

cvKMeans2均值聚类分析+代码解析+灰度彩色图像聚类

1 K-均聚类算法的基本思想 K-均聚类算法 是著名的划分聚类分割方法。划分方法的基本思想是:给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,KN。而且这K个分组满足下列条件:(1) 每一个分组至少包含一个数据纪录;(
1 K-均值聚类算法的基本思想
K-均值聚类算法是著名的划分聚类分割方法。划分方法的基本思想是:给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K K-means算法的工作原理:算法首先随机从数据集中选取 K个点作为初始聚类中心,然后计算各个样本到聚类中心的距离,把样本归到离它最近的那个聚类中心所在的类。计算新形成的每一个聚类的数据对象的平均值来得到新的聚类中心,如果相邻两次的聚类中心没有任何变化,说明样本调整结束,聚类准则函数 已经收敛。本算法的一个特点是在每次迭代中都要考察每个样本的分类是否正确。若不正确,就要调整,在全部样本调整完后,再修改聚类中心,进入下一次迭代。这个过程将不断重复直到满足某个终止条件,终止条件可以是以下任何一个: (1)没有对象被重新分配给不同的聚类。 (2)聚类中心再发生变化。 (3)误差平方和局部最小。 K-means聚类算法的一般步骤: (1)从 n个数据对象任意选择 k 个对象作为初始聚类中心; (2)循环(3)到(4)直到每个聚类不再发生变化为止; (3)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分; (4)重新计算每个(有变化)聚类的均值(中心对象),直到聚类中心不再变化。这种划分使得下式最小 K-均值聚类法的缺点: (1)在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。 (2)在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。 (3) K-means算法需要不断地进行样本分类调整不断地计算调整后的新的聚类中心因此当数据量非常大时算法的时间开销是非常大的。 (4)K-means算法对一些离散点和初始k值敏感,不同的距离初始值对同样的数据样本可能得到不同的结果。
2 OpenCV中K均值函数分析:
CV_IMPL int
cvKMeans2( const CvArr* _samples, intcluster_count, CvArr* _labels,
CvTermCriteria termcrit, int attempts, CvRNG*,
intflags, CvArr* _centers, double* _compactness )
_samples:输入样本的浮点矩阵,每个样本一行,如对彩色图像进行聚类,每个通道一行,CV_32FC3
cluster_count:所给定的聚类数目
_labels:输出整数向量:每个样本对应的类别标识,其范围为0- (cluster_count-1),必须满足以下条件:
cv::Mat data = cv::cvarrToMat(_samples),labels = cv::cvarrToMat(_labels);
CV_Assert(labels.isContinuous() && labels.type() == CV_32S &&
(labels.cols == 1 || labels.rows == 1)&&
labels.cols + labels.rows - 1 ==data.rows );
termcrit:指定聚类的最大迭代次数和/或精度(两次迭代引起的聚类中心的移动距离),其执行 k-means 算法搜索 cluster_count 个类别的中心并对样本进行分类,输出 labels(i) 为样本i的类别标识。其中CvTermCriteria为OpenCV中的迭代算法的终止准则,其结构如下:
#define CV_TERMCRIT_ITER 1
#define CV_TERMCRIT_NUMBER CV_TERMCRIT_ITER
#define CV_TERMCRIT_EPS 2
typedef struct CvTermCriteria
{
int type; int max_iter; double epsilon;
} CvTermCriteria;
max_iter:最大迭代次数。 epsilon:结果的精确性 。
attempts:
flags: 与labels和centers相关
_centers: 输出聚类中心,可以不用设置输出聚类中心,但如果想输出聚类中心必须满足以下条件:
CV_Assert(!centers.empty() );
CV_Assert( centers.rows == cluster_count );
CV_Assert( centers.cols ==data.cols );
CV_Assert( centers.depth() == data.depth() );
聚类中心的获得方式:(以三类为例)
double cent0 = centers->data.fl[0];
double cent1 = centers->data.fl[1];
double cent2 = centers->data.fl[2];
CV_IMPL int
cvKMeans2( const CvArr* _samples,int cluster_count,CvArr* _labels,
CvTermCriteriatermcrit, intattempts, CvRNG*,
int flags, CvArr* _centers, double* _compactness )
{
cv::Mat data = cv::cvarrToMat(_samples), labels= cv::cvarrToMat(_labels), centers;
if( _centers )
{
centers= cv::cvarrToMat(_centers);
// 将centers和data转换为行向量
centers= centers.reshape(1);
data= data.reshape(1);
// centers必须满足的条件
CV_Assert(!centers.empty());
CV_Assert(centers.rows== cluster_count );
CV_Assert(centers.cols== data.cols);
CV_Assert(centers.depth()== data.depth());
}
// labels必须满足的条件
CV_Assert(labels.isContinuous()&& labels.type()== CV_32S &&
(labels.cols == 1 || labels.rows == 1) &&
labels.cols + labels.rows - 1 == data.rows );
// 调用kmeans实现聚类,如果定义了输出聚类中心矩阵,那么输出centers
double compactness = cv::kmeans(data, cluster_count, labels,termcrit, attempts,
flags, _centers? cv::_OutputArray(centers) : cv::_OutputArray() );
if( _compactness )
*_compactness= compactness;
return 1;
}
double cv::kmeans( InputArray_data, int K,
InputOutputArray_bestLabels,
TermCriteriacriteria, intattempts,
intflags, OutputArray_centers )
{
const int SPP_TRIALS =3;
Mat data = _data.getMat();
// 判断data是否为行向量
bool isrow = data.rows == 1 && data.channels() > 1;
int N = !isrow ? data.rows : data.cols;
int dims = (!isrow? data.cols: 1)*data.channels();
int type = data.depth();
attempts= std::max(attempts, 1);
CV_Assert(data.dimstype == CV_32F && K> 0 );
CV_Assert(N >= K);
_bestLabels.create(N, 1, CV_32S, -1, true);
Mat _labels, best_labels = _bestLabels.getMat();
// 使用已初始化的labels
if( flags & CV_KMEANS_USE_INITIAL_LABELS)
{
CV_Assert((best_labels.cols== 1 || best_labels.rows== 1) &&
best_labels.cols*best_labels.rows == N&&
best_labels.type() == CV_32S&&
best_labels.isContinuous());
best_labels.copyTo(_labels);
}
else
{
if( !((best_labels.cols== 1 || best_labels.rows== 1) &&
best_labels.cols*best_labels.rows == N&&
best_labels.type() == CV_32S&&
best_labels.isContinuous()))
best_labels.create(N, 1, CV_32S);
_labels.create(best_labels.size(), best_labels.type());
}
int* labels = _labels.ptrint>();
Mat centers(K, dims, type), old_centers(K, dims, type), temp(1, dims, type);
vectorint> counters(K);
vectorVec2f> _box(dims);
Vec2f* box = &_box[0];
double best_compactness = DBL_MAX,compactness = 0;
RNG&rng = theRNG();
int a, iter, i, j, k;
// 对终止条件进行修改
if( criteria.type& TermCriteria::EPS)
criteria.epsilon = std::max(criteria.epsilon, 0.);
else
criteria.epsilon = FLT_EPSILON;
criteria.epsilon *= criteria.epsilon;
if( criteria.type& TermCriteria::COUNT)
criteria.maxCount = std::min(std::max(criteria.maxCount, 2), 100);
else
criteria.maxCount = 100;
// 聚类数目为1类的时候
if( K == 1 )
{
attempts= 1;
criteria.maxCount = 2;
}
const float* sample = data.ptrfloat>(0);
for( j = 0; j dims; j++ )
box[j] = Vec2f(sample[j], sample[j]);
for( i = 1; i N; i++ )
{
sample= data.ptrfloat>(i);
for( j = 0; j dims; j++ )
{
floatv = sample[j];
box[j][0] = std::min(box[j][0], v);
box[j][1] = std::max(box[j][1], v);
}
}
for( a = 0; a attempts; a++ )
{
double max_center_shift = DBL_MAX;
for( iter = 0;; )
{
swap(centers, old_centers);
/*enum
{
KMEANS_RANDOM_CENTERS=0, // Chooses random centers for k-Meansinitialization
KMEANS_PP_CENTERS=2, // Usesk-Means++ algorithm for initialization
KMEANS_USE_INITIAL_LABELS=1 // Uses the user-provided labels for K-Meansinitialization
};*/
if(iter == 0 && (a > 0 || !(flags& KMEANS_USE_INITIAL_LABELS)) )
{
if(flags & KMEANS_PP_CENTERS)
generateCentersPP(data, centers, K, rng, SPP_TRIALS);
else
{
for(k = 0; kK; k++)
generateRandomCenter(_box, centers.ptrfloat>(k), rng);
}
}
else
{
if(iter == 0 && a == 0 && (flags& KMEANS_USE_INITIAL_LABELS) )
{
for(i = 0; iN; i++)
CV_Assert( (unsigned)labels[i] unsigned)K);
}
//compute centers
centers= Scalar(0);
for(k = 0; kK; k++)
counters[k] = 0;
for(i = 0; iN; i++)
{
sample= data.ptrfloat>(i);
k= labels[i];
float*center = centers.ptrfloat>(k);
j=0;
#ifCV_ENABLE_UNROLLED
for(;j dims- 4; j += 4 )
{
float t0 = center[j] + sample[j];
float t1 = center[j+1] + sample[j+1];
center[j] = t0;
center[j+1] = t1;
t0 = center[j+2] + sample[j+2];
t1 = center[j+3] + sample[j+3];
center[j+2] = t0;
center[j+3] = t1;
}
#endif
for(; j dims;j++ )
center[j] += sample[j];
counters[k]++;
}
if(iter > 0 )
max_center_shift= 0;
for(k = 0; kK; k++)
{
if(counters[k]!= 0 )
continue;
// if somecluster appeared to be empty then:
// 1. find the biggest cluster
// 2. find the farthest from the center pointin the biggest cluster
// 3. exclude the farthest point from thebiggest cluster and form a new 1-point cluster.
intmax_k = 0;
for(int k1 = 1; k1 K; k1++ )
{
if( counters[max_k] counters[k1] )
max_k = k1;
}
doublemax_dist = 0;
intfarthest_i = -1;
float*new_center = centers.ptrfloat>(k);
float*old_center = centers.ptrfloat>(max_k);
float*_old_center = temp.ptrfloat>();// normalized
floatscale = 1.f/counters[max_k];
for(j = 0; jdims; j++)
_old_center[j] = old_center[j]*scale;
for(i = 0; iN; i++)
{
if(labels[i]!= max_k )
continue;
sample = data.ptrfloat>(i);
double dist = normL2Sqr_(sample,_old_center, dims);
if( max_dist dist )
{
max_dist = dist;
farthest_i = i;
}
}
counters[max_k]--;
counters[k]++;
labels[farthest_i] = k;
sample= data.ptrfloat>(farthest_i);
for(j = 0; jdims; j++)
{
old_center[j] -= sample[j];
new_center[j] += sample[j];
}
}
for(k = 0; kK; k++)
{
float*center = centers.ptrfloat>(k);
CV_Assert(counters[k]!= 0 );
floatscale = 1.f/counters[k];
for(j = 0; jdims; j++)
center[j] *= scale;
if(iter > 0 )
{
double dist = 0;
const float* old_center = old_centers.ptrfloat>(k);
for( j = 0; j dims; j++ )
{
double t = center[j] - old_center[j];
dist += t*t;
}
max_center_shift= std::max(max_center_shift, dist);
}
}
}
if(++iter == MAX(criteria.maxCount,2) || max_center_shift criteria.epsilon)
break;
// assignlabels
Matdists(1, N,CV_64F);
double*dist = dists.ptrdouble>(0);
parallel_for_(Range(0, N),
KMeansDistanceComputer(dist,labels, data,centers));
compactness= 0;
for(i = 0; iN; i++)
{
compactness+= dist[i];
}
}
if( compactness best_compactness)
{
best_compactness= compactness;
if(_centers.needed())
centers.copyTo(_centers);
_labels.copyTo(best_labels);
}
}
return best_compactness;
}
3 采用cvKMeans2对灰度图像进行聚类分析
//灰度图像聚类分析
BOOL GrayImageSegmentByKMeans2(const IplImage* pImg, IplImage*pResult, intsortFlag)
{
assert(pImg != NULL&& pImg->nChannels== 1);
//创建样本矩阵,CV_32FC1代表位浮点通道(灰度图像)
CvMat*samples = cvCreateMat((pImg->width)* (pImg->height),1, CV_32FC1);
//创建类别标记矩阵,CV_32SF1代表位整型通道
CvMat*clusters = cvCreateMat((pImg->width)* (pImg->height),1, CV_32SC1);
//创建类别中心矩阵
CvMat*centers = cvCreateMat(nClusters, 1, CV_32FC1);
// 将原始图像转换到样本矩阵
{
intk = 0;
CvScalars;
for(int i = 0; i pImg->width; i++)
{
for(int j=0;j pImg->height; j++)
{
s.val[0] = (float)cvGet2D(pImg, j, i).val[0];
cvSet2D(samples,k++, 0, s);
}
}
}
//开始聚类,迭代次,终止误差.0
cvKMeans2(samples, nClusters,clusters, cvTermCriteria(CV_TERMCRIT_ITER + CV_TERMCRIT_EPS,100, 1.0), 1, 0, 0, centers);
// 无需排序直接输出时
if (sortFlag == 0)
{
intk = 0;
intval = 0;
floatstep = 255 / ((float)nClusters - 1);
CvScalars;
for(int i = 0; i pImg->width; i++)
{
for(int j = 0;j pImg->height; j++)
{
val = (int)clusters->data.i[k++];
s.val[0] = 255- val * step;//这个是将不同类别取不同的像素值,
cvSet2D(pResult,j, i, s); //将每个像素点赋值
}
}
returnTRUE;
}
4 利用OpenCV对彩色图像进行颜色聚类:
BOOL ColorImageSegmentByKMeans2(const IplImage* img, IplImage* pResult, int sortFlag)
{
assert(img != NULL&& pResult != NULL);
assert(img->nChannels== 3 && pResult->nChannels == 1);
int i,j;
CvMat*samples=cvCreateMat((img->width)*(img->height),1,CV_32FC3);//创建样本矩阵,CV_32FC3代表位浮点通道(彩色图像)
CvMat*clusters=cvCreateMat((img->width)*(img->height),1,CV_32SC1);//创建类别标记矩阵,CV_32SF1代表位整型通道
int k=0;
for (i=0;iimg->width;i++)
{
for(j=0;jimg->height;j++)
{
CvScalars;
//获取图像各个像素点的三通道值(RGB)
s.val[0]=(float)cvGet2D(img,j,i).val[0];
s.val[1]=(float)cvGet2D(img,j,i).val[1];
s.val[2]=(float)cvGet2D(img,j,i).val[2];
cvSet2D(samples,k++,0,s);//将像素点三通道的值按顺序排入样本矩阵
}
}
cvKMeans2(samples,nClusters,clusters,cvTermCriteria(CV_TERMCRIT_ITER,100,1.0));//开始聚类,迭代次,终止误差.0
k=0;
int val=0;
float step=255/(nClusters-1);
for (i=0;iimg->width;i++)
{
for(j=0;jimg->height;j++)
{
val=(int)clusters->data.i[k++];
CvScalars;
s.val[0]=255-val*step;//这个是将不同类别取不同的像素值,
cvSet2D(pResult,j,i,s); //将每个像素点赋值
}
}
cvReleaseMat(&samples);
cvReleaseMat(&clusters);
return TRUE;
}

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Explication détaillée de l'erreur Oracle 3114 : comment la résoudre rapidement
Mar 08, 2024 pm 02:42 PM
Explication détaillée de l'erreur Oracle 3114 : comment la résoudre rapidement
Mar 08, 2024 pm 02:42 PM
Explication détaillée de l'erreur Oracle 3114 : Comment la résoudre rapidement, des exemples de code spécifiques sont nécessaires Lors du développement et de la gestion de la base de données Oracle, nous rencontrons souvent diverses erreurs, parmi lesquelles l'erreur 3114 est un problème relativement courant. L'erreur 3114 indique généralement un problème avec la connexion à la base de données, qui peut être provoqué par une défaillance du réseau, un arrêt du service de base de données ou des paramètres de chaîne de connexion incorrects. Cet article expliquera en détail la cause de l'erreur 3114 et comment résoudre rapidement ce problème, et joindra le code spécifique.
 Analyse de la signification et de l'utilisation du point médian en PHP
Mar 27, 2024 pm 08:57 PM
Analyse de la signification et de l'utilisation du point médian en PHP
Mar 27, 2024 pm 08:57 PM
[Analyse de la signification et de l'utilisation du point médian PHP] En PHP, le point médian (.) est un opérateur couramment utilisé, utilisé pour connecter deux chaînes ou propriétés ou méthodes d'objets. Dans cet article, nous approfondirons la signification et l’utilisation des points médians en PHP, en les illustrant avec des exemples de code concrets. 1. Opérateur de point médian de chaîne de connexion L’utilisation la plus courante en PHP consiste à connecter deux chaînes. En plaçant . entre deux chaînes, vous pouvez les assembler pour former une nouvelle chaîne. $string1=&qu
 Parsing Wormhole NTT : un framework ouvert pour n'importe quel jeton
Mar 05, 2024 pm 12:46 PM
Parsing Wormhole NTT : un framework ouvert pour n'importe quel jeton
Mar 05, 2024 pm 12:46 PM
Wormhole est un leader en matière d'interopérabilité blockchain, axé sur la création de systèmes décentralisés résilients et évolutifs qui donnent la priorité à la propriété, au contrôle et à l'innovation sans autorisation. Le fondement de cette vision est un engagement envers l'expertise technique, les principes éthiques et l'alignement de la communauté pour redéfinir le paysage de l'interopérabilité avec simplicité, clarté et une large suite de solutions multi-chaînes. Avec l’essor des preuves sans connaissance, des solutions de mise à l’échelle et des normes de jetons riches en fonctionnalités, les blockchains deviennent plus puissantes et l’interopérabilité devient de plus en plus importante. Dans cet environnement d’applications innovant, de nouveaux systèmes de gouvernance et des capacités pratiques offrent des opportunités sans précédent aux actifs du réseau. Les créateurs de protocoles se demandent désormais comment opérer dans ce nouveau marché multi-chaînes.
 Créer et exécuter des fichiers Linux '.a'
Mar 20, 2024 pm 04:46 PM
Créer et exécuter des fichiers Linux '.a'
Mar 20, 2024 pm 04:46 PM
Travailler avec des fichiers dans le système d'exploitation Linux nécessite l'utilisation de diverses commandes et techniques qui permettent aux développeurs de créer et d'exécuter efficacement des fichiers, du code, des programmes, des scripts et d'autres éléments. Dans l'environnement Linux, les fichiers portant l'extension « .a » sont d'une grande importance en tant que bibliothèques statiques. Ces bibliothèques jouent un rôle important dans le développement de logiciels, permettant aux développeurs de gérer et de partager efficacement des fonctionnalités communes sur plusieurs programmes. Pour un développement logiciel efficace dans un environnement Linux, il est crucial de comprendre comment créer et exécuter des fichiers « .a ». Cet article explique comment installer et configurer de manière complète le fichier Linux « .a ». Explorons la définition, l'objectif, la structure et les méthodes de création et d'exécution du fichier Linux « .a ». Qu'est-ce que L
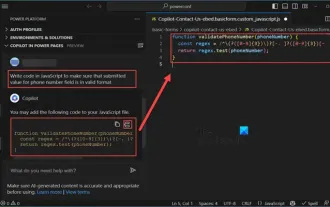 Comment utiliser Copilot pour générer du code
Mar 23, 2024 am 10:41 AM
Comment utiliser Copilot pour générer du code
Mar 23, 2024 am 10:41 AM
En tant que programmeur, je suis enthousiasmé par les outils qui simplifient l'expérience de codage. À l'aide d'outils d'intelligence artificielle, nous pouvons générer du code de démonstration et apporter les modifications nécessaires selon les exigences. Le nouvel outil Copilot dans Visual Studio Code nous permet de créer du code généré par l'IA avec des interactions de chat en langage naturel. En expliquant les fonctionnalités, nous pouvons mieux comprendre la signification du code existant. Comment utiliser Copilot pour générer du code ? Pour commencer, nous devons d’abord obtenir la dernière extension PowerPlatformTools. Pour y parvenir, vous devez vous rendre sur la page de l'extension, rechercher "PowerPlatformTool" et cliquer sur le bouton Installer.
 Analyse des nouvelles fonctionnalités de Win11 : Comment ignorer la connexion au compte Microsoft
Mar 27, 2024 pm 05:24 PM
Analyse des nouvelles fonctionnalités de Win11 : Comment ignorer la connexion au compte Microsoft
Mar 27, 2024 pm 05:24 PM
Analyse des nouvelles fonctionnalités de Win11 : Comment ignorer la connexion à un compte Microsoft Avec la sortie de Windows 11, de nombreux utilisateurs ont constaté qu'il apportait plus de commodité et de nouvelles fonctionnalités. Cependant, certains utilisateurs n'aiment pas que leur système soit lié à un compte Microsoft et souhaitent ignorer cette étape. Cet article présentera quelques méthodes pour aider les utilisateurs à ne pas se connecter à un compte Microsoft dans Windows 11 afin d'obtenir une expérience plus privée et autonome. Tout d’abord, comprenons pourquoi certains utilisateurs hésitent à se connecter à leur compte Microsoft. D'une part, certains utilisateurs craignent
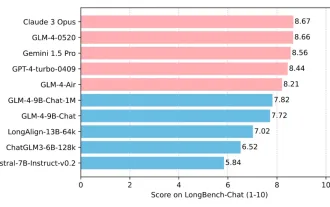 L'Université Tsinghua et Zhipu AI open source GLM-4 : lancent une nouvelle révolution dans le traitement du langage naturel
Jun 12, 2024 pm 08:38 PM
L'Université Tsinghua et Zhipu AI open source GLM-4 : lancent une nouvelle révolution dans le traitement du langage naturel
Jun 12, 2024 pm 08:38 PM
Depuis le lancement du ChatGLM-6B le 14 mars 2023, les modèles de la série GLM ont reçu une large attention et une grande reconnaissance. Surtout après que ChatGLM3-6B soit open source, les développeurs sont pleins d'attentes pour le modèle de quatrième génération lancé par Zhipu AI. Cette attente a finalement été pleinement satisfaite avec la sortie du GLM-4-9B. La naissance du GLM-4-9B Afin de donner aux petits modèles (10B et moins) des capacités plus puissantes, l'équipe technique de GLM a lancé ce nouveau modèle open source de la série GLM de quatrième génération : GLM-4-9B après près de six mois de exploration. Ce modèle compresse considérablement la taille du modèle tout en garantissant la précision, et offre une vitesse d'inférence plus rapide et une efficacité plus élevée. L’exploration de l’équipe technique du GLM n’a pas
 Créez un agent en une phrase ! Robin Li : L'ère approche où tout le monde sera développeur
Apr 17, 2024 pm 02:28 PM
Créez un agent en une phrase ! Robin Li : L'ère approche où tout le monde sera développeur
Apr 17, 2024 pm 02:28 PM
Le grand modèle bouleverse tout, et arrive finalement à la tête de cet éditeur. C'est aussi un Agent qui a été créé en une seule phrase. Comme ça, donnez-lui un article, et en moins d'une seconde, de nouvelles suggestions de titres sortiront. Par rapport à moi, on ne peut dire que cette efficacité est aussi rapide que l'éclair et aussi lente qu'un paresseux... Ce qui est encore plus incroyable, c'est que la création de cet Agent ne prend en réalité que quelques minutes. L'invite appartient à tante Jiang : Et si vous souhaitez également ressentir ce sentiment subversif, désormais, sur la base de la nouvelle plateforme intelligente Wenxin lancée par Baidu, chacun peut créer gratuitement son propre assistant intelligent. Vous pouvez utiliser les moteurs de recherche, les plates-formes matérielles intelligentes, la reconnaissance vocale, les cartes, les voitures et autres canaux écologiques mobiles Baidu pour permettre à davantage de personnes d'utiliser votre créativité ! Robin Li lui-même
