UA Pour une requête entrante, nous devons connaître le type de l'appareil afin de générer le contenu correspondant. Il existe déjà sur le marché des bibliothèques de signatures et des outils de détection de User Agent très matures et compatibles avec un grand nombre d'appareils. Voici une liste compilée par Mozilla. Parmi eux, certains s'exécutent côté navigateur et d'autres s'exécutent sur la couche de code côté serveur. Certains outils fournissent même des modules Nginx/Apache, qui sont chargés d'analyser les informations UA de chaque requête.
Nous recommandons en fait la dernière méthode. La solution basée sur la séparation du front-end et du back-end détermine que la détection UA ne peut s'exécuter que côté serveur, mais coupler le code de détection et la bibliothèque de fonctionnalités dans le code métier n'est pas une solution assez conviviale. Nous déplaçons ce comportement plus loin et l'accrochons à Nginx/Apache. Ils sont chargés d'analyser les informations UA de chaque requête, puis de les transmettre au code métier via des méthodes telles que l'en-tête HTTP.
Il y a plusieurs avantages à faire cela :
Dans notre code, nous n'avons plus besoin de prêter attention à la façon dont UA est analysé, nous pouvons directement récupérer les informations analysées depuis la couche supérieure. S'il existe plusieurs applications sur le même serveur, elles peuvent utiliser conjointement les mêmes informations UA analysées par Nginx, évitant ainsi la perte d'analyse entre différentes applications.
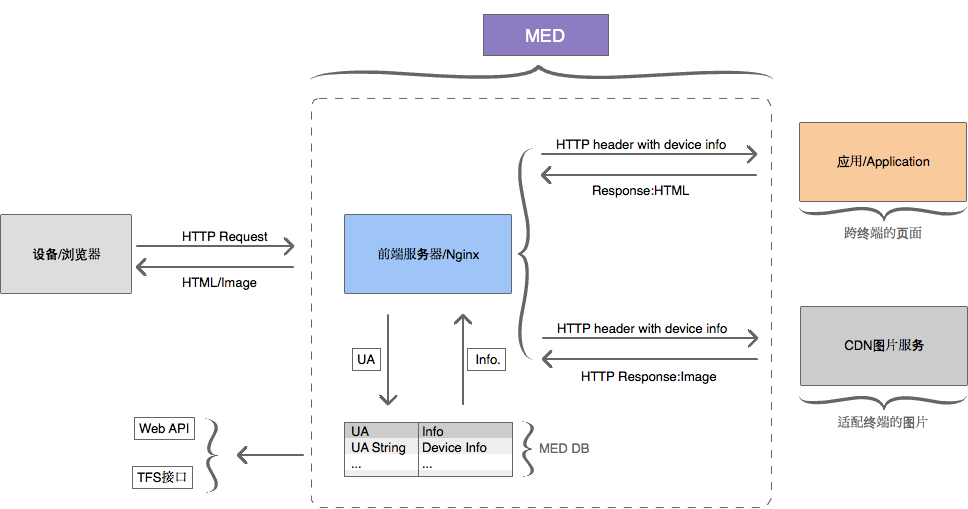
Solution de détection UA basée sur Nginx partagée par Tmall
Le serveur Web Tengine de Taobao fournit également un module similaire ngx_http_user_agent_module.
Il convient de mentionner que lors du choix d'un outil de détection UA, vous devez tenir compte de la maintenabilité de la base de données de signatures, car il existe de plus en plus de nouveaux types d'appareils sur le marché, et chaque appareil aura un agent utilisateur indépendant, donc ceci fonctionnalité Les bibliothèques doivent fournir de bonnes stratégies de mise à jour et de maintenance pour s'adapter à l'évolution des appareils.
Plusieurs solutions d'adaptation construites dans le modèle MVC
Après avoir obtenu les informations UA, nous devons réfléchir à la manière d'effectuer l'adaptation du terminal en fonction de l'UA spécifié. Même dans la couche NodeJS, bien que la majeure partie de la logique métier ait disparu, nous divisons toujours l'intérieur en trois modèles : Modèle / Contrôleur / Vue.
Utilisons d'abord la figure ci-dessus pour analyser certaines solutions d'adaptation multi-terminaux existantes.
Solution d'adaptation construite sur Controller
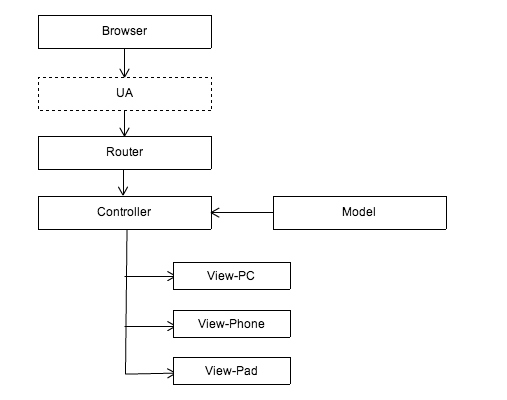
Cette solution devrait être la manière la plus simple et la plus grossière de résoudre ce problème. Transmettez la même URL à la même couche de contrôle (Contrôleur) via le routage (Routeur). La couche de contrôle utilise ensuite les informations UA pour envoyer les données et la logique du modèle à l'affichage correspondant (View) pour le rendu. La couche de rendu fournit des modèles adaptés à plusieurs terminaux selon l'accord préalable.
L'avantage de cette solution est qu'elle maintient l'unité des couches de données et de contrôle, et la logique métier ne doit être traitée qu'une seule fois et peut être appliquée à tous les terminaux. Cependant, ce scénario ne convient qu'aux applications à faible interaction telles que les pages d'affichage. Une fois le métier plus complexe, le contrôleur de chaque terminal peut avoir sa propre logique de traitement. Si un contrôleur est toujours partagé, le contrôleur sera très gonflé et. difficile à maintenir. Sans doute un mauvais choix.
Solution d'adaptation construite sur Routeur
Afin de résoudre les problèmes ci-dessus, nous pouvons distinguer les appareils sur le routeur et les distribuer à différents contrôleurs pour différents terminaux :
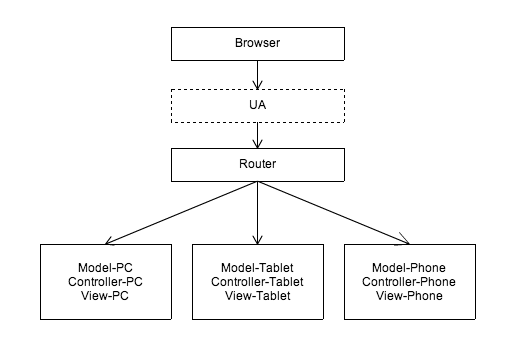
C'est également l'une des solutions les plus courantes, qui se manifeste principalement par l'utilisation d'ensembles d'applications distincts pour différents terminaux. Tels que la page d'accueil PC Taobao et la version WAP de la page d'accueil Taobao Lorsque différents appareils accèdent à www.taobao.com, le serveur sera redirigé vers la version WAP de la page d'accueil Taobao ou la version PC de la page d'accueil Taobao via le contrôle du routeur. Ce sont deux ensembles d’applications complètement indépendants.
Cependant, cette solution pose sans aucun doute le problème que les données et une partie de la logique ne peuvent pas être partagées. Différents terminaux ne peuvent pas partager les mêmes données et la même logique métier, ce qui entraîne beaucoup de travail répétitif et une faible efficacité.
Afin de pallier ce problème, quelqu'un a proposé une solution optimisée : toujours dans le même ensemble d'applications, chaque source de données est extraite dans chaque Modèle, qui est fourni aux contrôleurs des différents terminaux pour une utilisation combinée :
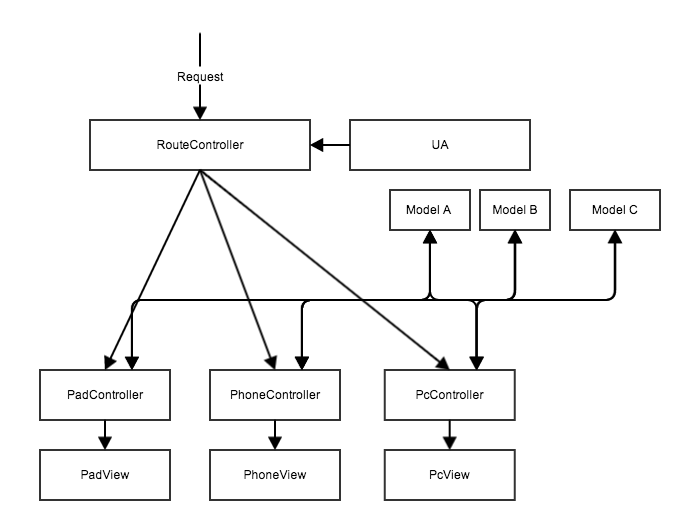
Cette solution résout le problème précédent de l'impossibilité de partager les données. Chaque terminal du contrôleur reste indépendant les uns des autres, mais ils peuvent utiliser conjointement le même lot de sources de données. Au moins en termes de données, il n'est pas nécessaire de développer des interfaces indépendantes pour les types de terminaux.
Pour les deux solutions basées sur un routeur ci-dessus, en raison de l'indépendance du contrôleur, chaque terminal peut implémenter une logique d'interaction différente pour sa propre page, garantissant une flexibilité suffisante de chaque terminal lui-même. C'est pourquoi la plupart des applications adoptent cette solution principale. raison.
Schéma d'adaptation construit sur la couche Vue
C'est la solution utilisée par la page de commande de Taobao, mais la différence est que la page de commande place toute la couche de rendu côté navigateur au lieu de la couche NodeJS. Cependant, qu'il s'agisse d'un navigateur ou de NodeJS, l'idée globale de conception est toujours la même :
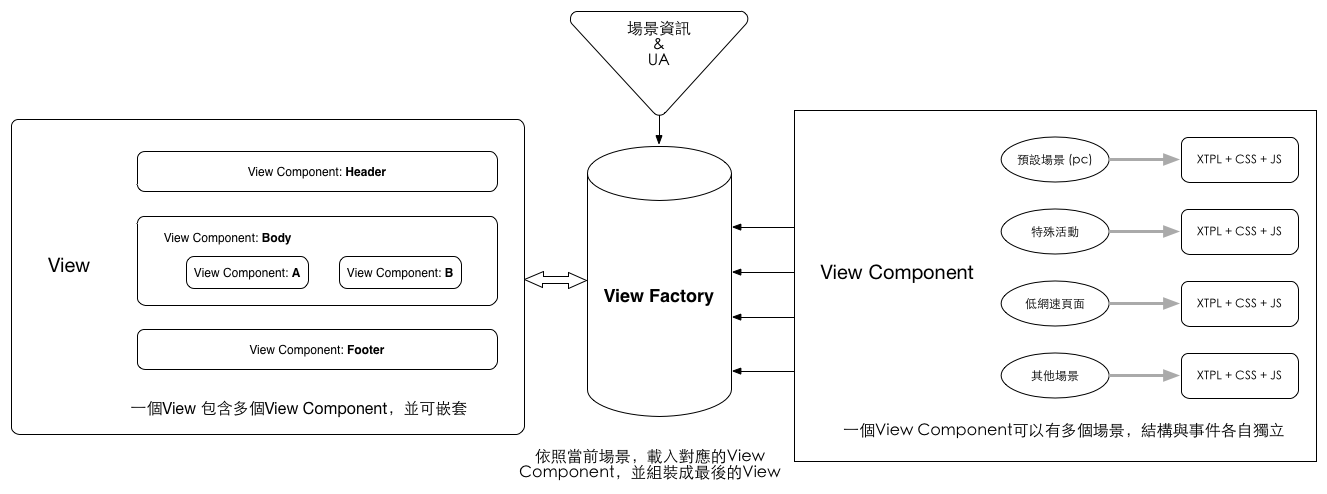
Dans cette solution, le routeur, le contrôleur et le modèle n'ont pas besoin de prêter attention aux informations sur le périphérique, et le jugement du type de terminal est entièrement laissé à la couche de présentation. Le module principal de la figure est "View Factory". Une fois que le modèle et le contrôleur ont transmis les données et la logique de rendu, View Factory utilise les informations sur le périphérique et d'autres états (non seulement les informations UA, mais également l'environnement réseau, la zone utilisateur, etc. .) Récupérez des composants spécifiques parmi un ensemble de composants prédéfinis (Afficher les composants) et combinez-les dans la page finale.
Cette solution présente plusieurs avantages :
La couche supérieure n'a pas besoin de prêter attention aux informations sur l'appareil (UA). Les vidéos multi-terminaux sont toujours gérées par la couche View, qui a la plus grande relation avec l'affichage final, en plus ; Aux informations UA, chaque composant d'affichage peut également être basé sur le statut de l'utilisateur. Décidez vous-même quel modèle afficher, par exemple en masquant les images par défaut à faible vitesse du réseau et en affichant des bannières d'événements dans des zones désignées. Différents modèles de chaque composant View peuvent décider d'utiliser ou non les mêmes données et la même logique métier, offrant ainsi une méthode de mise en œuvre très flexible.
Mais évidemment, cette solution est aussi la plus complexe, surtout si l'on considère certains scénarios d'application d'interaction riche, le routeur et le contrôleur ne pourront peut-être pas rester aussi purs. En particulier pour certaines entreprises relativement intégrées qui ne peuvent pas être divisées en composants, cette solution peut ne pas être applicable et pour certaines entreprises simples, l'utilisation de cette architecture n'est peut-être pas le meilleur choix ;
Résumé
Les solutions ci-dessus se reflètent chacune dans une ou plusieurs parties du modèle MVC. En termes d'entreprise, si une solution ne répond pas aux besoins, plusieurs solutions peuvent être adoptées en même temps. Ou bien, on peut comprendre que la complexité métier et les attributs d'interaction déterminent quelle solution d'adaptation multiterminale est la plus adaptée au produit.
Par rapport aux solutions de conception réactive basées sur un navigateur, étant donné que la majeure partie de la logique de détection et de rendu du terminal a été migrée vers le serveur, l'adaptation au niveau de la couche NodeJS apportera sans aucun doute de meilleures performances et une meilleure expérience utilisateur par rapport à la qualité de conversion ; les problèmes causés par certaines solutions dites « d'adaptation au cloud » n'existeront pas dans les solutions « personnalisées » basées sur la séparation front-end et back-end. La solution d'adaptation de séparation front-end et back-end présente des avantages naturels dans ces aspects.
Enfin, afin de s'adapter à des exigences d'adaptation plus flexibles et plus puissantes, les solutions d'adaptation basées sur la séparation front-end et back-end seront confrontées à plus de défis !
 qu'est-ce que nodejs
qu'est-ce que nodejs
 Nodejs implémente le robot d'exploration
Nodejs implémente le robot d'exploration
 Comment ouvrir le disque virtuel
Comment ouvrir le disque virtuel
 Quelles sont les différences entre le cellpadding et l'espacement des cellules ?
Quelles sont les différences entre le cellpadding et l'espacement des cellules ?
 Quel logiciel est Dreamweaver ?
Quel logiciel est Dreamweaver ?
 Les mots disparaissent après avoir tapé
Les mots disparaissent après avoir tapé
 Que faire s'il n'y a pas de curseur lorsque vous cliquez sur la zone de saisie
Que faire s'il n'y a pas de curseur lorsque vous cliquez sur la zone de saisie
 commandes communes iscsiadm
commandes communes iscsiadm








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



