

MS SQL 排序规则总结

排序规则术语 什么是排序规则呢? 排序规则根据特定语言和区域设置标准指定对字符串数据进行排序和比较的规则。SQL Server 支持在单个数据库中存储具有不同排序规则的对象。MSDN解释:在 Microsoft SQL Server 中,字符串的物理存储由排序规则控制。排序规则
排序规则术语
什么是排序规则呢? 排序规则根据特定语言和区域设置标准指定对字符串数据进行排序和比较的规则。SQL Server 支持在单个数据库中存储具有不同排序规则的对象。MSDN解释:在 Microsoft SQL Server 中,字符串的物理存储由排序规则控制。排序规则指定表示每个字符的位模式以及存储和比较字符所使用的规则
当 Transact-SQL 语句在具有不同排序规则设置的不同数据库上下文中运行时,其运行结果可能会不同。如果可能,请为您的组织使用标准化排序规则。这样就不必显式指定每个字符或 Unicode 表达式中的排序规则。如果必须使用具有不同排序规则和代码页设置的对象,请对查询进行编码,以考虑排序规则的优先顺序规则。
排序规则指定了表示每个字符的位模式。它还指定了用于排序和比较字符的规则。排序规则的特征是区分语言、区分大小写、区分重音、区分假名以及区分全半角。如下所示:
Chinese_PRC_CI_AS 前半部份:指UNICODE字符集,Chinese_PRC_指针对大陆简体字UNICODE的排序规则,CI表示不区分大小写,AS表示区分重音。
排序规则的后半部份即后缀 含义:
_BIN 指定使用向后兼容的二进制排序顺序。
_BIN2 指定使用 SQL Server 2005 中引入的码位比较语义的二进制排序顺序。
_Stroke 按笔划排序
_CI(CS) 是否区分大小写,CI不区分,CS区分(case-insensitive/case-sensitive)
_AI(AS) 是否区分重音,AI不区分,AS区分(accent-insensitive/accent-sensitive)
_KI(KS) 是否区分假名类型,KI不区分,KS区分(kanatype-insensitive/kanatype-sensitive)
_WI(WS) 是否区分全半角, WI不区分,WS区分(width-insensitive/width-sensitive)
区分大小写:如果想让比较将大写字母和小写字母视为不等,请选择该选项。
区分重音:如果想让比较将重音和非重音字母视为不等,请选择该选项。如果选择该选项,
比较还将重音不同的字母视为不等。
区分假名:如果想让比较将片假名和平假名日语音节视为不等,请选择该选项。
区分宽度:如果想让比较将半角字符和全角字符视为不等,请选择该选项。
查看数据库支持哪些排序规则可以通过下面系统函数查看:
select * from ::fn_helpcollations();
排序规则类型
SQL Server 提供了两组排序规则:Windows 排序规则和 SQL Server 排序规则。具体参考MSDN,这里不做过多赘述。
查看服务器排序规则
SELECT SERVERPROPERTY(N'Collation')
查看数据库排序规则
SQL 1: , ) SQL 2: , collation_name sys.databases;
查看列排序规则
SQL 1:
SELECT c.object_id, c.name, t.name, c.collation_name FROM sys.columns c LEFT JOIN sys.types t on t.system_type_id = c.system_type_id ();
修改服务器排序规则
修改服务器的排序规则的原因千差万别,大部分情况是由于安装的时候,忽略了服务器排序规则这个选项设定,没有事前规划好,等到将数据库还原或迁移到新服务器上,测试过程中才发现问题。
修改服务器排序规则,其实是重新生成 master、model、msdb 和 tempdb 系统数据库时,将删除这些系统数据库,然后在默认位置重新创建。 如果在重新生成语句中指定了新排序规则,则将使用该排序规则设置创建系统数据库。 用户对这些数据库所做的所有修改都会丢失。 例如,账号信息、作业、链接服务器等等。
MSDN关于设置和更改服务器排序规则
SQL 2005
start /wait setup.exe /qb INSTANCENAME=MSSQLSERVER REINSTALL=SQL_Engine REBUILDDATABASE=1 SAPWD=test SQLCOLLATION=SQL_Latin1_General_CP1_CI_AI
SQL 2008
Setup /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=InstanceName /SQLSYSADMINACCOUNTS=accounts /[ SAPWD= StrongPassword ] /SQLCOLLATION=CollationName

服务器排序规则修改起来看似很简单,其实不然,一不小心,就会让你万劫不复。我在实践中就碰到过一次疏忽了某个步骤,结果让我惊出一身冷汗。下面是我自己实施的步骤:
Step 1: 首先备份数据库(包括系统数据库和用户数据库)。记得千万不要漏掉了系统数据库备份。有备才能无患,否则每一步操作,你总要提心吊胆。
Step 2: 在文档上记录下你修改过的一些服务器配置值。例如,在SQL SERVER 2008中,你有可能启用backup compression default ;在某个32位数据库开启了awe enabled 选项,那么修改服务器排序规则后,你需要重新应用、配置这些值。以免遗漏,导致数据库性能等问题。
Step 3:记录一下系统数据库的数据文件和日志文件的所在路径。 重新生成系统数据库会将所有系统数据库安装到其原位置。 如果你没有移动过系统数据库数据库文件或日志文件,这部可以忽略,,像很多时候,为了I/O性能等原因,可能移动过这些系统数据库文件和日志文件。
Step 4: 用文档将登录名(logins)和相关密码整理出来。因为修改服务器排序规则,实则重建系统数据库master、msdb、tempd等,登录名等信息会全部没有,需要重新创建、配置。
Step 5: 生成已有作业的SQL脚本。方便修改服务器排序规则后,重新创建、部署作业。道理同上。
Step 6: 生成已有链接服务器的排序规则,方便修改服务器排序规则后,重新创建、部署链接服务器。道理同上。
Step 7: 整理一下数据库邮件配置文件和已经创建的账号,方便修改服务器排序规则后,重新配置。
Step 8: 如果在实例上有配置发布—订阅等,那么也需要整理这些相关的脚本、文档。
Step 9: 分离用户创建的数据库(这一步其实没有必要)。
Step 10:修改服务器排序规则
Step 11: 附加Step 9分离的数据库。
Step 12:解决孤立账号、配置作业、链接服务器…..
当然,看似简单的操作过程,其实在不同的环境下,你总会遇到一些意外情况
例1:
D:\软件工具\SQL SERVER 2008>Setup /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=M
SSQLSERVER /SQLSYSADMINACCOUNTS=sa /SAPWD=123456 /SQLCOLLATION=SQL_Latin1_General_CP1_CI_AS
Microsoft (R) SQL Server 2008
The following error occurred:
指定的 sa 密码不满足强密码要求。有关强密码要求的更多信息,请参见安装程序帮助或 SQL Server 2008 联机丛书中的“数据库引擎配置 - 帐户设置”。
Error result: -2068578304
Result facility code: 1204
Result error code: 0
Please review the summary.txt log for further details

这个需要你修改sa的密码,满足强密码要求就可解决这个问题。
例2: 不小心将/SAPWD中间多了几个空格,结果报如下错误。

例3:附加数据库时,没有用sa账号,而是用sa创建的windows 身份登录验证账号附加数据库,结果报如下错误,改用sa账号附加,问题解决

另外以前也碰到过两个异常情况,一下子很难重现,以后遇到在补上。


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



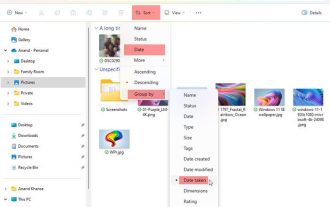 Comment trier les photos par date prise sous Windows 11/10
Feb 19, 2024 pm 08:45 PM
Comment trier les photos par date prise sous Windows 11/10
Feb 19, 2024 pm 08:45 PM
Cet article explique comment trier les images en fonction de la date de prise de vue dans Windows 11/10 et explique également ce qu'il faut faire si Windows ne trie pas les images par date. Dans les systèmes Windows, organiser correctement les photos est crucial pour faciliter la recherche des fichiers image. Les utilisateurs peuvent gérer des dossiers contenant des photos en fonction de différentes méthodes de tri telles que la date, la taille et le nom. De plus, vous pouvez définir l'ordre croissant ou décroissant selon vos besoins pour organiser les fichiers de manière plus flexible. Comment trier les photos par date de prise sous Windows 11/10 Pour trier les photos par date de prise sous Windows, procédez comme suit : Ouvrez Images, Bureau ou tout dossier dans lequel vous placez des photos. Dans le menu du ruban, cliquez sur
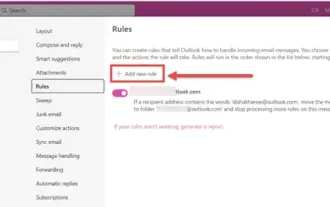 Comment trier les e-mails par expéditeur, sujet, date, catégorie, taille dans Outlook
Feb 19, 2024 am 10:48 AM
Comment trier les e-mails par expéditeur, sujet, date, catégorie, taille dans Outlook
Feb 19, 2024 am 10:48 AM
Outlook propose de nombreux paramètres et fonctionnalités pour vous aider à gérer votre travail plus efficacement. L’une d’elles est l’option de tri qui vous permet de classer vos emails en fonction de vos besoins. Dans ce didacticiel, nous allons apprendre à utiliser la fonction de tri d'Outlook pour organiser les e-mails en fonction de critères tels que l'expéditeur, l'objet, la date, la catégorie ou la taille. Cela vous permettra de traiter et de trouver plus facilement des informations importantes, ce qui vous rendra plus productif. Microsoft Outlook est une application puissante qui facilite la gestion centralisée de vos plannings de messagerie et de calendrier. Vous pouvez facilement envoyer, recevoir et organiser des e-mails, tandis que la fonctionnalité de calendrier intégrée facilite le suivi de vos événements et rendez-vous à venir. Comment être dans Outloo
 Filtrage et tri des données XML à l'aide de Python
Aug 07, 2023 pm 04:17 PM
Filtrage et tri des données XML à l'aide de Python
Aug 07, 2023 pm 04:17 PM
Implémentation du filtrage et du tri des données XML à l'aide de Python Introduction : XML est un format d'échange de données couramment utilisé qui stocke les données sous forme de balises et d'attributs. Lors du traitement de données XML, nous devons souvent filtrer et trier les données. Python fournit de nombreux outils et bibliothèques utiles pour traiter les données XML. Cet article explique comment utiliser Python pour filtrer et trier les données XML. Lecture du fichier XML Avant de commencer, nous devons lire le fichier XML. Python possède de nombreuses bibliothèques de traitement XML,
 Développement PHP : Comment implémenter les fonctions de tri et de pagination des données des tables
Sep 20, 2023 am 11:28 AM
Développement PHP : Comment implémenter les fonctions de tri et de pagination des données des tables
Sep 20, 2023 am 11:28 AM
Développement PHP : comment implémenter des fonctions de tri et de pagination des données de table Dans le développement Web, le traitement de grandes quantités de données est une tâche courante. Pour les tableaux devant afficher une grande quantité de données, il est généralement nécessaire de mettre en œuvre des fonctions de tri et de pagination des données pour offrir une bonne expérience utilisateur et optimiser les performances du système. Cet article explique comment utiliser PHP pour implémenter les fonctions de tri et de pagination des données de table et donne des exemples de code spécifiques. La fonction de tri implémente la fonction de tri dans le tableau, permettant aux utilisateurs de trier par ordre croissant ou décroissant selon différents champs. Ce qui suit est un formulaire de mise en œuvre
 Résumer l'utilisation de la fonction system() dans le système Linux
Feb 23, 2024 pm 06:45 PM
Résumer l'utilisation de la fonction system() dans le système Linux
Feb 23, 2024 pm 06:45 PM
Résumé de la fonction system() sous Linux Dans le système Linux, la fonction system() est une fonction très couramment utilisée, qui permet d'exécuter des commandes en ligne de commande. Cet article présentera la fonction system() en détail et fournira quelques exemples de code spécifiques. 1. Utilisation de base de la fonction system(). La déclaration de la fonction system() est la suivante : intsystem(constchar*command) où le paramètre de commande est un caractère.
 Comment la méthode Arrays.sort() en Java trie-t-elle les tableaux par comparateur personnalisé ?
Nov 18, 2023 am 11:36 AM
Comment la méthode Arrays.sort() en Java trie-t-elle les tableaux par comparateur personnalisé ?
Nov 18, 2023 am 11:36 AM
Comment la méthode Arrays.sort() en Java trie-t-elle les tableaux par comparateur personnalisé ? En Java, la méthode Arrays.sort() est une méthode très utile pour trier les tableaux. Par défaut, cette méthode trie par ordre croissant. Mais parfois, nous devons trier le tableau selon nos propres règles définies. À ce stade, vous devez utiliser un comparateur personnalisé (Comparator). Un comparateur personnalisé est une classe qui implémente l'interface Comparator.
 Programme C++ : réorganiser la position des mots par ordre alphabétique
Sep 01, 2023 pm 11:37 PM
Programme C++ : réorganiser la position des mots par ordre alphabétique
Sep 01, 2023 pm 11:37 PM
Dans ce problème, une chaîne est donnée en entrée et nous devons trier les mots apparaissant dans la chaîne par ordre lexicographique. Pour ce faire, nous attribuons un index commençant à 1 à chaque mot de la chaîne (séparés par des espaces) et obtenons le résultat sous forme d'index triés. String={"Hello","World"}"Hello"=1 "World"=2 Puisque les mots dans la chaîne d'entrée sont dans l'ordre lexicographique, la sortie imprimera "12". Examinons quelques scénarios d'entrée/résultat - en supposant que tous les mots de la chaîne d'entrée sont identiques, regardons les résultats - Entrée :{"hello","hello","hello"}Résultat : 3 Résultat obtenu
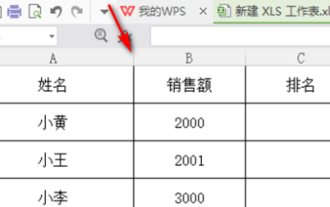 Comment trier les scores WPS
Mar 20, 2024 am 11:28 AM
Comment trier les scores WPS
Mar 20, 2024 am 11:28 AM
Dans notre travail, nous utilisons souvent le logiciel wps. Il existe de nombreuses façons de traiter les données dans le logiciel wps, et les fonctions sont également très puissantes. Nous utilisons souvent des fonctions pour trouver des moyennes, des résumés, etc. des méthodes qui peuvent être utilisées pour les données statistiques ont été préparées pour tout le monde dans la bibliothèque du logiciel WPS. Ci-dessous, nous présenterons les étapes à suivre pour trier les scores dans WPS. Après avoir lu ceci, vous pourrez tirer les leçons de cette expérience. 1. Ouvrez d’abord le tableau qui doit être classé. Comme indiqué ci-dessous. 2. Entrez ensuite la formule =rank(B2, B2 : B5, 0) et assurez-vous de saisir 0. Comme indiqué ci-dessous. 3. Après avoir saisi la formule, appuyez sur la touche F4 du clavier de l'ordinateur. Cette étape consiste à changer la référence relative en référence absolue.
