

Oracle压缩功能小结2—预估表压缩的效果

在使用压缩之前,我们可以估算一下使用压缩能够拥有多大的效果。 11gr2以前可以使用dbms_comp_advisor,具体代码已经在附件中给出。只需要执行两个文件dbmscomp.sql和prvtcomp.plb,然后使用DBMS_COMP_ADVISOR.getratio存储过程即可。不再详细描述。 SQL set
在使用压缩之前,我们可以估算一下使用压缩能够拥有多大的效果。
11gr2以前可以使用dbms_comp_advisor,具体代码已经在附件中给出。只需要执行两个文件dbmscomp.sql和prvtcomp.plb,然后使用DBMS_COMP_ADVISOR.getratio存储过程即可。不再详细描述。
SQL> set serveroutput on
SQL> execdbms_comp_advisor.getratio('SH','SALES',10)
Sampling table: SH.SALES
Sampling percentage: 10%
Estimated compression ratio for the advancedcompression option is : 2.9611gr2以后系统会自带一个dbms_compression的包,用来代替dbms_comp_advisor提供服务。
_sys@FAKE> desc dbms_compression PROCEDURE GET_COMPRESSION_RATIO ArgumentName Type In/Out Default? ----------------------------------------------------- ------ -------- SCRATCHTBSNAME VARCHAR2 IN OWNNAME VARCHAR2 IN TABNAME VARCHAR2 IN PARTNAME VARCHAR2 IN COMPTYPE NUMBER IN BLKCNT_CMP BINARY_INTEGER OUT BLKCNT_UNCMP BINARY_INTEGER OUT ROW_CMP BINARY_INTEGER OUT ROW_UNCMP BINARY_INTEGER OUT CMP_RATIO NUMBER OUT COMPTYPE_STR VARCHAR2 OUT SUBSET_NUMROWS NUMBER IN DEFAULT FUNCTION GET_COMPRESSION_TYPE RETURNS NUMBER ArgumentName Type In/Out Default? ----------------------------------------------------- ------ -------- OWNNAME VARCHAR2 IN TABNAME VARCHAR2 IN ROW_ID ROWID IN PROCEDURE INCREMENTAL_COMPRESS ArgumentName Type In/Out Default? ----------------------------------------------------- ------ -------- OWNNAME VARCHAR2(30) IN TABNAME VARCHAR2(128) IN PARTNAME VARCHAR2(30) IN COLNAME VARCHAR2 IN DUMP_ON NUMBER IN DEFAULT AUTOCOMPRESS_ON NUMBER IN DEFAULT WHERE_CLAUSE VARCHAR2 IN DEFAULT
重点看GET_COMPRESSION_RATIO这个存储过程,它可以预估表的压缩比例。
可以使用以下的匿名块执行。
DECLARE
blkcnt_comp PLS_INTEGER;
blkcnt_uncm PLS_INTEGER;
row_comp PLS_INTEGER;
row_uncm PLS_INTEGER;
comp_ratio number;
comp_type VARCHAR2(30);
username varchar2(30) := '&USER';
tablename varchar2(30) := '&TB' ;
BEGIN
dbms_compression.get_compression_ratio('&Usedtbs',
username,
tablename,
NULL,
dbms_compression.COMP_FOR_OLTP,
blkcnt_comp,
blkcnt_uncm,
row_comp,
row_uncm,
comp_ratio,
comp_type);
dbms_output.put_line('Sampling table: '||username||'.'||tablename);
dbms_output.put_line('Estimated compression ratio: ' ||TO_CHAR(comp_ratio));
dbms_output.put_line('Compression Type: ' || comp_type);
END;
/执行效果:
/
Enter value for user: DEXTER
old 8: username varchar2(30) :='&USER';
new 8: username varchar2(30) :='DEXTER';
Enter value for tb: ACCOUNT
old 9: tablename varchar2(30) :='&TB' ;
new 9: tablename varchar2(30) :='ACCOUNT' ;
Enter value for usedtbs: USERS
old 11: dbms_compression.get_compression_ratio('&Usedtbs',
new 11: dbms_compression.get_compression_ratio('USERS',
Sampling table: DEXTER.ACCOUNT
Estimated compression ratio: 1
Compression Type: "Compress For OLTP"
PL/SQL procedure successfully completed.
因为表中的重复值非常少,上文中Estimated compression ratio: 1,表示没有任何压缩效果。
高级压缩,基于块内的压缩。所以就算有重复值,但是没有在一个块中,那么高级压缩还是无法起作用。
这里重点介绍一个参数 COMPTYPE,它一共有6个选项,分别是
COMP_NOCOMPRESS CONSTANT NUMBER := 1; COMP_FOR_OLTP CONSTANT NUMBER := 2; COMP_FOR_QUERY_HIGH CONSTANT NUMBER := 4; COMP_FOR_QUERY_LOW CONSTANT NUMBER := 8; COMP_FOR_ARCHIVE_HIGH CONSTANT NUMBER := 16; COMP_FOR_ARCHIVE_LOW CONSTANT NUMBER := 32;
Query high 以下都是HCC(HybridColumnar Compression)的内容,因为与Exadata的存储节点相关,所以在非Exadata一体机环境无法使用。不过有意思的是,你可以在普通环境下使用get_compression_ratio来预估压缩的比例。
11gr2以前compression-advisor存储过程下载地址:
http://download.csdn.net/detail/renfengjun/7514723

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Combien de temps les journaux de la base de données Oracle seront-ils conservés ?
May 10, 2024 am 03:27 AM
Combien de temps les journaux de la base de données Oracle seront-ils conservés ?
May 10, 2024 am 03:27 AM
La durée de conservation des journaux de la base de données Oracle dépend du type de journal et de la configuration, notamment : Redo logs : déterminé par la taille maximale configurée avec le paramètre "LOG_ARCHIVE_DEST". Redo logs archivés : Déterminé par la taille maximale configurée par le paramètre "DB_RECOVERY_FILE_DEST_SIZE". Redo logs en ligne : non archivés, perdus au redémarrage de la base de données et la durée de conservation est cohérente avec la durée d'exécution de l'instance. Journal d'audit : Configuré par le paramètre "AUDIT_TRAIL", conservé 30 jours par défaut.
 L'ordre des étapes de démarrage de la base de données Oracle est
May 10, 2024 am 01:48 AM
L'ordre des étapes de démarrage de la base de données Oracle est
May 10, 2024 am 01:48 AM
La séquence de démarrage de la base de données Oracle est la suivante : 1. Vérifiez les conditions préalables ; 2. Démarrez l'écouteur ; 3. Démarrez l'instance de base de données ; 4. Attendez que la base de données s'ouvre ; 6. Vérifiez l'état de la base de données ; . Activez le service (si nécessaire) ; 8. Testez la connexion.
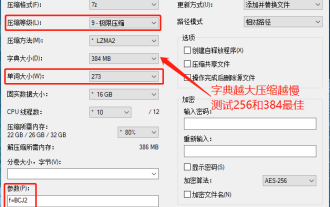 Paramètres du taux de compression maximum de 7-zip, comment compresser 7zip au minimum
Jun 18, 2024 pm 06:12 PM
Paramètres du taux de compression maximum de 7-zip, comment compresser 7zip au minimum
Jun 18, 2024 pm 06:12 PM
J'ai découvert que le package compressé téléchargé à partir d'un certain site Web de téléchargement sera plus volumineux que le package compressé d'origine après décompression. La différence est de plusieurs dizaines de Ko et de dizaines de Mo. S'il est téléchargé sur un disque cloud ou un espace payant, cela n'a pas d'importance. si le fichier est petit, s'il y a beaucoup de fichiers, le coût de stockage sera considérablement augmenté. J'ai fait quelques recherches à ce sujet et je peux en tirer des leçons si nécessaire. Niveau de compression : compression 9 extrême Taille du dictionnaire : 256 ou 384, plus le dictionnaire est compressé, plus il est lent. La différence de taux de compression est plus grande avant 256 Mo, et il n'y a aucune différence de taux de compression après 384 Mo. Taille du mot : maximum 273. Paramètres : f=BCJ2, le taux de compression des paramètres de test et d'ajout sera plus élevé
 Comment voir le nombre d'occurrences d'un certain caractère dans Oracle
May 09, 2024 pm 09:33 PM
Comment voir le nombre d'occurrences d'un certain caractère dans Oracle
May 09, 2024 pm 09:33 PM
Pour trouver le nombre d'occurrences d'un caractère dans Oracle, effectuez les étapes suivantes : Obtenez la longueur totale d'une chaîne ; Obtenez la longueur de la sous-chaîne dans laquelle un caractère apparaît. Comptez le nombre d'occurrences d'un caractère en soustrayant la longueur de la sous-chaîne ; de la longueur totale.
 Exigences de configuration matérielle du serveur de base de données Oracle
May 10, 2024 am 04:00 AM
Exigences de configuration matérielle du serveur de base de données Oracle
May 10, 2024 am 04:00 AM
Exigences de configuration matérielle du serveur de base de données Oracle : Processeur : multicœur, avec une fréquence principale d'au moins 2,5 GHz Pour les grandes bases de données, 32 cœurs ou plus sont recommandés. Mémoire : au moins 8 Go pour les petites bases de données, 16 à 64 Go pour les tailles moyennes, jusqu'à 512 Go ou plus pour les grandes bases de données ou les charges de travail lourdes. Stockage : disques SSD ou NVMe, matrices RAID pour la redondance et les performances. Réseau : réseau haut débit (10GbE ou supérieur), carte réseau dédiée, réseau à faible latence. Autres : alimentation stable, composants redondants, système d'exploitation et logiciels compatibles, dissipation thermique et système de refroidissement.
 De quelle quantité de mémoire Oracle a-t-il besoin ?
May 10, 2024 am 04:12 AM
De quelle quantité de mémoire Oracle a-t-il besoin ?
May 10, 2024 am 04:12 AM
La quantité de mémoire requise par Oracle dépend de la taille de la base de données, du niveau d'activité et du niveau de performances requis : pour le stockage des tampons de données, des tampons d'index, l'exécution d'instructions SQL et la gestion du cache du dictionnaire de données. Le montant exact dépend de la taille de la base de données, du niveau d'activité et du niveau de performances requis. Les meilleures pratiques incluent la définition de la taille SGA appropriée, le dimensionnement des composants SGA, l'utilisation d'AMM et la surveillance de l'utilisation de la mémoire.
 Les tâches planifiées Oracle exécutent l'étape de création une fois par jour
May 10, 2024 am 03:03 AM
Les tâches planifiées Oracle exécutent l'étape de création une fois par jour
May 10, 2024 am 03:03 AM
Pour créer une tâche planifiée dans Oracle qui s'exécute une fois par jour, vous devez effectuer les trois étapes suivantes : Créer une tâche. Ajoutez un sous-travail au travail et définissez son expression de planification sur "INTERVAL 1 DAY". Activez le travail.
 Quelle quantité de mémoire est nécessaire pour utiliser la base de données Oracle
May 10, 2024 am 03:42 AM
Quelle quantité de mémoire est nécessaire pour utiliser la base de données Oracle
May 10, 2024 am 03:42 AM
La quantité de mémoire requise pour une base de données Oracle dépend de la taille de la base de données, du type de charge de travail et du nombre d'utilisateurs simultanés. Recommandations générales : petites bases de données : 16 à 32 Go, bases de données moyennes : 32 à 64 Go, grandes bases de données : 64 Go ou plus. D'autres facteurs à prendre en compte incluent la version de la base de données, les options d'optimisation de la mémoire, la virtualisation et les meilleures pratiques (surveiller l'utilisation de la mémoire, ajuster les allocations).
