

Schema Design for Social Inboxes in MongoDB

Designing a schema is a critical part of any application. Like most databases, there are many options for modeling data in MongoDB, and it is important to incorporate the functional requirements and performance goals for your application w
Designing a schema is a critical part of any application. Like most databases, there are many options for modeling data in MongoDB, and it is important to incorporate the functional requirements and performance goals for your application when determining the best design. In this post, we’ll explore three approaches for using MongoDB when creating social inboxes or message timelines.
If you’re building a social network, like Twitter for example, you need to design a schema that is efficient for users viewing their inbox, as well as users sending messages to all their followers. The whole point of social media, after all, is that you can connect in real time.
There are several design considerations for this kind of application:
- The application needs to support a potentially large volume of reads and writes.
- Reads and writes are not uniformly distributed across users. Some users post much more frequently than others, and some users have many, many more followers than others.
- The application must provide a user experience that is instantaneous.
- Edit 11/6: The application will have little to no user deletions of data (a follow up blog post will include information about user deletions and historical data)
Because we are designing an application that needs to support a large volume of reads and writes we will be using a sharded collection for the messages. All three designs include the concept of “fan out,” which refers to distributing the work across the shards in parallel:
- Fan out on Read
- Fan out on Write
- Fan out on Write with Buckets
Each approach presents trade-offs, and you should use the design that is best for your application’s requirements.
The first design you might consider is called Fan Out on Read. When a user sends a message, it is simply saved to the inbox collection. When any user views their own inbox, the application queries for all messages that include the user as a recipient. The messages are returned in descending date order so that users can see the most recent messages.
To implement this design, create a sharded collection called inbox, specifying the from field as the shard key, which represents the address sending the message. You can then add a compound index on the to field and the sent field. Once the document is saved into the inbox, the message is effectively sent to all the recipients. With this approach sending messages is very efficient.
Viewing an inbox, on the other hand, is less efficient. When a user views their inbox the application issues a find command based on the to field, sorted by sent. Because the inbox collection uses from as its shard key, messages are grouped by sender across the shards. In MongoDB queries that are not based on the shard key will be routed to all shards. Therefore, each inbox view will be routed to all shards in the system. As the system scales and many users go to view their inbox, all queries will be routed to all shards. This design does not scale as well as each query being routed to a single shard.

With the “Fan Out on Read” method, sending a message is very efficient, but viewing the inbox is less efficient.
Fan out on Read is very efficient for sending messages, but less efficient for reading messages. If the majority of your application consists of users sending messages, but very few go to read what anyone sends them — let’s call it an anti-social app — then this design might work well. However, for most social apps there are more requests by users to view their inbox than there are to send messages.
The Fan out on Write takes a different approach that is more optimized for viewing inboxes. This time, instead of sharding our inbox collection on the sender, we shard on the message recipient. In this way, when we go to view an inbox the queries can be routed to a single shard, which will scale very well. Our message document is the same, but now save a copy of the message for every recipient.

With the “Fan Out on Write” method, viewing the inbox is efficient, but sending messages consumes more resources.
In practice we might implement the saving of messages asynchronously. Imagine two celebrities quickly exchange messages at a high-profile event - the system could quickly be saturated with millions of writes. By saving a first copy of their message, then using a pool of background workers to write copies to all followers, we can ensure the two celebrities can exchange messages quickly, and that followers will soon have their own copies. Furthermore, we could maintain a last-viewed date on the user document to ensure they have accessed the system recently - zombie accounts probably shouldn’t get a copy of the message, and for users that haven’t accessed their account recently we could always resort to our first design - Fan out on Read - to repopulate their inbox. Subsequent requests would then be fast again.
At this point we have improved the design for viewing inboxes by routing each inbox view to a single shard. However, each message in the user’s inbox will produce a random read operation. If each inbox view produces 50 random reads, then it only takes a relatively modest number of concurrent users to potentially saturate the disks. Fortunately we can take advantage of the document data model to further optimize this design to be even more efficient.
Fan out on Write with Buckets refines the Fan Out on Write design by “bucketing” messages together into documents of 50 messages ordered by time. When a user views their inbox the request can be fulfilled by reading just a few documents of 50 messages each instead of performing many random reads. Because read time is dominated by seek time, reducing the number of seeks can provide a major performance improvement to the application. Another advantage to this approach is that there are fewer index entries.
To implement this design we create two collections, an inbox collection and a user collection. The inbox collection uses two fields for the shard key, owner and sequence, which holds the owner’s user id and sequence number (i.e. the id of 50-message “bucket” documents in their inbox). The user collection contains simple user documents for tracking the total number of messages in their inbox. Since we will probably need to show the total number of messages for a user in a variety of places in our application, this is a nice place to maintain the count instead of calculating for each request. Our message document is the same as in the prior examples.
To send a message we iterate through the list of recipients as we did in the Fan out on Write example, but we also take another step to increment the count of total messages in the inbox of the recipient, which is maintained on the user document. Once we know the count of messages, we know the “bucket” in which to add the latest message. As these messages reach the 50 item threshold, the sequence number increments and we begin to add messages to the next “bucket” document. The most recent messages will always be in the “bucket” document with the highest sequence number. Viewing the most recent 50 messages for a user’s inbox is at most two reads; viewing the most recent 100 messages is at most three reads.
Normally a user’s entire inbox will exist on a single shard. However, it is possible that a few user inboxes could be spread across two shards. Because our application will probably page through a user’s inbox, it is still likely that every query for these few users will be routed to a single shard.
Fan out on Write with Buckets is generally the most scalable approach of the these three designs for social inbox applications. Every design presents different trade-offs. In this case viewing a user’s inbox is very efficient, but writes are somewhat more complex, and more disk space is consumed. For many applications these are the right trade-offs to make.

Schema design is one of the most important optimizations you can make for your application. We have a number of additional resources available on schema design if you are interested in learning more:
Shard per recipient Multiple writes |
Shard per recipient Appends (grows) |
||
Broadcast all shards Random reads |
Single shard Random reads |
Single shard Single read |
|
Message stored once |
Copy per recipient |
Copy per recipient |
Schema design is one of the most important optimizations you can make for your application. We have a number of additional resources available on schema design if you are interested in learning more:
- Check out the recording of our recent Schema Design webinar on this topic.
- Schema Design in general in the MongoDB Manual
- You can also view our schema design resources on the MongoDB docs page
- If you have any schema design questions, please view the archived questions on our user forum or ask a question yourselfon the MongoDB User Forum.
原文地址:Schema Design for Social Inboxes in MongoDB, 感谢原作者分享。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 17 façons de résoudre l'écran bleu kernel_security_check_failure
Feb 12, 2024 pm 08:51 PM
17 façons de résoudre l'écran bleu kernel_security_check_failure
Feb 12, 2024 pm 08:51 PM
Kernelsecuritycheckfailure (échec de la vérification du noyau) est un type de code d'arrêt relativement courant. Cependant, quelle qu'en soit la raison, l'erreur d'écran bleu rend de nombreux utilisateurs très angoissés. Laissez ce site présenter soigneusement 17 types de solutions aux utilisateurs. 17 solutions à l'écran bleu kernel_security_check_failure Méthode 1 : Supprimer tous les périphériques externes Lorsqu'un périphérique externe que vous utilisez est incompatible avec votre version de Windows, l'erreur d'écran bleu Kernelsecuritycheckfailure peut se produire. Pour ce faire, vous devez débrancher tous les périphériques externes avant d'essayer de redémarrer votre ordinateur.
 Rien ne montre le tout nouveau design de la CMF Watch Pro 2, révèle des détails curieux sur le CMF Phone 1
Jun 27, 2024 am 10:42 AM
Rien ne montre le tout nouveau design de la CMF Watch Pro 2, révèle des détails curieux sur le CMF Phone 1
Jun 27, 2024 am 10:42 AM
Rien n'avait déjà annoncé la semaine dernière que trois nouveaux produits seraient dévoilés le 8 juillet 2024 : le CMF Watch Pro 2, le CMF Phone 1 et le CMF Buds Pro 2. Le fabricant a maintenant publié des images teaser révélant de nouveaux détails de conception pour ces produits.
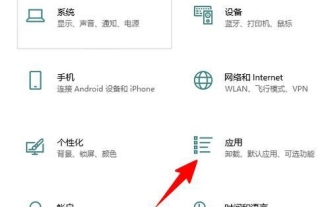 Comment désinstaller Skype Entreprise sur Win10 ? Comment désinstaller complètement Skype sur votre ordinateur
Feb 13, 2024 pm 12:30 PM
Comment désinstaller Skype Entreprise sur Win10 ? Comment désinstaller complètement Skype sur votre ordinateur
Feb 13, 2024 pm 12:30 PM
Win10 Skype peut-il être désinstallé ? C'est une question que de nombreux utilisateurs veulent savoir, car de nombreux utilisateurs constatent que cette application est incluse dans le programme par défaut de leur ordinateur et craignent que sa suppression affecte le fonctionnement du système. ce site aide les utilisateurs Examinons de plus près comment désinstaller Skype Entreprise dans Win10. Comment désinstaller Skype Entreprise dans Win10 1. Cliquez sur l'icône Windows sur le bureau de l'ordinateur, puis cliquez sur l'icône des paramètres pour entrer. 2. Cliquez sur "Appliquer". 3. Entrez « Skype » dans la zone de recherche et cliquez pour sélectionner le résultat trouvé. 4. Cliquez sur "Désinstaller". 5
 Le propriétaire du Cybertruck examine le nouveau design intérieur et l'expérience de livraison de Tactical Grey
Jun 30, 2024 pm 09:44 PM
Le propriétaire du Cybertruck examine le nouveau design intérieur et l'expérience de livraison de Tactical Grey
Jun 30, 2024 pm 09:44 PM
Outre l'intérieur Cybertruck blanc élégant mais facile à teindre disponible au lancement, Tesla propose désormais également le pick-up électrique disponible dans une couleur plus large. La nouvelle couleur intérieure du Cybertruck Tactical Grey a obtenu son premier aperçu grâce à une nouvelle chance
 Comment utiliser for pour trouver la factorielle de n en JavaScript
Dec 08, 2021 pm 06:04 PM
Comment utiliser for pour trouver la factorielle de n en JavaScript
Dec 08, 2021 pm 06:04 PM
Comment utiliser for pour trouver n factorielle : 1. Utilisez l'instruction "for (var i=1;i<=n;i++){}" pour contrôler la plage de parcours de la boucle sur "1~n" 2. Dans la boucle ; body, utilisez "cj *=i" Multipliez les nombres de 1 à n et attribuez le produit à la variable cj 3. Une fois la boucle terminée, la valeur de la variable cj est la factorielle de n, puis affichez-la.
 HMD Slate Tab 5G fuit en tant que tablette de milieu de gamme avec Snapdragon 7s Gen 2, écran de 10,6 pouces et design Lumia
Jun 18, 2024 pm 05:46 PM
HMD Slate Tab 5G fuit en tant que tablette de milieu de gamme avec Snapdragon 7s Gen 2, écran de 10,6 pouces et design Lumia
Jun 18, 2024 pm 05:46 PM
Avec le Skyline, HMD Global devrait dévoiler le 10 juillet un smartphone milieu de gamme dans le style du Nokia Lumia 920. Selon les dernières informations du leaker @smashx_60, le design Lumia sera bientôt également utilisé pour une tablette, qui sera c
 Quelle est la différence entre les boucles foreach et for
Jan 05, 2023 pm 04:26 PM
Quelle est la différence entre les boucles foreach et for
Jan 05, 2023 pm 04:26 PM
Différences : 1. for parcourt chaque élément de données via l'index, tandis que forEach parcourt les éléments de données du tableau via le programme sous-jacent JS ; 2. for peut terminer l'exécution de la boucle via le mot-clé break, mais forEach ne le peut pas ; .for peut contrôler l'exécution de la boucle en contrôlant la valeur de la variable de boucle, mais forEach ne peut pas ; 4. for peut appeler des variables de boucle en dehors de la boucle, mais forEach ne peut pas appeler des variables de boucle en dehors de la boucle ; est supérieur à forEach.
 Quelles sont les structures de contrôle de flux courantes en Python ?
Jan 20, 2024 am 08:17 AM
Quelles sont les structures de contrôle de flux courantes en Python ?
Jan 20, 2024 am 08:17 AM
Quelles sont les structures de contrôle de flux courantes en Python ? En Python, la structure de contrôle de flux est un outil important utilisé pour déterminer l'ordre d'exécution du programme. Ils nous permettent d'exécuter différents blocs de code en fonction de différentes conditions, ou d'exécuter un bloc de code de manière répétée. Ce qui suit présentera les structures de contrôle de processus courantes en Python et fournira des exemples de code correspondants. Instructions conditionnelles (if-else) : les instructions conditionnelles nous permettent d'exécuter différents blocs de code en fonction de différentes conditions. Sa syntaxe de base est la suivante : if condition 1 : #when condition
