

Apache Thrift入门2-Java代码实现例子

在上一篇文章中提到了Thrift的架构、传输协议(Ref),本篇文章将对Thrift的入门实例进行介绍。 分为如下5个部分: 运行环境、安装/配置、脚本文件、创建代码、运行程序。 一、开发环境(清单1) 1.操作系统 Server-Linux / Client-WinXP 2.SDK Sun JDK1.5+ 3.需
在上一篇文章中提到了Thrift的架构、传输协议(Ref),本篇文章将对Thrift的入门实例进行介绍。 分为如下5个部分: 运行环境、安装/配置、脚本文件、创建代码、运行程序。
一、开发环境(清单1)
1.操作系统
Server-Linux / Client-WinXP
2.SDK
Sun JDK1.5+
3.需要的jar依赖包
libthrift.jar
slf4j-api-1.5.8.jar
slf4j-log4j12-1.5.8.jar
log4j-1.2.15.jar
4.编译工具
Apache Ant & Apache ivy
二、安装/配置 (清单2)
1.下载thrift源文件
http://labs.renren.com/apache-mirror//incubator/thrift/0.5.0-incubating/thrift-0.5.0.tar.gz
2.编译thrift源文件
1)解压 thrift-0.5.0.tar.gz
2)用ant编译源代码,进入x:\thrift-0.5.0\lib\java目录,执行ant,通过ant中的ivy工具会自动从站点下载所需要的依赖包,编译完成后如图所示:

3)编译过程中下载的依赖包在x:\thrift-0.5.0\lib\java\build\ivy\lib 目录下可以看见下载的jar依赖包,将编译成功以后的jar包加入Eclipse的开发环境中。
三、脚本文件(清单3)
1.创建脚本
创建脚本文件 testJava.thrift ,脚本文件内容如下:
namespace java com.javabloger.gen.code # 注释1 定义生成代码的命名空间,与你需要定义的package相对应。
struct Blog { # 注释2.1 定义实体名称和数据结构,类似你业务逻辑中的pojo get/set
1: string topic # 注释2.2 参数类型可以参见 Thrift wiki
2: binary content
3: i64 createdTime
4: string id
5: string ipAddress
6: map
}
service ThriftCase { # 注释3 代码生成的类名,你的业务逻辑代码需要实现代码生成的ThriftCase.Iface接口
i32 testCase1(1:i32 num1, 2:i32 num2, 3:string num3) #注释4.1 方法名称和方法中的入参,入参类型参见wiki
list
void testCase3()
void testCase4(1:list
}
2.运行脚本
1)从 thrift 站点下载windows版本的编译工具,下载地址:http://labs.renren.com/apache-mirror//incubator/thrift/0.5.0-incubating/thrift-0.5.0.exe
2)通过Thrift的脚本文件,运行 thrift 命令创建生成的代码,例如:执行 thrift -gen java x:\testJava.thrift 命令,在当前运行的盘符下,可看见gen-java目录,在这里目录中可以看见生成的java代码,更多thrift 命令内容,请参见thrift命令自带的help。
3.Thrift 中的基本数据类型 (清单4)
类型 描述
bool true, false
byte 8位的有符号整数
i16 16位的有符号整数
i32 32位的有符号整数
i64 64位的有符号整数
double 64位的浮点数
string UTF-8编码的字符串
binary 字符数组
struct 结构体
list 有序的元素列表,类似于STL的vector
set 无序的不重复元素集,类似于STL的set
map key-value型的映射,类似于STL的map
exception 是一个继承于本地语言的exception基类
service 服务。包含多个函数接口(纯虚函数)
四、创建代码(清单5)
我将示例工程分了4个包,如下所示:
\com\javabloger
\client # 1.客户端测试代码
\gen\code # 2.通过脚本生成的class
\layer\transport # 3.服务器端代码和定义的传输协议
\layer\business # 4.具体的业务逻辑代码
具体代码内容这里就不阐述了,重点是要明白代码的结构和层次关系,其次是里面主要的几个类的含义,至于代码是怎么写的并不是非常重要,仅仅是我个人观点,仅供参考,谢谢。
代码示例的下载地址: http://javabloger-mini-books.googlecode.com/files/Thritf.zip
五、运行程序
先运行server,再运行client ,客户端向服务器端发送数据调用服务器端的4个方法,服务器端被传入客户端数据,运行效果如图所示:

相关文章:
Apache Thrift入门1-架构&介绍
–end–
原文地址:Apache Thrift入门2-Java代码实现例子, 感谢原作者分享。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Kimi : En une seule phrase, un PPT est prêt en seulement dix secondes. PPT est tellement ennuyeux ! Pour tenir une réunion, vous devez avoir un PPT ; pour rédiger un rapport hebdomadaire, vous devez avoir un PPT ; pour solliciter des investissements, vous devez présenter un PPT ; même pour accuser quelqu'un de tricherie, vous devez envoyer un PPT ; L'université ressemble plus à une spécialisation PPT. Vous regardez le PPT en classe et faites le PPT après les cours. Peut-être que lorsque Dennis Austin a inventé le PPT il y a 37 ans, il ne s'attendait pas à ce qu'un jour le PPT devienne aussi répandu. Parler de notre dure expérience de création de PPT nous fait monter les larmes aux yeux. "Il m'a fallu trois mois pour réaliser un PPT de plus de 20 pages, et je l'ai révisé des dizaines de fois. J'avais envie de vomir quand j'ai vu le PPT." "À mon apogée, je faisais cinq PPT par jour, et même ma respiration." était PPT." Si vous avez une réunion impromptue, vous devriez le faire
 Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tôt le matin du 20 juin, heure de Pékin, CVPR2024, la plus grande conférence internationale sur la vision par ordinateur qui s'est tenue à Seattle, a officiellement annoncé le meilleur article et d'autres récompenses. Cette année, un total de 10 articles ont remporté des prix, dont 2 meilleurs articles et 2 meilleurs articles étudiants. De plus, il y a eu 2 nominations pour les meilleurs articles et 4 nominations pour les meilleurs articles étudiants. La conférence la plus importante dans le domaine de la vision par ordinateur (CV) est la CVPR, qui attire chaque année un grand nombre d'instituts de recherche et d'universités. Selon les statistiques, un total de 11 532 articles ont été soumis cette année, dont 2 719 ont été acceptés, avec un taux d'acceptation de 23,6 %. Selon l'analyse statistique des données CVPR2024 du Georgia Institute of Technology, du point de vue des sujets de recherche, le plus grand nombre d'articles est la synthèse et la génération d'images et de vidéos (Imageandvideosyn
 Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Nous savons que le LLM est formé sur des clusters informatiques à grande échelle utilisant des données massives. Ce site a présenté de nombreuses méthodes et technologies utilisées pour aider et améliorer le processus de formation LLM. Aujourd'hui, ce que nous souhaitons partager est un article qui approfondit la technologie sous-jacente et présente comment transformer un ensemble de « bare metals » sans même un système d'exploitation en un cluster informatique pour la formation LLM. Cet article provient d'Imbue, une startup d'IA qui s'efforce d'atteindre une intelligence générale en comprenant comment les machines pensent. Bien sûr, transformer un tas de « bare metal » sans système d'exploitation en un cluster informatique pour la formation LLM n'est pas un processus facile, plein d'exploration et d'essais et d'erreurs, mais Imbue a finalement réussi à former un LLM avec 70 milliards de paramètres et dans. le processus s'accumule
 L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
Rédacteur du Machine Power Report : Yang Wen La vague d’intelligence artificielle représentée par les grands modèles et l’AIGC a discrètement changé notre façon de vivre et de travailler, mais la plupart des gens ne savent toujours pas comment l’utiliser. C'est pourquoi nous avons lancé la rubrique « AI in Use » pour présenter en détail comment utiliser l'IA à travers des cas d'utilisation de l'intelligence artificielle intuitifs, intéressants et concis et stimuler la réflexion de chacun. Nous invitons également les lecteurs à soumettre des cas d'utilisation innovants et pratiques. Lien vidéo : https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Récemment, le vlog de la vie d'une fille vivant seule est devenu populaire sur Xiaohongshu. Une animation de style illustration, associée à quelques mots de guérison, peut être facilement récupérée en quelques jours seulement.
 Compte à rebours des 12 points faibles de RAG, l'architecte senior de NVIDIA enseigne les solutions
Jul 11, 2024 pm 01:53 PM
Compte à rebours des 12 points faibles de RAG, l'architecte senior de NVIDIA enseigne les solutions
Jul 11, 2024 pm 01:53 PM
La génération augmentée par récupération (RAG) est une technique qui utilise la récupération pour améliorer les modèles de langage. Plus précisément, avant qu'un modèle de langage ne génère une réponse, il récupère les informations pertinentes à partir d'une vaste base de données de documents, puis utilise ces informations pour guider le processus de génération. Cette technologie peut considérablement améliorer l'exactitude et la pertinence du contenu, atténuer efficacement le problème des hallucinations, augmenter la vitesse de mise à jour des connaissances et améliorer la traçabilité de la génération de contenu. RAG est sans aucun doute l’un des domaines de recherche les plus passionnants en matière d’intelligence artificielle. Pour plus de détails sur RAG, veuillez vous référer à l'article de la rubrique de ce site "Quelles sont les nouveautés de RAG, spécialisée dans le rattrapage des défauts des grands modèles ?" Cette revue l'explique clairement. Mais RAG n'est pas parfait et les utilisateurs rencontrent souvent des « problèmes » lorsqu'ils l'utilisent. Récemment, la solution avancée d'IA générative de NVIDIA
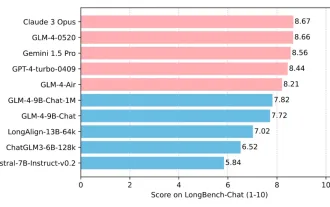 L'Université Tsinghua et Zhipu AI open source GLM-4 : lancent une nouvelle révolution dans le traitement du langage naturel
Jun 12, 2024 pm 08:38 PM
L'Université Tsinghua et Zhipu AI open source GLM-4 : lancent une nouvelle révolution dans le traitement du langage naturel
Jun 12, 2024 pm 08:38 PM
Depuis le lancement du ChatGLM-6B le 14 mars 2023, les modèles de la série GLM ont reçu une large attention et une grande reconnaissance. Surtout après que ChatGLM3-6B soit open source, les développeurs sont pleins d'attentes pour le modèle de quatrième génération lancé par Zhipu AI. Cette attente a finalement été pleinement satisfaite avec la sortie du GLM-4-9B. La naissance du GLM-4-9B Afin de donner aux petits modèles (10B et moins) des capacités plus puissantes, l'équipe technique de GLM a lancé ce nouveau modèle open source de la série GLM de quatrième génération : GLM-4-9B après près de six mois de exploration. Ce modèle compresse considérablement la taille du modèle tout en garantissant la précision, et offre une vitesse d'inférence plus rapide et une efficacité plus élevée. L’exploration de l’équipe technique du GLM n’a pas
 Comment effectuer des tests de concurrence et le débogage dans la programmation simultanée Java ?
May 09, 2024 am 09:33 AM
Comment effectuer des tests de concurrence et le débogage dans la programmation simultanée Java ?
May 09, 2024 am 09:33 AM
Tests de concurrence et débogage Les tests de concurrence et le débogage dans la programmation simultanée Java sont cruciaux et les techniques suivantes sont disponibles : Tests de concurrence : tests unitaires : isolez et testez une seule tâche simultanée. Tests d'intégration : tester l'interaction entre plusieurs tâches simultanées. Tests de charge : évaluez les performances et l'évolutivité d'une application sous une charge importante. Débogage simultané : points d'arrêt : suspendez l'exécution du thread et inspectez les variables ou exécutez le code. Journalisation : enregistrez les événements et l'état du fil. Trace de pile : identifiez la source de l’exception. Outils de visualisation : surveillez l'activité des threads et l'utilisation des ressources.
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
