

cocos2dx多线程以及线程同步 与 cocos2dx内存管理与多线程问题

//-------------------------------------------------------------------- // // CCPoolManager // //-------------------------------------------------------------------- /////【diff - begin】- by layne////// CCPoolManager* CCPoolManager::shared
//--------------------------------------------------------------------
//
// CCPoolManager
//
//--------------------------------------------------------------------
/////【diff - begin】- by layne//////
CCPoolManager* CCPoolManager::sharedPoolManager()
{
if (s_pPoolManager == NULL)
{
s_pPoolManager = new CCPoolManager();
}
return s_pPoolManager;
}
void CCPoolManager::purgePoolManager()
{
CC_SAFE_DELETE(s_pPoolManager);
}
CCPoolManager::CCPoolManager()
{
// m_pReleasePoolStack = new CCArray();
// m_pReleasePoolStack->init();
// m_pCurReleasePool = 0;
m_pReleasePoolMultiStack = new CCDictionary();
}
CCPoolManager::~CCPoolManager()
{
// finalize();
// // we only release the last autorelease pool here
// m_pCurReleasePool = 0;
// m_pReleasePoolStack->removeObjectAtIndex(0);
//
// CC_SAFE_DELETE(m_pReleasePoolStack);
finalize();
CC_SAFE_DELETE(m_pReleasePoolMultiStack);
}
void CCPoolManager::finalize()
{
if(m_pReleasePoolMultiStack->count() > 0)
{
//CCAutoreleasePool* pReleasePool;
CCObject* pkey = NULL;
CCARRAY_FOREACH(m_pReleasePoolMultiStack->allKeys(), pkey)
{
if(!pkey)
break;
CCInteger *key = (CCInteger*)pkey;
CCArray *poolStack = (CCArray *)m_pReleasePoolMultiStack->objectForKey(key->getValue());
CCObject* pObj = NULL;
CCARRAY_FOREACH(poolStack, pObj)
{
if(!pObj)
break;
CCAutoreleasePool* pPool = (CCAutoreleasePool*)pObj;
pPool->clear();
}
}
}
}
void CCPoolManager::push()
{
// CCAutoreleasePool* pPool = new CCAutoreleasePool(); //ref = 1
// m_pCurReleasePool = pPool;
//
// m_pReleasePoolStack->addObject(pPool); //ref = 2
//
// pPool->release(); //ref = 1
pthread_mutex_lock(&m_mutex);
CCArray* pCurReleasePoolStack = getCurReleasePoolStack();
CCAutoreleasePool* pPool = new CCAutoreleasePool(); //ref = 1
pCurReleasePoolStack->addObject(pPool); //ref = 2
pPool->release(); //ref = 1
pthread_mutex_unlock(&m_mutex);
}
void CCPoolManager::pop()
{
// if (! m_pCurReleasePool)
// {
// return;
// }
//
// int nCount = m_pReleasePoolStack->count();
//
// m_pCurReleasePool->clear();
//
// if(nCount > 1)
// {
// m_pReleasePoolStack->removeObjectAtIndex(nCount-1);
//
// // if(nCount > 1)
// // {
// // m_pCurReleasePool = m_pReleasePoolStack->objectAtIndex(nCount - 2);
// // return;
// // }
// m_pCurReleasePool = (CCAutoreleasePool*)m_pReleasePoolStack->objectAtIndex(nCount - 2);
// }
//
// /*m_pCurReleasePool = NULL;*/
pthread_mutex_lock(&m_mutex);
CCArray* pCurReleasePoolStack = getCurReleasePoolStack();
CCAutoreleasePool* pCurReleasePool = getCurReleasePool();
if (pCurReleasePoolStack && pCurReleasePool)
{
int nCount = pCurReleasePoolStack->count();
pCurReleasePool->clear();
if(nCount > 1)
{
pCurReleasePoolStack->removeObject(pCurReleasePool);
}
}
pthread_mutex_unlock(&m_mutex);
}
void CCPoolManager::removeObject(CCObject* pObject)
{
// CCAssert(m_pCurReleasePool, "current auto release pool should not be null");
//
// m_pCurReleasePool->removeObject(pObject);
pthread_mutex_lock(&m_mutex);
CCAutoreleasePool* pCurReleasePool = getCurReleasePool();
CCAssert(pCurReleasePool, "current auto release pool should not be null");
pCurReleasePool->removeObject(pObject);
pthread_mutex_unlock(&m_mutex);
}
void CCPoolManager::addObject(CCObject* pObject)
{
// getCurReleasePool()->addObject(pObject);
pthread_mutex_lock(&m_mutex);
CCAutoreleasePool* pCurReleasePool = getCurReleasePool(true);
CCAssert(pCurReleasePool, "current auto release pool should not be null");
pCurReleasePool->addObject(pObject);
pthread_mutex_unlock(&m_mutex);
}
CCArray* CCPoolManager::getCurReleasePoolStack()
{
CCArray* pPoolStack = NULL;
pthread_t tid = pthread_self();
if(m_pReleasePoolMultiStack->count() > 0)
{
pPoolStack = (CCArray*)m_pReleasePoolMultiStack->objectForKey((int)tid);
}
if (!pPoolStack) {
pPoolStack = new CCArray();
m_pReleasePoolMultiStack->setObject(pPoolStack, (int)tid);
pPoolStack->release();
}
return pPoolStack;
}
CCAutoreleasePool* CCPoolManager::getCurReleasePool(bool autoCreate)
{
// if(!m_pCurReleasePool)
// {
// push();
// }
//
// CCAssert(m_pCurReleasePool, "current auto release pool should not be null");
//
// return m_pCurReleasePool;
CCAutoreleasePool* pReleasePool = NULL;
CCArray* pPoolStack = getCurReleasePoolStack();
if(pPoolStack->count() > 0)
{
pReleasePool = (CCAutoreleasePool*)pPoolStack->lastObject();
}
if (!pReleasePool && autoCreate) {
CCAutoreleasePool* pPool = new CCAutoreleasePool(); //ref = 1
pPoolStack->addObject(pPool); //ref = 2
pPool->release(); //ref = 1
pReleasePool = pPool;
}
return pReleasePool;
}
/////【diff - end】- by layne//////
代码下载地址:https://github.com/kaitiren/pthread-test-for-cocos2dx

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Optimisation importante de la mémoire, que dois-je faire si l'ordinateur passe à une vitesse de mémoire de 16 Go/32 Go et qu'il n'y a aucun changement ?
Jun 18, 2024 pm 06:51 PM
Optimisation importante de la mémoire, que dois-je faire si l'ordinateur passe à une vitesse de mémoire de 16 Go/32 Go et qu'il n'y a aucun changement ?
Jun 18, 2024 pm 06:51 PM
Pour les disques durs mécaniques ou les disques SSD SATA, vous ressentirez l'augmentation de la vitesse d'exécution du logiciel. S'il s'agit d'un disque dur NVME, vous ne la ressentirez peut-être pas. 1. Importez le registre sur le bureau et créez un nouveau document texte, copiez et collez le contenu suivant, enregistrez-le sous 1.reg, puis cliquez avec le bouton droit pour fusionner et redémarrer l'ordinateur. WindowsRegistryEditorVersion5.00[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\MemoryManagement]"DisablePagingExecutive"=d
 Comment vérifier l'utilisation de la mémoire sur Xiaomi Mi 14Pro ?
Mar 18, 2024 pm 02:19 PM
Comment vérifier l'utilisation de la mémoire sur Xiaomi Mi 14Pro ?
Mar 18, 2024 pm 02:19 PM
Récemment, Xiaomi a lancé un puissant smartphone haut de gamme, le Xiaomi 14Pro, qui présente non seulement un design élégant, mais également une technologie noire interne et externe. Le téléphone offre des performances optimales et d'excellentes capacités multitâches, permettant aux utilisateurs de profiter d'une expérience de téléphonie mobile rapide et fluide. Cependant, les performances seront également affectées par la mémoire. De nombreux utilisateurs souhaitent savoir comment vérifier l’utilisation de la mémoire du Xiaomi 14Pro, alors jetons-y un coup d’œil. Comment vérifier l’utilisation de la mémoire sur Xiaomi Mi 14Pro ? Introduction à la façon de vérifier l'utilisation de la mémoire du Xiaomi 14Pro. Ouvrez le bouton [Gestion des applications] dans [Paramètres] du téléphone Xiaomi 14Pro. Pour afficher la liste de toutes les applications installées, parcourez la liste et recherchez l'application que vous souhaitez afficher, cliquez dessus pour accéder à la page de détails de l'application. Dans la page de détails de la candidature
 Un ou plusieurs éléments du dossier que vous avez synchronisé ne correspondent pas à l'erreur Outlook
Mar 18, 2024 am 09:46 AM
Un ou plusieurs éléments du dossier que vous avez synchronisé ne correspondent pas à l'erreur Outlook
Mar 18, 2024 am 09:46 AM
Lorsque vous constatez qu'un ou plusieurs éléments de votre dossier de synchronisation ne correspondent pas au message d'erreur dans Outlook, cela peut être dû au fait que vous avez mis à jour ou annulé des éléments de réunion. Dans ce cas, vous verrez un message d'erreur indiquant que votre version locale des données est en conflit avec la copie distante. Cette situation se produit généralement dans l'application de bureau Outlook. Un ou plusieurs éléments du dossier que vous avez synchronisé ne correspondent pas. Pour résoudre le conflit, ouvrez les projets et retentez l'opération. Réparer Un ou plusieurs éléments dans les dossiers synchronisés ne correspondent pas à l'erreur Outlook Dans la version de bureau d'Outlook, vous pouvez rencontrer des problèmes lorsque des éléments du calendrier local entrent en conflit avec la copie du serveur. Heureusement, il existe des moyens simples d’aider
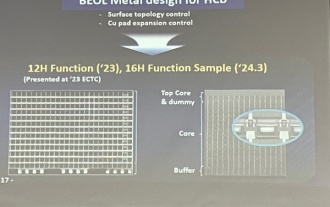 Samsung a annoncé l'achèvement de la vérification de la technologie du processus d'empilement de liaisons hybrides à 16 couches, qui devrait être largement utilisée dans la mémoire HBM4.
Apr 07, 2024 pm 09:19 PM
Samsung a annoncé l'achèvement de la vérification de la technologie du processus d'empilement de liaisons hybrides à 16 couches, qui devrait être largement utilisée dans la mémoire HBM4.
Apr 07, 2024 pm 09:19 PM
Selon le rapport, Dae Woo Kim, directeur de Samsung Electronics, a déclaré que lors de la réunion annuelle 2024 de la Korean Microelectronics and Packaging Society, Samsung Electronics terminerait la vérification de la technologie de mémoire HBM à liaison hybride à 16 couches. Il est rapporté que cette technologie a passé avec succès la vérification technique. Le rapport indique également que cette vérification technique jettera les bases du développement du marché de la mémoire dans les prochaines années. DaeWooKim a déclaré que Samsung Electronics avait réussi à fabriquer une mémoire HBM3 empilée à 16 couches basée sur la technologie de liaison hybride. À l'avenir, la technologie de liaison hybride empilée à 16 couches sera utilisée pour la production en série de mémoire HBM4. ▲ Source de l'image TheElec, comme ci-dessous. Par rapport au processus de liaison existant, la liaison hybride n'a pas besoin d'ajouter de bosses entre les couches de mémoire DRAM, mais connecte directement les couches supérieure et inférieure de cuivre au cuivre.
 Des sources affirment que Samsung Electronics et SK Hynix commercialiseront de la mémoire mobile empilée après 2026
Sep 03, 2024 pm 02:15 PM
Des sources affirment que Samsung Electronics et SK Hynix commercialiseront de la mémoire mobile empilée après 2026
Sep 03, 2024 pm 02:15 PM
Selon des informations publiées sur ce site Web le 3 septembre, le média coréen etnews a rapporté hier (heure locale) que les produits de mémoire mobile à structure empilée « de type HBM » de Samsung Electronics et SK Hynix seraient commercialisés après 2026. Des sources ont indiqué que les deux géants coréens de la mémoire considèrent la mémoire mobile empilée comme une source importante de revenus futurs et prévoient d'étendre la « mémoire de type HBM » aux smartphones, tablettes et ordinateurs portables afin de fournir de la puissance à l'IA finale. Selon des rapports précédents sur ce site, le produit de Samsung Electronics s'appelle LPWide I/O memory, et SK Hynix appelle cette technologie VFO. Les deux sociétés ont utilisé à peu près la même voie technique, à savoir combiner emballage en sortance et canaux verticaux. La mémoire LPWide I/O de Samsung Electronics a une largeur de 512 bits.
 Mar 22, 2024 pm 08:16 PM
Mar 22, 2024 pm 08:16 PM
Ce site rapportait le 21 mars que Micron avait tenu une conférence téléphonique après la publication de son rapport financier trimestriel. Lors de la conférence, le PDG de Micron, Sanjay Mehrotra, a déclaré que par rapport à la mémoire traditionnelle, la HBM consomme beaucoup plus de plaquettes. Micron a déclaré qu'en produisant la même capacité sur le même nœud, la mémoire HBM3E la plus avancée actuelle consomme trois fois plus de tranches que la DDR5 standard, et on s'attend à ce qu'à mesure que les performances s'améliorent et que la complexité de l'emballage s'intensifie, à l'avenir HBM4, ce ratio augmentera encore. . Si l’on se réfère aux rapports précédents sur ce site, ce ratio élevé est en partie dû au faible taux de rendement de HBM. La mémoire HBM est empilée avec des connexions TSV de mémoire DRAM multicouche. Un problème avec une couche signifie que l'ensemble.
 Lexar lance le kit de mémoire Ares Wings of War DDR5 7600 16 Go x2 : particules Hynix A-die, 1 299 yuans
May 07, 2024 am 08:13 AM
Lexar lance le kit de mémoire Ares Wings of War DDR5 7600 16 Go x2 : particules Hynix A-die, 1 299 yuans
May 07, 2024 am 08:13 AM
Selon les informations de ce site Web le 6 mai, Lexar a lancé la mémoire d'overclocking DDR57600CL36 de la série Ares Wings of War. L'ensemble de 16 Go x 2 sera disponible en prévente à 00h00 le 7 mai avec un dépôt de 50 yuans, et le prix est de 50 yuans. 1 299 yuans. La mémoire Lexar Wings of War utilise des puces mémoire Hynix A-die, prend en charge Intel XMP3.0 et fournit les deux préréglages d'overclocking suivants : 7600MT/s : CL36-46-46-961.4V8000MT/s : CL38-48-49 -1001.45V En termes de dissipation thermique, cet ensemble de mémoire est équipé d'un gilet de dissipation thermique tout en aluminium de 1,8 mm d'épaisseur et est équipé du tampon de graisse en silicone thermoconducteur exclusif de PMIC. La mémoire utilise 8 perles LED haute luminosité et prend en charge 13 modes d'éclairage RVB.
 Kingbang lance une nouvelle mémoire DDR5 8600, disponible en CAMM2, LPCAMM2 et modèles standards
Jun 08, 2024 pm 01:35 PM
Kingbang lance une nouvelle mémoire DDR5 8600, disponible en CAMM2, LPCAMM2 et modèles standards
Jun 08, 2024 pm 01:35 PM
Selon les informations de ce site le 7 juin, GEIL a lancé sa dernière solution DDR5 au Salon international de l'informatique de Taipei 2024 et a proposé les versions SO-DIMM, CUDIMM, CSODIMM, CAMM2 et LPCAMM2. ▲ Source de l'image : Wccftech Comme le montre l'image, la mémoire CAMM2/LPCAMM2 présentée par Jinbang adopte un design très compact, peut fournir une capacité maximale de 128 Go et une vitesse allant jusqu'à 8533 MT/s. Certains de ces produits peuvent même l'être. stable sur la plateforme AMDAM5 Overclocké à 9000MT/s sans aucun refroidissement auxiliaire. Selon les rapports, la mémoire de la série Polaris RGBDDR5 2024 de Jinbang peut fournir jusqu'à 8 400
