

用Python编写简单的微博爬虫

先说点题外话,我一开始想使用Sina Weibo API来获取微博内容,但后来发现新浪微博的API限制实在太多,大家感受一下:

只能获取当前授权的用户(就是自己),而且只能返回最新的5条,WTF!
所以果断放弃掉这条路,改为『生爬』,因为PC端的微博是Ajax的动态加载,爬取起来有些困难,我果断知难而退,改为对移动端的微博进行爬取,因为移动端的微博可以通过分页爬取的方式来一次性爬取所有微博内容,这样工作就简化了不少。
最后实现的功能:
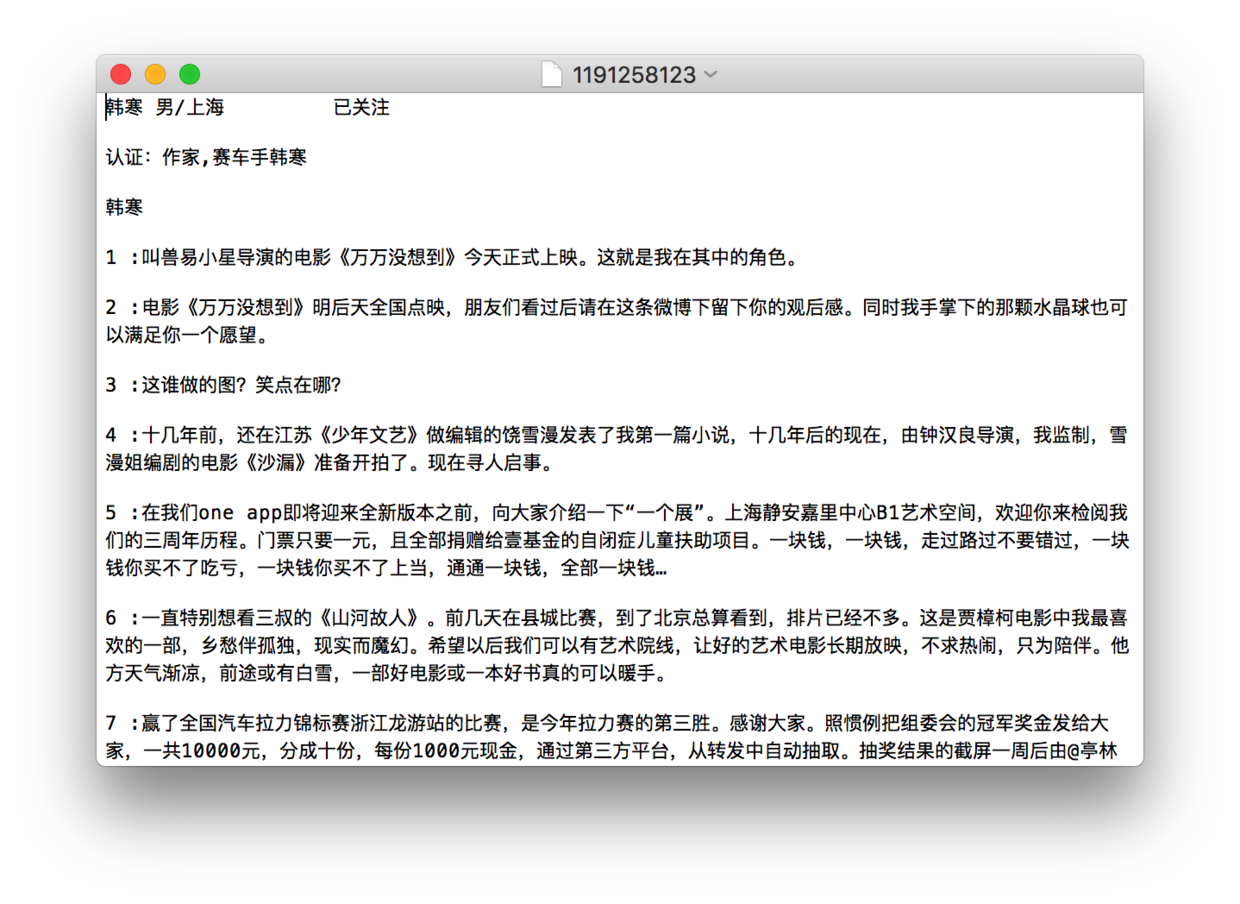
1、输入要爬取的微博用户的user_id,获得该用户的所有微博
2、文字内容保存到以%user_id命名文本文件中,所有高清原图保存在weibo_image文件夹中
具体操作:
首先我们要获得自己的cookie,这里只说chrome的获取方法。
1、用chrome打开新浪微博移动端
2、option+command+i调出开发者工具
3、点开Network,将Preserve log选项选中
4、输入账号密码,登录新浪微博
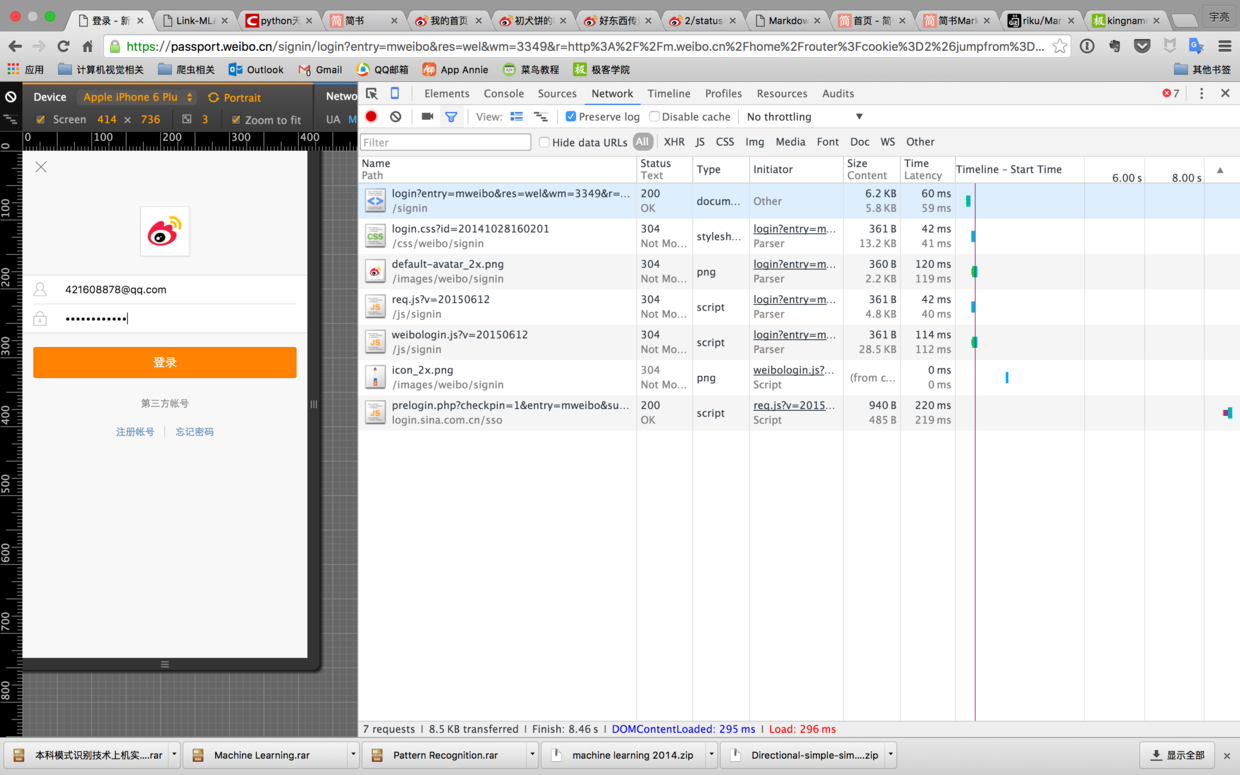
5、找到m.weibo.cn->Headers->Cookie,把cookie复制到代码中的#your cookie处
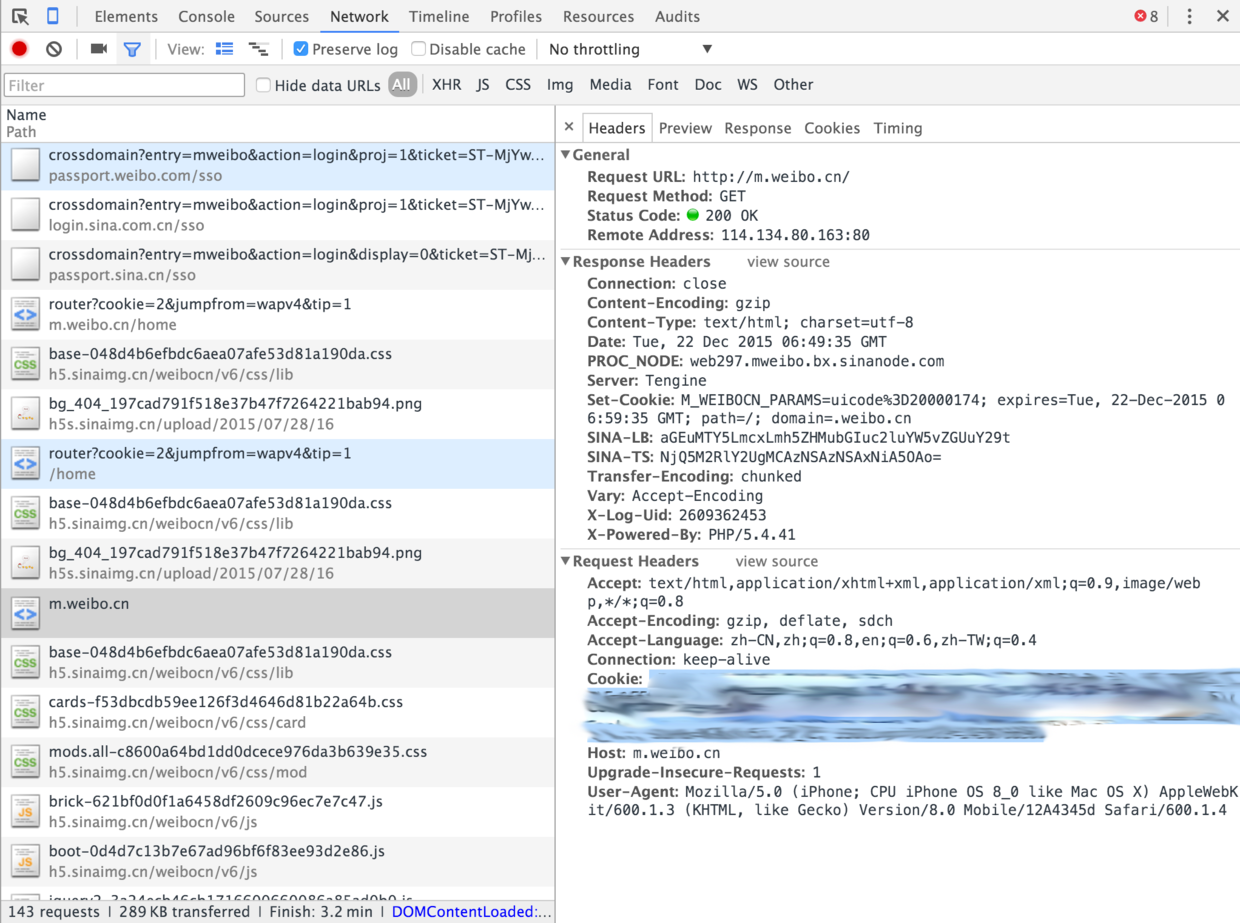
然后再获取你想爬取的用户的user_id,这个我不用多说啥了吧,点开用户主页,地址栏里面那个号码就是user_id
将python代码保存到weibo_spider.py文件中
定位到当前目录下后,命令行执行python weibo_spider.py user_id
当然如果你忘记在后面加user_id,执行的时候命令行也会提示你输入
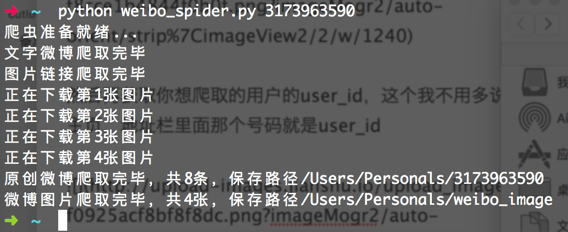
最后执行结束
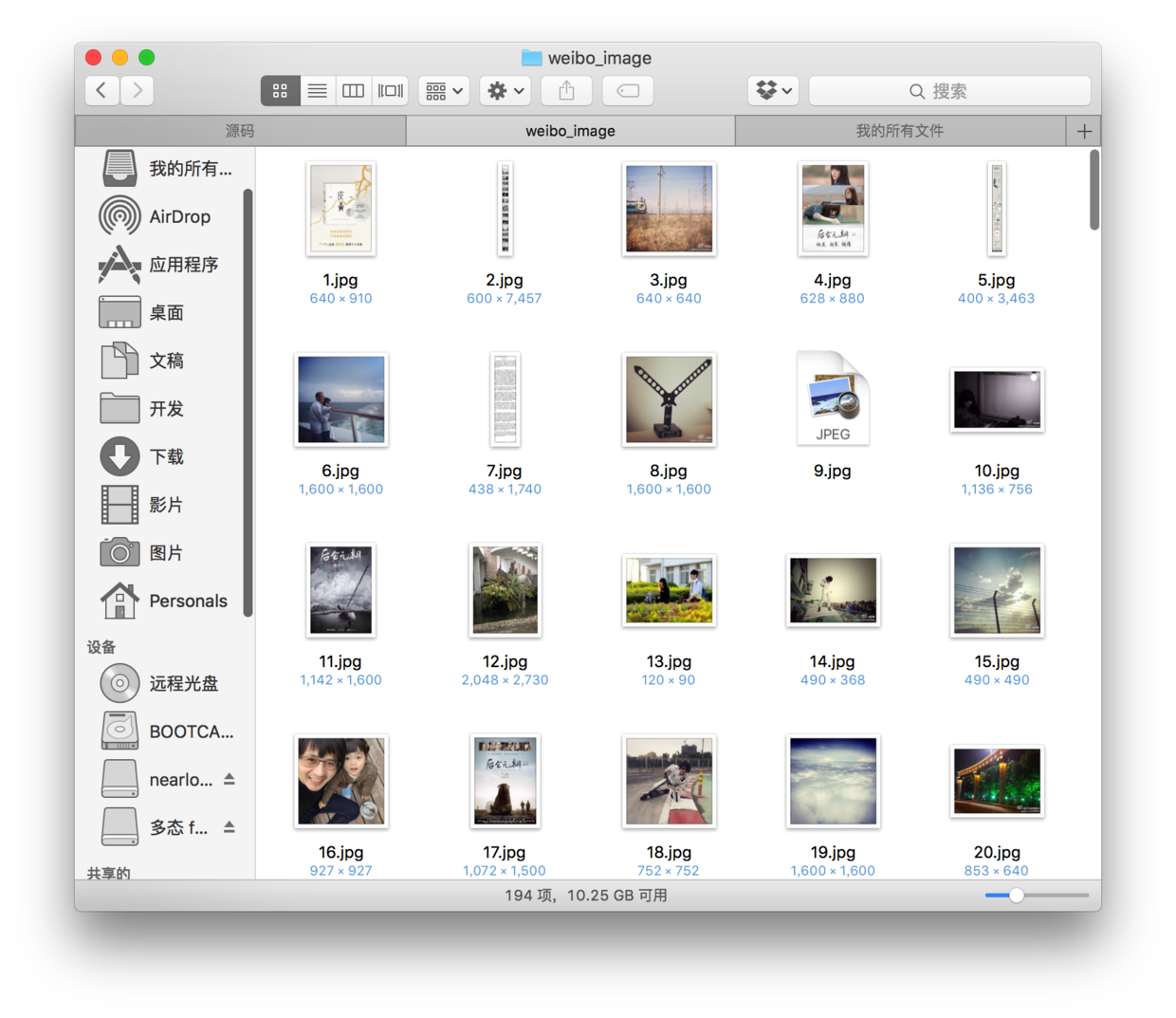
小问题:在我的测试中,有的时候会出现图片下载失败的问题,具体原因还不是很清楚,可能是网速问题,因为我宿舍的网速实在太不稳定了,当然也有可能是别的问题,所以在程序根目录下面,我还生成了一个userid_imageurls的文本文件,里面存储了爬取的所有图片的下载链接,如果出现大片的图片下载失败,可以将该链接群一股脑导进迅雷等下载工具进行下载。
另外,我的系统是OSX EI Capitan10.11.2,Python的版本是2.7,依赖库用sudo pip install XXXX就可以安装,具体配置问题可以自行stackoverflow,这里就不展开讲了。
下面我就给出实现代码
#-*-coding:utf8-*-
import re
import string
import sys
import os
import urllib
import urllib2
from bs4 import BeautifulSoup
import requests
from lxml import etree
reload(sys)
sys.setdefaultencoding('utf-8')
if(len(sys.argv)>=2):
user_id = (int)(sys.argv[1])
else:
user_id = (int)(raw_input(u"请输入user_id: "))
cookie = {"Cookie": "#your cookie"}
url = 'http://weibo.cn/u/%d?filter=1&page=1'%user_id
html = requests.get(url, cookies = cookie).content
selector = etree.HTML(html)
pageNum = (int)(selector.xpath('//input[@name="mp"]')[0].attrib['value'])
result = ""
urllist_set = set()
word_count = 1
image_count = 1
print u'爬虫准备就绪...'
for page in range(1,pageNum+1):
#获取lxml页面
url = 'http://weibo.cn/u/%d?filter=1&page=%d'%(user_id,page)
lxml = requests.get(url, cookies = cookie).content
#文字爬取
selector = etree.HTML(lxml)
content = selector.xpath('//span[@class="ctt"]')
for each in content:
text = each.xpath('string(.)')
if word_count>=4:
text = "%d :"%(word_count-3) +text+"\n\n"
else :
text = text+"\n\n"
result = result + text
word_count += 1
#图片爬取
soup = BeautifulSoup(lxml, "lxml")
urllist = soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/oripic',re.I))
first = 0
for imgurl in urllist:
urllist_set.add(requests.get(imgurl['href'], cookies = cookie).url)
image_count +=1
fo = open("/Users/Personals/%s"%user_id, "wb")
fo.write(result)
word_path=os.getcwd()+'/%d'%user_id
print u'文字微博爬取完毕'
link = ""
fo2 = open("/Users/Personals/%s_imageurls"%user_id, "wb")
for eachlink in urllist_set:
link = link + eachlink +"\n"
fo2.write(link)
print u'图片链接爬取完毕'
if not urllist_set:
print u'该页面中不存在图片'
else:
#下载图片,保存在当前目录的pythonimg文件夹下
image_path=os.getcwd()+'/weibo_image'
if os.path.exists(image_path) is False:
os.mkdir(image_path)
x=1
for imgurl in urllist_set:
temp= image_path + '/%s.jpg' % x
print u'正在下载第%s张图片' % x
try:
urllib.urlretrieve(urllib2.urlopen(imgurl).geturl(),temp)
except:
print u"该图片下载失败:%s"%imgurl
x+=1
print u'原创微博爬取完毕,共%d条,保存路径%s'%(word_count-4,word_path)
print u'微博图片爬取完毕,共%d张,保存路径%s'%(image_count-1,image_path)
一个简单的微博爬虫就完成了,希望对大家的学习有所帮助。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python excelle dans l'automatisation, les scripts et la gestion des tâches. 1) Automatisation: La sauvegarde du fichier est réalisée via des bibliothèques standard telles que le système d'exploitation et la fermeture. 2) Écriture de script: utilisez la bibliothèque PSUTIL pour surveiller les ressources système. 3) Gestion des tâches: utilisez la bibliothèque de planification pour planifier les tâches. La facilité d'utilisation de Python et la prise en charge de la bibliothèque riche en font l'outil préféré dans ces domaines.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
