
 interface Web
js tutoriel
Une brève discussion sur les jeux de caractères JavaScript_Connaissances de base
interface Web
js tutoriel
Une brève discussion sur les jeux de caractères JavaScript_Connaissances de base
Une brève discussion sur les jeux de caractères JavaScript_Connaissances de base

JavaScript est sensible à la casse :
Les mots clés, les variables, les noms de fonctions et tous les identifiants doivent être en majuscules et minuscules cohérentes (généralement nous les écrivons en minuscules), ce qui est très différent de la méthode d'écriture multi-style lorsque j'ai appris le C# pour la première fois.
Par exemple : (Ici, nous prenons les variables str et Str comme exemples)
var str='abc';
var Str ='ABC';
alert(str);//Sortie abc
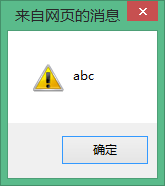
Si str et Str sont la même variable, alors alert(str);, le résultat de sortie doit être ABC au lieu de abc comme indiqué ci-dessus. Cela montre simplement : JavaScript est sensible à la casse.
Séquence d'échappement Unicode
L'émergence du jeu de caractères Unicode vise à compenser la limitation selon laquelle les codes ASCII ne peuvent représenter que 128 caractères. Si l'on veut afficher les caractères chinois et japonais dans la vie quotidienne, l'ASCII est évidemment impossible. Unicode est donc un surensemble d'ASCII et de Latin-1. Tout d'abord, les programmes JavaScript sont écrits à l'aide du jeu de caractères Unicode. Cependant, sur certains matériels informatiques et logiciels, il est impossible d'afficher ou de saisir le jeu complet de caractères Unicode (tels que : é). JavaScript définit une séquence spéciale, cette séquence utilise 6 caractères ASCII pour représenter tout code interne Unicode de 16 bits. Cette séquence spéciale est collectivement appelée séquence d'échappement Unicode. Elle est préfixée par u, suivi de 4 chiffres hexadécimaux
.Par exemple :
var str='cafu00e9';
var Str ='café';
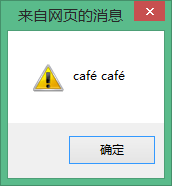
alert(Str ' ' str);// On voit que l'affichage a le même effet.
alerte (Str===str);//output true
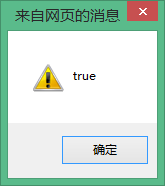
Mais il faut noter qu'Unicode permet à plusieurs méthodes d'encoder le même caractère, comme illustré par l'exemple d'échappement é ci-dessus :
é:
1. Le caractère Unicode u00E9 peut être utilisé pour représenter
2. Vous pouvez également utiliser eu0301 (caractère d'intonation) pour représenter
var str='cafu00e9';
var Str ='cafeu0301';
alert(str ' ' Str); //Comme le montre la figure ci-dessous, les résultats de sortie de Str et str sont les mêmes
alert(Str===str); //Le résultat est le même, mais leurs représentations de codage binaire sont fondamentalement différentes, donc le résultat est faux
Bien que les résultats affichés sur l'éditeur de texte soient les mêmes, leurs représentations de codage binaire sont fondamentalement différentes. Le langage de programmation sera finalement converti en code mécanique informatique (codage binaire) de la plateforme locale, et l'ordinateur ne pourra que traiter. le binaire Le résultat ne peut être connu qu'en comparant les codes, donc le résultat final de leur comparaison ne peut être que faux
C'est donc la meilleure explication de "Unicode permet à plusieurs méthodes de coder le même caractère", car la norme Unicode définit un format de codage préféré pour tous les caractères afin de convertir le texte en une séquence Unicode uniforme pour une comparaison appropriée
En utilisant à nouveau é comme exemple :Le é in face et le café sont-ils pareils ?
Le é en face et le café sont tous deux convertis en u00E9 ou les deux sont convertis en eu0301, afin que le é en face et le café puissent être comparés

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment mettre en œuvre un système de reconnaissance vocale en ligne à l'aide de WebSocket et JavaScript
Dec 17, 2023 pm 02:54 PM
Comment mettre en œuvre un système de reconnaissance vocale en ligne à l'aide de WebSocket et JavaScript
Dec 17, 2023 pm 02:54 PM
Comment utiliser WebSocket et JavaScript pour mettre en œuvre un système de reconnaissance vocale en ligne Introduction : Avec le développement continu de la technologie, la technologie de reconnaissance vocale est devenue une partie importante du domaine de l'intelligence artificielle. Le système de reconnaissance vocale en ligne basé sur WebSocket et JavaScript présente les caractéristiques d'une faible latence, d'un temps réel et d'une multiplateforme, et est devenu une solution largement utilisée. Cet article explique comment utiliser WebSocket et JavaScript pour implémenter un système de reconnaissance vocale en ligne.
 WebSocket et JavaScript : technologies clés pour mettre en œuvre des systèmes de surveillance en temps réel
Dec 17, 2023 pm 05:30 PM
WebSocket et JavaScript : technologies clés pour mettre en œuvre des systèmes de surveillance en temps réel
Dec 17, 2023 pm 05:30 PM
WebSocket et JavaScript : technologies clés pour réaliser des systèmes de surveillance en temps réel Introduction : Avec le développement rapide de la technologie Internet, les systèmes de surveillance en temps réel ont été largement utilisés dans divers domaines. L'une des technologies clés pour réaliser une surveillance en temps réel est la combinaison de WebSocket et de JavaScript. Cet article présentera l'application de WebSocket et JavaScript dans les systèmes de surveillance en temps réel, donnera des exemples de code et expliquera leurs principes de mise en œuvre en détail. 1. Technologie WebSocket
 Comment utiliser JavaScript et WebSocket pour mettre en œuvre un système de commande en ligne en temps réel
Dec 17, 2023 pm 12:09 PM
Comment utiliser JavaScript et WebSocket pour mettre en œuvre un système de commande en ligne en temps réel
Dec 17, 2023 pm 12:09 PM
Introduction à l'utilisation de JavaScript et de WebSocket pour mettre en œuvre un système de commande en ligne en temps réel : avec la popularité d'Internet et les progrès de la technologie, de plus en plus de restaurants ont commencé à proposer des services de commande en ligne. Afin de mettre en œuvre un système de commande en ligne en temps réel, nous pouvons utiliser les technologies JavaScript et WebSocket. WebSocket est un protocole de communication full-duplex basé sur le protocole TCP, qui peut réaliser une communication bidirectionnelle en temps réel entre le client et le serveur. Dans le système de commande en ligne en temps réel, lorsque l'utilisateur sélectionne des plats et passe une commande
 Comment mettre en œuvre un système de réservation en ligne à l'aide de WebSocket et JavaScript
Dec 17, 2023 am 09:39 AM
Comment mettre en œuvre un système de réservation en ligne à l'aide de WebSocket et JavaScript
Dec 17, 2023 am 09:39 AM
Comment utiliser WebSocket et JavaScript pour mettre en œuvre un système de réservation en ligne. À l'ère numérique d'aujourd'hui, de plus en plus d'entreprises et de services doivent fournir des fonctions de réservation en ligne. Il est crucial de mettre en place un système de réservation en ligne efficace et en temps réel. Cet article explique comment utiliser WebSocket et JavaScript pour implémenter un système de réservation en ligne et fournit des exemples de code spécifiques. 1. Qu'est-ce que WebSocket ? WebSocket est une méthode full-duplex sur une seule connexion TCP.
 JavaScript et WebSocket : créer un système efficace de prévisions météorologiques en temps réel
Dec 17, 2023 pm 05:13 PM
JavaScript et WebSocket : créer un système efficace de prévisions météorologiques en temps réel
Dec 17, 2023 pm 05:13 PM
JavaScript et WebSocket : Construire un système efficace de prévisions météorologiques en temps réel Introduction : Aujourd'hui, la précision des prévisions météorologiques revêt une grande importance pour la vie quotidienne et la prise de décision. À mesure que la technologie évolue, nous pouvons fournir des prévisions météorologiques plus précises et plus fiables en obtenant des données météorologiques en temps réel. Dans cet article, nous apprendrons comment utiliser la technologie JavaScript et WebSocket pour créer un système efficace de prévisions météorologiques en temps réel. Cet article démontrera le processus de mise en œuvre à travers des exemples de code spécifiques. Nous
 Tutoriel JavaScript simple : Comment obtenir le code d'état HTTP
Jan 05, 2024 pm 06:08 PM
Tutoriel JavaScript simple : Comment obtenir le code d'état HTTP
Jan 05, 2024 pm 06:08 PM
Tutoriel JavaScript : Comment obtenir le code d'état HTTP, des exemples de code spécifiques sont requis Préface : Dans le développement Web, l'interaction des données avec le serveur est souvent impliquée. Lors de la communication avec le serveur, nous devons souvent obtenir le code d'état HTTP renvoyé pour déterminer si l'opération a réussi et effectuer le traitement correspondant en fonction de différents codes d'état. Cet article vous apprendra comment utiliser JavaScript pour obtenir des codes d'état HTTP et fournira quelques exemples de codes pratiques. Utilisation de XMLHttpRequest
 Comment utiliser insertBefore en javascript
Nov 24, 2023 am 11:56 AM
Comment utiliser insertBefore en javascript
Nov 24, 2023 am 11:56 AM
Utilisation : En JavaScript, la méthode insertBefore() est utilisée pour insérer un nouveau nœud dans l'arborescence DOM. Cette méthode nécessite deux paramètres : le nouveau nœud à insérer et le nœud de référence (c'est-à-dire le nœud où le nouveau nœud sera inséré).
 Explication détaillée de la façon de modifier le jeu de caractères de la base de données Oracle
Mar 02, 2024 pm 03:18 PM
Explication détaillée de la façon de modifier le jeu de caractères de la base de données Oracle
Mar 02, 2024 pm 03:18 PM
Explication détaillée de la façon de modifier le jeu de caractères de la base de données Oracle. La base de données Oracle est un puissant système de gestion de base de données relationnelle qui prend en charge plusieurs jeux de caractères, notamment le jeu de caractères chinois simplifié, le jeu de caractères chinois traditionnel, le jeu de caractères anglais, etc. Dans les applications pratiques, vous pouvez rencontrer des situations dans lesquelles vous devez modifier le jeu de caractères de la base de données. Cet article présentera en détail la méthode de modification du jeu de caractères de la base de données Oracle et fournira des exemples de code spécifiques pour référence aux lecteurs. 1. Vérifiez le jeu de caractères actuel de la base de données. Avant de modifier le jeu de caractères de la base de données, vous devez d'abord vérifier le jeu de caractères actuel de la base de données.
