

Recognizing the Power of Hadoop: Platfora BI Is Be

Recognizing the Power of Hadoop: Platfora BI Is Better on Hadoop: Ben Werther announcing the general availability of the Platfora BI: At Platfora, we made a bet that Hadoop’s destiny wasn’t simply to be a cheaper, slower cousin of the re
Recognizing the Power of Hadoop: Platfora BI Is Better on Hadoop:Ben Werther announcing the general availability of the Platfora BI:
At Platfora, we made a bet that Hadoop’s destiny wasn’t simply to be a cheaper, slower cousin of the relational data warehouse. […] Hadoop is superb at two things — it provides a near-infinite data reservoir where data of all kinds can be landed without needing to figure out how it will be used ahead of time, and it is a slow lumbering freight-train of an engine for crunching and aggregating batches of millions or billions of rows.
They are neither the first, nor the last to understand and bet on Hadoop. But in some cases this bet originates only in the financial potential of the Hadoop market and less so on the technological potential.
Indeed it’s rarely the case that these two can leave alone. When they do, it leads to either a smaller market segment or to a shorter life time. Looking around at what’s happening in the Hadoop space, technologically and business wise, I assume many economists would recognize the signs of a long lived opportunity.
As a side note, I find it interesting that very few articles are looking at two other fundamental aspects of the Hadoop platform, which, in my opinion, were, are and will remain critical to the growth of this market: open source and extensibility. Without any of these two, what would we see would be tons of copy cats wasting resources in creating small indistinguishable clones, plus countless and endless negotiations to extend and integrate the platform. Hadoop is open source and the open source developers working on it have built it with extensibility in mind. The proof is out there and is clear: look at the breadth and depth of the tools around Hadoop.
That’s the power of open source. The way of the future.
Original title and link: Recognizing the Power of Hadoop: Platfora BI Is Better on Hadoop (NoSQL database?myNoSQL)

原文地址:Recognizing the Power of Hadoop: Platfora BI Is Be, 感谢原作者分享。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1662
1662
 14
1419
52
1311
25
1261
29
1234
24
14
1419
52
1311
25
1261
29
1234
24

 Power BI ne peut pas se connecter, une erreur s'est produite lors de la tentative de connexion
Feb 18, 2024 pm 05:48 PM
Power BI ne peut pas se connecter, une erreur s'est produite lors de la tentative de connexion
Feb 18, 2024 pm 05:48 PM
PowerBI peut rencontrer des difficultés lorsqu'il ne parvient pas à se connecter à une source de données qui est un fichier XLS, SQL ou Excel. Cet article explorera les solutions possibles pour vous aider à résoudre ce problème. Cet article vous expliquera quoi faire si vous rencontrez des erreurs ou des échecs de connexion pendant le processus de connexion. Donc, si vous êtes confronté à ce problème, continuez à lire et nous vous fournirons quelques suggestions utiles. Quelle est l’erreur de connexion à la passerelle dans PowerBI ? Les erreurs de passerelle dans PowerBI sont souvent causées par une inadéquation entre les informations de la source de données et l'ensemble de données sous-jacent. Pour résoudre ce problème, vous devez vous assurer que la source de données définie sur la passerelle de données locale est exacte et cohérente avec la source de données spécifiée dans le bureau PowerBI. PowerBI ne peut pas se connecter
 Après 2 mois, le robot humanoïde Walker S peut plier les vêtements
Apr 03, 2024 am 08:01 AM
Après 2 mois, le robot humanoïde Walker S peut plier les vêtements
Apr 03, 2024 am 08:01 AM
Rédacteur en chef du Machine Power Report : Wu Xin La version domestique de l'équipe robot humanoïde + grand modèle a accompli pour la première fois la tâche d'exploitation de matériaux flexibles complexes tels que le pliage de vêtements. Avec le dévoilement de Figure01, qui intègre le grand modèle multimodal d'OpenAI, les progrès connexes des pairs nationaux ont attiré l'attention. Hier encore, UBTECH, le « stock numéro un de robots humanoïdes » en Chine, a publié la première démo du robot humanoïde WalkerS, profondément intégré au grand modèle de Baidu Wenxin, présentant de nouvelles fonctionnalités intéressantes. Maintenant, WalkerS, bénéficiant des capacités de grands modèles de Baidu Wenxin, ressemble à ceci. Comme la figure 01, WalkerS ne se déplace pas, mais se tient derrière un bureau pour accomplir une série de tâches. Il peut suivre les commandes humaines et plier les vêtements
 Power BI Nous ne pouvons pas nous connecter car cette ressource ne prend pas en charge ce type d'informations d'identification
Feb 19, 2024 am 10:57 AM
Power BI Nous ne pouvons pas nous connecter car cette ressource ne prend pas en charge ce type d'informations d'identification
Feb 19, 2024 am 10:57 AM
Lorsque vous essayez de connecter PowerBI à SharePoint, vous pouvez rencontrer une erreur indiquant que le type d'informations d'identification fourni n'est pas pris en charge par une ressource spécifique. Cela a un impact sur le flux de travail et doit être résolu rapidement. Cet article explique comment gérer le message PowerBI indiquant qu'il ne peut pas se connecter car la ressource ne prend pas en charge le type d'informations d'identification. PowerBI Nous ne pouvons pas nous connecter car cette ressource ne prend pas en charge ce type d'informations d'identification. Si PowerBI affiche « Nous ne pouvons pas nous connecter car cette ressource ne prend pas en charge ce type d'informations d'identification », suivez les solutions mentionnées ci-dessous. Modifier les autorisations pour la source de données Vider le cache et/ou modifier les autorisations Modifier le navigateur par défaut Effacer la source de données Utilisation d'ODataFeed Contacter le support PowerBI Parlons en détail. 1]
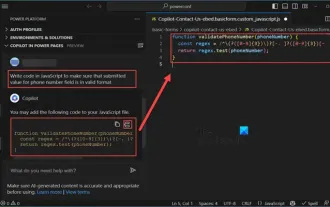 Comment utiliser Copilot pour générer du code
Mar 23, 2024 am 10:41 AM
Comment utiliser Copilot pour générer du code
Mar 23, 2024 am 10:41 AM
En tant que programmeur, je suis enthousiasmé par les outils qui simplifient l'expérience de codage. À l'aide d'outils d'intelligence artificielle, nous pouvons générer du code de démonstration et apporter les modifications nécessaires selon les exigences. Le nouvel outil Copilot dans Visual Studio Code nous permet de créer du code généré par l'IA avec des interactions de chat en langage naturel. En expliquant les fonctionnalités, nous pouvons mieux comprendre la signification du code existant. Comment utiliser Copilot pour générer du code ? Pour commencer, nous devons d’abord obtenir la dernière extension PowerPlatformTools. Pour y parvenir, vous devez vous rendre sur la page de l'extension, rechercher "PowerPlatformTool" et cliquer sur le bouton Installer.
 Erreurs Java : erreurs Hadoop, comment les gérer et les éviter
Jun 24, 2023 pm 01:06 PM
Erreurs Java : erreurs Hadoop, comment les gérer et les éviter
Jun 24, 2023 pm 01:06 PM
Erreurs Java : erreurs Hadoop, comment les gérer et les éviter Lorsque vous utilisez Hadoop pour traiter des données volumineuses, vous rencontrez souvent des erreurs d'exception Java, qui peuvent affecter l'exécution des tâches et provoquer l'échec du traitement des données. Cet article présentera quelques erreurs Hadoop courantes et fournira des moyens de les gérer et de les éviter. Java.lang.OutOfMemoryErrorOutOfMemoryError est une erreur provoquée par une mémoire insuffisante de la machine virtuelle Java. Quand Hadoop est
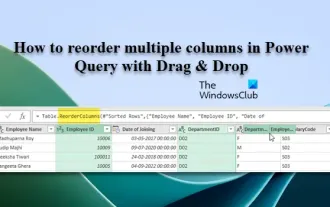 Comment réorganiser plusieurs colonnes dans Power Query par glisser-déposer
Mar 14, 2024 am 10:55 AM
Comment réorganiser plusieurs colonnes dans Power Query par glisser-déposer
Mar 14, 2024 am 10:55 AM
Dans cet article, nous allons vous montrer comment réorganiser plusieurs colonnes dans PowerQuery par glisser-déposer. Souvent, lors de l'importation de données provenant de diverses sources, les colonnes peuvent ne pas être dans l'ordre souhaité. La réorganisation des colonnes vous permet non seulement de les organiser dans un ordre logique adapté à vos besoins d'analyse ou de reporting, mais elle améliore également la lisibilité de vos données et accélère les tâches telles que le filtrage, le tri et l'exécution de calculs. Comment réorganiser plusieurs colonnes dans Excel ? Il existe de nombreuses façons de réorganiser les colonnes dans Excel. Vous pouvez simplement sélectionner l'en-tête de colonne et le faire glisser vers l'emplacement souhaité. Cependant, cette approche peut devenir fastidieuse lorsqu’il s’agit de grands tableaux comportant de nombreuses colonnes. Pour réorganiser les colonnes plus efficacement, vous pouvez utiliser l'éditeur de requête amélioré. Améliorer la requête
 Comment utiliser PHP et Hadoop pour le traitement du Big Data
Jun 19, 2023 pm 02:24 PM
Comment utiliser PHP et Hadoop pour le traitement du Big Data
Jun 19, 2023 pm 02:24 PM
Alors que la quantité de données continue d’augmenter, les méthodes traditionnelles de traitement des données ne peuvent plus relever les défis posés par l’ère du Big Data. Hadoop est un cadre informatique distribué open source qui résout le problème de goulot d'étranglement des performances causé par les serveurs à nœud unique dans le traitement du Big Data grâce au stockage distribué et au traitement de grandes quantités de données. PHP est un langage de script largement utilisé dans le développement Web et présente les avantages d'un développement rapide et d'une maintenance facile. Cet article explique comment utiliser PHP et Hadoop pour le traitement du Big Data. Qu'est-ce que HadoopHadoop ?
 Utilisation de Hadoop et HBase dans Beego pour le stockage et les requêtes Big Data
Jun 22, 2023 am 10:21 AM
Utilisation de Hadoop et HBase dans Beego pour le stockage et les requêtes Big Data
Jun 22, 2023 am 10:21 AM
Avec l'avènement de l'ère du Big Data, le traitement et le stockage des données sont devenus de plus en plus importants, et la gestion et l'analyse efficaces de grandes quantités de données sont devenues un défi pour les entreprises. Hadoop et HBase, deux projets de la Fondation Apache, proposent une solution de stockage et d'analyse du Big Data. Cet article explique comment utiliser Hadoop et HBase dans Beego pour le stockage et les requêtes Big Data. 1. Introduction à Hadoop et HBase Hadoop est un système informatique et de stockage distribué open source qui peut
