

BigData-09-Greenplum概述及架构

0.写在前面: 0.1. 此笔记是参考《Greenplum企业应用实战》、《PostgreSQL8.2.3 中文文档》和《Getting Started with Greenplum for Big Data Analytics》整理; 0.2. 《Greenplum企业应用实战》购买地址:【京东商城】 【 当当网】 0.3.参考网页(持续更新)
0.写在前面:
0.1. 此笔记是参考《Greenplum企业应用实战》、《PostgreSQL8.2.3 中文文档》和《Getting Started with Greenplum for Big Data Analytics》整理;
0.2. 《Greenplum企业应用实战》购买地址:【京东商城】 【 当当网】
0.3.参考网页(持续更新)
1) Shared Disk VS Shared Nothing分布式架构1. Greenplum概述及架构
1.1. 什么是Greenplum
1) 为全球大型企业用户提供新型企业级数据仓库(EDW)、企业级数据云(EDC)和商务智能(BI)提供解决方案和咨询服务,专注于OLAP系统数据引擎开发;
2) 海量并行处理(Massively Parallel Processing) DBMS:
Greenplum的架构采用了MPP(大规模并行处理),在 MPP 系统中,每个 SMP节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution) 。
SMP(SymmetricMulti-Processing),对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。在这种技术的支持下,一个服务器系统可以同时运行多个处理器,并共享内存和其他的主机资源。传统的ORACLE和DB2均是此种类型,ORACLE RAC 是半共享状态;
与传统的SMP架构明显不同,通常情况下,MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点,但是这也不是绝对的,因为 MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。这就是看通信时间占用计算时间的比例而定,如果通信时间比较多,那MPP系统就不占优势了,相反,如果通信时间比较少,那MPP系统可以充分发挥资源的优势,达到高效率。
3) 基于PostgreSQL 8.2开源版本,具有相同的客户端功能,增加支持并行处理的技术,增加支持数据仓库和BI的特性;
4) 外部表(external tables)/并行加载(parallel loading):外部表是指数据库可以直接使用操作系统中的数据文件,在Greenplum 4.2版本中支持对外部表的读写操作;
5) 资源管理:基于PostgreSQL增加了并行度的处理;
6) 查询优化器增强(query optimizer enhancements):增加对分布式的支持,空间的回收和分析,不需要进行多方面的调优。
1.2. Greenplum 体系架构

图一
Greenplum是一种基于ProstgreSQL的分布式数据库,其采用Shared-Nothing架构、主机、操作系统、内存、存储都是自我控制的,不存在共享。
补充:SharedDisk与Shared Nothing介绍

图二

图三
|
比较事项 |
概述 |
优点 |
缺点 |
使用场景 |
|
Shared Disk |
如图二所示,所有节点共享一份数据 |
只要有一个节点就可以访问所有数据 |
内存融合限制水平扩展能力 |
Oracle RAC,24*7的高可用性核心业务 |
|
Shared Nothing |
如图三所示,数据和节点有一一对应关系 |
每个节点交互少,很容易扩展 |
如果需要访问所有数据,需要所有节点都可用 |
SQL Server、DB2、Hadoop以及Greenplum |
1.2.1.Master Host
1) 建立与客户端的会话连接和管理;
2) SQL的解析并形成分布式的执行计划;
3) 将生成好的执行计划分发到每个Segment上执行;
4) 收集Segment的执行结果;
5) 不存储业务数据,只存储数据字典;
6) 可以一主一备,分布在两台机器上,为了提高性能,最好单独占用一台机器。
1.2.2.Segment Host
1) 业务数据的存储和存取;
2) 执行由Master分发的SQL语句;
3) 对于Master来说,每个Segment都是对等的,负责对应数据的存储和计算;
4) 每一台机器上可以配置一到多个Segment,因此建议采用相同的机器配置。
1.2.3.Interconnect
1) 是GP数据库的网络层,在每个Segment中起到一个IPC作用;
2) 推荐使用千兆以太网交换机做Interconnect;
3) 支持UDP和TCP两种协议,推荐使用UDP协议,因为其高可靠性、高性能以及可扩展性;而TCP协议最高只能使用1000个Segment实例。
1.3.网络配置示例

图四
图四显示一个常见的网络配置示例,其中X4200是主节点,X4500(Segment host1)是主从节点,当主节点宕机后会主节点服务切换到此节点上,X4500(Segment host2)是从节点。
每个网络接口对应不同的网口,隔离到独立网络,保证不会竞争其他端口的网络带宽,提高网络的可靠性;串口连接到交换机是管理员管理的窗口。
1.4.Greenplum 高可用性体系架构

图五
图五中显示高可用性体系的示例图,其中按照从左到右且从上到下依次是主从节点,主节点,客户端,私有局域网以及从节点集群,实现功能和图一基本一致。
1.5.Master/Standby 镜像保护

图六
图六说明:Standby 节点用于当 Master 节点损坏时提供 Master服务,Standby 实时与Master 节点的Catalog 和事务日志保持同步,确保系统的变更信息不会丢失,提升系统的健壮性。
1.6.数据冗余-Segment 镜像保护

图七
图七说明:
1) 当GP配置了镜像节点之后,主节点不可用时会自动切换到镜像节点,集群仍然保持可用状态。当主节点恢复并启动之后,主节点会自动恢复期间的变更;
2) 只要Master不能连接上Segment实例时,就会在系统表中将此实例标识为不可用,并用镜像节点来代替,一般需要和主节点位于不同的服务器上,当Primary Segment失败时,Mirror Segment将自动提供服务,Primary Segment恢复正常后,使用gprecoverseg –F 同步数据
1.7.Segment 主机硬件配置示例

图八
1.8.网络冗余

图九
图九说明:
1) 数据之间存在冗余,网络也存在冗余;
2) 公共网络连接到主节点,主节点通过一台或者多台交换机连接到子节点。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Le concept d'apprentissage profond est né de la recherche sur les réseaux de neurones artificiels. Un perceptron multicouche contenant plusieurs couches cachées est une structure d'apprentissage profond. L'apprentissage profond combine des fonctionnalités de bas niveau pour former des représentations de haut niveau plus abstraites afin de caractériser des catégories ou des caractéristiques de données. Il est capable de découvrir des représentations de fonctionnalités distribuées de données. L'apprentissage profond est un type d'apprentissage automatique, et l'apprentissage automatique est le seul moyen d'atteindre l'intelligence artificielle. Alors, quelles sont les différences entre les différentes architectures de systèmes d’apprentissage profond ? 1. Réseau entièrement connecté (FCN) Un réseau entièrement connecté (FCN) se compose d'une série de couches entièrement connectées, chaque neurone de chaque couche étant connecté à chaque neurone d'une autre couche. Son principal avantage est qu'il est « indépendant de la structure », c'est-à-dire qu'aucune hypothèse particulière concernant l'entrée n'est requise. Bien que cette agnostique structurelle rende la
 Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Il y a quelque temps, un tweet soulignant l'incohérence entre le schéma d'architecture du Transformer et le code de l'article de l'équipe Google Brain "AttentionIsAllYouNeed" a déclenché de nombreuses discussions. Certains pensent que la découverte de Sebastian était une erreur involontaire, mais elle est aussi surprenante. Après tout, compte tenu de la popularité du document Transformer, cette incohérence aurait dû être mentionnée mille fois. Sebastian Raschka a déclaré en réponse aux commentaires des internautes que le code « le plus original » était effectivement cohérent avec le schéma d'architecture, mais que la version du code soumise en 2017 a été modifiée, mais que le schéma d'architecture n'a pas été mis à jour en même temps. C’est aussi la cause profonde des discussions « incohérentes ».
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA est basé sur l'architecture JPA et interagit avec la base de données via le mappage, l'ORM et la gestion des transactions. Son référentiel fournit des opérations CRUD et les requêtes dérivées simplifient l'accès à la base de données. De plus, il utilise le chargement paresseux pour récupérer les données uniquement lorsque cela est nécessaire, améliorant ainsi les performances.
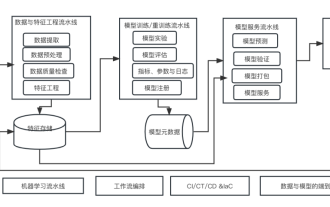 Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Nous vivons une ère d’autonomisation de l’IA, et l’apprentissage automatique est un moyen technique important pour y parvenir. Alors, existe-t-il une architecture universelle de système d’apprentissage automatique ? Dans le champ cognitif des programmeurs expérimentés, tout n'est rien, notamment pour l'architecture système. Cependant, il est possible de créer une architecture de système d'apprentissage automatique évolutive et fiable si elle est applicable à la plupart des systèmes ou cas d'utilisation basés sur l'apprentissage automatique. Du point de vue du cycle de vie du machine learning, cette architecture dite universelle couvre les étapes clés du machine learning, du développement de modèles de machine learning au déploiement de systèmes de formation et de systèmes de services dans des environnements de production. Nous pouvons essayer de décrire une telle architecture de système d’apprentissage automatique à partir des dimensions de 10 éléments. 1.
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
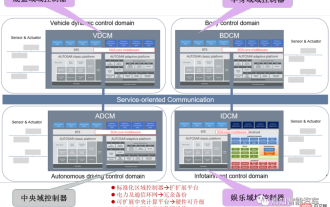 Conception d'architecture logicielle et méthodologie de découplage logiciel et matériel dans SOA
Apr 08, 2023 pm 11:21 PM
Conception d'architecture logicielle et méthodologie de découplage logiciel et matériel dans SOA
Apr 08, 2023 pm 11:21 PM
Pour la prochaine génération d'architecture électronique et électrique centralisée, l'utilisation d'une unité centrale de calcul centrale + zonale et d'une disposition de contrôleur régional est devenue une option incontournable pour divers OEM ou acteurs de niveau 1. Concernant l'architecture de l'unité centrale de calcul, il y en a trois. façons : séparation SOC, isolation matérielle, virtualisation logicielle. L'unité informatique centrale centralisée intégrera les fonctions commerciales de base des trois principaux domaines de la conduite autonome, du cockpit intelligent et du contrôle des véhicules. Le contrôleur régional standardisé a trois responsabilités principales : la distribution d'énergie, les services de données et la passerelle régionale. L’unité centrale de calcul intégrera donc un commutateur Ethernet haut débit. À mesure que le degré d'intégration de l'ensemble du véhicule devient de plus en plus élevé, de plus en plus de fonctions ECU seront lentement absorbées par le contrôleur régional. Et la plateforme
 Quelle est la courbe d'apprentissage de l'architecture du framework Golang ?
Jun 05, 2024 pm 06:59 PM
Quelle est la courbe d'apprentissage de l'architecture du framework Golang ?
Jun 05, 2024 pm 06:59 PM
La courbe d'apprentissage de l'architecture du framework Go dépend de la familiarité avec le langage Go et le développement back-end ainsi que de la complexité du framework choisi : une bonne compréhension des bases du langage Go. Il est utile d’avoir une expérience en développement back-end. Les cadres qui diffèrent en complexité entraînent des différences dans les courbes d'apprentissage.
