

Python网络爬虫实例讲解

聊一聊Python与网络爬虫。
1、爬虫的定义
爬虫:自动抓取互联网数据的程序。
2、爬虫的主要框架
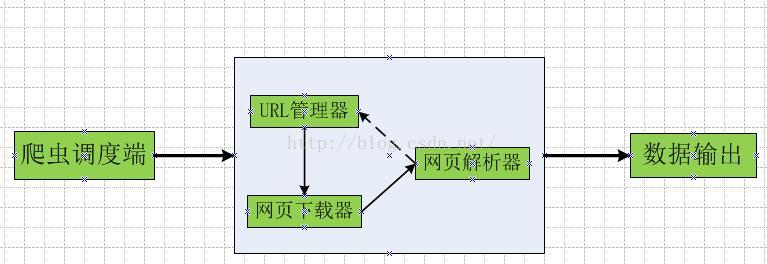
爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出。
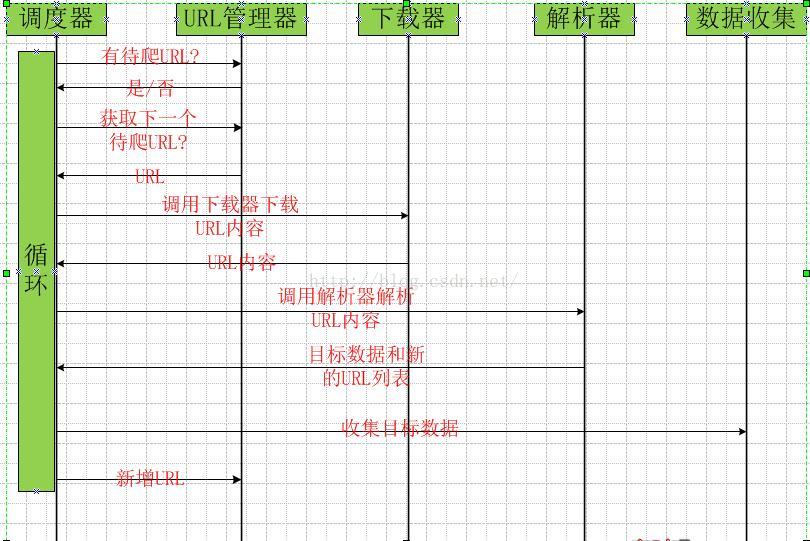
3、爬虫的时序图
4、URL管理器
URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取。URL管理器的主要职能如下图所示:

URL管理器在实现方式上,Python中主要采用内存(set)、和关系数据库(MySQL)。对于小型程序,一般在内存中实现,Python内置的set()类型能够自动判断元素是否重复。对于大一点的程序,一般使用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用urllib库,这是python自带的模块。对于2.x版本中的urllib2库,在python3.x中集成到urllib中,在其request等子模块中。urllib中的urlopen函数用于打开url,并获取url数据。urlopen函数的参数可以是url链接,也可以使request对象,对于简单的网页,直接使用url字符串做参数就已足够,但对于复杂的网页,设有防爬虫机制的网页,再使用urlopen函数时,需要添加http header。对于带有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载到的url数据中提取有价值的数据和新的url。对于数据的提取,可以使用正则表达式和BeautifulSoup等方法。正则表达式使用基于字符串的模糊匹配,对于特点比较鲜明的目标数据具有较好的作用,但通用性不高。BeautifulSoup是第三方模块,用于结构化解析url内容。将下载到的网页内容解析为DOM树,下图为使用BeautifulSoup打印抓取到的百度百科中某网页的输出的一部分。

关于BeautifulSoup的具体使用,在以后的文章中再写。下面的代码使用python抓取百度百科中英雄联盟词条中的其他与英雄联盟相关的词条,并将这些词条保存在新建的excel中。上代码:
from bs4 import BeautifulSoup
import re
import xlrd
<span style="font-size:18px;">import xlwt
from urllib.request import urlopen
excelFile=xlwt.Workbook()
sheet=excelFile.add_sheet('league of legend')
## 百度百科:英雄联盟##
html=urlopen("http://baike.baidu.com/subview/3049782/11262116.htm")
bsObj=BeautifulSoup(html.read(),"html.parser")
#print(bsObj.prettify())
row=0
for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}):
links=node.findAll("a",href=re.compile("^(/view/)[0-9]+\.htm$"))
for link in links:
if 'href' in link.attrs:
print(link.attrs['href'],link.get_text())
sheet.write(row,0,link.attrs['href'])
sheet.write(row,1,link.get_text())
row=row+1
excelFile.save('E:\Project\Python\lol.xls')</span> 输出的部分截图如下:

excel部分的截图如下:

以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
En ce qui concerne le problème de la suppression de l'interpréteur Python qui est livré avec des systèmes Linux, de nombreuses distributions Linux préinstalleront l'interpréteur Python lors de l'installation, et il n'utilise pas le gestionnaire de packages ...
 Comment résoudre le problème de la détection de type pylance des décorateurs personnalisés dans Python?
Apr 02, 2025 am 06:42 AM
Comment résoudre le problème de la détection de type pylance des décorateurs personnalisés dans Python?
Apr 02, 2025 am 06:42 AM
Solution de problème de détection de type pylance Lorsque vous utilisez un décorateur personnalisé dans la programmation Python, le décorateur est un outil puissant qui peut être utilisé pour ajouter des lignes ...
 La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
À propos de Pythonasyncio ...
 Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Utilisation de Python dans Linux Terminal ...
 Python 3.6 Chargement du fichier de cornichon MODULENOTFOUNDERROR: Que dois-je faire si je charge le fichier de cornichon '__builtin__'?
Apr 02, 2025 am 06:27 AM
Python 3.6 Chargement du fichier de cornichon MODULENOTFOUNDERROR: Que dois-je faire si je charge le fichier de cornichon '__builtin__'?
Apr 02, 2025 am 06:27 AM
Chargement du fichier de cornichon dans Python 3.6 Erreur d'environnement: modulenotFounonError: NomoduLenamed ...
 FastAPI et AIOHTTP partagent-ils la même boucle d'événements mondiaux?
Apr 02, 2025 am 06:12 AM
FastAPI et AIOHTTP partagent-ils la même boucle d'événements mondiaux?
Apr 02, 2025 am 06:12 AM
Problèmes de compatibilité entre les bibliothèques asynchrones Python dans Python, la programmation asynchrone est devenue le processus de concurrence élevée et d'E / S ...
 Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Chargement des fichiers de cornichons dans Python 3.6 Rapport de l'environnement Erreur: modulenotFoundError: NomoduLenamed ...
 Comment s'assurer que le processus de l'enfant se termine également après avoir tué le processus parent via le signal dans Python?
Apr 02, 2025 am 06:39 AM
Comment s'assurer que le processus de l'enfant se termine également après avoir tué le processus parent via le signal dans Python?
Apr 02, 2025 am 06:39 AM
Le problème et la solution du processus enfant continuent d'exécuter lors de l'utilisation de signaux pour tuer le processus parent. Dans la programmation Python, après avoir tué le processus parent à travers des signaux, le processus de l'enfant est toujours ...
