

搭建Hadoop环境的详细过程

即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们想先搭建hadoop环境,在这个过程中慢慢体会一下hadoop。 我在这里说的是hadoop伪分布式模式(Pseudo-Distributed Mode),其实网上已经有很多教程,在这里我
即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们想先搭建hadoop环境,在这个过程中慢慢体会一下hadoop。
我在这里说的是hadoop伪分布式模式(Pseudo-Distributed Mode),其实网上已经有很多教程,在这里我详详细细的描述整个搭建过程,也算是自己重新回忆一下。
准备阶段(下载地址我这里就不给出了):
Win7旗舰版 Vmware-9.0.2
ubuntu-12.04 hadoop-0.20.2 jdk-8u5-linux-i586-demos
搭建流程:
1、装机阶段:
一、安装Ubuntu操作系统
二、在Ubuntu下创建hadoop用户组和用户
三、在Ubuntu下安装JDK
四、修改机器名
五、安装ssh服务
六、建立ssh无密码登录本机
七、安装hadoop
八、在单机上运行hadoop
一、安装Ubuntu操作系统
略……
二、在Ubuntu下创建hadoop用户组和用户
(1)安装Ubuntu时已经建立了一个用户,但是为了以后Hadoop操作,专门渐建立一个hadoop用户组和hadoop用户。

(2)给hadoop用户添加权限,打开/etc/sudoers文件。
sudo gedit /etc/sudoers
打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。在
root ALL=(ALL:ALL) ALL
下添加:
hadoop ALL=(ALL:ALL) ALL
三、在Ubuntu下安装JDK
1、创建JDK安装目录
(1)由于我使用的是VMware安装的Ubuntu系统,设置本地thisceshi文件夹共享到Ubuntu系统,指定的安装目录是:/usr/local/java。可是系统安装后在/usr/local下并没有java目录,这需要我们去创建一个java文件夹,
进入/usr/local文件夹
cd /usr/local
创建java文件夹,
sudo mkdir /usr/local/java
(2)解压JDK到目标目录
进入共享文件夹thisceshi,
cd /mnt/hgfs/thisceshi
然后进入到共享文件夹中,继续我们解压JDK到之前建好的java文件夹中,
sudo cp jdk-8u5-linux-i586-demos.tar.gz /usr/local/java
2、安装jdk
(1)切换到root用户下,
hadoop@s15:/mnt/hgfs/thisceshi$ su 密码:
(2)解压jdk-8u5-linux-i586-demos.tar.gz
sudo tar -zxf jdk-8u5-linux-i586-demos.tar.gz
此时java目录中多了一个jdk1.6.0_30文件夹。
3、配置环境变量
(1)打开/etc/profile文件,
sudo gedit /etc/profile
(2)添加变量,
#set java environment export JAVA_HOME=/usr/local/java/jdk1.6.0_30 export JRE_HOME=/usr/local/java/jdk1.6.0_30/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
一般更改/etc/profile文件后,需要重启机器才能生效,在这里我们可以使用如下指令可使配置文件立即生效,
source /etc/profile
(3)查看java环境变量是否配置成功,
java -version
显示如下:
java version "1.6.0_30" Java(TM) SE Runtime Environment (build 1.6.0_30-b12) Java HotSpot(TM) Client VM (build 20.5-b03, mixed mode, sharing)
但是在root下一切正常,在hadoop用户下就出现了问题,
程序“java”已包含在下列软件包中: * gcj-4.4-jre-headless * openjdk-6-jre-headless * cacao * gij-4.3 * jamvm
在终端中我们分别运行下面指令,
sudo update-alternatives --install /usr/bin/java java /usr/local/java/jdk1.6.0_30/bin/java 300 sudo update-alternatives --install /usr/bin/javac javac /usr/local/java/jdk1.6.0_30/bin/javac 300
问题解决。
四、修改机器名
当ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。这是我开始是根据网上教程也给修改了,其实伪分布式搭建的时候,可以省了,不然还造成一些不必要的麻烦。
1、打开/etc/hostname文件,运行指令,
sudo gedit /etc/hostname
2、然后hostname中添加s15五、安装ssh服务保存退出,即s15是当前用户别名。在这里需要重启系统后才会生效。
hadoop@s15:~$
五、安装ssh服务
1、安装openssh-server
sudo apt-get install openssh-server
2、等待安装,即可。



六、 建立ssh无密码登录本机
在这里,我自己还是模模糊糊的。
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1、创建ssh-key,,这里我们采用rsa方式,
ssh-keygen -t rsa -P ''
网上教程中后面是双引号,我在执行出现错误,换成单引号,则可以执行。

进入ssh,查看里面文件
hadoop@s15:~$ cd .ssh hadoop@s15:~/.ssh$ ls id_rsa id_rsa.pub
2、进入~/.ssh/目录下,将idrsa.pub追加到authorizedkeys授权文件中,开始是没有authorized_keys文件的,
cat id_rsa.pub >> authorized_keys
3、登录localhost,
hadoop@s15:~/.ssh$ ssh localhost Welcome to Ubuntu 12.04 LTS (GNU/Linux 3.2.0-61-generic-pae i686) * Documentation: https://help.ubuntu.com/ 663 packages can be updated. 266 updates are security updates. Last login: Sat May 10 13:08:03 2014 from localhost
4、执行退出命令,
hadoop@s15:~$ exit 登出 Connection to localhost closed.
七、安装hadoop
1、从共享文件夹thisceshi中将hadoop-0.20.2.tar.gz复制到安装目录 /usr/local/下
2、解压hadoop-0.20.203.tar.gz,
3、将解压出的文件夹改名为hadoop,
4、将该hadoop文件夹的属主用户设为hadoop,
sudo chown -R hadoop:hadoop hadoop
5、打开hadoop/conf/hadoop-env.sh文件,
6、配置conf/hadoop-env.sh(找到#export JAVA_HOME=…,去掉#,然后加上本机jdk的路径)
# The java implementation to use. Required. export JAVA_HOME=/usr/local/java/jdk1.6.0_30 export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:/usr/local/hadoop/bin
让环境立即生效,
source /usr/local/hadoop/conf/hadoop-env.sh
7、打开conf/core-site.xml文件,编辑如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://www.cndwzone.com/archives/configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> fs.default.name hdfs://localhost:9000
8、打开conf/mapred-site.xml文件,编辑如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://www.cndwzone.com/archives/configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> mapred.job.tracker localhost:9001
9、打开conf/hdfs-site.xml文件,编辑如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://www.cndwzone.com/archives/configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> dfs.name.dir /usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2 dfs.data.dir /usr/local/hadoop/data1,/usr/local/hadoop/data2 dfs.replication 2
10、打开conf/masters文件,添加作为secondarynamenode的主机名,因为是伪分布式,只有一个节点,这里只需填写localhost就可以。
11、打开conf/slaves文件,添加作为slave的主机名,一行一个。因为是伪分布式,只有一个节点,这里也只需填写localhost就可以。
八、在单机上运行hadoop
1、进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作,当你看到下图时,就说明你的hdfs文件系统格式化成功了。

3、进入bin目录启动start-all.sh,
4、检测hadoop是否启动成功,

到此,hadoop伪分布式环境搭建完成。
在搭建过程中可能会遇到各种问题,到时大家不用着急,可以谷歌,百度一下。解决问题的过程就是加深学习的过程。我当时都忘了花了多久才将环境搭建好,最初的时候,连最基本的指令也不懂,也不知道怎么运行。我在这里说出来就是想说,开始的一无所知不要害怕,慢慢来就好,在那么一刻你就会有所知,有所明白。之后的文章中会介绍在hadoop环境下运行WordCount,hadoop中的HelloWorld。
 即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们 […]
即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们 […]

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Impossible de démarrer dans l'environnement de récupération Windows
Feb 19, 2024 pm 11:12 PM
Impossible de démarrer dans l'environnement de récupération Windows
Feb 19, 2024 pm 11:12 PM
L'environnement de récupération Windows (WinRE) est un environnement utilisé pour réparer les erreurs du système d'exploitation Windows. Après avoir entré WinRE, vous pouvez effectuer une restauration du système, une réinitialisation d'usine, désinstaller les mises à jour, etc. Si vous ne parvenez pas à démarrer WinRE, cet article vous guidera à travers les correctifs pour résoudre le problème. Impossible de démarrer dans l'environnement de récupération Windows Si vous ne pouvez pas démarrer dans l'environnement de récupération Windows, utilisez les correctifs fournis ci-dessous : Vérifiez l'état de l'environnement de récupération Windows Utilisez d'autres méthodes pour accéder à l'environnement de récupération Windows Avez-vous accidentellement supprimé la partition de récupération Windows ? Effectuez une mise à niveau sur place ou une nouvelle installation de Windows ci-dessous, nous avons expliqué tous ces correctifs en détail. 1] Vérifiez le Wi-Fi
 Quelles sont les différences entre Python et Anaconda ?
Sep 06, 2023 pm 08:37 PM
Quelles sont les différences entre Python et Anaconda ?
Sep 06, 2023 pm 08:37 PM
Dans cet article, nous découvrirons les différences entre Python et Anaconda. Qu’est-ce que Python ? Python est un langage open source qui met l'accent sur la facilité de lecture et de compréhension du code en indentant les lignes et en fournissant des espaces. La flexibilité et la facilité d'utilisation de Python le rendent idéal pour une variété d'applications, notamment le calcul scientifique, l'intelligence artificielle et la science des données, ainsi que pour la création et le développement d'applications en ligne. Lorsque Python est testé, il est immédiatement traduit en langage machine car il s’agit d’un langage interprété. Certains langages, comme le C++, nécessitent une compilation pour être compris. La maîtrise de Python est un avantage important car il est très facile à comprendre, développer, exécuter et lire. Cela rend Python
 Erreurs Java : erreurs Hadoop, comment les gérer et les éviter
Jun 24, 2023 pm 01:06 PM
Erreurs Java : erreurs Hadoop, comment les gérer et les éviter
Jun 24, 2023 pm 01:06 PM
Erreurs Java : erreurs Hadoop, comment les gérer et les éviter Lorsque vous utilisez Hadoop pour traiter des données volumineuses, vous rencontrez souvent des erreurs d'exception Java, qui peuvent affecter l'exécution des tâches et provoquer l'échec du traitement des données. Cet article présentera quelques erreurs Hadoop courantes et fournira des moyens de les gérer et de les éviter. Java.lang.OutOfMemoryErrorOutOfMemoryError est une erreur provoquée par une mémoire insuffisante de la machine virtuelle Java. Quand Hadoop est
 Comment créer rapidement un système de graphiques statistiques sous le framework Vue
Aug 21, 2023 pm 05:48 PM
Comment créer rapidement un système de graphiques statistiques sous le framework Vue
Aug 21, 2023 pm 05:48 PM
Comment créer rapidement un système de graphiques statistiques sous le framework Vue. Dans les applications Web modernes, les graphiques statistiques sont un composant essentiel. En tant que framework frontal populaire, Vue.js fournit de nombreux outils et composants pratiques qui peuvent nous aider à créer rapidement un système de graphiques statistiques. Cet article expliquera comment utiliser le framework Vue et certains plug-ins pour créer un système de graphiques statistiques simple. Tout d'abord, nous devons préparer un environnement de développement Vue.js, y compris l'installation de l'échafaudage Vue et de certains plug-ins associés. Exécutez la commande suivante dans la ligne de commande
 Peut-on construire des bâtiments à l'état sauvage dans Mistlock Kingdom ?
Mar 07, 2024 pm 08:28 PM
Peut-on construire des bâtiments à l'état sauvage dans Mistlock Kingdom ?
Mar 07, 2024 pm 08:28 PM
Les joueurs peuvent collecter différents matériaux pour construire des bâtiments lorsqu'ils jouent dans le Royaume de Mistlock. De nombreux joueurs veulent savoir si les bâtiments ne peuvent pas être construits à l'état sauvage dans le Royaume de Mistlock. . Des bâtiments peuvent-ils être construits à l’état sauvage dans Mistlock Kingdom Réponse : Non. 1. Les bâtiments ne peuvent pas être construits dans les zones sauvages du Royaume de Mist Lock. 2. Le bâtiment doit être construit dans le cadre de l'autel. 3. Les joueurs peuvent placer eux-mêmes l'Autel du Feu Spirituel, mais une fois qu'ils auront quitté le champ de tir, ils ne pourront plus construire de bâtiments. 4. Nous pouvons également creuser directement un trou dans la montagne pour en faire notre maison, nous n’avons donc pas besoin de consommer de matériaux de construction. 5. Il existe un mécanisme de confort dans les bâtiments construits par les joueurs eux-mêmes, c'est-à-dire que plus l'intérieur est bon, plus le confort est élevé. 6. Un confort élevé apportera des bonus d'attributs aux joueurs, tels que
 Utilisation de Hadoop et HBase dans Beego pour le stockage et les requêtes Big Data
Jun 22, 2023 am 10:21 AM
Utilisation de Hadoop et HBase dans Beego pour le stockage et les requêtes Big Data
Jun 22, 2023 am 10:21 AM
Avec l'avènement de l'ère du Big Data, le traitement et le stockage des données sont devenus de plus en plus importants, et la gestion et l'analyse efficaces de grandes quantités de données sont devenues un défi pour les entreprises. Hadoop et HBase, deux projets de la Fondation Apache, proposent une solution de stockage et d'analyse du Big Data. Cet article explique comment utiliser Hadoop et HBase dans Beego pour le stockage et les requêtes Big Data. 1. Introduction à Hadoop et HBase Hadoop est un système informatique et de stockage distribué open source qui peut
 Bonnes pratiques et précautions pour créer un serveur Web sous CentOS 7
Aug 25, 2023 pm 11:33 PM
Bonnes pratiques et précautions pour créer un serveur Web sous CentOS 7
Aug 25, 2023 pm 11:33 PM
Meilleures pratiques et précautions pour la création de serveurs Web sous CentOS7 Introduction : À l'ère d'Internet d'aujourd'hui, les serveurs Web sont l'un des composants essentiels pour la création et l'hébergement de sites Web. CentOS7 est une puissante distribution Linux largement utilisée dans les environnements serveur. Cet article explorera les meilleures pratiques et considérations pour la création d'un serveur Web sur CentOS7 et fournira quelques exemples de code pour vous aider à mieux comprendre. 1. Installer le serveur HTTP Apache Apache est le serveur le plus utilisé
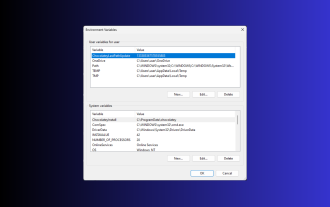 11 façons de définir des variables d'environnement sur Windows 3
Sep 15, 2023 pm 12:21 PM
11 façons de définir des variables d'environnement sur Windows 3
Sep 15, 2023 pm 12:21 PM
La définition de variables d'environnement sur Windows 11 peut vous aider à personnaliser votre système, à exécuter des scripts et à configurer des applications. Dans ce guide, nous aborderons trois méthodes ainsi que des instructions étape par étape afin que vous puissiez configurer votre système à votre guise. Il existe trois types de variables d'environnement Variables d'environnement système : les variables globales ont la priorité la plus basse et sont accessibles à tous les utilisateurs et applications sous Windows et sont généralement utilisées pour définir les paramètres à l'échelle du système. Variables d'environnement utilisateur – Priorité plus élevée, ces variables s'appliquent uniquement à l'utilisateur actuel et au processus exécuté sous ce compte, et sont définies par l'utilisateur ou l'application exécuté sous ce compte. Variables d'environnement de processus - ont la priorité la plus élevée, elles sont temporaires et s'appliquent au processus en cours et à ses sous-processus, fournissant ainsi au programme
