

Hadoop2.3.0详细安装过程

前言: Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large d
前言:
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
1,系统架构
集群角色:
2.2 用户目录创建
创建hadoop运行账户:
2.3 配置ssh免密码登陆
参考文章地址:http://blog.csdn.net/ab198604/article/details/8250461
2.3.1 每个节点分别产生密钥
# 提示:
2.3.2 在data01(192.168.52.129)上面执行:
useradd hadoop #设置hadoop用户组
2.3.3 在data01(192.168.52.130)上面执行:
useradd hadoop #设置hadoop用户组
2.3.4 构造3个通用的authorized_keys
在name01(192.168.52.128)上操作:
2.3.5 解决ssh name01失败的问题
[hadoop@data01 ~]$ ssh name01
2.3.6 验证name01、data01、data02任何ssh免密码登录
[hadoop@data02 ~]$ ssh name01
3.2,安装hadoop
下载软件包:
3.3,hadoop配置文件
hadoop群集涉及配置文件:hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-env.sh slaves yarn-site.xml
3.3,格式化文件系统
在name01主库上面执行 hadoop namenode -format操作,格式化hdfs文件系统。
3.4,hadoop管理
3.4.1 格式化完成后,开始启动hadoop 程序启动hadoop 的命令脚本都在$HADOOP_HOME/sbin/下,下面的所有命令都不再带有完整路径名称:
distribute-exclude.sh hdfs-config.sh slaves.sh start-dfs.cmd start-yarn.sh stop-dfs.cmd stop-yarn.sh
3.4.2,第一种,一次性全部启动:
执行start-all.sh 启动hadoop,观察控制台的输出,可以看到正在启动进程,分别是namenode、datanode、secondarynamenode、jobtracker、tasktracker,一共5 个,待执行完毕后,并不意味着这5 个进程成功启动,上面仅仅表示系统正在启动进程而已。我们使用jdk 的命令jps 查看进程是否已经正确启动。执行以下jps,如果看到了这5 个进程,说明hadoop 真的启动成功了。如果缺少一个或者多个,那就进入到“Hadoop的常见启动错误”章节寻找原因了。
3.4.2.1,检查后台各个节点运行的hadoop进程
[hadoop@name01 hadoop]$ jps
3.4.2.3,再去data02节点下检查
[hadoop@data02 ~]$ jps
进入http://192.168.52.128:50070/dfshealth.html#tab-overview,看集群基本信息,如下图所示:
 进入http://192.168.52.128:50070/dfshealth.html#tab-datanode,看datanode信息,如下图所示:
进入http://192.168.52.128:50070/dfshealth.html#tab-datanode,看datanode信息,如下图所示:
 进入http://192.168.52.128:50070/logs/,查看所有日志信息,如下图所示:
进入http://192.168.52.128:50070/logs/,查看所有日志信息,如下图所示:
 3.4.2.5,关闭hadoop 的命令是stop-all.sh,如下所示:
3.4.2.5,关闭hadoop 的命令是stop-all.sh,如下所示:
[hadoop@name01 src]$ /home/hadoop/src/hadoop-2.3.0/sbin/stop-all.sh
3.4.3,第二种,分别启动HDFS 和yarn:
执行命令start-dfs.sh,是单独启动hdfs。执行完该命令后,通过jps 能够看到NameNode、DataNode、SecondaryNameNode 三个进程启动了,该命令适合于只执行hdfs
3.4.3.2 再启动yarn
执行命令start-yarn.sh,可以单独启动资源管理器的服务器端和客户端进程,关闭的命令就是stop-yarn.sh
3.4.3.3 依次关闭,先关闭yarn再关闭HDFS
[hadoop@name01 sbin]$ stop-yarn.sh
3.4.4,第三种,分别启动各个进程:
[root@book0 bin]# jps
3.5,另外一种检查状态hadoop集群的状态
:用"hadoop dfsadmin -report"来查看hadoop集群的状态
参考网址:
http://blog.csdn.net/hguisu/article/details/7237395

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Solution au problème selon lequel le pack de langue chinoise ne peut pas être installé sur le système Win11
Mar 09, 2024 am 09:48 AM
Solution au problème selon lequel le pack de langue chinoise ne peut pas être installé sur le système Win11
Mar 09, 2024 am 09:48 AM
Solution au problème selon lequel le système Win11 ne peut pas installer le pack de langue chinoise Avec le lancement du système Windows 11, de nombreux utilisateurs ont commencé à mettre à niveau leur système d'exploitation pour découvrir de nouvelles fonctions et interfaces. Cependant, certains utilisateurs ont constaté qu'ils ne parvenaient pas à installer le pack de langue chinoise après la mise à niveau, ce qui perturbait leur expérience. Dans cet article, nous discuterons des raisons pour lesquelles le système Win11 ne peut pas installer le pack de langue chinoise et proposerons des solutions pour aider les utilisateurs à résoudre ce problème. Analyse des causes Tout d'abord, analysons l'incapacité du système Win11 à
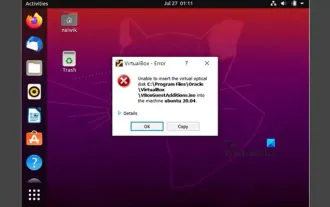 Impossible d'installer les ajouts d'invités dans VirtualBox
Mar 10, 2024 am 09:34 AM
Impossible d'installer les ajouts d'invités dans VirtualBox
Mar 10, 2024 am 09:34 AM
Vous ne pourrez peut-être pas installer des ajouts d'invités sur une machine virtuelle dans OracleVirtualBox. Lorsque nous cliquons sur Périphériques> InstallGuestAdditionsCDImage, cela renvoie simplement une erreur comme indiqué ci-dessous : VirtualBox - Erreur : Impossible d'insérer le disque virtuel C : Programmation de fichiersOracleVirtualBoxVBoxGuestAdditions.iso dans la machine Ubuntu Dans cet article, nous comprendrons ce qui se passe lorsque vous Que faire lorsque vous Je ne peux pas installer les ajouts d'invités dans VirtualBox. Impossible d'installer les ajouts d'invités dans VirtualBox Si vous ne pouvez pas l'installer dans Virtua
 Que dois-je faire si Baidu Netdisk est téléchargé avec succès mais ne peut pas être installé ?
Mar 13, 2024 pm 10:22 PM
Que dois-je faire si Baidu Netdisk est téléchargé avec succès mais ne peut pas être installé ?
Mar 13, 2024 pm 10:22 PM
Si vous avez téléchargé avec succès le fichier d'installation de Baidu Netdisk, mais que vous ne parvenez pas à l'installer normalement, il se peut qu'il y ait une erreur dans l'intégrité du fichier du logiciel ou qu'il y ait un problème avec les fichiers résiduels et les entrées de registre. prenons-en soin pour les utilisateurs. Présentons l'analyse du problème selon lequel Baidu Netdisk est téléchargé avec succès mais ne peut pas être installé. Analyse du problème du téléchargement réussi de Baidu Netdisk mais qui n'a pas pu être installé 1. Vérifiez l'intégrité du fichier d'installation : Assurez-vous que le fichier d'installation téléchargé est complet et n'est pas endommagé. Vous pouvez le télécharger à nouveau ou essayer de télécharger le fichier d'installation à partir d'une autre source fiable. 2. Désactivez le logiciel antivirus et le pare-feu : Certains logiciels antivirus ou pare-feu peuvent empêcher le bon fonctionnement du programme d'installation. Essayez de désactiver ou de quitter le logiciel antivirus et le pare-feu, puis réexécutez l'installation.
 Comment installer des applications Android sur Linux ?
Mar 19, 2024 am 11:15 AM
Comment installer des applications Android sur Linux ?
Mar 19, 2024 am 11:15 AM
L'installation d'applications Android sur Linux a toujours été une préoccupation pour de nombreux utilisateurs. Surtout pour les utilisateurs Linux qui aiment utiliser des applications Android, il est très important de maîtriser comment installer des applications Android sur les systèmes Linux. Bien qu'exécuter des applications Android directement sur Linux ne soit pas aussi simple que sur la plateforme Android, en utilisant des émulateurs ou des outils tiers, nous pouvons toujours profiter avec plaisir des applications Android sur Linux. Ce qui suit explique comment installer des applications Android sur les systèmes Linux.
 Comment installer Podman sur Ubuntu 24.04
Mar 22, 2024 am 11:26 AM
Comment installer Podman sur Ubuntu 24.04
Mar 22, 2024 am 11:26 AM
Si vous avez utilisé Docker, vous devez comprendre les démons, les conteneurs et leurs fonctions. Un démon est un service qui s'exécute en arrière-plan lorsqu'un conteneur est déjà utilisé dans n'importe quel système. Podman est un outil de gestion gratuit permettant de gérer et de créer des conteneurs sans recourir à un démon tel que Docker. Par conséquent, il présente des avantages dans la gestion des conteneurs sans nécessiter de services backend à long terme. De plus, Podman ne nécessite pas d'autorisations au niveau racine pour être utilisé. Ce guide explique en détail comment installer Podman sur Ubuntu24. Pour mettre à jour le système, nous devons d'abord mettre à jour le système et ouvrir le shell du terminal d'Ubuntu24. Pendant les processus d’installation et de mise à niveau, nous devons utiliser la ligne de commande. un simple
 Mar 22, 2024 pm 04:40 PM
Mar 22, 2024 pm 04:40 PM
Durant leurs études au lycée, certains élèves prennent des notes très claires et précises, prenant plus de notes que d’autres dans la même classe. Pour certains, prendre des notes est un passe-temps, tandis que pour d’autres, c’est une nécessité lorsqu’ils oublient facilement de petites informations sur quelque chose d’important. L'application NTFS de Microsoft est particulièrement utile pour les étudiants qui souhaitent sauvegarder des notes importantes au-delà des cours réguliers. Dans cet article, nous décrirons l'installation des applications Ubuntu sur Ubuntu24. Mise à jour du système Ubuntu Avant d'installer le programme d'installation d'Ubuntu, sur Ubuntu24, nous devons nous assurer que le système nouvellement configuré a été mis à jour. Nous pouvons utiliser le "a" le plus célèbre du système Ubuntu
 Étapes détaillées pour installer le langage Go sur un ordinateur Win7
Mar 27, 2024 pm 02:00 PM
Étapes détaillées pour installer le langage Go sur un ordinateur Win7
Mar 27, 2024 pm 02:00 PM
Étapes détaillées pour installer le langage Go sur un ordinateur Win7 Go (également connu sous le nom de Golang) est un langage de programmation open source développé par Google. Il est simple, efficace et offre d'excellentes performances de concurrence. Il convient au développement de services cloud, d'applications réseau et. systèmes back-end. Installer le langage Go sur un ordinateur Win7 permet de prendre rapidement en main le langage et de commencer à écrire des programmes Go. Ce qui suit présentera en détail les étapes pour installer le langage Go sur un ordinateur Win7 et joindra des exemples de code spécifiques. Étape 1 : Téléchargez le package d'installation du langage Go et visitez le site officiel de Go
 Comment installer le langage Go sous le système Win7 ?
Mar 27, 2024 pm 01:42 PM
Comment installer le langage Go sous le système Win7 ?
Mar 27, 2024 pm 01:42 PM
L'installation du langage Go sous le système Win7 est une opération relativement simple. Suivez simplement les étapes suivantes pour réussir son installation. Ce qui suit présentera en détail comment installer le langage Go sous le système Win7. Étape 1 : Téléchargez le package d'installation du langage Go. Tout d'abord, ouvrez le site Web officiel du langage Go (https://golang.org/) et accédez à la page de téléchargement. Sur la page de téléchargement, sélectionnez la version du package d'installation compatible avec le système Win7 à télécharger. Cliquez sur le bouton Télécharger et attendez que le package d'installation soit téléchargé. Étape 2 : Installer la langue Go
