

TI TPA2016D2 D类音频放大方案

欢迎进入IT技术社区论坛,与200万技术人员互动交流 >>进入 TI 公司的TPA2016D2 是立体声无滤波器的D类音频功率放大器,带有音量控制,动态范围压缩(DRC)和自动增益控制(AGC),5V工作时每路能向8欧姆负载1.7W的功率.器件具有独立的软件关断特性,并提供热保护和短
欢迎进入IT技术社区论坛,与200万技术人员互动交流 >>进入
TI 公司的TPA2016D2 是立体声无滤波器的D类音频功率放大器,带有音量控制,动态范围压缩(DRC)和自动增益控制(AGC),5V工作时每路能向8欧姆负载1.7W的功率.器件具有独立的软件关断特性,并提供热保护和短路保护,广泛应用在无线手机和PDA,手提导航设备,手提DVD播放器,笔记本电脑,收音机,游戏机以及智力玩具等.本文介绍了TPA2016D2的主要特性,功能方框图和应用电路以及TPA2016D2EVM评估板电路图和所用元件列表.The TPA2016D2 is a stereo, filter-free Class-D audio power amplifier with volume control, dynamic range compression (DRC) and automatic gain control (AGC). It is available in a 2.2 mm x 2.2 mm WCSP package.
The DRC/AGC function in the TPA2016D2 is programmable via a digital I2C interface. The DRC/AGC function can be configured to automatically prevent distortion of the audio signal and enhance quiet passages that are normally not heard. The DRC/AGC can also be configured to protect the speaker from damage at high power levels and compress the dynamic range of music to fit within the dynamic range of the speaker. The gain can be selected from -28 dB to +30 dB in 1-dB steps. The TPA2016D2 is capable of driving 1.7 W/Ch at 5 V or 750 mW/Ch at 3.6 V into 8 Ω load. The device features independent software shutdown controls for each channel and also provides thermal and short circuit protection.

图1. TPA2016D2外形图
TPA2016D2 主要特性:
Filter-Free Class-D Architecture
1.7 W/Ch Into 8 Ω at 5 V (10% THD+N)
750 mW/Ch Into 8 Ω at 3.6 V (10% THD+N)
Power Supply Range: 2.5 V to 5.5 V
Flexible Operation With/Without I2C
Programmable DRC/AGC Parameters
Digital I2C Volume Control
Selectable Gain from -28 dB to 30 dB in 1-dB Steps (when compression is used)
Selectable Attack, Release and Hold Times
4 Selectable Compression Ratios
Low Supply Current: 3.5 mA
Low Shutdown Current: 0.2 µA
High PSRR: 80 dB
Fast Start-up Time: 5 ms
AGC Enable/Disable Function
Limiter Enable/Disable Function
Short-Circuit and Thermal Protection
Space-Saving Package 2,2 mm × 2,2 mm Nano-Free WCSP (YZH)
应用范围:
Wireless or Cellular Handsets and PDAs
Portable Navigation Devices
Portable DVD Player
Notebook PCs
Portable Radio
Portable Games
Educational Toys
USB Speakers

图2. TPA2016D2功能方框图
图3. TPA2016D2简化应用电路
The TPA2016D2 evaluation module (EVM) is a complete, stand-alone audio board. It contains the TPA2016D2 WCSP (YZH) Class-D audio power amplifier.

图4. TPA2016D2EVM
[1] [2]


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
L'article de StableDiffusion3 est enfin là ! Ce modèle est sorti il y a deux semaines et utilise la même architecture DiT (DiffusionTransformer) que Sora. Il a fait beaucoup de bruit dès sa sortie. Par rapport à la version précédente, la qualité des images générées par StableDiffusion3 a été considérablement améliorée. Il prend désormais en charge les invites multithèmes, et l'effet d'écriture de texte a également été amélioré et les caractères tronqués n'apparaissent plus. StabilityAI a souligné que StableDiffusion3 est une série de modèles avec des tailles de paramètres allant de 800M à 8B. Cette plage de paramètres signifie que le modèle peut être exécuté directement sur de nombreux appareils portables, réduisant ainsi considérablement l'utilisation de l'IA.
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
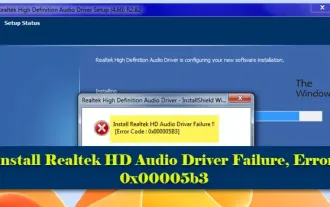 L'installation du pilote audio Realtek HD a échoué avec l'erreur 0x00005b3
Feb 19, 2024 am 10:42 AM
L'installation du pilote audio Realtek HD a échoué avec l'erreur 0x00005b3
Feb 19, 2024 am 10:42 AM
Si vous rencontrez le code d'erreur d'échec du pilote audio RealtekHD 0x00005b3 sur un PC Windows 11/10, veuillez vous référer aux étapes suivantes pour résoudre le problème. Nous vous guiderons tout au long du dépannage et de la résolution de l'erreur. Le code d'erreur 0x00005b3 peut être dû à des problèmes d'installation du pilote audio. Il se peut que le pilote actuel soit corrompu ou partiellement désinstallé, affectant l'installation du nouveau pilote. Ce problème peut également être dû à un espace disque insuffisant ou à un pilote audio incompatible avec votre version de Windows. L'installation du pilote audio RealtekHD a échoué ! ! [Code d'erreur : 0x00005B3] S'il y a un problème avec l'assistant d'installation du pilote audio Realtek, continuez à lire
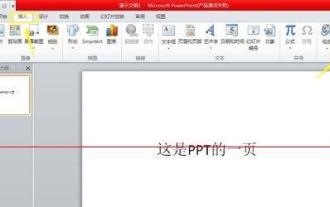 Comment configurer PPT pour lire automatiquement plusieurs audios
Mar 26, 2024 pm 06:21 PM
Comment configurer PPT pour lire automatiquement plusieurs audios
Mar 26, 2024 pm 06:21 PM
1. Ouvrez PPT, cliquez sur [Insérer] dans la barre de menu, puis cliquez sur [Audio]. 2. Dans la boîte de sélection de fichier qui s'ouvre, sélectionnez le premier fichier audio que vous souhaitez insérer. 3. Une fois l'insertion réussie, une icône de haut-parleur s'affichera dans le PPT pour représenter le fichier qui vient d'être inséré. Vous pouvez le lire et l'écouter et régler le volume pour contrôler son volume pendant le processus de sélection PPT. 4. Suivez la même méthode et insérez le deuxième fichier audio. À ce moment, deux icônes de haut-parleur seront affichées dans le PPT, représentant respectivement deux fichiers audio. 5. Cliquez pour sélectionner la première icône de fichier audio, puis cliquez sur le menu [Lecture]. 6. Dans Démarrer dans la barre d'outils, sélectionnez [Lire sur les diapositives] pour que cet audio soit lu dans chaque diapositive sans intervention humaine. 7. Suivez les étapes de l'étape 6
 Plus qu'une simple gaussienne 3D ! Dernier aperçu des techniques de reconstruction 3D de pointe
Jun 02, 2024 pm 06:57 PM
Plus qu'une simple gaussienne 3D ! Dernier aperçu des techniques de reconstruction 3D de pointe
Jun 02, 2024 pm 06:57 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que la reconstruction 3D basée sur l'image est une tâche difficile qui implique de déduire la forme 3D d'un objet ou d'une scène à partir d'un ensemble d'images d'entrée. Les méthodes basées sur l’apprentissage ont attiré l’attention pour leur capacité à estimer directement des formes 3D. Cet article de synthèse se concentre sur les techniques de reconstruction 3D de pointe, notamment la génération de nouvelles vues inédites. Un aperçu des développements récents dans les méthodes d'éclaboussure gaussienne est fourni, y compris les types d'entrée, les structures de modèle, les représentations de sortie et les stratégies de formation. Les défis non résolus et les orientations futures sont également discutés. Compte tenu des progrès rapides dans ce domaine et des nombreuses opportunités d’améliorer les méthodes de reconstruction 3D, un examen approfondi de l’algorithme semble crucial. Par conséquent, cette étude fournit un aperçu complet des progrès récents en matière de diffusion gaussienne. (Faites glisser votre pouce vers le haut
 Revoir! Fusion profonde de modèles (LLM/modèle de base/apprentissage fédéré/mise au point, etc.)
Apr 18, 2024 pm 09:43 PM
Revoir! Fusion profonde de modèles (LLM/modèle de base/apprentissage fédéré/mise au point, etc.)
Apr 18, 2024 pm 09:43 PM
Le 23 septembre, l'article « DeepModelFusion:ASurvey » a été publié par l'Université nationale de technologie de la défense, JD.com et l'Institut de technologie de Pékin. La fusion/fusion de modèles profonds est une technologie émergente qui combine les paramètres ou les prédictions de plusieurs modèles d'apprentissage profond en un seul modèle. Il combine les capacités de différents modèles pour compenser les biais et les erreurs des modèles individuels pour de meilleures performances. La fusion profonde de modèles sur des modèles d'apprentissage profond à grande échelle (tels que le LLM et les modèles de base) est confrontée à certains défis, notamment un coût de calcul élevé, un espace de paramètres de grande dimension, l'interférence entre différents modèles hétérogènes, etc. Cet article divise les méthodes de fusion de modèles profonds existantes en quatre catégories : (1) « Connexion de modèles », qui relie les solutions dans l'espace de poids via un chemin de réduction des pertes pour obtenir une meilleure fusion de modèles initiale.
 GPT-4o révolutionnaire : remodeler l'expérience d'interaction homme-machine
Jun 07, 2024 pm 09:02 PM
GPT-4o révolutionnaire : remodeler l'expérience d'interaction homme-machine
Jun 07, 2024 pm 09:02 PM
Le modèle GPT-4o publié par OpenAI constitue sans aucun doute une énorme avancée, notamment dans sa capacité à traiter plusieurs supports d'entrée (texte, audio, images) et à générer la sortie correspondante. Cette capacité rend l’interaction homme-machine plus naturelle et intuitive, améliorant considérablement l’aspect pratique et la convivialité de l’IA. Plusieurs points forts de GPT-4o incluent : une évolutivité élevée, des entrées et sorties multimédias, de nouvelles améliorations des capacités de compréhension du langage naturel, etc. 1. Entrée/sortie multimédia : GPT-4o+ peut accepter n'importe quelle combinaison de texte, d'audio et d'images en entrée et générer directement une sortie à partir de ces médias. Cela brise les limites des modèles d’IA traditionnels qui ne traitent qu’un seul type d’entrée, rendant ainsi l’interaction homme-machine plus flexible et plus diversifiée. Cette innovation contribue à alimenter les assistants intelligents
