

HDFS集中式的缓存管理原理与代码剖析

Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。 主要解决了哪些问题 1.用户可
Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。
主要解决了哪些问题
1.用户可以根据自己的逻辑指定一些经常被使用的数据或者高优先级任务对应的数据常驻内存而不被淘汰到磁盘。例如在Hive或Impala构建的数据仓库应用中fact表会频繁地与其他表做JOIN,显然应该让fact常驻内存,这样DataNode在内存使用紧张的时候也不会把这些数据淘汰出去,同时也实现了对于?mixed workloads的SLA。
2.centralized cache是由NameNode统一管理的,那么HDFS client(例如MapReduce、Impala)就可以根据block被cache的分布情况去调度任务,做到memory-locality。
3.HDFS原来单纯靠DataNode的OS buffer cache,这样不但没有把block被cache的分布情况对外暴露给上层应用优化任务调度,也有可能会造成cache浪费。例如一个block的三个replica分别存储在三个DataNote 上,有可能这个block同时被这三台DataNode的OS buffer cache,那么从HDFS的全局看就有同一个block在cache中存了三份,造成了资源浪费。?
4.加快HDFS client读速度。过去NameNode处理读请求时只根据拓扑远近决定去哪个DataNode读,现在还要加入speed的因素。当HDFS client和要读取的block被cache在同一台DataNode的时候,可以通过zero-copy read直接从内存读,略过磁盘I/O、checksum校验等环节。
5.即使数据被cache的DataNode节点宕机,block移动,集群重启,cache都不会受到影响。因为cache被NameNode统一管理并被被持久化到FSImage和EditLog,如果cache的某个block的DataNode宕机,NameNode会调度其他存储了这个replica的DataNode,把它cache到内存。
基本概念
cache directive: 表示要被cache到内存的文件或者目录。
cache pool: 用于管理一系列的cache directive,类似于命名空间。同时使用UNIX风格的文件读、写、执行权限管理机制。命令例子:
hdfs cacheadmin -addDirective -path /user/hive/warehouse/fact.db/city -pool financial -replication 1?
以上代码表示把HDFS上的文件city(其实是hive上的一个fact表)放到HDFS centralized cache的financial这个cache pool下,而且这个文件只需要被缓存一份。
系统架构与原理
 用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
DFSClient读取文件时向NameNode发送getBlockLocations RPC请求。NameNode会返回一个LocatedBlock列表给DFSClient,这个LocatedBlock对象里有这个block的replica所在的DataNode和cache了这个block的DataNode。可以理解为把被cache到内存中的replica当做三副本外的一个高速的replica。
注:centralized cache和distributed cache的区别:
distributed cache将文件分发到各个DataNode结点本地磁盘保存,并且用完后并不会被立即清理的,而是由专门的一个线程根据文件大小限制和文件数目上限周期性进行清理。本质上distributed cache只做到了disk locality,而centralized cache做到了memory locality。
实现逻辑与代码剖析
HDFS centralized cache涉及到多个操作,其处理逻辑非常类似。为了简化问题,以addDirective这个操作为例说明。
1.NameNode处理逻辑
 NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
DFSClient给NameNode发送名为addCacheDirective的RPC, 在ClientNamenodeProtocol.proto这个文件中定义相应的接口。
NameNode接收到这个RPC之后处理,首先把这个需要被缓存的Path包装成CacheDirective加入CacheManager所管理的directivesByPath中。这时对应的File/Directory并没有被cache到内存。
一旦CacheManager那边添加了新的CacheDirective,触发CacheReplicationMonitor.rescan()来扫描并把需要通知DataNode做cache的block加入到CacheReplicationMonitor. cachedBlocks映射中。这个rescan操作在NameNode启动时也会触发,同时在NameNode运行期间以固定的时间间隔触发。
Rescan()函数主要逻辑如下:
rescanCacheDirectives()->rescanFile():依次遍历每个等待被cache的directive(存储在CacheManager. directivesByPath里),把每个等待被cache的directive包含的block都加入到CacheReplicationMonitor.cachedBlocks集合里面。
rescanCachedBlockMap():调用CacheReplicationMonitor.addNewPendingCached()为每个等待被cache的block选择一个合适的DataNode去cache(一般是选择这个block的三个replica所在的DataNode其中的剩余可用内存最多的一个),加入对应的DatanodeDescriptor的pendingCached列表。
2.NameNode与DataNode的RPC逻辑
DataNode定期向NameNode发送heartbeat RPC用于表明它还活着,同时DataNode还会向NameNode定期发送block report(默认6小时)和cache block(默认10秒)用于同步block和cache的状态。
NameNode会在每次处理某一DataNode的heartbeat RPC时顺便检查该DataNode的pendingCached列表是否为空,不为空的话发送DatanodeProtocol.DNA_CACHE命令给具体的DataNode去cache对应的block replica。
3.DataNode处理逻辑
 DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
在DataNode节点上每个BlockPool对应有一个BPServiceActor线程向NameNode发送heartbeat、接收response并处理。如果接收到来自NameNode的RPC里面的命令是DatanodeProtocol.DNA_CACHE,那么调用FsDatasetImpl.cacheBlock()把对应的block cache到内存。
这个函数先是通过RPC传过来的blockId找到其对应的FsVolumeImpl (因为执行cache block操作的线程cacheExecutor是绑定在对应的FsVolumeImpl里的);然后调用FsDatasetCache.cacheBlock()把这个block封装成MappableBlock加入到mappableBlockMap里统一管理起来,然后向对应的FsVolumeImpl.cacheExecutor线程池提交一个CachingTask异步任务(cache的过程是异步执行的)。
FsDatasetCache有个成员mappableBlockMap(HashMap)管理着这台DataNode的所有的MappableBlock及其状态(caching/cached/uncaching)。目前DataNode中”哪些block被cache到内存里了”也是只保存了soft state(和NameNode的block map一样),是DataNode向NameNode 发送heartbeat之后从NameNode那问回来的,没有持久化到DataNode本地硬盘。
CachingTask的逻辑: 调用MappableBlock.load()方法把对应的block从DataNode本地磁盘通过mmap映射到内存中,然后通过mlock锁定这块内存空间,并对这个映射到内存的block做checksum检验其完整性。这样对于memory-locality的DFSClient就可以通过zero-copy直接读内存中的block而不需要校验了。
4.DFSClient读逻辑:
HDFS的读主要有三种: 网络I/O读 -> short circuit read -> zero-copy read。网络I/O读就是传统的HDFS读,通过DFSClient和Block所在的DataNode建立网络连接传输数据。?
当DFSClient和它要读取的block在同一台DataNode时,DFSClient可以跨过网络I/O直接从本地磁盘读取数据,这种读取数据的方式叫short circuit read。目前HDFS实现的short circuit read是通过共享内存获取要读的block在DataNode磁盘上文件的file descriptor(因为这样比传递文件目录更安全),然后直接用对应的file descriptor建立起本地磁盘输入流,所以目前的short circuit read也是一种zero-copy read。
增加了Centralized cache的HDFS的读接口并没有改变。DFSClient通过RPC获取LocatedBlock时里面多了个成员表示哪个DataNode把这个block cache到内存里面了。如果DFSClient和该block被cache的DataNode在一起,就可以通过zero-copy read大大提升读效率。而且即使在读取的过程中该block被uncache了,那么这个读就被退化成了本地磁盘读,一样能够获取数据。?
对上层应用的影响
对于HDFS上的某个目录已经被addDirective缓存起来之后,如果这个目录里新加入了文件,那么新加入的文件也会被自动缓存。这一点对于Hive/Impala式的应用非常有用。
HBase in-memory table:可以直接把某个HBase表的HFile放到centralized cache中,这会显著提高HBase的读性能,降低读请求延迟。
和Spark RDD的区别:多个RDD的之间的读写操作可能完全在内存中完成,出错就重算。HDFS centralized cache中被cache的block一定是先写到磁盘上的,然后才能显式被cache到内存。也就是说只能cache读,不能cache写。
目前的centralized cache不是DFSClient读了谁就会把谁cache,而是需要DFSClient显式指定要cache谁,cache多长时间,淘汰谁。目前也没有类似LRU的置换策略,如果内存不够用的时候需要client显式去淘汰对应的directive到磁盘。
现在还没有跟YARN整合,需要用户自己调整好留给DataNode用于cache的内存和NodeManager的内存使用。
参考文献
http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/CentralizedCacheManagement.html
https://issues.apache.org/jira/browse/HDFS-4949
原文地址:HDFS集中式的缓存管理原理与代码剖析, 感谢原作者分享。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Analyse de la fonction et du principe de nohup
Mar 25, 2024 pm 03:24 PM
Analyse de la fonction et du principe de nohup
Mar 25, 2024 pm 03:24 PM
Analyse du rôle et du principe de nohup Dans les systèmes d'exploitation Unix et de type Unix, nohup est une commande couramment utilisée pour exécuter des commandes en arrière-plan. Même si l'utilisateur quitte la session en cours ou ferme la fenêtre du terminal, la commande peut. continuent toujours à être exécutés. Dans cet article, nous analyserons en détail la fonction et le principe de la commande nohup. 1. Le rôle de nohup : Exécuter des commandes en arrière-plan : Grâce à la commande nohup, nous pouvons laisser les commandes de longue durée continuer à s'exécuter en arrière-plan sans être affectées par la sortie de l'utilisateur de la session du terminal. Cela doit être exécuté
 Comment afficher et actualiser le cache DNS sous Linux
Mar 07, 2024 am 08:43 AM
Comment afficher et actualiser le cache DNS sous Linux
Mar 07, 2024 am 08:43 AM
DNS (DomainNameSystem) est un système utilisé sur Internet pour convertir les noms de domaine en adresses IP correspondantes. Dans les systèmes Linux, la mise en cache DNS est un mécanisme qui stocke localement la relation de mappage entre les noms de domaine et les adresses IP, ce qui peut augmenter la vitesse de résolution des noms de domaine et réduire la charge sur le serveur DNS. La mise en cache DNS permet au système de récupérer rapidement l'adresse IP lors d'un accès ultérieur au même nom de domaine sans avoir à émettre une requête de requête au serveur DNS à chaque fois, améliorant ainsi les performances et l'efficacité du réseau. Cet article expliquera avec vous comment afficher et actualiser le cache DNS sous Linux, ainsi que les détails associés et des exemples de code. Importance de la mise en cache DNS Dans les systèmes Linux, la mise en cache DNS joue un rôle clé. son existence
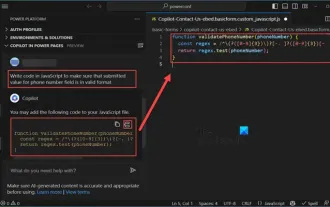 Comment utiliser Copilot pour générer du code
Mar 23, 2024 am 10:41 AM
Comment utiliser Copilot pour générer du code
Mar 23, 2024 am 10:41 AM
En tant que programmeur, je suis enthousiasmé par les outils qui simplifient l'expérience de codage. À l'aide d'outils d'intelligence artificielle, nous pouvons générer du code de démonstration et apporter les modifications nécessaires selon les exigences. Le nouvel outil Copilot dans Visual Studio Code nous permet de créer du code généré par l'IA avec des interactions de chat en langage naturel. En expliquant les fonctionnalités, nous pouvons mieux comprendre la signification du code existant. Comment utiliser Copilot pour générer du code ? Pour commencer, nous devons d’abord obtenir la dernière extension PowerPlatformTools. Pour y parvenir, vous devez vous rendre sur la page de l'extension, rechercher "PowerPlatformTool" et cliquer sur le bouton Installer.
 Créer et exécuter des fichiers Linux '.a'
Mar 20, 2024 pm 04:46 PM
Créer et exécuter des fichiers Linux '.a'
Mar 20, 2024 pm 04:46 PM
Travailler avec des fichiers dans le système d'exploitation Linux nécessite l'utilisation de diverses commandes et techniques qui permettent aux développeurs de créer et d'exécuter efficacement des fichiers, du code, des programmes, des scripts et d'autres éléments. Dans l'environnement Linux, les fichiers portant l'extension « .a » sont d'une grande importance en tant que bibliothèques statiques. Ces bibliothèques jouent un rôle important dans le développement de logiciels, permettant aux développeurs de gérer et de partager efficacement des fonctionnalités communes sur plusieurs programmes. Pour un développement logiciel efficace dans un environnement Linux, il est crucial de comprendre comment créer et exécuter des fichiers « .a ». Cet article explique comment installer et configurer de manière complète le fichier Linux « .a ». Explorons la définition, l'objectif, la structure et les méthodes de création et d'exécution du fichier Linux « .a ». Qu'est-ce que L
 Mécanisme de mise en cache et pratique d'application dans le développement PHP
May 09, 2024 pm 01:30 PM
Mécanisme de mise en cache et pratique d'application dans le développement PHP
May 09, 2024 pm 01:30 PM
Dans le développement PHP, le mécanisme de mise en cache améliore les performances en stockant temporairement les données fréquemment consultées en mémoire ou sur disque, réduisant ainsi le nombre d'accès à la base de données. Les types de cache incluent principalement le cache de mémoire, de fichiers et de bases de données. En PHP, vous pouvez utiliser des fonctions intégrées ou des bibliothèques tierces pour implémenter la mise en cache, telles que cache_get() et Memcache. Les applications pratiques courantes incluent la mise en cache des résultats des requêtes de base de données pour optimiser les performances des requêtes et la mise en cache de la sortie des pages pour accélérer le rendu. Le mécanisme de mise en cache améliore efficacement la vitesse de réponse du site Web, améliore l'expérience utilisateur et réduit la charge du serveur.
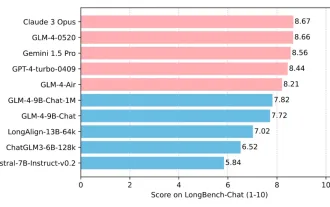 L'Université Tsinghua et Zhipu AI open source GLM-4 : lancent une nouvelle révolution dans le traitement du langage naturel
Jun 12, 2024 pm 08:38 PM
L'Université Tsinghua et Zhipu AI open source GLM-4 : lancent une nouvelle révolution dans le traitement du langage naturel
Jun 12, 2024 pm 08:38 PM
Depuis le lancement du ChatGLM-6B le 14 mars 2023, les modèles de la série GLM ont reçu une large attention et une grande reconnaissance. Surtout après que ChatGLM3-6B soit open source, les développeurs sont pleins d'attentes pour le modèle de quatrième génération lancé par Zhipu AI. Cette attente a finalement été pleinement satisfaite avec la sortie du GLM-4-9B. La naissance du GLM-4-9B Afin de donner aux petits modèles (10B et moins) des capacités plus puissantes, l'équipe technique de GLM a lancé ce nouveau modèle open source de la série GLM de quatrième génération : GLM-4-9B après près de six mois de exploration. Ce modèle compresse considérablement la taille du modèle tout en garantissant la précision, et offre une vitesse d'inférence plus rapide et une efficacité plus élevée. L’exploration de l’équipe technique du GLM n’a pas
 La relation entre CPU, mémoire et cache est expliquée en détail !
Mar 07, 2024 am 08:30 AM
La relation entre CPU, mémoire et cache est expliquée en détail !
Mar 07, 2024 am 08:30 AM
Il existe une interaction étroite entre le CPU (unité centrale de traitement), la mémoire (mémoire vive) et le cache, qui forment ensemble un composant essentiel d'un système informatique. La coordination entre eux assure le fonctionnement normal et les performances efficaces de l'ordinateur. En tant que cerveau de l'ordinateur, le processeur est responsable de l'exécution de diverses instructions et du traitement des données ; la mémoire est utilisée pour stocker temporairement des données et des programmes, offrant des vitesses d'accès en lecture et en écriture rapides et le cache joue un rôle tampon, accélérant l'accès aux données ; vitesse et amélioration Le processeur de l'ordinateur est le composant central de l'ordinateur et est responsable de l'exécution de diverses instructions, opérations arithmétiques et opérations logiques. Il est appelé le « cerveau » de l’ordinateur et joue un rôle important dans le traitement des données et l’exécution des tâches. La mémoire est un périphérique de stockage important dans un ordinateur.
 Créez un agent en une phrase ! Robin Li : L'ère approche où tout le monde sera développeur
Apr 17, 2024 pm 02:28 PM
Créez un agent en une phrase ! Robin Li : L'ère approche où tout le monde sera développeur
Apr 17, 2024 pm 02:28 PM
Le grand modèle bouleverse tout, et arrive finalement à la tête de cet éditeur. C'est aussi un Agent qui a été créé en une seule phrase. Comme ça, donnez-lui un article, et en moins d'une seconde, de nouvelles suggestions de titres sortiront. Par rapport à moi, on ne peut dire que cette efficacité est aussi rapide que l'éclair et aussi lente qu'un paresseux... Ce qui est encore plus incroyable, c'est que la création de cet Agent ne prend en réalité que quelques minutes. L'invite appartient à tante Jiang : Et si vous souhaitez également ressentir ce sentiment subversif, désormais, sur la base de la nouvelle plateforme intelligente Wenxin lancée par Baidu, chacun peut créer gratuitement son propre assistant intelligent. Vous pouvez utiliser les moteurs de recherche, les plates-formes matérielles intelligentes, la reconnaissance vocale, les cartes, les voitures et autres canaux écologiques mobiles Baidu pour permettre à davantage de personnes d'utiliser votre créativité ! Robin Li lui-même
