

mongodb入门-8查询3

mongodb入门-8查询3 继续学下mongodb的查询 $or $nor $or或者的意思 只要有一个符合就查出了. $nor与$or相反,只要是$or能够查出来的$nor作为去除的部分. [html] db.user.find() { _id : ObjectId(5198c286c686eb50e2c843b2), name : user0, age : 0 } { _id
mongodb入门-8查询3
继续学下mongodb的查询
$or $nor
$or或者的意思 只要有一个符合就查出了. $nor与$or相反,只要是$or能够查出来的$nor作为去除的部分.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
> db.user.find({$or:[{name:"user1"},{age:20}]}) -->这里可以看到$or和其它的$开头方法不同,其它一般都是作为一个键的值,这个是之间作为键的,可能这里解释的不是很清楚,大家理解了就好
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
同样$nor就是查询出其它的部分:
[html]
> db.user.find({$nor:[{name:"user1"},{age:20}]})
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
$size 查询数组的长度等于给定数组长度的文档
[html]
> db.phone.find()
{ "_id" : ObjectId("5198e20220c9b0dc40419385"), "num" : [ 1, 2, 3 ] }
{ "_id" : ObjectId("5198e21820c9b0dc40419386"), "num" : [ 4, 2, 3 ] }
{ "_id" : ObjectId("5198e22120c9b0dc40419387"), "num" : [ 1, 2, 5 ] }
{ "_id" : ObjectId("5198e51a20c9b0dc40419388"), "state" : 1 }
{ "_id" : ObjectId("519969952b76790566165de2"), "num" : [ 2, 3 ] }
> db.phone.find({num:{$size:4}}) -->num数组长度为4的结果没有
> db.phone.find({num:{$size:3}}) -->长度为3的有三个
{ "_id" : ObjectId("5198e20220c9b0dc40419385"), "num" : [ 1, 2, 3 ] }
{ "_id" : ObjectId("5198e21820c9b0dc40419386"), "num" : [ 4, 2, 3 ] }
{ "_id" : ObjectId("5198e22120c9b0dc40419387"), "num" : [ 1, 2, 5 ] }
$where 自定义的查询
$where的值是一个function,我们可以自己写这个function然后去判断哪些值是我们需要的.它会循环扫描集合中的文档,然后执行函数中的判断,只要我们返回true,此文档就会被查出.但是有一点这个方法的性能不是很好,比如下面的查询我能明显感到一些停顿(与上面讲过的方法比较),有兴趣的考研自己试一下.建议只有在其他$方法不能满足查询的时候,在使用$where查询.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
> db.user.find({$where:function(){return this.age == 3 || this.age == 4}})
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
$type 根据数据类型查询
在mongodb中每一种数据类型都有对应的数字,我们在使用$type的时候需要使用这些数字,文档中给出如下的表示
类型 编号
双精度 1
字符串 2
对象 3
数组 4
二进制数据 5
对象 ID 7
布尔值 8
日期 9
空 10
正则表达式 11
JavaScript 13
符号 14
JavaScript(带范围) 15
32 位整数 16
时间戳 17
64 位整数 18
最小键 255
最大键 127 一段例子代码:
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
{ "_id" : ObjectId("51996ef22b76790566165e47"), "name" : 23, "age" : 33 }
> db.user.find({name:{$type:1}}) -->查找name为双精度的文档
{ "_id" : ObjectId("51996ef22b76790566165e47"), "name" : 23, "age" : 33 }
在命令行中type的一些值是不起作用的,这可能与命令行环境有关系,如果谁清楚这个,还请给我留言.
正则表达式
mongodb中查询也支持正则,跟javascript中的正则基本一样,但是不建议使用,因为性能不算是很好.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
{ "_id" : ObjectId("51996ef22b76790566165e47"), "name" : 23, "age" : 33 }
> db.user.find({name:/user*/i}) -->查询name以user开头不区分大小写的文档
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
排序
在mongodb中排序很简单,使用sort方法,传递给它你想按照哪个字段的哪种方式排序即可.这里1代表升序,-1代表降序.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
> db.user.find().sort({age:1})
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
> db.user.find().sort({age:-1})
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
group 分组查询
mongodb中的group可以实现类似关系型数据库中的分组的功能,但是mongodb中的group远比关系型数据库中的group强大,可以实现map-reduce功能,至于map-reduce读者自己百度吧,现在比较火.
group中的json参数类似这样{key:{字段:1},initial:{变量:初始值},$reduce:function(doc,prev){函数代码}}.
其中的字段代表,需要按哪个字段分组.变量表示这一个分组中会使用的变量,并且给一个初始值.可以在后面的$reduce函数中使用.$reduce的两个参数,分别代表当前的文档和上个文档执行完函数后的结果.如下我们按年龄分组,同级不同年龄的用户的多少:
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 2 }
> db.user.group({key:{age:1},initial:{count:0},$reduce:function(doc,prev){prev.count++}})
[
{
"age" : 0,
"count" : 1
},
{
"age" : 1,
"count" : 3
},
{
"age" : 2,
"count" : 2
}
]
group更加详细的介绍请看http://www.2cto.com/database/201305/212159.html这篇文章
distinct
去除查询结果中的重复数据,对原有数据不会产生影响,返回的结果是一个数组.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 2 }
> db.user.distinct("age")
[ 0, 1, 2 ]
分页查询
在mongodb中实现分页比较简单,需要使用到skip 和limit方法.skip表示跳过前面的几个文档,limit表示显示几个文档.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 2 }
> db.user.find().skip(2).limit(3) -->跳过前两个文档查询后面的三个文档,经过测试这两个方法的使用顺序没有影响
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }
> db.user.find().limit(3).skip(2)
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Kimi : En une seule phrase, un PPT est prêt en seulement dix secondes. PPT est tellement ennuyeux ! Pour tenir une réunion, vous devez avoir un PPT ; pour rédiger un rapport hebdomadaire, vous devez avoir un PPT ; pour solliciter des investissements, vous devez présenter un PPT ; même pour accuser quelqu'un de tricherie, vous devez envoyer un PPT ; L'université ressemble plus à une spécialisation PPT. Vous regardez le PPT en classe et faites le PPT après les cours. Peut-être que lorsque Dennis Austin a inventé le PPT il y a 37 ans, il ne s'attendait pas à ce qu'un jour le PPT devienne aussi répandu. Parler de notre dure expérience de création de PPT nous fait monter les larmes aux yeux. "Il m'a fallu trois mois pour réaliser un PPT de plus de 20 pages, et je l'ai révisé des dizaines de fois. J'avais envie de vomir quand j'ai vu le PPT." "À mon apogée, je faisais cinq PPT par jour, et même ma respiration." était PPT." Si vous avez une réunion impromptue, vous devriez le faire
 Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Nous savons que le LLM est formé sur des clusters informatiques à grande échelle utilisant des données massives. Ce site a présenté de nombreuses méthodes et technologies utilisées pour aider et améliorer le processus de formation LLM. Aujourd'hui, ce que nous souhaitons partager est un article qui approfondit la technologie sous-jacente et présente comment transformer un ensemble de « bare metals » sans même un système d'exploitation en un cluster informatique pour la formation LLM. Cet article provient d'Imbue, une startup d'IA qui s'efforce d'atteindre une intelligence générale en comprenant comment les machines pensent. Bien sûr, transformer un tas de « bare metal » sans système d'exploitation en un cluster informatique pour la formation LLM n'est pas un processus facile, plein d'exploration et d'essais et d'erreurs, mais Imbue a finalement réussi à former un LLM avec 70 milliards de paramètres et dans. le processus s'accumule
 L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
Rédacteur du Machine Power Report : Yang Wen La vague d’intelligence artificielle représentée par les grands modèles et l’AIGC a discrètement changé notre façon de vivre et de travailler, mais la plupart des gens ne savent toujours pas comment l’utiliser. C'est pourquoi nous avons lancé la rubrique « AI in Use » pour présenter en détail comment utiliser l'IA à travers des cas d'utilisation de l'intelligence artificielle intuitifs, intéressants et concis et stimuler la réflexion de chacun. Nous invitons également les lecteurs à soumettre des cas d'utilisation innovants et pratiques. Lien vidéo : https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Récemment, le vlog de la vie d'une fille vivant seule est devenu populaire sur Xiaohongshu. Une animation de style illustration, associée à quelques mots de guérison, peut être facilement récupérée en quelques jours seulement.
 Un autre joueur de niveau Sora arrive dans la rue ! Nous l'avons comparé à Sora et Keling.
Aug 02, 2024 am 10:19 AM
Un autre joueur de niveau Sora arrive dans la rue ! Nous l'avons comparé à Sora et Keling.
Aug 02, 2024 am 10:19 AM
Lorsque Sora n'est pas parvenu à se manifester, les adversaires d'OpenAI ont utilisé leurs armes pour détruire les rues. Si Sora n'est pas ouvert à l'utilisation, il sera vraiment volé ! Aujourd'hui, la startup de San Francisco, LumaAI, a joué un atout et a lancé une nouvelle génération de modèle de génération vidéo IA DreamMachine. Gratuit et accessible à tous. Selon les rapports, le modèle peut générer des vidéos réalistes de haute qualité basées sur de simples descriptions textuelles, avec des effets comparables à ceux de Sora. Dès l’annonce de la nouvelle, un grand nombre d’utilisateurs se sont rassemblés sur le site officiel pour l’essayer. Bien que les responsables affirment que le modèle peut générer une vidéo de 120 images en seulement deux minutes, de nombreux utilisateurs attendent depuis des heures sur le site officiel en raison d'une augmentation des visites. BarkleyDai, responsable de la croissance des produits chez Luma, a dû commenter Discord
 Kuaishou Keling AI est entièrement ouvert aux tests internes à l'échelle mondiale et l'effet du modèle a de nouveau été mis à niveau.
Jul 24, 2024 pm 08:34 PM
Kuaishou Keling AI est entièrement ouvert aux tests internes à l'échelle mondiale et l'effet du modèle a de nouveau été mis à niveau.
Jul 24, 2024 pm 08:34 PM
Le 24 juillet, Keling AI, grand modèle de génération vidéo Kuaishou, a annoncé que le modèle de base avait de nouveau été mis à niveau et était entièrement ouvert aux tests internes. Kuaishou a déclaré que afin de permettre à davantage d'utilisateurs d'utiliser Keling AI et de mieux répondre aux différents niveaux d'utilisation des créateurs, il lancera désormais également officiellement un système d'adhésion pour différentes catégories de créateurs, sur la base de tests internes entièrement ouverts. membres. Fournir des services fonctionnels exclusifs correspondants. Dans le même temps, le modèle de base de Keling AI a également été à nouveau mis à niveau pour améliorer encore l'expérience utilisateur. L'effet de modèle de base a été mis à niveau pour améliorer encore l'expérience utilisateur. Depuis sa sortie il y a plus d'un mois, Keling AI a été mis à niveau et itéré à plusieurs reprises. Avec le lancement de ce système d'adhésion, l'effet de modèle de base de Keling AI a été amélioré. à nouveau subi une transformation. La première est que la qualité de l'image a été considérablement améliorée et les effets visuels générés grâce au modèle de base amélioré.
 Pourquoi ne le savais-je pas lorsque j'apprenais la génération de lignes : il existe une relation d'équivalence entre les matrices et les graphiques ?
Aug 19, 2024 pm 04:52 PM
Pourquoi ne le savais-je pas lorsque j'apprenais la génération de lignes : il existe une relation d'équivalence entre les matrices et les graphiques ?
Aug 19, 2024 pm 04:52 PM
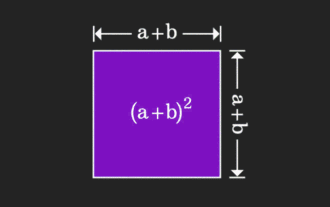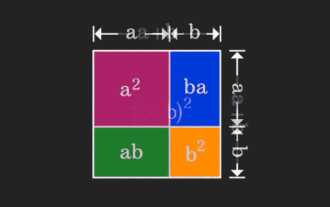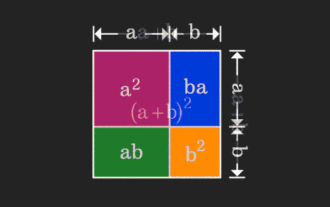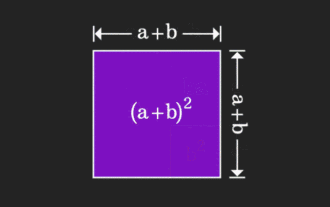
La matrice est difficile à comprendre, mais elle peut être différente si vous la regardez sous un autre angle. Lorsque nous apprenons les mathématiques, nous sommes souvent frustrés par la difficulté et le caractère abstrait des connaissances que nous apprenons, mais parfois, en changeant simplement de perspective, nous pouvons trouver une solution simple et intuitive au problème. Par exemple, lorsque nous apprenions la formule de la somme des carrés (a+b)² quand nous étions enfants, nous ne comprenions peut-être pas pourquoi elle est égale à a²+2ab+b². Nous savions seulement qu'elle était écrite ainsi en. le livre et le professeur nous ont demandé de nous en souvenir ainsi ; jusqu'au jour où nous avons vu cette image animée : Il m'est soudain apparu que nous pouvions la comprendre d'un point de vue géométrique ! Maintenant, ce sentiment d’illumination se reproduit : une matrice non négative peut être convertie de manière équivalente en le graphe orienté correspondant ! Comme le montre la figure ci-dessous, la matrice 3×3 de gauche peut en réalité être
 700 000 personnes se sont précipitées pour en faire l'expérience ! Le nouveau roi de la génération vidéo 'Keling AI' a de nouveau été mis à niveau
Jul 20, 2024 am 05:09 AM
700 000 personnes se sont précipitées pour en faire l'expérience ! Le nouveau roi de la génération vidéo 'Keling AI' a de nouveau été mis à niveau
Jul 20, 2024 am 05:09 AM
Est-il possible que l’ère des courts métrages dramatiques générés par l’IA arrive vraiment ? Récemment, les démos publiées par diverses IA de génération vidéo sont éblouissantes. Qu'il s'agisse de jouer avec des mèmes et des énigmes de longueur ou de prêter attention à la véritable logique physique, il est difficile de faire la distinction entre la créativité sans fin de l'intelligence artificielle, et tous doivent rivaliser avec Sora. À ce moment-là, quelqu'un a soudainement pris une longueur d'avance et a créé une performance « de niveau film » : des effets de lumière et d'ombre de style réel : Source : https://x.com/i/status/1806383419661730197 à une imagination riche, tous les éléments sont terminés, cela peut être fait : de manière inattendue, aux yeux de l'IA, c'est en fait Batman qui peut empêcher le Joker de garder son sang-froid. Source : https://x.com/blizaine/status/18
 Doubao Big Model Team publie un nouveau benchmark d'évaluation des légendes d'images détaillées pour améliorer la fiabilité de l'évaluation des légendes VLM
Jul 18, 2024 pm 08:10 PM
Doubao Big Model Team publie un nouveau benchmark d'évaluation des légendes d'images détaillées pour améliorer la fiabilité de l'évaluation des légendes VLM
Jul 18, 2024 pm 08:10 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Le modèle de langage visuel (VLM) actuel effectue principalement une évaluation des performances via un format de questions et réponses d'assurance qualité, mais manque d'évaluation de la compréhension de base du modèle, telle que des méthodes d'évaluation fiables pour performances de la légende de l'image détaillée. En réponse à ce problème, l'Académie chinoise des sciences,
