
 interface Web
tutoriel HTML
Le problème chinois tronqué des fichiers HTML et le problème d'affichage dans la production des pages browser_HTML/Xhtml_Web
interface Web
tutoriel HTML
Le problème chinois tronqué des fichiers HTML et le problème d'affichage dans la production des pages browser_HTML/Xhtml_Web
Le problème chinois tronqué des fichiers HTML et le problème d'affichage dans la production des pages browser_HTML/Xhtml_Web

Ma page d'aujourd'hui contenait également des caractères tronqués, j'ai donc recherché des problèmes connexes sur Internet. Il semble que cette méthode soit plutôt bonne, je l'ai également essayée, j'ai utilisé l'éditeur editp et je suis allé dans Document - Encodage de fichier - Modifier le. encodage de fichier : choisissez simplement l'encodage dont vous avez besoin
Dans les pages Web, le problème des caractères chinois tronqués se produit souvent. Lorsque j'ai rencontré des problèmes de code tronqué dans le passé, j'ai simplement continué à essayer différentes méthodes d'encodage jusqu'à ce que je réussisse. Hier, le projet a de nouveau rencontré ce problème, j'ai donc fait un test simple.
Les fichiers HTML ont des méthodes d'encodage, telles que "UTF-8", "GBK", etc. Ceux-ci peuvent ne pas être visibles dans le Bloc-notes, mais dans Eclipse, vous pouvez définir la méthode d'encodage des fichiers HTML, comme expliqué dans les images suivantes.
Test 1 :
Enregistrez le fichier html en mode "UTF-8". Le contenu spécifique du fichier est affiché ci-dessous :
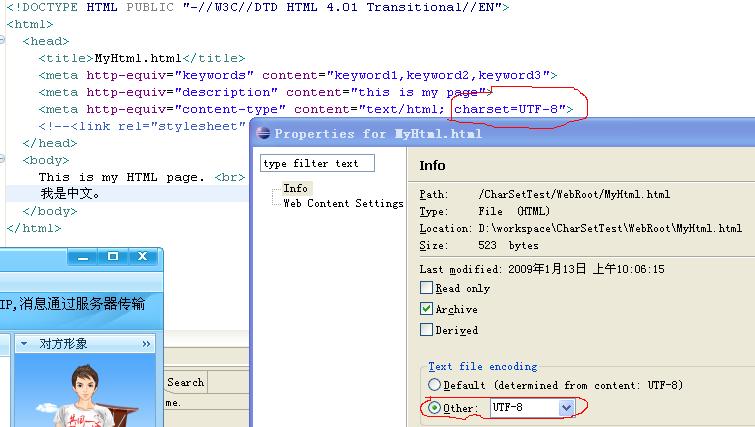
Comme vous pouvez le voir sur l'image, la méthode d'encodage du fichier est "UTF-8", comme indiqué par Other dans l'encadré rouge ci-dessous, qui est défini dans Eclipse. La case rouge au-dessus de l'image indique la méthode d'encodage utilisée par le navigateur pour ouvrir le fichier, qui peut être considérée comme « UTF-8 ».
Utilisez IE pour ouvrir le fichier et vous verrez l'image suivante :
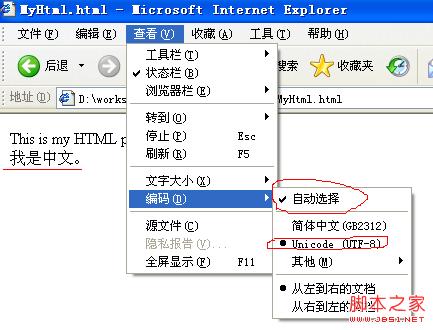
Vérifiez la méthode d'encodage du navigateur. Vous pouvez voir que le navigateur sélectionne automatiquement la méthode "UTF-8" et qu'aucun caractère tronqué n'apparaît.
Basculez la méthode d'encodage du navigateur sur "GB2312", vous pouvez voir l'image suivante :
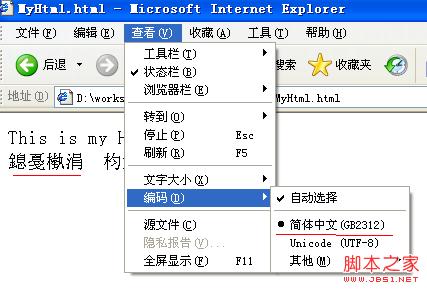
Test 2 :
Enregistrez le fichier html en mode "UTF-8" et définissez la méthode d'encodage dans l'en-tête du fichier sur "GBK", comme indiqué ci-dessous :
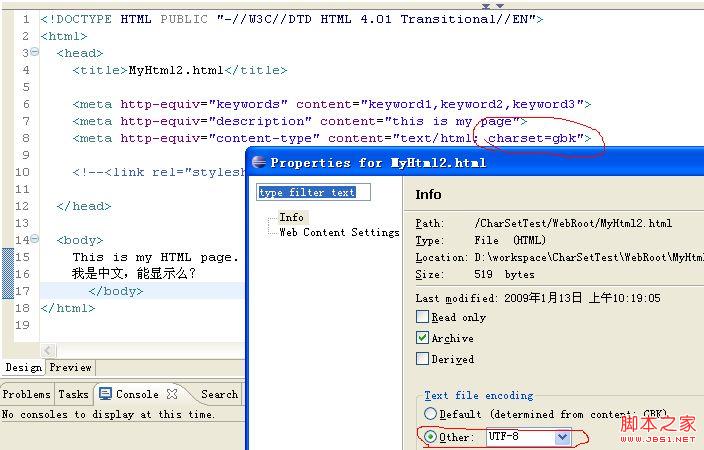
Ceci montre : la méthode d'encodage du fichier est "UTF-8", et la méthode d'ouverture de fichier par défaut est "GBK".
La capture d'écran de l'ouverture de ce fichier à l'aide d'IE est la suivante :
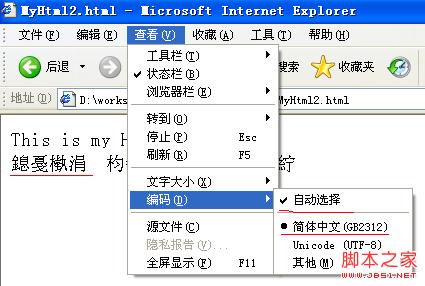
Vous pouvez voir que le navigateur l'ouvre en mode "GB2312" selon les instructions du fichier html. Étant donné que la méthode de codage du fichier lui-même est « UTF-8 », des caractères tronqués apparaissent. Mais le fichier source de la page Web n’est pas tronqué.
Sélectionnez la méthode de codage du navigateur comme "UTF-8" et vous pourrez voir que les caractères tronqués disparaissent. La capture d'écran est la suivante :
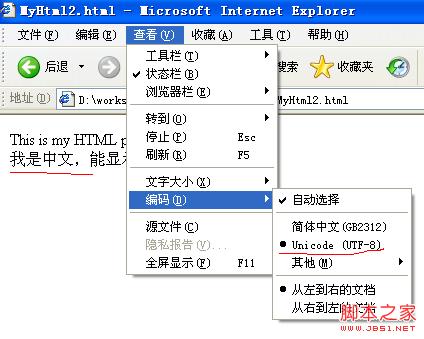
À ce stade, le test est terminé. Résumez les points suivants :
1. Le fichier html a un format d'encodage, qui ne peut être vu et défini que dans un éditeur spécifique.
2. Le "charset" défini dans le "content-type" dans l'en-tête du fichier html indique au navigateur la méthode d'encodage utilisée pour ouvrir le fichier.
3. Généralement, les méthodes de codage des points 1 et 2 doivent être cohérentes. Une incohérence peut entraîner des caractères tronqués.
4. Si le navigateur affiche des caractères tronqués, mais que le fichier source de la page n'est pas tronqué, vous pouvez voir le chinois correct en modifiant la méthode d'encodage du navigateur. Si le "jeu de caractères" correct est défini dans le fichier source, il n'y en a pas. vous devez le modifier. La méthode d'encodage du navigateur.

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Méthodes pour résoudre le problème des caractères chinois tronqués en PHP Dompdf
Mar 05, 2024 pm 03:45 PM
Méthodes pour résoudre le problème des caractères chinois tronqués en PHP Dompdf
Mar 05, 2024 pm 03:45 PM
Méthodes pour résoudre le problème chinois tronqué de PHPDompdf PHPDompdf est un outil de conversion de documents HTML en fichiers PDF. Il est puissant et facile à utiliser. Cependant, lors du traitement du contenu chinois, vous rencontrez parfois le problème des caractères chinois tronqués. Cet article présentera quelques méthodes pour résoudre le problème des caractères chinois tronqués dans PHPDompdf et fournira des exemples de code spécifiques. 1. Lors de l'utilisation de fichiers de polices pour traiter du contenu chinois, un problème courant est que Dompdf ne prend pas en charge le contenu chinois par défaut.
 La solution ultime au problème des caractères chinois tronqués dans PyCharm
Jan 27, 2024 am 08:00 AM
La solution ultime au problème des caractères chinois tronqués dans PyCharm
Jan 27, 2024 am 08:00 AM
La méthode ultime pour résoudre le problème des caractères chinois tronqués dans PyCharm nécessite des exemples de code spécifiques Introduction : PyCharm, en tant qu'environnement de développement intégré (IDE) Python couramment utilisé, possède des fonctions puissantes et une interface utilisateur conviviale, et est apprécié et utilisé par les utilisateurs. majorité des développeurs. Cependant, lorsque PyCharm traite des caractères chinois, il peut parfois rencontrer des caractères tronqués, ce qui provoque certains problèmes de développement et de débogage. Cet article explique comment résoudre le problème du chinois tronqué dans PyCharm et donne des exemples de code spécifiques. 1. Mettre en place le projet
 Causes courantes et solutions aux caractères chinois tronqués dans l'installation de MySQL
Mar 02, 2024 am 09:00 AM
Causes courantes et solutions aux caractères chinois tronqués dans l'installation de MySQL
Mar 02, 2024 am 09:00 AM
Raisons et solutions courantes pour les caractères chinois tronqués dans l'installation de MySQL MySQL est un système de gestion de base de données relationnelle couramment utilisé, mais vous pouvez rencontrer le problème des caractères chinois tronqués lors de l'utilisation, ce qui pose des problèmes aux développeurs et aux administrateurs système. Le problème des caractères chinois tronqués est principalement dû à des paramètres de jeu de caractères incorrects, à des jeux de caractères incohérents entre le serveur de base de données et le client, etc. Cet article présentera en détail les causes courantes et les solutions des caractères chinois tronqués dans l'installation de MySQL pour aider tout le monde à mieux résoudre ce problème. 1. Raisons courantes : paramètre du jeu de caractères
 Que faire si ajax transmet des caractères chinois tronqués
Nov 15, 2023 am 10:42 AM
Que faire si ajax transmet des caractères chinois tronqués
Nov 15, 2023 am 10:42 AM
Solutions pour qu'Ajax transmette des caractères chinois tronqués : 1. Définir une méthode de codage unifiée ; 2. Codage côté serveur ; 3. Décodage côté client ; 4. Définir les en-têtes de réponse HTTP ; Introduction détaillée : 1. Définissez une méthode de codage unifiée pour garantir que le serveur et le client utilisent la même méthode de codage. Dans des circonstances normales, UTF-8 est une méthode de codage couramment utilisée car elle peut prendre en charge plusieurs langues et jeux de caractères ; 2, Codage côté serveur. Côté serveur, assurez-vous que les données chinoises sont codées selon la méthode de codage correcte, puis transmises au client, etc.
 Que dois-je faire si la page Web PHP contient des caractères chinois tronqués ? Une solution complète
Mar 26, 2024 pm 03:27 PM
Que dois-je faire si la page Web PHP contient des caractères chinois tronqués ? Une solution complète
Mar 26, 2024 pm 03:27 PM
Le problème des caractères chinois tronqués dans les pages Web PHP est que les caractères chinois sont affichés sous forme de caractères tronqués dans l'affichage de la page Web. Cette situation est généralement due à un encodage incohérent ou au jeu de caractères non défini. Résoudre le problème des caractères chinois tronqués dans les pages Web PHP nécessite de partir de plusieurs aspects. Voici quelques solutions courantes et exemples de code spécifiques. Définir l'encodage du fichier PHP : Assurez-vous d'abord que l'encodage du fichier PHP lui-même est UTF-8. Vous pouvez définir l'encodage UTF-8 lors de l'enregistrement dans l'éditeur, ou ajouter le code suivant à l'en-tête du fichier PHP pour le définir. l'encodage : &l
 Méthodes pour résoudre le problème des caractères chinois tronqués dans le système Linux
Feb 19, 2024 am 09:22 AM
Méthodes pour résoudre le problème des caractères chinois tronqués dans le système Linux
Feb 19, 2024 am 09:22 AM
Le problème des caractères chinois tronqués sous Linux est un problème que de nombreux utilisateurs chinois rencontrent souvent lorsqu'ils utilisent des systèmes Linux. La principale raison des caractères chinois tronqués est que le codage de caractères par défaut utilisé par le système Linux est UTF-8, mais certains logiciels ou applications peuvent ne pas être compatibles avec le codage UTF-8, ce qui entraîne un affichage incorrect des caractères chinois. Il existe de nombreuses façons de résoudre ce problème. Plusieurs solutions courantes seront détaillées ci-dessous et des exemples de code spécifiques seront fournis. Modifier les paramètres de codage des caractères du terminal : Les paramètres de codage des caractères du terminal déterminent si le terminal peut correctement
 Une méthode pratique pour résoudre efficacement le problème des caractères chinois tronqués dans Eclipse
Jan 03, 2024 pm 05:50 PM
Une méthode pratique pour résoudre efficacement le problème des caractères chinois tronqués dans Eclipse
Jan 03, 2024 pm 05:50 PM
Des conseils pratiques pour résoudre rapidement les caractères chinois tronqués dans Eclipse nécessitent des exemples de code spécifiques Présentation : Eclipse est un environnement de développement intégré (IDE) largement utilisé qui prend non seulement en charge le développement de plusieurs langages de programmation, mais prend également en charge plusieurs systèmes d'exploitation. Cependant, parfois lors de l'utilisation d'Eclipse, nous pouvons rencontrer le problème des caractères chinois tronqués, ce qui gêne notre travail de développement. Cet article présentera quelques techniques pratiques pour nous aider à résoudre rapidement le problème des caractères chinois tronqués dans Eclipse et joindra des exemples de code spécifiques. un,
 Méthode efficace pour résoudre le problème tronqué du chinois matplotlib
Jan 13, 2024 am 11:03 AM
Méthode efficace pour résoudre le problème tronqué du chinois matplotlib
Jan 13, 2024 am 11:03 AM
Une méthode efficace pour résoudre rapidement les caractères chinois tronqués de matplotlib Introduction : matplotlib est une bibliothèque de dessins couramment utilisée en Python. Cependant, lors de l'utilisation du chinois pour l'annotation et l'affichage, des caractères tronqués apparaissent souvent. Cet article présentera quelques solutions de contournement efficaces et fournira des exemples de code spécifiques. 1. Définir la police matplotlib utilise la police système pour l'affichage chinois par défaut, mais la police système ne contient souvent pas de caractères chinois, vous devez donc définir manuellement la police chinoise appropriée. Tout d'abord, vous devez confirmer si l'ordinateur a
