
 Périphériques technologiques
IA
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
Périphériques technologiques
IA
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées

Écrit avant
Aujourd'hui, nous discutons de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons que SL-SLAM surpasse les algorithmes SLAM de pointe en termes de précision de positionnement et de robustesse de suivi.
Lien du projet : https://github.com/zzzzxxxx111/SLslam.
(Faites glisser votre pouce vers le haut, cliquez sur la carte du haut pour me suivre, L'opération entière ne vous prendra que 1,328 secondes, puis prendra loin de l'avenir, tous, des informations sèches et gratuites, au cas où un contenu vous serait utile ~)
Introduction à l'arrière-plan actuel de l'application SLAM
SLAM (positionnement simultané et construction de cartes) est une technologie en robotique, conduite autonome et reconstruction 3D La technologie clé est qu'elle détermine simultanément la position du capteur (localisation) et construit une carte de l'environnement. Les capteurs de vision et les capteurs inertiels sont les dispositifs de détection les plus couramment utilisés, et les solutions associées ont été discutées et explorées en profondeur. Après des décennies de développement, le cadre de traitement du SLAM visuel (inertiel) a formé un cadre de base, comprenant le suivi, la construction de cartes et la détection de boucles. Dans l'algorithme SLAM, le module de suivi est chargé d'estimer la trajectoire du robot, le module de création de carte est utilisé pour générer et mettre à jour la carte de l'environnement, et la détection de boucle est utilisée pour identifier les emplacements visités. Ces modules collaborent entre eux pour prendre conscience de l'état et de l'environnement du robot. Les algorithmes couramment utilisés dans le SLAM visuel incluent la méthode des points caractéristiques, la méthode directe et la méthode semi-directe. Dans la méthode des points caractéristiques, la pose de la caméra et le nuage de points tridimensionnels sont estimés en extrayant et en faisant correspondre les points caractéristiques ; la méthode directe estime directement la pose de la caméra et le nuage de points tridimensionnels en minimisant la différence d'échelle de gris de l'image au cours des dernières années. la recherche s'est concentrée sur l'amélioration de la robustesse dans des conditions extrêmes et de l'adaptabilité. En raison de la longue histoire de développement de la technologie SLAM, il existe de nombreux travaux SLAM représentatifs basés sur des méthodes géométriques traditionnelles, telles que ORB-SLAM, VINS-Mono, DVO, MSCKF, etc. Toutefois, certaines questions non résolues demeurent. Dans des environnements difficiles tels qu'une faible luminosité ou un éclairage dynamique, une gigue importante et des zones de texture faibles, étant donné que les algorithmes d'extraction de caractéristiques traditionnels ne prennent en compte que les informations locales de l'image sans prendre en compte les informations structurelles et sémantiques de l'image, lorsqu'ils rencontrent les situations ci-dessus, les le suivi du système SLAM peut devenir instable et inefficace. Par conséquent, dans ces conditions, le suivi du système SLAM peut devenir instable et inefficace.
Le développement rapide du deep learning a apporté des changements révolutionnaires dans le domaine de la vision par ordinateur. En utilisant de grandes quantités de données pour la formation, les modèles d'apprentissage profond peuvent simuler des structures de scènes complexes et des informations sémantiques, améliorant ainsi la capacité du système SLAM à comprendre et à exprimer des scènes. Cette méthode se divise principalement en deux approches. Le premier est un algorithme de bout en bout basé sur l'apprentissage profond, tel que Droid-slam, NICE-SLAM et DVI-SLAM. Cependant, ces méthodes nécessitent une grande quantité de données pour la formation, des ressources informatiques et un espace de stockage élevés, ce qui rend difficile la réalisation d'un suivi en temps réel. La deuxième approche est appelée SLAM hybride, qui exploite l'apprentissage en profondeur pour améliorer des modules spécifiques du SLAM. Le SLAM hybride tire pleinement parti des méthodes géométriques traditionnelles et des méthodes d'apprentissage en profondeur, et peut trouver un équilibre entre presque toutes les contraintes et la compréhension sémantique. Bien qu'il y ait eu quelques études dans ce domaine, la manière d'intégrer efficacement la technologie d'apprentissage profond reste une direction qui mérite des recherches plus approfondies.
Actuellement, le SLAM hybride existant présente certaines limites. DXNet remplace simplement les points caractéristiques ORB par des points caractéristiques approfondis, mais continue d'utiliser des méthodes traditionnelles pour suivre ces fonctionnalités. Par conséquent, cela peut conduire à une incohérence dans les informations détaillées sur les fonctionnalités. SP-Loop introduit uniquement les points de fonctionnalité d'apprentissage en profondeur dans le module en boucle fermée, tout en conservant les méthodes traditionnelles d'extraction de points de fonctionnalité ailleurs. Par conséquent, ces méthodes SLAM hybrides ne combinent pas de manière efficace et complète la technologie d’apprentissage profond, ce qui entraîne une diminution des effets de suivi et de cartographie dans certaines scènes complexes.
Pour résoudre ces problèmes, un système SLAM multifonctionnel basé sur le deep learning est proposé ici. Intégrez le module d'extraction de points caractéristiques Superpoint dans le système et utilisez-le comme seule forme d'expression. De plus, dans des environnements complexes, les méthodes traditionnelles de mise en correspondance de caractéristiques présentent souvent une instabilité, entraînant une diminution de la qualité du suivi et de la cartographie. Cependant, les progrès récents dans les méthodes de mise en correspondance de fonctionnalités basées sur l’apprentissage profond ont montré le potentiel d’améliorer les performances de mise en correspondance dans des environnements complexes. Ces méthodes exploitent des informations préalables et des détails structurels de la scène pour améliorer l'efficacité de la mise en correspondance. En tant que dernière méthode de correspondance SOTA (état de l'art), Lightglue présente des avantages pour les systèmes SLAM qui nécessitent des performances élevées en temps réel en raison de ses caractéristiques efficaces et légères. Par conséquent, nous avons remplacé la méthode de correspondance des fonctionnalités dans l'ensemble du système SLAM par Lightglue, ce qui améliore la robustesse et la précision par rapport aux méthodes traditionnelles.
Lors du traitement des descripteurs de points caractéristiques Superpoint, nous les prétraitons pour être cohérents avec la formation du sac de mots visuels correspondant. Lorsqu'elle est combinée avec Lightglue, cette approche permet d'obtenir une reconnaissance précise de la scène. Dans le même temps, afin de maintenir l’équilibre entre précision et efficacité, une stratégie de sélection des points caractéristiques est conçue. Compte tenu de l'évolutivité, de la portabilité et des performances en temps réel, nous utilisons la bibliothèque ONNX+Runtime pour déployer ces modèles d'apprentissage en profondeur. Enfin, une série d'expériences sont conçues pour prouver que la méthode améliore la précision de la prédiction de trajectoire et la robustesse du suivi de l'algorithme SLAM dans une variété de scénarios difficiles, comme le montre la figure 8.
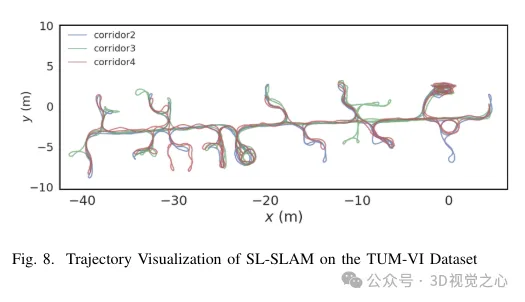
Cadre du système SL-SLAM
La structure du système SL-SLAM est illustrée à la figure 2. Le système comporte principalement quatre configurations de capteurs, à savoir monoculaire, inertie monoculaire, binoculaire et inertie binoculaire. Le système est basé sur ORB-SLAM3 comme base et contient trois modules principaux : suivi, cartographie locale et détection de boucle. Pour intégrer des modèles d'apprentissage profond dans le système, le cadre de déploiement d'apprentissage profond ONNX Runtime est utilisé, combinant les modèles SuperPoint et LightGlue.
Pour chaque image d'entrée, le système l'entre d'abord dans le réseau SuperPoint pour obtenir le tenseur de probabilité et le tenseur de descripteur des points caractéristiques. Le système s'initialise ensuite avec deux images et effectue un suivi grossier sur chaque image suivante. Il affine encore l'estimation de la pose en suivant les cartes locales. En cas d'échec du suivi, le système utilise un cadre de référence pour le suivi ou effectue une relocalisation pour réacquérir la pose. Veuillez noter que LightGlue est utilisé pour la correspondance des fonctionnalités lors du suivi grossier, de l'initialisation, du suivi du cadre de référence et de la relocalisation. Cela garantit des relations de correspondance précises et robustes, augmentant ainsi l’efficacité du suivi.
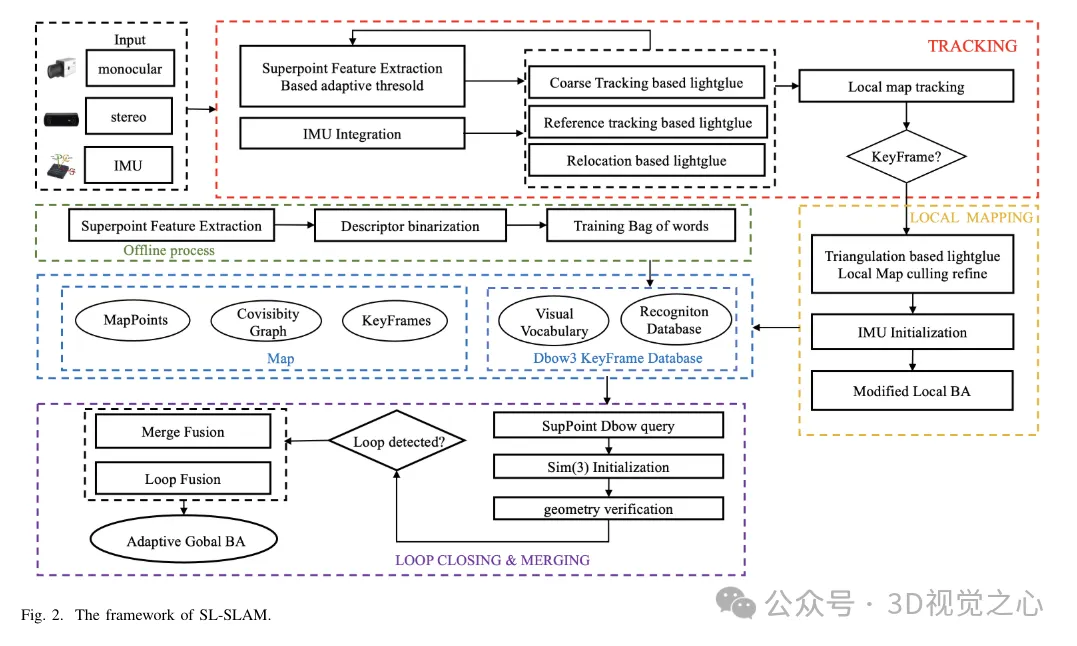
Dans l'algorithme de base, le rôle principal du fil de cartographie local est de construire dynamiquement une carte locale en temps réel, comprenant les points de la carte et les images clés. Il utilise des cartes locales pour effectuer l'optimisation des ajustements de lots, réduisant ainsi les erreurs de suivi et améliorant la cohérence. Le fil de cartographie local utilise les images clés générées par le fil de suivi, la triangulation basée sur LightGlue et l'optimisation adaptative de l'ajustement du faisceau local (BA) pour reconstruire des points de carte précis. Les points de carte et les images clés redondants sont ensuite distingués et supprimés.
Le fil de correction en boucle fermée utilise une base de données d'images clés et un modèle de sac de mots formés sur les descripteurs SuperPoint pour récupérer des images clés similaires. Améliorez l’efficacité de la récupération en binarisant les descripteurs SuperPoint. Les images clés sélectionnées sont mises en correspondance à l'aide de LightGlue pour la vérification de la géométrie de la vue commune, réduisant ainsi le risque de disparités. Enfin, une fusion en boucle fermée et un BA (Bundle Adjustment) global sont effectués pour optimiser la posture globale.
1) Extraction de fonctionnalités
Structure du réseau SuperPoint : L'architecture du réseau SuperPoint se compose principalement de trois parties : un encodeur partagé, un décodeur de détection de fonctionnalités et un décodeur de descripteur. L'encodeur est un réseau de style VGG capable de réduire les dimensions de l'image et d'extraire des fonctionnalités. La tâche du décodeur de détection de caractéristiques est de calculer la probabilité de chaque pixel de l'image pour déterminer sa probabilité d'être un point caractéristique. Le réseau de décodage de descripteur utilise une convolution de sous-pixels pour réduire la complexité informatique du processus de décodage. Le réseau produit ensuite un descripteur semi-dense et un algorithme d'interpolation bicubique est appliqué pour obtenir le descripteur complet. Après avoir obtenu le tenseur de points caractéristiques et le tenseur de descripteurs produits par le réseau, afin d'améliorer la robustesse de l'extraction de caractéristiques, nous adoptons une stratégie de sélection de seuil adaptative pour filtrer les points caractéristiques et effectuer des opérations de post-traitement pour obtenir les points caractéristiques et leurs descripteurs. . La structure spécifique du module d'extraction de fonctionnalités est illustrée à la figure 3.
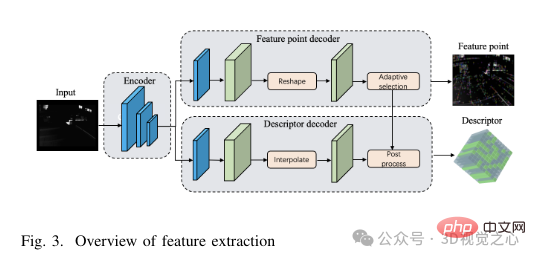
Sélection adaptative des fonctionnalités : tout d'abord, chaque image, étiquetée I(W × H), est convertie en gris avant d'être redimensionnée pour correspondre aux dimensions de l'image d'entrée (W′ × H′) de l'image du degré du réseau SuperPoint. Les images trop petites peuvent gêner l'extraction de caractéristiques, réduisant ainsi les performances de suivi, tandis que les images trop grandes peuvent entraîner des besoins de calcul et une utilisation de la mémoire excessifs. Par conséquent, afin d’équilibrer la précision et l’efficacité de l’extraction de caractéristiques, cet article choisit W′ = 400 et H′ = 300. Par la suite, un tenseur de taille W′ × H′ est introduit dans le réseau, produisant deux tenseurs de sortie : le tenseur de score S et le tenseur de descripteur D. Une fois le tenseur de score de points caractéristiques et le descripteur de caractéristiques obtenus, l'étape suivante consiste à définir un seuil pour filtrer les points caractéristiques.
Dans des scénarios difficiles, la confiance de chaque point de caractéristique sera réduite, ce qui peut entraîner une réduction du nombre de caractéristiques extraites si un seuil de confiance fixe est adopté. Pour résoudre ce problème, nous introduisons une stratégie adaptative de définition de seuil SuperPoint. Cette méthode adaptative ajuste dynamiquement le seuil d'extraction de caractéristiques en fonction de la scène, obtenant ainsi une extraction de caractéristiques plus robuste dans les scènes difficiles. Le mécanisme de seuil adaptatif prend en compte deux facteurs : les relations intra-fonctionnalités et les relations entre caractéristiques inter-trames.
Dans des scénarios difficiles, la confiance de chaque point de fonctionnalité sera réduite, ce qui peut entraîner une réduction du nombre de fonctionnalités extraites si un seuil de confiance fixe est adopté. Pour résoudre ce problème, une stratégie adaptative de définition de seuil SuperPoint est introduite. Cette méthode adaptative ajuste dynamiquement le seuil d'extraction de caractéristiques en fonction de la scène, obtenant ainsi une extraction de caractéristiques plus robuste dans les scènes difficiles. Le mécanisme de seuil adaptatif prend en compte deux facteurs : les relations intra-fonctionnalités et les relations entre caractéristiques inter-trames.
2) Correspondance des fonctionnalités et front-end
Structure du réseau LightGlue : Le modèle LightGlue se compose de plusieurs couches identiques qui traitent conjointement deux ensembles de fonctionnalités. Chaque couche contient des unités d'auto-attention et d'attention croisée pour mettre à jour la représentation des points. Les classificateurs de chaque couche décident où arrêter l'inférence, évitant ainsi les calculs inutiles. Enfin, un en-tête léger calcule les scores de correspondance partielle. La profondeur du réseau s'ajuste dynamiquement en fonction de la complexité de l'image d'entrée. Si les paires d'images correspondent facilement, une résiliation anticipée peut être obtenue grâce à la grande confiance des balises. En conséquence, LightGlue a des durées d'exécution plus courtes et une consommation de mémoire inférieure, ce qui le rend adapté à l'intégration dans des tâches nécessitant des performances en temps réel.
L'intervalle de temps entre les images adjacentes n'est généralement que de quelques dizaines de millisecondes. ORB-SLAM3 suppose que la caméra se déplace à une vitesse constante pendant cette courte période de temps. Il utilise la pose et la vitesse de l'image précédente pour estimer la pose de l'image actuelle et utilise cette pose estimée pour la correspondance de projection. Il recherche ensuite les points correspondants dans une certaine plage et affine la pose en conséquence. Cependant, en réalité, les mouvements de la caméra ne sont pas toujours uniformes. Une accélération, une décélération ou une rotation soudaine peut nuire à l'efficacité de cette méthode. Lightglue peut résoudre efficacement ce problème en faisant directement correspondre les caractéristiques entre l'image actuelle et l'image précédente. Il utilise ensuite ces caractéristiques adaptées pour affiner l'estimation de la pose initiale, réduisant ainsi les effets négatifs d'une accélération ou d'une rotation soudaine.
Dans les situations où le suivi d'image échoue dans les images précédentes, que ce soit en raison d'un mouvement soudain de la caméra ou d'autres facteurs, des images clés de référence doivent être utilisées pour le suivi ou le repositionnement. L'algorithme de base utilise la méthode Bag-of-Words (BoW) pour accélérer la correspondance des caractéristiques entre le cadre actuel et le cadre de référence. Cependant, la méthode BoW convertit les informations spatiales en informations statistiques basées sur un vocabulaire visuel, ce qui peut perdre la relation spatiale précise entre les points caractéristiques. De plus, si le vocabulaire visuel utilisé dans le modèle BoW est insuffisant ou pas assez représentatif, il risque de ne pas capturer la richesse des caractéristiques de la scène, ce qui entraînera des inexactitudes dans le processus de mise en correspondance.
Combiné avec le suivi Lightglue : Étant donné que l'intervalle de temps entre les images adjacentes est très court, généralement seulement quelques dizaines de millisecondes, ORB-SLAM3 suppose que la caméra se déplace à une vitesse uniforme pendant cette période. Il utilise la pose et la vitesse de l'image précédente pour estimer la pose de l'image actuelle et utilise cette pose estimée pour la correspondance de projection. Il recherche ensuite les points correspondants dans une certaine plage et affine la pose en conséquence. Cependant, en réalité, les mouvements de la caméra ne sont pas toujours uniformes. Une accélération, une décélération ou une rotation soudaine peut nuire à l'efficacité de cette méthode. Lightglue peut résoudre efficacement ce problème en faisant directement correspondre les caractéristiques entre l'image actuelle et l'image précédente. Il utilise ensuite ces caractéristiques adaptées pour affiner l'estimation de la pose initiale, réduisant ainsi les effets négatifs d'une accélération ou d'une rotation soudaine.
Dans les situations où le suivi d'image échoue dans les images précédentes, que ce soit en raison d'un mouvement soudain de la caméra ou d'autres facteurs, des images clés de référence doivent être utilisées pour le suivi ou le repositionnement. L'algorithme de base utilise la méthode Bag-of-Words (BoW) pour accélérer la correspondance des caractéristiques entre le cadre actuel et le cadre de référence. Cependant, la méthode BoW convertit les informations spatiales en informations statistiques basées sur un vocabulaire visuel, ce qui peut perdre la relation spatiale précise entre les points caractéristiques. De plus, si le vocabulaire visuel utilisé dans le modèle BoW est insuffisant ou pas assez représentatif, il risque de ne pas capturer la richesse des caractéristiques de la scène, ce qui entraînera des inexactitudes dans le processus de mise en correspondance.

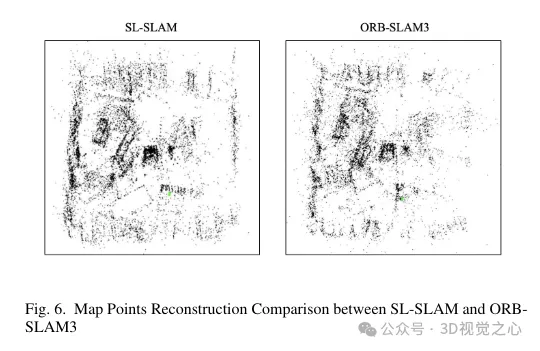
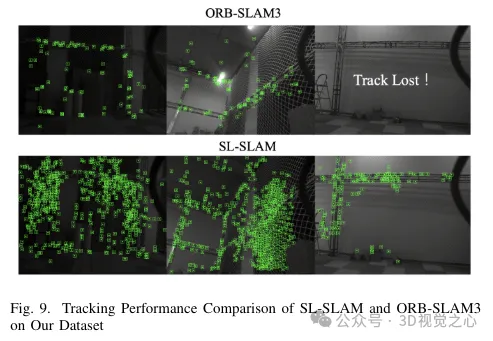
Pour résoudre ces problèmes, la méthode BoW a été remplacée par Lightglue dans tout le système. Ce changement améliore considérablement la probabilité de succès du suivi et de la relocalisation dans le cadre de transformations à grande échelle, améliorant ainsi la précision et la robustesse de notre processus de suivi. La figure 4 démontre l'efficacité des différentes méthodes d'appariement. On peut observer que la méthode de correspondance basée sur Lightglue montre de meilleures performances de correspondance que la méthode de correspondance basée sur la projection ou le Bag-of-Words utilisée dans ORB-SLAM3. Par conséquent, pendant l’opération SLAM, le suivi des points de la carte est plus uniforme et plus stable, comme le montre la figure 6.
Combiné avec la cartographie locale de Lightglue : Dans le fil de cartographie locale, la triangulation des nouveaux points de la carte est complétée via l'image clé actuelle et ses images clés adjacentes. Pour obtenir des points de carte plus précis, vous devez comparer les images clés avec une ligne de base plus grande. Cependant, ORB-SLAM3 utilise la correspondance Bag-of-Words (BoW) pour y parvenir, mais les performances de la correspondance des fonctionnalités BoW diminuent lorsque la ligne de base est grande. En revanche, l’algorithme Lightglue est bien adapté à la mise en correspondance avec de grandes lignes de base et s’intègre parfaitement au système. En utilisant Lightglue pour la correspondance des caractéristiques et la triangulation des points de correspondance, des points de carte plus complets et de meilleure qualité peuvent être récupérés.
Cela améliore les capacités de cartographie locale en créant davantage de connexions entre les images clés et en stabilisant le suivi en optimisant conjointement la pose des images clés et des points de la carte visibles conjointement. L'effet de triangulation des points de la carte est illustré à la figure 6. On peut observer que par rapport à ORB-SLAM3, les points de carte construits par notre méthode peuvent mieux refléter les informations structurelles de la scène. De plus, ils sont répartis plus uniformément et plus largement dans l’espace.
3) Fermeture de boucle
Descripteur de profondeur du sac de mots : La méthode du sac de mots utilisée dans la détection de fermeture de boucle est une méthode basée sur le vocabulaire visuel, qui s'appuie sur le concept de sac de mots dans le traitement du langage naturel. Il effectue d’abord une formation hors ligne du dictionnaire. Initialement, l'algorithme K-means est utilisé pour regrouper les descripteurs de caractéristiques détectés dans l'ensemble d'images d'entraînement en k ensembles, formant le premier niveau de l'arborescence du dictionnaire. Ensuite, des opérations récursives sont effectuées au sein de chaque ensemble, et finalement un arbre de dictionnaire final avec une profondeur de L et un nombre de branches est obtenu, et un vocabulaire visuel est établi. Chaque nœud feuille est considéré comme un vocabulaire.
Une fois la formation du dictionnaire terminée, des vecteurs de sac de mots et des vecteurs de caractéristiques sont générés en ligne à partir de tous les points caractéristiques de l'image actuelle pendant l'exécution de l'algorithme. Les frameworks SLAM grand public ont tendance à utiliser des descripteurs binaires définis manuellement en raison de leur faible empreinte mémoire et de leurs méthodes de comparaison simples. Afin d'améliorer encore l'efficacité de la méthode, SP-Loop utilise une distribution gaussienne avec une valeur attendue de 0 et un écart type de 0,07 pour représenter la valeur du descripteur de superpoint. Par conséquent, le descripteur à virgule flottante à 256 dimensions du superpoint peut être codé en binaire pour améliorer la vitesse d'interrogation de la reconnaissance visuelle de l'emplacement. Le codage binaire est illustré dans l'équation 4.
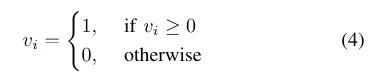
Processus de base : La détection de fermeture de boucle dans SLAM implique généralement trois étapes clés : trouver les images clés candidates à la fermeture de boucle initiale, vérifier les images clés candidates à la fermeture de boucle et effectuer la correction de fermeture de boucle et l'ajustement global du paquet (Bundle Adjustment, BA).
La première étape du processus de démarrage consiste à identifier les images clés initiales candidates à la fermeture de la boucle. Ceci est réalisé en tirant parti du modèle de sac de mots DBoW3 précédemment formé. Les images clés qui partagent le vocabulaire avec l'image Ka actuelle sont identifiées, mais les images clés co-visibles avec Ka sont exclues. Calculez le score total des images clés co-visibles liées à ces images clés candidates. Parmi les N premiers groupes ayant les scores les plus élevés parmi les images clés candidates en boucle fermée, sélectionnez l’image clé avec le score le plus élevé. Cette image clé sélectionnée est exprimée en Km.
Ensuite, vous devez déterminer la transformation de posture relative Tam de Km à l'image clé actuelle Ka. Dans ORB-SLAM3, une méthode de mise en correspondance de caractéristiques basée sur un sac de mots est utilisée pour faire correspondre l'image clé actuelle avec l'image clé candidate Km et son image clé co-visible Kco. Il convient de noter que, puisque l’algorithme Lightglue améliore considérablement l’efficacité de la correspondance, la correspondance de la trame actuelle avec la trame candidate Km produira des correspondances de points de carte de haute qualité. Ensuite, l'algorithme RANSAC est appliqué pour éliminer les valeurs aberrantes et la transformation Sim(3) est résolue pour déterminer l'attitude relative initiale Tam. Afin d'éviter une identification de position erronée, les images clés candidates seront vérifiées géométriquement et les étapes suivantes sont similaires à ORB-SLAM3.
Analyse comparative expérimentale
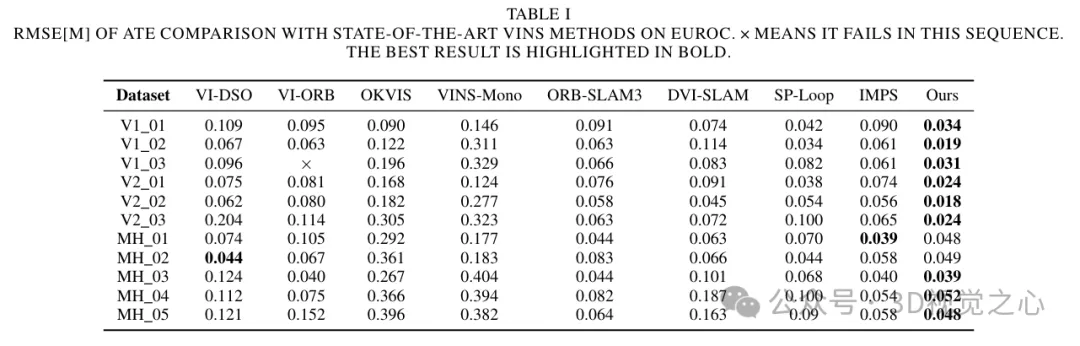
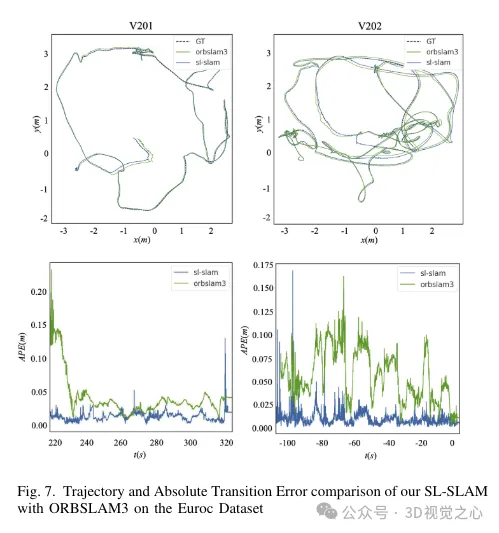
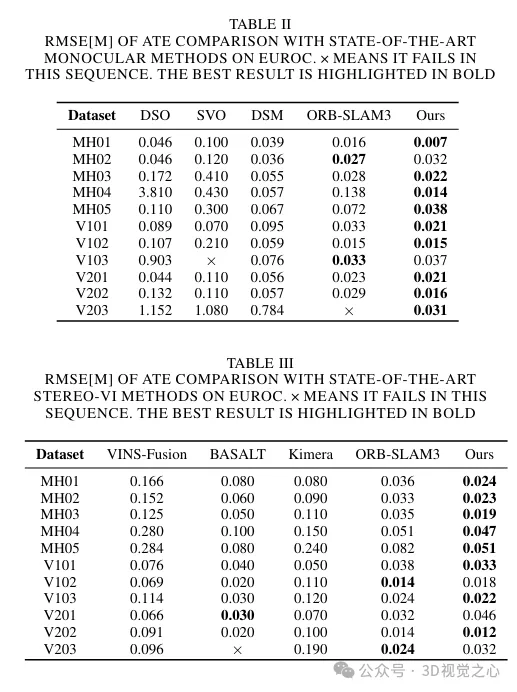
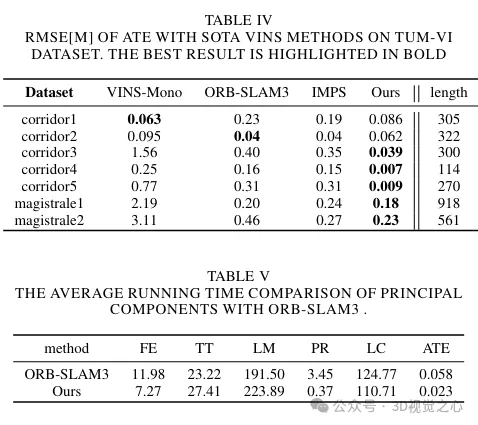
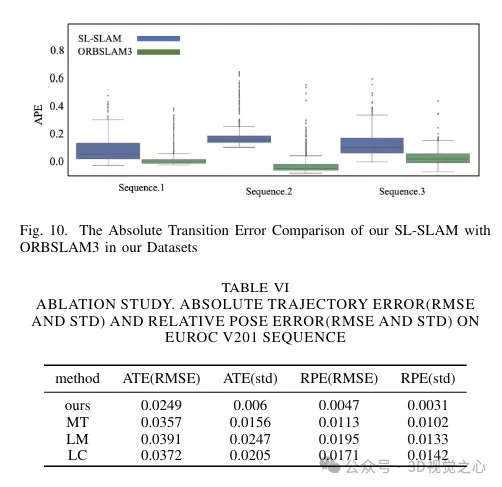
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
BERT est un modèle de langage d'apprentissage profond pré-entraîné proposé par Google en 2018. Le nom complet est BidirectionnelEncoderRepresentationsfromTransformers, qui est basé sur l'architecture Transformer et présente les caractéristiques d'un codage bidirectionnel. Par rapport aux modèles de codage unidirectionnels traditionnels, BERT peut prendre en compte les informations contextuelles en même temps lors du traitement du texte, de sorte qu'il fonctionne bien dans les tâches de traitement du langage naturel. Sa bidirectionnalité permet à BERT de mieux comprendre les relations sémantiques dans les phrases, améliorant ainsi la capacité expressive du modèle. Grâce à des méthodes de pré-formation et de réglage fin, BERT peut être utilisé pour diverses tâches de traitement du langage naturel, telles que l'analyse des sentiments, la dénomination
 Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Les fonctions d'activation jouent un rôle crucial dans l'apprentissage profond. Elles peuvent introduire des caractéristiques non linéaires dans les réseaux neuronaux, permettant ainsi au réseau de mieux apprendre et simuler des relations entrées-sorties complexes. La sélection et l'utilisation correctes des fonctions d'activation ont un impact important sur les performances et les résultats de formation des réseaux de neurones. Cet article présentera quatre fonctions d'activation couramment utilisées : Sigmoid, Tanh, ReLU et Softmax, à partir de l'introduction, des scénarios d'utilisation, des avantages, Les inconvénients et les solutions d'optimisation sont abordés pour vous fournir une compréhension complète des fonctions d'activation. 1. Fonction sigmoïde Introduction à la formule de la fonction SIgmoïde : La fonction sigmoïde est une fonction non linéaire couramment utilisée qui peut mapper n'importe quel nombre réel entre 0 et 1. Il est généralement utilisé pour unifier le
 Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
L'intégration d'espace latent (LatentSpaceEmbedding) est le processus de mappage de données de grande dimension vers un espace de faible dimension. Dans le domaine de l'apprentissage automatique et de l'apprentissage profond, l'intégration d'espace latent est généralement un modèle de réseau neuronal qui mappe les données d'entrée de grande dimension dans un ensemble de représentations vectorielles de basse dimension. Cet ensemble de vecteurs est souvent appelé « vecteurs latents » ou « latents ». encodages". Le but de l’intégration de l’espace latent est de capturer les caractéristiques importantes des données et de les représenter sous une forme plus concise et compréhensible. Grâce à l'intégration de l'espace latent, nous pouvons effectuer des opérations telles que la visualisation, la classification et le regroupement de données dans un espace de faible dimension pour mieux comprendre et utiliser les données. L'intégration d'espace latent a de nombreuses applications dans de nombreux domaines, tels que la génération d'images, l'extraction de caractéristiques, la réduction de dimensionnalité, etc. L'intégration de l'espace latent est le principal
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
 La première reconstruction purement visuelle et statique de la conduite autonome
Jun 02, 2024 pm 03:24 PM
La première reconstruction purement visuelle et statique de la conduite autonome
Jun 02, 2024 pm 03:24 PM
Une solution d'annotation purement visuelle utilise principalement la vision ainsi que certaines données du GPS, de l'IMU et des capteurs de vitesse de roue pour l'annotation dynamique. Bien entendu, pour les scénarios de production de masse, il n’est pas nécessaire qu’il s’agisse d’une vision pure. Certains véhicules produits en série seront équipés de capteurs comme le radar à semi-conducteurs (AT128). Si nous créons une boucle fermée de données dans la perspective d'une production de masse et utilisons tous ces capteurs, nous pouvons résoudre efficacement le problème de l'étiquetage des objets dynamiques. Mais notre plan ne prévoit pas de radar à semi-conducteurs. Par conséquent, nous présenterons cette solution d’étiquetage de production de masse la plus courante. Le cœur d’une solution d’annotation purement visuelle réside dans la reconstruction de pose de haute précision. Nous utilisons le schéma de reconstruction de pose de Structure from Motion (SFM) pour garantir la précision de la reconstruction. Mais passe
 AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
Editeur | Radis Skin Depuis la sortie du puissant AlphaFold2 en 2021, les scientifiques utilisent des modèles de prédiction de la structure des protéines pour cartographier diverses structures protéiques dans les cellules, découvrir des médicaments et dresser une « carte cosmique » de chaque interaction protéique connue. Tout à l'heure, Google DeepMind a publié le modèle AlphaFold3, capable d'effectuer des prédictions de structure conjointe pour des complexes comprenant des protéines, des acides nucléiques, de petites molécules, des ions et des résidus modifiés. La précision d’AlphaFold3 a été considérablement améliorée par rapport à de nombreux outils dédiés dans le passé (interaction protéine-ligand, interaction protéine-acide nucléique, prédiction anticorps-antigène). Cela montre qu’au sein d’un cadre unique et unifié d’apprentissage profond, il est possible de réaliser
