

Hive查询

Hive查询 排序和聚集 通过Hive提供的order by子句可以让最终的输出结果整体有序。但是因为Hive是基于Hadoop之上的,要生成这种整体有序的结果,就必须强迫Hadoop只利用一个Reduce来完成处理。这种方式的副作用就是回降低效率。 如果你不需要最终结果整体有序
Hive查询
排序和聚集
通过Hive提供的order by子句可以让最终的输出结果整体有序。但是因为Hive是基于Hadoop之上的,要生成这种整体有序的结果,就必须强迫Hadoop只利用一个Reduce来完成处理。这种方式的副作用就是回降低效率。
如果你不需要最终结果整体有序,你就可以使用sort by子句来进行排序。这种排序操作只保证每个Reduce的输出是有序的。如果你希望某些特定行被同一个Reduce处理,则你可以使用distribute子句来完成。比如:
表student(classNo,stuNo,score)数据如下:
C01 N0101 82
C01 N0102 59
C02 N0201 81
C01 N0103 65
C03 N0302 92
C02 N0202 82
C02 N0203 79
C03 N0301 56
C03 N0306 72
我们希望按照成绩由低到高输出每个班级的成绩信息。执行以下语句:
Select classNo,stuNo,score from student distribute byclassNo sort by score;
输出结果为:
C02 N0203 79
C02 N0201 81
C02 N0202 82
C03 N0301 56
C03 N0306 72
C03 N0302 92
C01 N0102 59
C01 N0103 65
C01 N0101 82
我们可以看到每一个班级里所有的学生成绩是有序的。因为同一个classNo的记录会被分发到一个单独的reduce处理,而同时sort by保证了每一个reduce的输出是有序的。
注意:
为了测试上例中的distribute by的效果,你应该首先设置足够多的reduce。比如上例中有3个不同的classNo,则我们需要设置reduce个数至少为3或更多。如果设置的reduce个数少于3,将会导致多个不同的classNo被分发到同一个reduce,从而不能产生你所期望的输出。设置命令如下:
set mapred.reduce.tasks = 3;
MapReduce脚本
如果我们需要在查询语句中调用外部脚本,比如Python,则我们可以使用transform,map,reduce等子句。
比如,我们希望过滤掉所有不及格的学生记录,只输出及格学生的成绩信息。
新建一个Python脚本文件score_pass.py,内容如下:
#! /usr/bin/env python
import sys
for line in sys.stdin:
(classNo,stuNo,score)= line.strip().split('\t')
ifint(score) >= 60:
print"%s\t%s\t%s" %(classNo,stuNo,score)
执行以下语句
add file /home/user/score_pass.py;
select transform(classNo,stuNo,score) using'score_pass.py' as classNo,stuNo,score from student;
输出结果为:
C01 N0101 82
C02 N0201 81
C01 N0103 65
C03 N0302 92
C02 N0202 82
C02 N0203 79
C03 N0306 72
注意:
1) 以上Python脚本中,分隔符只能是制表符(\t)。同样输出的分隔符也必须为制表符。这个是有hive自身决定的,不能更改,不要尝试使用其他分隔符,否则会报错。同时需要调用strip函数,以去除掉行尾的换行符。(或者直接使用不带参数的line.split()代替。
2) 使用脚本前,先使用add file语句注册脚本文件,以便hive将其分发到Hadoop集群。
3) Transfom传递数据到Python脚本,as语句指定输出的列。
连接(join)
直接编程使用Hadoop的MapReduce是一件比较费时的事情。Hive则大大简化了这个操作。
内连接(inner join)
和SQL的内连相似。执行以下语句查询每个学生的编号和教师名:
Select a.stuNo,b.teacherName from student a join teacherb on a.classNo = b.classNo;
输出结果如下:
N0203 Sun
N0202 Sun
N0201 Sun
N0306 Wang
N0301 Wang
N0302 Wang
N0103 Zhang
N0102 Zhang
N0101 Zhang
注意:
数据文件内容请参照上一篇文章。
不要使用select xx from aa bb where aa.f=bb.f这样的语法,hive不支持这种写法。
如果需要查看hive的执行计划,你可以在语句前加上explain,比如:
explain Select a.stuNo,b.teacherName from student a jointeacher b on a.classNo = b.classNo;
外连接(outer join)
和传统SQL类似,Hive提供了left outer join,right outer join,full out join。
半连接(semi join)
Hive不提供in子查询。此时你可以用leftsemi join实现同样的功能。
执行以下语句:
Select * from teacher left semi join student onstudent.classNo = teacher.classNo;
输出结果如下:
C02 Sun
C03 Wang
C01 Zhang
可以看出,C04 Dong没有出现在查询结果中,因为C04在表student中不存在。
注意:
右表(student)中的字段只能出现在on子句中,不能出现在其他地方,比如不能出现在select子句中。
Map连接(map join)
当一个表非常小,足以直接装载到内存中去时,可以使用map连接以提高效率,比如:
Select /*+mapjoin(teacher) */ a.stuNo,b.teacherNamefrom student a join teacher b on a.classNo = b.classNo;
以上红色标记部分采用了C的注释风格。
当连接时用到不等值判断时,也比较适合Map连接。具体原因需要深入了解Hive和MapReduce的工作原理。
子查询(sub query)
运行以下语句将返回所有班级平均分的最高记录。
Select max(avgScore) as maScore
from
(Select classNo,avg(score) as avgScore from student group byclassNo) a;
输出结果:
80.66666666666667
以上语句中红色部分为一个子查询,且别名为a。返回的子查询结果和一个表类似,可以被继续查询。
视图(view)
和传统数据库中的视图类似,Hive的视图只是一个定义,视图数据并不会存储到文件系统中。同样,视图是只读的。
运行以下两个命令:
Create view avg_score as
Select classNo,avg(score) as avgScore from student groupby classNo;
Select max(avgScore) as maScore
From avg_score;
可以看到输出结果和上例中的结果是一样的。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment vérifier vos diplômes universitaires sur Xuexin.com
Mar 28, 2024 pm 04:31 PM
Comment vérifier vos diplômes universitaires sur Xuexin.com
Mar 28, 2024 pm 04:31 PM
Comment vérifier mes diplômes universitaires sur Xuexin.com ? Vous pouvez vérifier vos diplômes universitaires sur Xuexin.com. De nombreux utilisateurs ne savent pas comment vérifier leurs diplômes universitaires sur Xuexin.com. Ensuite, l'éditeur vous propose un didacticiel graphique sur la façon de vérifier vos diplômes universitaires sur Xuexin.com. les utilisateurs viennent jeter un oeil ! Tutoriel d'utilisation de Xuexin.com : Comment vérifier vos diplômes universitaires sur Xuexin.com 1. Entrée Xuexin.com : https://www.chsi.com.cn/ 2. Requête sur le site Web : Étape 1 : Cliquez sur l'adresse Xuexin.com ci-dessus pour accéder à la page d'accueil Cliquez sur [Requête sur l'éducation] ; Étape 2 : Sur la dernière page Web, cliquez sur [Requête] comme indiqué par la flèche dans la figure ci-dessous. Étape 3 : Cliquez ensuite sur [Connexion au fichier de crédits académiques] sur la nouvelle page ; Étape 4 : Sur la page de connexion, saisissez les informations et cliquez sur [Connexion] ;
 12306 Comment vérifier l'historique des enregistrements d'achat de billets Comment vérifier l'historique des enregistrements d'achat de billets
Mar 28, 2024 pm 03:11 PM
12306 Comment vérifier l'historique des enregistrements d'achat de billets Comment vérifier l'historique des enregistrements d'achat de billets
Mar 28, 2024 pm 03:11 PM
Téléchargez la dernière version de l'application de réservation de billets 12306. C'est un logiciel d'achat de billets de voyage dont tout le monde est très satisfait. Il est très pratique d'aller où vous voulez. Il existe de nombreuses sources de billets fournies dans le logiciel. -authentification par nom pour acheter des billets en ligne. Tous les utilisateurs Vous pouvez facilement acheter des billets de voyage et des billets d'avion et profiter de différentes réductions. Vous pouvez également commencer à réserver à l'avance pour récupérer des billets. Vous pouvez réserver des hôtels ou des transferts spéciaux en voiture. Grâce à lui, vous pouvez aller où vous voulez et acheter des billets en un seul clic. Voyager est plus simple et plus pratique, ce qui rend l'expérience de voyage de chacun. plus confortable. Désormais, l'éditeur le détaille en ligne. Offre à 12306 utilisateurs un moyen de consulter l'historique des achats de billets. 1. Ouvrez Railway 12306, cliquez sur Mon dans le coin inférieur droit, puis cliquez sur Ma commande. 2. Cliquez sur Payé sur la page de commande. 3. Sur la page payante
 Comment vérifier la date d'activation sur le téléphone mobile Apple
Mar 08, 2024 pm 04:07 PM
Comment vérifier la date d'activation sur le téléphone mobile Apple
Mar 08, 2024 pm 04:07 PM
Si vous souhaitez vérifier la date d'activation à l'aide d'un téléphone mobile Apple, le meilleur moyen est de la vérifier via le numéro de série du téléphone mobile. Vous pouvez également la vérifier en visitant le site officiel d'Apple, en le connectant à un ordinateur et en en téléchargeant un troisième. -logiciel de fête pour le vérifier. Comment vérifier la date d'activation du téléphone mobile Apple Réponse : requête de numéro de série, requête sur le site officiel d'Apple, requête sur ordinateur, requête sur un logiciel tiers 1. La meilleure façon pour les utilisateurs est de connaître le numéro de série de leur téléphone mobile. le numéro de série en ouvrant Paramètres, Général, À propos de cette machine. 2. Grâce au numéro de série, vous pouvez non seulement connaître la date d'activation de votre téléphone mobile, mais également vérifier la version du téléphone mobile, l'origine du téléphone mobile, la date d'usine du téléphone mobile, etc. 3. Les utilisateurs visitent le site Web officiel d'Apple pour trouver une assistance technique, trouvent la colonne de service et de réparation en bas de la page et y vérifient les informations d'activation de l'iPhone. 4. Utilisateur
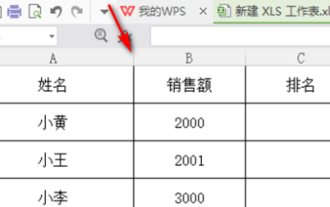 Comment trier les scores WPS
Mar 20, 2024 am 11:28 AM
Comment trier les scores WPS
Mar 20, 2024 am 11:28 AM
Dans notre travail, nous utilisons souvent le logiciel wps. Il existe de nombreuses façons de traiter les données dans le logiciel wps, et les fonctions sont également très puissantes. Nous utilisons souvent des fonctions pour trouver des moyennes, des résumés, etc. des méthodes qui peuvent être utilisées pour les données statistiques ont été préparées pour tout le monde dans la bibliothèque du logiciel WPS. Ci-dessous, nous présenterons les étapes à suivre pour trier les scores dans WPS. Après avoir lu ceci, vous pourrez tirer les leçons de cette expérience. 1. Ouvrez d’abord le tableau qui doit être classé. Comme indiqué ci-dessous. 2. Entrez ensuite la formule =rank(B2, B2 : B5, 0) et assurez-vous de saisir 0. Comme indiqué ci-dessous. 3. Après avoir saisi la formule, appuyez sur la touche F4 du clavier de l'ordinateur. Cette étape consiste à changer la référence relative en référence absolue.
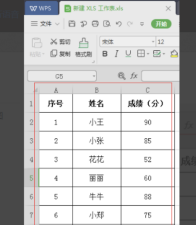 Comment trier les tableaux WPS pour faciliter les statistiques de données
Mar 20, 2024 pm 04:31 PM
Comment trier les tableaux WPS pour faciliter les statistiques de données
Mar 20, 2024 pm 04:31 PM
WPS est un logiciel bureautique très complet, comprenant l'édition de texte, les tableaux de données, les présentations PPT, les formats PDF, les organigrammes et d'autres fonctions. Parmi eux, ceux que nous utilisons le plus sont les textes, les tableaux et les démonstrations, et ce sont aussi ceux que nous connaissons le mieux. Dans notre travail d'étude, nous utilisons parfois des tableaux WPS pour établir des statistiques de données. Par exemple, l'école comptera les scores de chaque élève. Si nous devons trier manuellement les scores de tant d'élèves, ce sera vraiment un casse-tête. en fait, nous n'avons pas à nous inquiéter, car notre table WPS a une fonction de tri pour résoudre ce problème pour nous. Apprenons ensuite comment trier les WPS ensemble. Étapes de la méthode : Étape 1 : Nous devons d’abord ouvrir la table WPS qui doit être triée
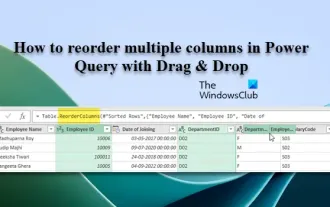 Comment réorganiser plusieurs colonnes dans Power Query par glisser-déposer
Mar 14, 2024 am 10:55 AM
Comment réorganiser plusieurs colonnes dans Power Query par glisser-déposer
Mar 14, 2024 am 10:55 AM
Dans cet article, nous allons vous montrer comment réorganiser plusieurs colonnes dans PowerQuery par glisser-déposer. Souvent, lors de l'importation de données provenant de diverses sources, les colonnes peuvent ne pas être dans l'ordre souhaité. La réorganisation des colonnes vous permet non seulement de les organiser dans un ordre logique adapté à vos besoins d'analyse ou de reporting, mais elle améliore également la lisibilité de vos données et accélère les tâches telles que le filtrage, le tri et l'exécution de calculs. Comment réorganiser plusieurs colonnes dans Excel ? Il existe de nombreuses façons de réorganiser les colonnes dans Excel. Vous pouvez simplement sélectionner l'en-tête de colonne et le faire glisser vers l'emplacement souhaité. Cependant, cette approche peut devenir fastidieuse lorsqu’il s’agit de grands tableaux comportant de nombreuses colonnes. Pour réorganiser les colonnes plus efficacement, vous pouvez utiliser l'éditeur de requête amélioré. Améliorer la requête
 Comparaison des similitudes et des différences entre MySQL et PL/SQL
Mar 16, 2024 am 11:15 AM
Comparaison des similitudes et des différences entre MySQL et PL/SQL
Mar 16, 2024 am 11:15 AM
MySQL et PL/SQL sont deux systèmes de gestion de bases de données différents, représentant respectivement les caractéristiques des bases de données relationnelles et des langages procéduraux. Cet article comparera les similitudes et les différences entre MySQL et PL/SQL, avec des exemples de code spécifiques à illustrer. MySQL est un système de gestion de bases de données relationnelles populaire qui utilise le langage de requête structuré (SQL) pour gérer et exploiter des bases de données. PL/SQL est un langage procédural unique à la base de données Oracle et est utilisé pour écrire des objets de base de données tels que des procédures stockées, des déclencheurs et des fonctions. même
 Tri avancé des tableaux PHP : comparateurs personnalisés et fonctions anonymes
Apr 27, 2024 am 11:09 AM
Tri avancé des tableaux PHP : comparateurs personnalisés et fonctions anonymes
Apr 27, 2024 am 11:09 AM
En PHP, il existe deux manières de trier un tableau dans un ordre personnalisé : Comparateur personnalisé : implémentez l'interface Comparable et spécifiez les règles de comparaison des deux objets. Fonction anonyme : créez une fonction anonyme en tant que comparateur personnalisé pour comparer deux objets par rapport à un critère.
