

添加lzo for hive table

hive?hiveconf hive.exec.compress.output=true hiveconf mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec 之后为其每个lzo块添加index: hadoop jar /usr/local/hadoop/lib/hadoop-lzo-0.4.15.jar com.hadoop.compression.lzo.Distr
hive?–hiveconf hive.exec.compress.output=true –hiveconf mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec
之后为其每个lzo块添加index:
hadoop jar /usr/local/hadoop/lib/hadoop-lzo-0.4.15.jar com.hadoop.compression.lzo.DistributedLzoIndexer ?path/xxx.lzo ? ?注意(没有-jobconf mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec选项只设置-jobconf mapred.output.compress=true 选项的话 reduce作业输出文件的格式为.lzo_deflate )
之所以要为其添加index的原理:
这样会按照block大小来切分块。(速度变快,但是多消耗cpu时间。map数目大量增加)
如果不对文件建立lzo索引则不会按照block来切分块
使用LZO过程会发现它有两种压缩编码可以使用,即LzoCodec和LzopCodec,下面说说它们区别:
- LzoCodec比LzopCodec更快, LzopCodec为了兼容LZOP程序添加了如?
bytes signature, header等信息 - 如果使用?
LzoCodec作为Reduce输出,则输出文件扩展名为”.lzo_deflate”,它无法被lzop读取;如果使用LzopCodec作为Reduce输出,则扩展名为”.lzo”,它可以被lzop读取 - 生成lzo index job的”DistributedLzoIndexer“无法为 LzoCodec,即 “.lzo_deflate”扩展名的文件创建index
- ”.lzo_deflate“文件无法作为MapReduce输入,”.LZO”文件则可以。
- 综上所述得出最佳实践:map输出的中间数据使用 LzoCodec,reduce输出使用 LzopCodec
原文地址:添加lzo for hive table, 感谢原作者分享。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 17 façons de résoudre l'écran bleu kernel_security_check_failure
Feb 12, 2024 pm 08:51 PM
17 façons de résoudre l'écran bleu kernel_security_check_failure
Feb 12, 2024 pm 08:51 PM
Kernelsecuritycheckfailure (échec de la vérification du noyau) est un type de code d'arrêt relativement courant. Cependant, quelle qu'en soit la raison, l'erreur d'écran bleu rend de nombreux utilisateurs très angoissés. Laissez ce site présenter soigneusement 17 types de solutions aux utilisateurs. 17 solutions à l'écran bleu kernel_security_check_failure Méthode 1 : Supprimer tous les périphériques externes Lorsqu'un périphérique externe que vous utilisez est incompatible avec votre version de Windows, l'erreur d'écran bleu Kernelsecuritycheckfailure peut se produire. Pour ce faire, vous devez débrancher tous les périphériques externes avant d'essayer de redémarrer votre ordinateur.
 Tutoriel sur l'ajout d'un nouveau disque dur dans Win11
Jan 05, 2024 am 09:39 AM
Tutoriel sur l'ajout d'un nouveau disque dur dans Win11
Jan 05, 2024 am 09:39 AM
Lors de l'achat d'un ordinateur, nous ne choisissons pas nécessairement un gros disque dur. À ce stade, si nous voulons ajouter un nouveau disque dur à win11, nous pouvons d'abord installer le nouveau disque dur que nous avons acheté, puis ajouter des partitions à l'ordinateur. Tutoriel sur l'ajout d'un nouveau disque dur dans win11 : 1. Tout d'abord, nous démontons l'hôte et trouvons l'emplacement du disque dur. 2. Après l'avoir trouvé, nous connectons d'abord le « câble de données », qui a généralement une conception infaillible. S'il ne peut pas être inséré, inversez simplement le sens. 3. Insérez ensuite le nouveau disque dur dans l'emplacement pour disque dur. 4. Après l'insertion, connectez l'autre extrémité du câble de données à la carte mère de l'ordinateur. 5. Une fois l'installation terminée, vous pouvez le remettre dans l'hôte et l'allumer. 6. Après le démarrage, cliquez avec le bouton droit sur "Cet ordinateur" et ouvrez "Gestion de l'ordinateur" 7. Après ouverture, cliquez sur "Gestion des disques" dans le coin inférieur gauche 8. Ensuite, à droite, vous pouvez
 Comment ajouter un téléviseur à Mijia
Mar 25, 2024 pm 05:00 PM
Comment ajouter un téléviseur à Mijia
Mar 25, 2024 pm 05:00 PM
De nombreux utilisateurs privilégient de plus en plus l'écosystème électronique d'interconnexion de la maison intelligente Xiaomi dans la vie moderne. Après vous être connecté à l'application Mijia, vous pouvez facilement contrôler les appareils connectés avec votre téléphone mobile. Cependant, de nombreux utilisateurs ne savent toujours pas comment ajouter Mijia à. leur application Homes., ce guide didacticiel vous présentera les méthodes et étapes de connexion spécifiques, dans l'espoir d'aider tous ceux qui en ont besoin. 1. Après avoir téléchargé l'application Mijia, créez ou connectez-vous au compte Xiaomi. 2. Méthode d'ajout : Une fois le nouvel appareil allumé, rapprochez le téléphone de l'appareil et allumez le téléviseur Xiaomi. Dans des circonstances normales, une invite de connexion apparaîtra. Sélectionnez « OK » pour entrer dans le processus de connexion de l'appareil. Si aucune invite ne s'affiche, vous pouvez également ajouter l'appareil manuellement. La méthode est la suivante : après avoir accédé à l'application Smart Home, cliquez sur le premier bouton en bas à gauche.
 Comment ajouter un filigrane aux images dans Vue ?
Aug 19, 2023 pm 12:37 PM
Comment ajouter un filigrane aux images dans Vue ?
Aug 19, 2023 pm 12:37 PM
Comment ajouter un filigrane aux images dans Vue ? Vue est un framework JavaScript populaire largement utilisé pour créer des applications Web. Parfois, nous devons ajouter des filigranes aux images dans les applications Vue pour protéger les droits d'auteur de l'image ou augmenter la reconnaissabilité de l'image. Dans cet article, je vais vous présenter une méthode d'ajout de filigranes aux images dans Vue et fournir des exemples de code correspondants. La première étape consiste à introduire une bibliothèque tierce pour ajouter des filigranes à Vue. Il est recommandé d'utiliser un filigrane
 Tutoriel pour créer rapidement des raccourcis sur le bureau dans Win11
Dec 27, 2023 pm 04:29 PM
Tutoriel pour créer rapidement des raccourcis sur le bureau dans Win11
Dec 27, 2023 pm 04:29 PM
Dans Win11, nous pouvons démarrer rapidement des logiciels ou des fichiers sur le bureau en ajoutant des raccourcis sur le bureau, et il nous suffit de cliquer avec le bouton droit sur les fichiers requis pour fonctionner. Ajouter un raccourci sur le bureau dans win11 : 1. Ouvrez « Ce PC » et recherchez le fichier ou le logiciel auquel vous souhaitez ajouter un raccourci sur le bureau. 2. Après l'avoir trouvé, faites un clic droit pour le sélectionner et cliquez sur "Afficher plus d'options" 3. Sélectionnez ensuite "Envoyer à" - "Raccourci du bureau" 4. Une fois l'opération terminée, vous pouvez trouver le raccourci sur le bureau.
 Comment ajouter un nouveau script dans Tampermonkey-Comment supprimer un script dans Tampermonkey
Mar 18, 2024 pm 12:10 PM
Comment ajouter un nouveau script dans Tampermonkey-Comment supprimer un script dans Tampermonkey
Mar 18, 2024 pm 12:10 PM
L'extension Tampermonkey Chrome est un plug-in de gestion de scripts utilisateur qui améliore l'efficacité des utilisateurs et l'expérience de navigation via des scripts. Alors, comment Tampermonkey ajoute-t-il de nouveaux scripts ? Comment supprimer le script ? Laissez l'éditeur vous donner la réponse ci-dessous ! Comment ajouter un nouveau script à Tampermonkey : 1. Prenez GreasyFork comme exemple. Ouvrez la page Web de GreasyFork et entrez le script que vous souhaitez suivre. L'éditeur choisit ici le téléchargement hors ligne en un clic. 2. Sélectionnez un script. Après être entré dans la page du script, vous pouvez voir le bouton pour installer ce script. 3. Cliquez pour installer ce script pour accéder à l'interface d'installation. Cliquez simplement ici pour installer. 4. Nous pouvons voir l'installé en un clic dans le script d'installation.
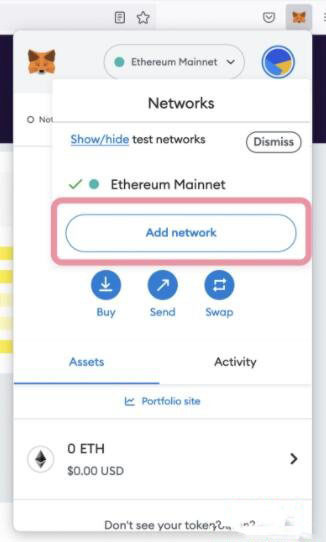 Comment se connecter au réseau Polygon dans le portefeuille MetaMask ? Guide didacticiel pour connecter le portefeuille MetaMask au réseau Polygon
Jan 19, 2024 pm 04:36 PM
Comment se connecter au réseau Polygon dans le portefeuille MetaMask ? Guide didacticiel pour connecter le portefeuille MetaMask au réseau Polygon
Jan 19, 2024 pm 04:36 PM
Comment ajouter un réseau PolygonMainnet Pour utiliser MATIC (Polygon) avec Metamask, vous devez ajouter un réseau privé appelé "PolygonMainnet". Un transfert avec une mauvaise adresse réseau peut causer des problèmes, alors assurez-vous d'utiliser le réseau "PolygonMainnet" avant de transférer hors de $MATIC. Le portefeuille Metamask est connecté par défaut au réseau principal Ethereum, mais nous pouvons simplement ajouter « PolygonMainnet » et utiliser $MATIC. Juste quelques étapes simples de copier-coller et le tour est joué. Tout d'abord, dans le portefeuille Metamask, cliquez sur l'option réseau dans le coin supérieur droit et sélectionnez "C
 Comment désinstaller Skype Entreprise sur Win10 ? Comment désinstaller complètement Skype sur votre ordinateur
Feb 13, 2024 pm 12:30 PM
Comment désinstaller Skype Entreprise sur Win10 ? Comment désinstaller complètement Skype sur votre ordinateur
Feb 13, 2024 pm 12:30 PM
Win10 Skype peut-il être désinstallé ? C'est une question que de nombreux utilisateurs veulent savoir, car de nombreux utilisateurs constatent que cette application est incluse dans le programme par défaut de leur ordinateur et craignent que sa suppression affecte le fonctionnement du système. ce site aide les utilisateurs Examinons de plus près comment désinstaller Skype Entreprise dans Win10. Comment désinstaller Skype Entreprise dans Win10 1. Cliquez sur l'icône Windows sur le bureau de l'ordinateur, puis cliquez sur l'icône des paramètres pour entrer. 2. Cliquez sur "Appliquer". 3. Entrez « Skype » dans la zone de recherche et cliquez pour sélectionner le résultat trouvé. 4. Cliquez sur "Désinstaller". 5
