

Berkeley DB 由浅入深【转自架构师杨建】

for (fail = 0;;) { /* Begin the transaction. */ if ((ret = dbenv-txn_begin(dbenv, NULL, tid, 0)) != 0) { dbenv-err(dbenv, ret, dbenv-txn_begin); exit (1); } /* Store the key. */ switch (ret = dbp-put(dbp, tid, key, data, 0)) { case 0: /* S
for (fail = 0;;) { /* Begin the transaction. */ if ((ret = dbenv->txn_begin(dbenv, NULL, &tid, 0)) != 0) { dbenv->err(dbenv, ret, "dbenv->txn_begin"); exit (1); } <p>/* Store the key. */ switch (ret = dbp->put(dbp, tid, &key, &data, 0)) { case 0: /* Success: commit the change. */ printf("db: %s: key stored.\n", (char *)key.data); if ((ret = tid->commit(tid, 0)) != 0) { dbenv->err(dbenv, ret, "DB_TXN->commit"); exit (1); } return (0); case DB_LOCK_DEADLOCK: default: /* Failure: retry the operation. */ if ((t_ret = tid->abort(tid)) != 0) { dbenv->err(dbenv, t_ret, "DB_TXN->abort"); exit (1); } if (fail++ == MAXIMUM_RETRY) return (ret); continue; } }</p>
<p> <wbr></wbr></p>
<p>
<wbr> <wbr> <wbr> Berkeley DB由五个主要的子系统构成.包括: 存取管理子系统、内存池管理子系统、事务子系统、锁子系统以及日志子系统。其中存取管理子系统作为Berkeley DB数据库进程包内部核心组件,而其他子系统都存在于Berkeley DB数据库进程包的外部。每个子系统支持不同的应用级别。</wbr></wbr></wbr></p>
<p>1.数据存取子系统
<wbr> <wbr>数据存取(Access Methods)子系统为创建和访问数据库文件提供了多种支持。Berkeley DB提供了以下四种文件存储方法:
哈希文件、B树、定长记录(队列)和变长记录(基于记录号的简单存储方式),应用程序可以从中选择最适合的文件组织结构。程序员创建表时可以使用任意一种结构,并且可以在同一个应用程序中对不同存储类型的文件进行混合操作。</wbr></wbr></p>
<p> <wbr> <wbr> <wbr> 在没有事务管理的情况下,该子系统中的模块可单独使用,为应用程序提供快速高效的数据存取服务。
数据存取子系统适用于不需事务只需快速格式文件访问的应用。</wbr></wbr></wbr></p>
<p> <wbr>2.内存池管理子系统
<wbr> <wbr> <wbr> 内存池(Memory pool)子系统对Berkeley DB所使用的共享缓冲区进行有效的管理。它允许同时访问数据库的多个进程或者
进程的多个线程共享一个高速缓存,负责将修改后的页写回文件和为新调入的页分配内存空间。它也可以独立于Berkeley DB系统之外,单独被应用程序使用,为其自己的文件和页分配内存空间。内存池管理子系统适用于需要灵活的、面向页的、缓冲的共享文件访问的应用。</wbr></wbr></wbr></wbr></p>
<p> <wbr>3.事务子系统
<wbr> <wbr>事务(Transaction)子系统为Berkeley DB提供事务管理功能。它允许把一组对数据库的修改看作一个原子单位,这组操作要么全做,要么全不做。在默认的情况下,系统将提供严格的ACID事务属性,但是应用程序可以选择不使用系统所作的隔离保证。该子系统使用两段锁技术和先写日志策略来保证数据库数据的正确性和一致性。它也可以被应用程序单独使用来对其自身的数据更新进行事务保护。事务子系统适用于需要事务保证数据的修改的应用。
<wbr> <wbr> <wbr>
<wbr>4.锁子系统
<wbr> <wbr> <wbr> 锁(Locking)子系统为Berkeley DB提供锁机制,为系统提供多用户读取和单用户修改同一对象的共享控制。
数据存取子系统可利用该子系统获得对页或记录的读写权限;事务子系统利用锁机制来实现多个事务的并发控制。
<wbr> <wbr> <wbr>
<wbr> <wbr> <wbr> 该子系统也可被应用程序单独采用。锁子系统适用于一个灵活的、快速的、可设置的锁管理器。
<wbr> <wbr> <wbr>
5.日志子系统 <wbr> <wbr> <wbr>
<wbr>日志(Logging)子系统采用的是先写日志的策略,用于支持事务子系统进行数据恢复,保证数据一致性。
它不大可能被应用程序单独使用,只能作为事务子系统的调用模块。</wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></p>
<p> <wbr> <wbr> <wbr>以上几部分构成了整个Berkeley DB数据库系统。各部分的关系如下图所示:</wbr></wbr></wbr></p>
<p><img src="/static/imghw/default1.png" data-src="/inc/test.jsp?url=http%3A%2F%2Fleeon.me%2Fupload%2F2010-04%2F20100403150406_56033.jpg&refer=http%3A%2F%2Fblog.csdn.net%2Fduanbeibei%2Farticle%2Fdetails%2F26456603" class="lazy" alt="Berkeley DB 由浅入深【转自架构师杨建】" >
<wbr> <wbr> <wbr>
<wbr> <wbr> <wbr> 在这个模型中,应用程序直接调用的是数据存取子系统和事务管理子系统,这两个系统进而调用更下层的内存管理子系统、
锁子系统和日志子系统。
<wbr> <wbr> <wbr>
<wbr> <wbr> <wbr> 由于几个子系统相对比较独立,所以应用程序在开始的时候可以指定哪些数据管理服务将被使用。可以全部使用,也可以只用其中的一部分。例如,如果一个应用程序需要支持多用户并发操作,但不需要进行事务管理,那它就可以只用锁子系统而不用事务。有些应用程序可能需要快速的、单用户、没有事务管理功能的B树存储结构,那么应用程序可以使锁子系统和事务子系统失效,这样就会减少开销。 <wbr> <wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></p>

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 17 façons de résoudre l'écran bleu kernel_security_check_failure
Feb 12, 2024 pm 08:51 PM
17 façons de résoudre l'écran bleu kernel_security_check_failure
Feb 12, 2024 pm 08:51 PM
Kernelsecuritycheckfailure (échec de la vérification du noyau) est un type de code d'arrêt relativement courant. Cependant, quelle qu'en soit la raison, l'erreur d'écran bleu rend de nombreux utilisateurs très angoissés. Laissez ce site présenter soigneusement 17 types de solutions aux utilisateurs. 17 solutions à l'écran bleu kernel_security_check_failure Méthode 1 : Supprimer tous les périphériques externes Lorsqu'un périphérique externe que vous utilisez est incompatible avec votre version de Windows, l'erreur d'écran bleu Kernelsecuritycheckfailure peut se produire. Pour ce faire, vous devez débrancher tous les périphériques externes avant d'essayer de redémarrer votre ordinateur.
 Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Le concept d'apprentissage profond est né de la recherche sur les réseaux de neurones artificiels. Un perceptron multicouche contenant plusieurs couches cachées est une structure d'apprentissage profond. L'apprentissage profond combine des fonctionnalités de bas niveau pour former des représentations de haut niveau plus abstraites afin de caractériser des catégories ou des caractéristiques de données. Il est capable de découvrir des représentations de fonctionnalités distribuées de données. L'apprentissage profond est un type d'apprentissage automatique, et l'apprentissage automatique est le seul moyen d'atteindre l'intelligence artificielle. Alors, quelles sont les différences entre les différentes architectures de systèmes d’apprentissage profond ? 1. Réseau entièrement connecté (FCN) Un réseau entièrement connecté (FCN) se compose d'une série de couches entièrement connectées, chaque neurone de chaque couche étant connecté à chaque neurone d'une autre couche. Son principal avantage est qu'il est « indépendant de la structure », c'est-à-dire qu'aucune hypothèse particulière concernant l'entrée n'est requise. Bien que cette agnostique structurelle rende la
 Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Il y a quelque temps, un tweet soulignant l'incohérence entre le schéma d'architecture du Transformer et le code de l'article de l'équipe Google Brain "AttentionIsAllYouNeed" a déclenché de nombreuses discussions. Certains pensent que la découverte de Sebastian était une erreur involontaire, mais elle est aussi surprenante. Après tout, compte tenu de la popularité du document Transformer, cette incohérence aurait dû être mentionnée mille fois. Sebastian Raschka a déclaré en réponse aux commentaires des internautes que le code « le plus original » était effectivement cohérent avec le schéma d'architecture, mais que la version du code soumise en 2017 a été modifiée, mais que le schéma d'architecture n'a pas été mis à jour en même temps. C’est aussi la cause profonde des discussions « incohérentes ».
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
 Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA est basé sur l'architecture JPA et interagit avec la base de données via le mappage, l'ORM et la gestion des transactions. Son référentiel fournit des opérations CRUD et les requêtes dérivées simplifient l'accès à la base de données. De plus, il utilise le chargement paresseux pour récupérer les données uniquement lorsque cela est nécessaire, améliorant ainsi les performances.
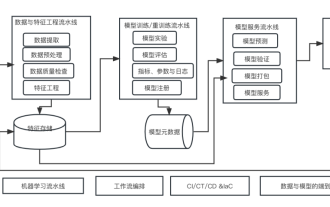 Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Nous vivons une ère d’autonomisation de l’IA, et l’apprentissage automatique est un moyen technique important pour y parvenir. Alors, existe-t-il une architecture universelle de système d’apprentissage automatique ? Dans le champ cognitif des programmeurs expérimentés, tout n'est rien, notamment pour l'architecture système. Cependant, il est possible de créer une architecture de système d'apprentissage automatique évolutive et fiable si elle est applicable à la plupart des systèmes ou cas d'utilisation basés sur l'apprentissage automatique. Du point de vue du cycle de vie du machine learning, cette architecture dite universelle couvre les étapes clés du machine learning, du développement de modèles de machine learning au déploiement de systèmes de formation et de systèmes de services dans des environnements de production. Nous pouvons essayer de décrire une telle architecture de système d’apprentissage automatique à partir des dimensions de 10 éléments. 1.
 Quelle est la courbe d'apprentissage de l'architecture du framework Golang ?
Jun 05, 2024 pm 06:59 PM
Quelle est la courbe d'apprentissage de l'architecture du framework Golang ?
Jun 05, 2024 pm 06:59 PM
La courbe d'apprentissage de l'architecture du framework Go dépend de la familiarité avec le langage Go et le développement back-end ainsi que de la complexité du framework choisi : une bonne compréhension des bases du langage Go. Il est utile d’avoir une expérience en développement back-end. Les cadres qui diffèrent en complexité entraînent des différences dans les courbes d'apprentissage.
