

NodeJS的url截取模块url-extract的使用实例_基础知识

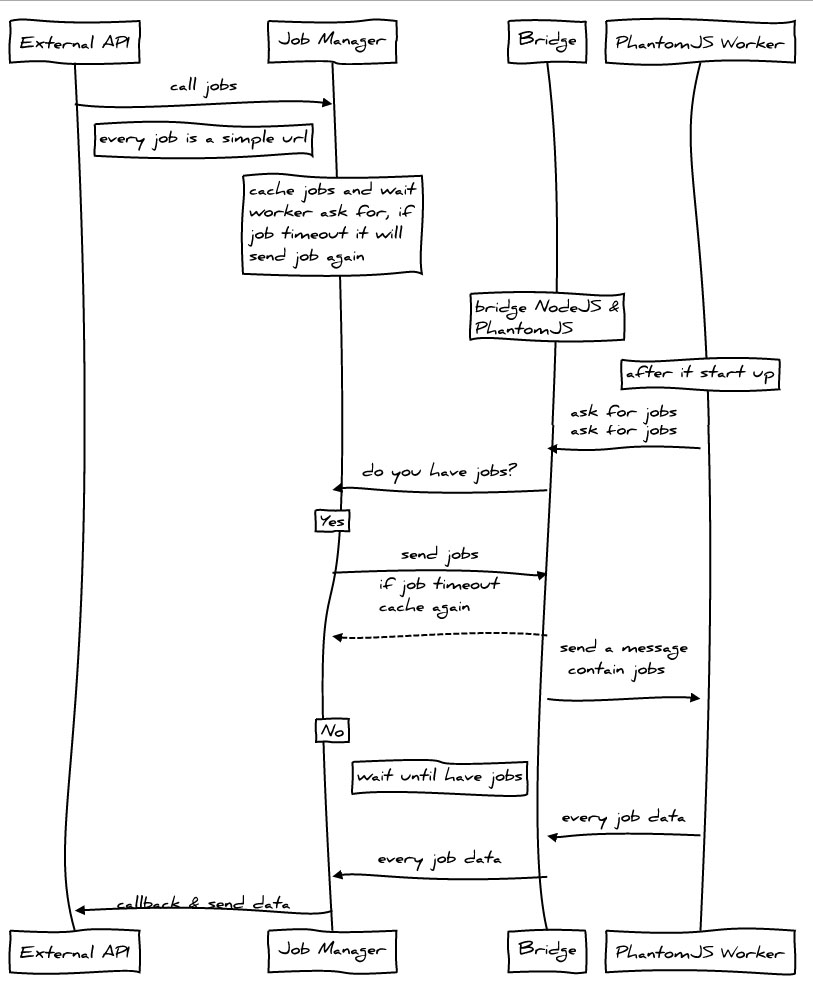
上次介绍了怎么利用NodeJS + PhantomJS进行截图,但由于对每次截图操作,都启用了一个PhantomJS进程,所以并发量上去后,效率堪忧,所以我们重写了所有代码,并将其独立成为一个模块,方便调用。
如何改进?控制线程数,以及单线程处理url数量。使用Standard Output & WebSocket 进行通讯。添加缓存机制,目前使用Javascript Object进行。对外提供简易的接口。
设计图
依赖 & 安装
由于PhantomJS 1.9.0+才开始支持Websocket,所以我们先要确定在PATH中的PhantomJS是为1.9.0以上版本。在命令行键入:
$ phantomjs -v
如果能返回版本号1.9.x,则可以继续操作。如果版本过低,或者出现错误,请到PhantomJS官网下载最新版本。
如果你已经安装了Git,或者拥有Git Shell,那么在命令行键入:
$ npm install url-extract
进行安装。
一个简单的例子
比如我们要截取百度首页,那么可以这样:
下面是打印:

其中,image属性就是截图相对于工作路径的地址。我们可以使用Job的getData接口来得到更清楚的数据,例如:
打印就变成了这样了:

image表示截图相对于工作路径的地址,status表示状态是否正常,true代表正常,false代表截图失败。
更多例子请参见:https://github.com/miniflycn/url-extract/tree/master/examples
主要API
.snapshot
url快照
.snapshot(url, [callback]).snapshot(urls, [callback]).snapshot(url, [option]).snapshot(urls, [option])复制代码 代码如下:url {String} 要截取的地址 urls {Array} 要截取的地址数组 callback {Function} 回调函数 option {Object} 可选参数 ┝ id {String} 自定义url的id,如果第一个参数是urls,此参数无效 ┝ image {String} 自定义截图的保存地址,如果第一个参数是urls,此参数无效 ┝ groupId {String} 定义一组url的groupId,用于返回时候辨认是哪一组url ┝ ignoreCache {Boolean} 是否忽略缓存 ┗ callback {Function} 回调函数.extract
url信息抓取,并获取快照
.extract(url, [callback]).extract(urls, [callback]).extract(url, [option]).extract(urls, [option])url {String} 要截取的地址
urls {Array} 要截取的地址数组
callback {Function} 回调函数
option {Object} 可选参数
┝ id {String} 自定义url的id,如果第一个参数是urls,此参数无效
┝ image {String} 自定义截图的保存地址,如果第一个参数是urls,此参数无效
┝ groupId {String} 定义一组url的groupId,用于返回时候辨认是哪一组url
┝ ignoreCache {Boolean} 是否忽略缓存
┗ callback {Function} 回调函数
Job(类)
每一个url对应一个job对象,url的相关信息由job对象存储。
Field
url {String} 链接地址content {Boolean} 是否抓取页面的title和description信息id {String} job的idgroupId {String} 一堆job的组idcache {Boolean} 是否开启缓存callback {Function} 回调函数image {String} 图片地址status {Boolean} job当前是否正常Prototype
getData() 获取job的相关数据全局配置
url-extract根目录中的config文件可以进行全局配置,默认如下:
module.exports = { wsPort: 3001, maxJob: 100, maxQueueJob: 400, cache: 'object', maxCache: 10000, workerNum: 0};Copier après la connexionwsPort {Number} websocket占用的端口地址maxJob {Number} 每个PhantomJS线程可并发worker数maxQueueJob {Number} 最大等待工作数量,0表示不限制,超过该数量,任何工作都直接返回失败(即status = false)cache {String} 缓存实现,目前只有object实现maxCache {Number} 最大缓存链接数workerNum {Number} PhantomJS线程数,0表示和CPU数量相同一个简单的服务例子
https://github.com/miniflycn/url-extract-server-example
注意,需要安装connect和url-extract:
$ npm install
如果你下载了网盘的文件,那么请安装connect:
$ npm install connect
然后键入:
$ node bin/server
打开:
查看效果。
;

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Que dois-je faire si je rencontre l'impression de code brouillé pour les reçus en papier thermique frontal?
Apr 04, 2025 pm 02:42 PM
Que dois-je faire si je rencontre l'impression de code brouillé pour les reçus en papier thermique frontal?
Apr 04, 2025 pm 02:42 PM
Des questions et des solutions fréquemment posées pour l'impression de billets thermiques frontaux pour le développement frontal, l'impression de billets est une exigence commune. Cependant, de nombreux développeurs mettent en œuvre ...
 Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Il n'y a pas de salaire absolu pour les développeurs Python et JavaScript, selon les compétences et les besoins de l'industrie. 1. Python peut être davantage payé en science des données et en apprentissage automatique. 2. JavaScript a une grande demande dans le développement frontal et complet, et son salaire est également considérable. 3. Les facteurs d'influence comprennent l'expérience, la localisation géographique, la taille de l'entreprise et les compétences spécifiques.
 Comment fusionner les éléments du tableau avec le même ID dans un seul objet en utilisant JavaScript?
Apr 04, 2025 pm 05:09 PM
Comment fusionner les éléments du tableau avec le même ID dans un seul objet en utilisant JavaScript?
Apr 04, 2025 pm 05:09 PM
Comment fusionner les éléments du tableau avec le même ID dans un seul objet en JavaScript? Lors du traitement des données, nous rencontrons souvent la nécessité d'avoir le même ID ...
 Démystifier javascript: ce qu'il fait et pourquoi c'est important
Apr 09, 2025 am 12:07 AM
Démystifier javascript: ce qu'il fait et pourquoi c'est important
Apr 09, 2025 am 12:07 AM
JavaScript est la pierre angulaire du développement Web moderne, et ses principales fonctions incluent la programmation axée sur les événements, la génération de contenu dynamique et la programmation asynchrone. 1) La programmation axée sur les événements permet aux pages Web de changer dynamiquement en fonction des opérations utilisateur. 2) La génération de contenu dynamique permet d'ajuster le contenu de la page en fonction des conditions. 3) La programmation asynchrone garantit que l'interface utilisateur n'est pas bloquée. JavaScript est largement utilisé dans l'interaction Web, les applications à une page et le développement côté serveur, améliorant considérablement la flexibilité de l'expérience utilisateur et du développement multiplateforme.
 La différence dans Console.Log de sortie Résultat: Pourquoi les deux appels sont-ils différents?
Apr 04, 2025 pm 05:12 PM
La différence dans Console.Log de sortie Résultat: Pourquoi les deux appels sont-ils différents?
Apr 04, 2025 pm 05:12 PM
Discussion approfondie des causes profondes de la différence de sortie Console.log. Cet article analysera les différences dans les résultats de sortie de la fonction Console.log dans un morceau de code et expliquera les raisons derrière. � ...
 TypeScript pour les débutants, partie 2: Types de données de base
Mar 19, 2025 am 09:10 AM
TypeScript pour les débutants, partie 2: Types de données de base
Mar 19, 2025 am 09:10 AM
Une fois que vous avez maîtrisé le didacticiel TypeScript de niveau d'entrée, vous devriez être en mesure d'écrire votre propre code dans un IDE qui prend en charge TypeScript et de le compiler en JavaScript. Ce tutoriel plongera dans divers types de données dans TypeScript. JavaScript a sept types de données: null, non défini, booléen, numéro, chaîne, symbole (introduit par ES6) et objet. TypeScript définit plus de types sur cette base, et ce tutoriel les couvrira tous en détail. Type de données nuls Comme javascript, null en typeScript
 Comment réaliser des effets de défilement de parallaxe et d'animation des éléments, comme le site officiel de Shiseido?
ou:
Comment pouvons-nous réaliser l'effet d'animation accompagné d'un défilement de page comme le site officiel de Shiseido?
Apr 04, 2025 pm 05:36 PM
Comment réaliser des effets de défilement de parallaxe et d'animation des éléments, comme le site officiel de Shiseido?
ou:
Comment pouvons-nous réaliser l'effet d'animation accompagné d'un défilement de page comme le site officiel de Shiseido?
Apr 04, 2025 pm 05:36 PM
La discussion sur la réalisation des effets de défilement de parallaxe et d'animation des éléments dans cet article explorera comment réaliser le site officiel de Shiseido (https://www.shiseido.co.jp/sb/wonderland/) ...
 PowerPoint peut-il exécuter JavaScript?
Apr 01, 2025 pm 05:17 PM
PowerPoint peut-il exécuter JavaScript?
Apr 01, 2025 pm 05:17 PM
JavaScript peut être exécuté dans PowerPoint et peut être implémenté en appelant des fichiers JavaScript externes ou en intégrant des fichiers HTML via VBA. 1. Pour utiliser VBA pour appeler les fichiers JavaScript, vous devez activer les macros et avoir des connaissances en programmation VBA. 2. ENCHED des fichiers HTML contenant JavaScript, qui sont simples et faciles à utiliser mais sont soumis à des restrictions de sécurité. Les avantages incluent les fonctions étendues et la flexibilité, tandis que les inconvénients impliquent la sécurité, la compatibilité et la complexité. En pratique, l'attention doit être accordée à la sécurité, à la compatibilité, aux performances et à l'expérience utilisateur.
