

伪分布式安装部署CDH4.2.1与Impala[原创实践]

参考资料: http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Quick-Start/cdh4qs_topic_3_3.html http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/Installing
参考资料:
http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Quick-Start/cdh4qs_topic_3_3.html
http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/Installing-and-Using-Impala.html
http://blog.cloudera.com/blog/2013/02/from-zero-to-impala-in-minutes/
什么是Impala?
Cloudera发布了实时查询开源项目Impala,根据多款产品实测表明,它比原来基于MapReduce的Hive SQL查询速度提升3~90倍。Impala是Google Dremel的模仿,但在SQL功能上青出于蓝胜于蓝。
1. 安装JDK
$ sudo yum install jdk-6u41-linux-amd64.rpm
2. 伪分布式模式安装CDH4
$ cd /etc/yum.repos.d/
$ sudo wget http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/cloudera-cdh4.repo
$ sudo yum install hadoop-conf-pseudo
格式化NameNode.
$ sudo -u hdfs hdfs namenode -format
启动HDFS
$ for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
创建/tmp目录
$ sudo -u hdfs hadoop fs -rm -r /tmp
$ sudo -u hdfs hadoop fs -mkdir /tmp
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
创建YARN与日志目录
$ sudo -u hdfs hadoop fs -mkdir /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -mkdir /tmp/hadoop-yarn/staging/history/done_intermediate
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging/history/done_intermediate
$ sudo -u hdfs hadoop fs -chown -R mapred:mapred /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -mkdir /var/log/hadoop-yarn
$ sudo -u hdfs hadoop fs -chown yarn:mapred /var/log/hadoop-yarn
检查HDFS文件树
$ sudo -u hdfs hadoop fs -ls -R /
drwxrwxrwt - hdfs supergroup 0 2012-05-31 15:31 /tmp drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /tmp/hadoop-yarn drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging drwxr-xr-x - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history/done_intermediate drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var/log drwxr-xr-x - yarn mapred 0 2012-05-31 15:31 /var/log/hadoop-yarn
启动YARN
$ sudo service hadoop-yarn-resourcemanager start
$ sudo service hadoop-yarn-nodemanager start
$ sudo service hadoop-mapreduce-historyserver start
创建用户目录(以用户dong.guo为例):
$ sudo -u hdfs hadoop fs -mkdir /user/dong.guo
$ sudo -u hdfs hadoop fs -chown dong.guo /user/dong.guo
测试上传文件
$ hadoop fs -mkdir input
$ hadoop fs -put /etc/hadoop/conf/*.xml input
$ hadoop fs -ls input
Found 4 items -rw-r--r-- 1 dong.guo supergroup 1461 2013-05-14 03:30 input/core-site.xml -rw-r--r-- 1 dong.guo supergroup 1854 2013-05-14 03:30 input/hdfs-site.xml -rw-r--r-- 1 dong.guo supergroup 1325 2013-05-14 03:30 input/mapred-site.xml -rw-r--r-- 1 dong.guo supergroup 2262 2013-05-14 03:30 input/yarn-site.xml
配置HADOOP_MAPRED_HOME环境变量
$ export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
运行一个测试Job
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar grep input output23 'dfs[a-z.]+'
Job完成后,可以看到以下目录
$ hadoop fs -ls
Found 2 items drwxr-xr-x - dong.guo supergroup 0 2013-05-14 03:30 input drwxr-xr-x - dong.guo supergroup 0 2013-05-14 03:32 output23
$ hadoop fs -ls output23
Found 2 items -rw-r--r-- 1 dong.guo supergroup 0 2013-05-14 03:32 output23/_SUCCESS -rw-r--r-- 1 dong.guo supergroup 150 2013-05-14 03:32 output23/part-r-00000
$ hadoop fs -cat output23/part-r-00000 | head
1 dfs.safemode.min.datanodes 1 dfs.safemode.extension 1 dfs.replication 1 dfs.namenode.name.dir 1 dfs.namenode.checkpoint.dir 1 dfs.datanode.data.dir
3. 安装 Hive
$ sudo yum install hive hive-metastore hive-server
$ sudo yum install mysql-server
$ sudo service mysqld start
$ cd ~
$ wget 'http://cdn.mysql.com/Downloads/Connector-J/mysql-connector-java-5.1.25.tar.gz'
$ tar xzf mysql-connector-java-5.1.25.tar.gz
$ sudo cp mysql-connector-java-5.1.25/mysql-connector-java-5.1.25-bin.jar /usr/lib/hive/lib/
$ sudo /usr/bin/mysql_secure_installation
[...] Enter current password for root (enter for none): OK, successfully used password, moving on... [...] Set root password? [Y/n] y New password:hadoophive Re-enter new password:hadoophive Remove anonymous users? [Y/n] Y [...] Disallow root login remotely? [Y/n] N [...] Remove test database and access to it [Y/n] Y [...] Reload privilege tables now? [Y/n] Y All done!
$ mysql -u root -phadoophive
mysql> CREATE DATABASE metastore; mysql> USE metastore; mysql> SOURCE /usr/lib/hive/scripts/metastore/upgrade/mysql/hive-schema-0.10.0.mysql.sql; mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hadoophive'; mysql> CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hadoophive'; mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'%'; mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'localhost'; mysql> GRANT SELECT,INSERT,UPDATE,DELETE,LOCK TABLES,EXECUTE ON metastore.* TO 'hive'@'%'; mysql> GRANT SELECT,INSERT,UPDATE,DELETE,LOCK TABLES,EXECUTE ON metastore.* TO 'hive'@'localhost'; mysql> FLUSH PRIVILEGES; mysql> quit;
$ sudo mv /etc/hive/conf/hive-site.xml /etc/hive/conf/hive-site.xml.bak
$ sudo vim /etc/hive/conf/hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://heylinux.com/archives/configuration.xsl"?> javax.jdo.option.ConnectionURL jdbc:mysql://localhost/metastore the URL of the MySQL database javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName hive javax.jdo.option.ConnectionPassword hadoophive datanucleus.autoCreateSchema false datanucleus.fixedDatastore true hive.metastore.uris thrift://127.0.0.1:9083 IP address (or fully-qualified domain name) and port of the metastore host hive.aux.jars.path file:///usr/lib/hive/lib/zookeeper.jar,file:///usr/lib/hive/lib/hbase.jar,file:///usr/lib/hive/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar,file:///usr/lib/hive/lib/guava-11.0.2.jar
$ sudo service hive-metastore start
Starting (hive-metastore): [ OK ]
$ sudo service hive-server start
Starting (hive-server): [ OK ]
$ sudo -u hdfs hadoop fs -mkdir /user/hive
$ sudo -u hdfs hadoop fs -chown hive /user/hive
$ sudo -u hdfs hadoop fs -mkdir /tmp
$ sudo -u hdfs hadoop fs -chmod 777 /tmp
$ sudo -u hdfs hadoop fs -chmod o+t /tmp
$ sudo -u hdfs hadoop fs -mkdir /data
$ sudo -u hdfs hadoop fs -chown hdfs /data
$ sudo -u hdfs hadoop fs -chmod 777 /data
$ sudo -u hdfs hadoop fs -chmod o+t /data
$ sudo chown -R hive:hive /var/lib/hive
$ sudo vim /tmp/kv1.txt
1 www.baidu.com 2 www.google.com 3 www.sina.com.cn 4 www.163.com 5 heylinx.com
$ sudo -u hive hive
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties Hive history file=/tmp/root/hive_job_log_root_201305140801_825709760.txt hive> CREATE TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n"; hive> show tables; OK pokes Time taken: 0.415 seconds hive> LOAD DATA LOCAL INPATH '/tmp/kv1.txt' OVERWRITE INTO TABLE pokes; Copying data from file:/tmp/kv1.txt Copying file: file:/tmp/kv1.txt Loading data to table default.pokes rmr: DEPRECATED: Please use 'rm -r' instead. Deleted /user/hive/warehouse/pokes Table default.pokes stats: [num_partitions: 0, num_files: 1, num_rows: 0, total_size: 79, raw_data_size: 0] OK Time taken: 1.681 seconds
$ export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
4. 安装 Impala
$ cd /etc/yum.repos.d/
$ sudo wget http://archive.cloudera.com/impala/redhat/6/x86_64/impala/cloudera-impala.repo
$ sudo yum install impala impala-shell
$ sudo yum install impala-server impala-state-store
$ sudo vim /etc/hadoop/conf/hdfs-site.xml
... dfs.client.read.shortcircuit true dfs.domain.socket.path /var/run/hadoop-hdfs/dn._PORT dfs.client.file-block-storage-locations.timeout 3000 dfs.datanode.hdfs-blocks-metadata.enabled true
$ sudo cp -rpa /etc/hadoop/conf/core-site.xml /etc/impala/conf/
$ sudo cp -rpa /etc/hadoop/conf/hdfs-site.xml /etc/impala/conf/
$ sudo service hadoop-hdfs-datanode restart
$ sudo service impala-state-store restart
$ sudo service impala-server restart
$ sudo /usr/java/default/bin/jps
5. 安装 Hbase
$ sudo yum install hbase
$ sudo vim /etc/security/limits.conf
hdfs - nofile 32768 hbase - nofile 32768
$ sudo vim /etc/pam.d/common-session
session required pam_limits.so
$ sudo vim /etc/hadoop/conf/hdfs-site.xml
dfs.datanode.max.xcievers 4096
$ sudo cp /usr/lib/impala/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar /usr/lib/hive/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar
$ sudo /etc/init.d/hadoop-hdfs-namenode restart
$ sudo /etc/init.d/hadoop-hdfs-datanode restart
$ sudo yum install hbase-master
$ sudo service hbase-master start
$ sudo -u hive hive
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties
Hive history file=/tmp/hive/hive_job_log_hive_201305140905_2005531704.txt
hive> CREATE TABLE hbase_table_1(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "xyz");
OK
Time taken: 3.587 seconds
hive> INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=5;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1368502088579_0004, Tracking URL = http://ip-10-197-10-4:8088/proxy/application_1368502088579_0004/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1368502088579_0004
Hadoop job information for Stage-0: number of mappers: 1; number of reducers: 0
2013-05-14 09:12:45,340 Stage-0 map = 0%, reduce = 0%
2013-05-14 09:12:53,165 Stage-0 map = 100%, reduce = 0%, Cumulative CPU 2.63 sec
MapReduce Total cumulative CPU time: 2 seconds 630 msec
Ended Job = job_1368502088579_0004
1 Rows loaded to hbase_table_1
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 2.63 sec HDFS Read: 288 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 630 msec
OK
Time taken: 21.063 seconds
hive> select * from hbase_table_1;
OK
5 heylinx.com
Time taken: 0.685 seconds
hive> SELECT COUNT (*) FROM pokes;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
Starting Job = job_1368502088579_0005, Tracking URL = http://ip-10-197-10-4:8088/proxy/application_1368502088579_0005/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1368502088579_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2013-05-14 10:32:04,711 Stage-1 map = 0%, reduce = 0%
2013-05-14 10:32:11,461 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:12,554 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:13,642 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:14,760 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:15,918 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:16,991 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:18,111 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:19,188 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.04 sec
MapReduce Total cumulative CPU time: 4 seconds 40 msec
Ended Job = job_1368502088579_0005
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 4.04 sec HDFS Read: 288 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 40 msec
OK
5
Time taken: 28.195 seconds
</number></number></number>6. 测试Impala性能
View parameters on http://ec2-204-236-182-78.us-west-1.compute.amazonaws.com:25000
$ impala-shell
[ip-10-197-10-4.us-west-1.compute.internal:21000] > CREATE TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n"; Query: create TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n" [ip-10-197-10-4.us-west-1.compute.internal:21000] > show tables; Query: show tables Query finished, fetching results ... +-------+ | name | +-------+ | pokes | +-------+ Returned 1 row(s) in 0.00s [ip-10-197-10-4.us-west-1.compute.internal:21000] > SELECT * from pokes; Query: select * from pokes Query finished, fetching results ... +-----+-----------------+ | foo | bar | +-----+-----------------+ | 1 | www.baidu.com | | 2 | www.google.com | | 3 | www.sina.com.cn | | 4 | www.163.com | | 5 | heylinx.com | +-----+-----------------+ Returned 5 row(s) in 0.28s [ip-10-197-10-4.us-west-1.compute.internal:21000] > SELECT COUNT (*) from pokes; Query: select COUNT (*) from pokes Query finished, fetching results ... +----------+ | count(*) | +----------+ | 5 | +----------+ Returned 1 row(s) in 0.34s
通过两个COUNT的结果来看,Hive使用了 28.195 seconds 而 Impala仅使用了0.34s,由此可以看出Impala的性能确实要优于Hive。
原文地址:伪分布式安装部署CDH4.2.1与Impala[原创实践], 感谢原作者分享。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Solution au problème selon lequel le pack de langue chinoise ne peut pas être installé sur le système Win11
Mar 09, 2024 am 09:48 AM
Solution au problème selon lequel le pack de langue chinoise ne peut pas être installé sur le système Win11
Mar 09, 2024 am 09:48 AM
Solution au problème selon lequel le système Win11 ne peut pas installer le pack de langue chinoise Avec le lancement du système Windows 11, de nombreux utilisateurs ont commencé à mettre à niveau leur système d'exploitation pour découvrir de nouvelles fonctions et interfaces. Cependant, certains utilisateurs ont constaté qu'ils ne parvenaient pas à installer le pack de langue chinoise après la mise à niveau, ce qui perturbait leur expérience. Dans cet article, nous discuterons des raisons pour lesquelles le système Win11 ne peut pas installer le pack de langue chinoise et proposerons des solutions pour aider les utilisateurs à résoudre ce problème. Analyse des causes Tout d'abord, analysons l'incapacité du système Win11 à
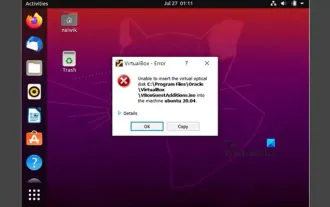 Impossible d'installer les ajouts d'invités dans VirtualBox
Mar 10, 2024 am 09:34 AM
Impossible d'installer les ajouts d'invités dans VirtualBox
Mar 10, 2024 am 09:34 AM
Vous ne pourrez peut-être pas installer des ajouts d'invités sur une machine virtuelle dans OracleVirtualBox. Lorsque nous cliquons sur Périphériques> InstallGuestAdditionsCDImage, cela renvoie simplement une erreur comme indiqué ci-dessous : VirtualBox - Erreur : Impossible d'insérer le disque virtuel C : Programmation de fichiersOracleVirtualBoxVBoxGuestAdditions.iso dans la machine Ubuntu Dans cet article, nous comprendrons ce qui se passe lorsque vous Que faire lorsque vous Je ne peux pas installer les ajouts d'invités dans VirtualBox. Impossible d'installer les ajouts d'invités dans VirtualBox Si vous ne pouvez pas l'installer dans Virtua
 Que dois-je faire si Baidu Netdisk est téléchargé avec succès mais ne peut pas être installé ?
Mar 13, 2024 pm 10:22 PM
Que dois-je faire si Baidu Netdisk est téléchargé avec succès mais ne peut pas être installé ?
Mar 13, 2024 pm 10:22 PM
Si vous avez téléchargé avec succès le fichier d'installation de Baidu Netdisk, mais que vous ne parvenez pas à l'installer normalement, il se peut qu'il y ait une erreur dans l'intégrité du fichier du logiciel ou qu'il y ait un problème avec les fichiers résiduels et les entrées de registre. prenons-en soin pour les utilisateurs. Présentons l'analyse du problème selon lequel Baidu Netdisk est téléchargé avec succès mais ne peut pas être installé. Analyse du problème du téléchargement réussi de Baidu Netdisk mais qui n'a pas pu être installé 1. Vérifiez l'intégrité du fichier d'installation : Assurez-vous que le fichier d'installation téléchargé est complet et n'est pas endommagé. Vous pouvez le télécharger à nouveau ou essayer de télécharger le fichier d'installation à partir d'une autre source fiable. 2. Désactivez le logiciel antivirus et le pare-feu : Certains logiciels antivirus ou pare-feu peuvent empêcher le bon fonctionnement du programme d'installation. Essayez de désactiver ou de quitter le logiciel antivirus et le pare-feu, puis réexécutez l'installation.
 Comment installer des applications Android sur Linux ?
Mar 19, 2024 am 11:15 AM
Comment installer des applications Android sur Linux ?
Mar 19, 2024 am 11:15 AM
L'installation d'applications Android sur Linux a toujours été une préoccupation pour de nombreux utilisateurs. Surtout pour les utilisateurs Linux qui aiment utiliser des applications Android, il est très important de maîtriser comment installer des applications Android sur les systèmes Linux. Bien qu'exécuter des applications Android directement sur Linux ne soit pas aussi simple que sur la plateforme Android, en utilisant des émulateurs ou des outils tiers, nous pouvons toujours profiter avec plaisir des applications Android sur Linux. Ce qui suit explique comment installer des applications Android sur les systèmes Linux.
 Comment installer Podman sur Ubuntu 24.04
Mar 22, 2024 am 11:26 AM
Comment installer Podman sur Ubuntu 24.04
Mar 22, 2024 am 11:26 AM
Si vous avez utilisé Docker, vous devez comprendre les démons, les conteneurs et leurs fonctions. Un démon est un service qui s'exécute en arrière-plan lorsqu'un conteneur est déjà utilisé dans n'importe quel système. Podman est un outil de gestion gratuit permettant de gérer et de créer des conteneurs sans recourir à un démon tel que Docker. Par conséquent, il présente des avantages dans la gestion des conteneurs sans nécessiter de services backend à long terme. De plus, Podman ne nécessite pas d'autorisations au niveau racine pour être utilisé. Ce guide explique en détail comment installer Podman sur Ubuntu24. Pour mettre à jour le système, nous devons d'abord mettre à jour le système et ouvrir le shell du terminal d'Ubuntu24. Pendant les processus d’installation et de mise à niveau, nous devons utiliser la ligne de commande. un simple
 Mar 22, 2024 pm 04:40 PM
Mar 22, 2024 pm 04:40 PM
Durant leurs études au lycée, certains élèves prennent des notes très claires et précises, prenant plus de notes que d’autres dans la même classe. Pour certains, prendre des notes est un passe-temps, tandis que pour d’autres, c’est une nécessité lorsqu’ils oublient facilement de petites informations sur quelque chose d’important. L'application NTFS de Microsoft est particulièrement utile pour les étudiants qui souhaitent sauvegarder des notes importantes au-delà des cours réguliers. Dans cet article, nous décrirons l'installation des applications Ubuntu sur Ubuntu24. Mise à jour du système Ubuntu Avant d'installer le programme d'installation d'Ubuntu, sur Ubuntu24, nous devons nous assurer que le système nouvellement configuré a été mis à jour. Nous pouvons utiliser le "a" le plus célèbre du système Ubuntu
 Étapes détaillées pour installer le langage Go sur un ordinateur Win7
Mar 27, 2024 pm 02:00 PM
Étapes détaillées pour installer le langage Go sur un ordinateur Win7
Mar 27, 2024 pm 02:00 PM
Étapes détaillées pour installer le langage Go sur un ordinateur Win7 Go (également connu sous le nom de Golang) est un langage de programmation open source développé par Google. Il est simple, efficace et offre d'excellentes performances de concurrence. Il convient au développement de services cloud, d'applications réseau et. systèmes back-end. Installer le langage Go sur un ordinateur Win7 permet de prendre rapidement en main le langage et de commencer à écrire des programmes Go. Ce qui suit présentera en détail les étapes pour installer le langage Go sur un ordinateur Win7 et joindra des exemples de code spécifiques. Étape 1 : Téléchargez le package d'installation du langage Go et visitez le site officiel de Go
 Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
1. Introduction Au cours des dernières années, les YOLO sont devenus le paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de leur équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont exploré la conception architecturale de YOLO, les objectifs d'optimisation, les stratégies d'expansion des données, etc., et ont réalisé des progrès significatifs. Dans le même temps, le recours à la suppression non maximale (NMS) pour le post-traitement entrave le déploiement de bout en bout de YOLO et affecte négativement la latence d'inférence. Dans les YOLO, la conception de divers composants manque d’une inspection complète et approfondie, ce qui entraîne une redondance informatique importante et limite les capacités du modèle. Il offre une efficacité sous-optimale et un potentiel d’amélioration des performances relativement important. Dans ce travail, l'objectif est d'améliorer encore les limites d'efficacité des performances de YOLO à la fois en post-traitement et en architecture de modèle. à cette fin
