
 Périphériques technologiques
IA
Déchirage manuel de la couche 1 de Llama3 : implémentation de Llama3 à partir de zéro
Périphériques technologiques
IA
Déchirage manuel de la couche 1 de Llama3 : implémentation de Llama3 à partir de zéro
Déchirage manuel de la couche 1 de Llama3 : implémentation de Llama3 à partir de zéro

1. Architecture de Llama3
Dans cette série d'articles, nous implémentons Llama3 à partir de zéro.
L'architecture globale de Llama3 :
 Photos
Photos
Les paramètres du modèle de Llama3 :
Jetons un coup d'œil aux valeurs réelles de ces paramètres dans le modèle LlaMa 3.
 Pictures
Pictures
[1] Fenêtre contextuelle (context-window)
Lors de l'instanciation de la classe LlaMa, la variable max_seq_len définit la fenêtre contextuelle. Il existe d'autres paramètres dans la classe, mais ce paramètre est le plus directement lié au modèle de transformateur. Le max_seq_len ici est de 8K.
 Images
Images
[2] Taille du vocabulaire et couches d'attention
La classe Transformer est un modèle qui définit le vocabulaire et le nombre de couches. Le vocabulaire fait ici référence à l'ensemble de mots (et de jetons) que le modèle est capable de reconnaître et de traiter. Les couches d'attention font référence au bloc de transformation (une combinaison de couches d'attention et de rétroaction) utilisé dans le modèle.
 Photos
Photos
Selon ces chiffres, LlaMa 3 a un vocabulaire de 128K, ce qui est assez large. De plus, il dispose de 32 blocs transformateurs.
[3] Dimension-caractéristique et têtes d'attention
La dimension-caractéristique et les têtes d'attention sont introduites dans le module Auto-Attention. La dimension des fonctionnalités fait référence à la taille vectorielle des jetons dans l'espace d'intégration (la dimension des fonctionnalités fait référence à la taille des données d'entrée ou au vecteur d'intégration), tandis que les têtes d'attention incluent le module QK qui pilote le mécanisme d'auto-attention dans les transformateurs.
 Images
Images
[4] Dimensions cachées
Les dimensions cachées font référence à la taille de la couche cachée dans le réseau neuronal à rétroaction (Feed Forward). Les réseaux de neurones Feedforward contiennent généralement une ou plusieurs couches cachées, et les dimensions de ces couches cachées déterminent la capacité et la complexité du réseau. Dans le modèle Transformer, la dimension de la couche cachée du réseau neuronal à action directe est généralement un multiple de la dimension des fonctionnalités pour augmenter la capacité de représentation du modèle. Dans LLama3, la dimension cachée est 1,3 fois la dimension caractéristique. Il convient de noter que les couches cachées et les dimensions cachées sont deux concepts.
Un nombre plus élevé de couches cachées permet au réseau de créer et de manipuler en interne des représentations plus riches avant de les projeter dans des dimensions de sortie plus petites.
 Picture
Picture
[5] Combinez les paramètres ci-dessus dans un transformateur
La première matrice est la matrice des fonctionnalités d'entrée, qui est traitée par la couche Attention pour générer des fonctionnalités pondérées par l'attention. Dans cette image, la matrice des caractéristiques d'entrée n'a qu'une taille de 5 x 3, mais dans le modèle réel Llama 3, elle atteint 8K x 4096, ce qui est énorme.
Vient ensuite les couches cachées du réseau Feed-Forward, passant à 5325 puis retombant à 4096 dans la dernière couche.
 Photos
Photos
[6] Plusieurs couches de blocs Transformateur
LlaMa 3 combine les 32 blocs transformateurs ci-dessus, et la sortie passe d'un bloc au suivant jusqu'à ce qu'elle atteigne le dernier.
 Photos
Photos
[7] Assembler le tout
Une fois que nous avons commencé toutes les parties ci-dessus, il est temps de les assembler et de voir comment elles créent l'effet LlaMa.
 Images
Images
Étape 1 : Nous avons d'abord notre matrice d'entrée de taille 8K (fenêtre contextuelle) x 128K (taille vocabulaire). Cette matrice subit un processus d'intégration pour convertir cette matrice de haute dimension en une matrice de basse dimension.
Étape 2 : Dans ce cas, ce résultat de faible dimension devient 4096, qui est la dimension spécifiée des caractéristiques dans le modèle LlaMa que nous avons vu plus tôt.
Dans les réseaux de neurones, l'amélioration et la réduction de la dimensionnalité sont des opérations courantes, et elles ont chacune des objectifs et des effets différents.
L'amélioration des dimensions consiste généralement à augmenter la capacité du modèle afin qu'il puisse capturer des caractéristiques et des modèles plus complexes. Lorsque les données d'entrée sont mappées dans un espace de dimension supérieure, différentes combinaisons de caractéristiques peuvent être plus facilement distinguées par le modèle. Ceci est particulièrement utile lorsqu’il s’agit de problèmes non linéaires, car cela peut aider le modèle à connaître des limites de décision plus complexes.
La réduction de dimensionnalité consiste à réduire la complexité du modèle et le risque de surajustement. En réduisant la dimensionnalité de l'espace des fonctionnalités, le modèle peut être contraint d'apprendre des représentations de fonctionnalités plus raffinées et généralisées. De plus, la réduction de dimensionnalité peut être utilisée comme méthode de régularisation pour contribuer à améliorer la capacité de généralisation du modèle. Dans certains cas, la réduction de la dimensionnalité peut également réduire les coûts de calcul et améliorer l’efficacité opérationnelle du modèle.
Dans les applications pratiques, la stratégie d'augmentation de dimensionnalité puis de réduction de dimensionnalité peut être considérée comme un processus d'extraction et de transformation de caractéristiques. Dans ce processus, le modèle explore d'abord la structure intrinsèque des données en augmentant la dimensionnalité, puis extrait les caractéristiques et les modèles les plus utiles en réduisant la dimensionnalité. Cette approche peut aider le modèle à éviter le surajustement des données d'entraînement tout en conservant une complexité suffisante.
Étape 3 : Cette fonctionnalité est traitée via le bloc Transformer, d'abord par la couche Attention, puis par la couche FFN. La couche Attention traite les entités horizontalement, tandis que la couche FFN traite les dimensions verticalement.
Étape 4 : L'étape 3 est répétée pour 32 couches du bloc Transformer. Enfin, les dimensions de la matrice résultante sont les mêmes que celles utilisées pour les dimensions des fonctionnalités.
Étape 5 : Enfin, cette matrice est reconvertie à la taille de la matrice de vocabulaire d'origine, qui est de 128 Ko, afin que le modèle puisse sélectionner et cartographier les mots disponibles dans le vocabulaire.
C'est ainsi que LlaMa 3 obtient des scores élevés dans ces critères et crée l'effet LlaMa 3.
Nous résumerons plusieurs termes facilement confus en langage bref :
1. max_seq_len (longueur maximale de la séquence)
Il s'agit du nombre maximum de jetons que le modèle peut accepter en un seul traitement.
Dans le modèle LlaMa 3-8B, ce paramètre est défini sur 8 000 jetons, soit une taille de fenêtre contextuelle = 8K. Cela signifie que le nombre maximum de jetons que le modèle peut prendre en compte en un seul traitement est de 8 000. Ceci est essentiel pour comprendre de longs textes ou maintenir le contexte de conversations à long terme.
2. Taille du vocabulaire
C'est le nombre de tous les jetons différents que le modèle peut reconnaître. Cela inclut tous les mots, signes de ponctuation et caractères spéciaux possibles. Le vocabulaire du modèle est de 128 000, exprimé sous la forme Vocabulary-size = 128K. Cela signifie que le modèle est capable de reconnaître et de traiter 128 000 jetons différents, qui incluent divers mots, signes de ponctuation et caractères spéciaux.
3. Couches d'attention
Un composant principal du modèle Transformer. Il est principalement responsable du traitement des données d'entrée en apprenant quelles parties des données d'entrée sont les plus importantes (c'est-à-dire quels jetons sont « surveillés »). Un modèle peut comporter plusieurs couches de ce type, chacune essayant de comprendre les données d'entrée sous un angle différent.
Le modèle LlaMa 3-8B contient 32 couches de traitement, soit un nombre de couches = 32. Ces couches comprennent plusieurs couches d'attention et d'autres types de couches réseau, chacune traitant et comprenant les données d'entrée sous un angle différent.
4. Bloc transformateur
Contient des modules de plusieurs couches différentes, comprenant généralement au moins une couche d'attention et un réseau Feed-Forward. Un modèle peut avoir plusieurs blocs de transformateur. Ces blocs sont connectés séquentiellement et la sortie de chaque bloc est l'entrée du bloc suivant. Le bloc transformateur peut également être appelé couche de décodeur.
Dans le contexte du modèle Transformer, on dit généralement que le modèle a "32 couches", ce qui peut équivaloir à dire que le modèle a "32 blocs Transformer". Chaque bloc Transformer contient généralement une couche d'auto-attention et une couche de réseau neuronal à action directe. Ces deux sous-couches forment ensemble une unité de traitement complète ou « couche ».
Ainsi, lorsque nous disons que le modèle comporte 32 blocs Transformer, nous décrivons en fait que le modèle est composé de 32 unités de traitement de ce type, chacune étant capable de traiter l'auto-attention et de traiter les données en réseau par anticipation. Cette présentation met l'accent sur la structure hiérarchique du modèle et ses capacités de traitement à chaque niveau.
En résumé, « 32 couches » et « 32 blocs Transformer » sont fondamentalement synonymes lorsqu'ils décrivent la structure du modèle Transformer. Ils signifient tous deux que le modèle contient 32 cycles de traitement de données indépendants, et chaque cycle inclut l'auto-attention et le fonctionnement du réseau Feedforward.
5. Feature-dimension
Il s'agit de la dimension de chaque vecteur lorsque le jeton d'entrée est représenté comme un vecteur dans le modèle.
Chaque jeton est converti en un vecteur contenant 4096 caractéristiques dans le modèle, c'est-à-dire Feature-dimension = 4096. Cette dimension élevée permet au modèle de capturer des informations sémantiques et des relations contextuelles plus riches.
6. Têtes d'attention
Dans chaque couche d'attention, il peut y avoir plusieurs têtes d'attention, et chaque tête analyse indépendamment les données d'entrée sous différents angles.
Chaque couche d'attention contient 32 têtes d'attention indépendantes, c'est-à-dire un nombre de têtes d'attention = 32. Ces responsables analysent les données d'entrée sous différents aspects et fournissent conjointement des capacités d'analyse de données plus complètes.
7. Dimensions cachées
Cela fait généralement référence à la largeur de la couche dans le réseau Feed-Forward, c'est-à-dire le nombre de neurones dans chaque couche. En règle générale, les dimensions cachées seront plus grandes que la dimension caractéristique, ce qui permet au modèle de créer une représentation des données plus riche en interne.
Dans les réseaux Feed-Forward, la dimension de la couche cachée est de 5325, c'est-à-dire Dimensions cachées = 5325. Cette dimension est plus grande que la dimension des fonctionnalités, ce qui permet au modèle d'effectuer une traduction et un apprentissage plus approfondis des fonctionnalités entre les couches internes.
Relations et valeurs :
Relation entre les couches d'attention et les têtes d'attention : chaque couche d'attention peut contenir plusieurs têtes d'attention.
Relation numérique : un modèle peut avoir plusieurs blocs de transformation, chaque bloc contient une couche d'attention et une ou plusieurs autres couches. Chaque couche d'attention peut avoir plusieurs têtes d'attention. De cette manière, l’ensemble du modèle effectue un traitement de données complexe dans différentes couches et têtes.
Téléchargez le script de lien officiel du modèle Llama3 : https://llama.meta.com/llama-downloads/
2 Visualisez le modèle
Le code suivant montre comment utiliser la bibliothèque tiktoken pour charger et utiliser un Tokenizer basé sur des paires d'octets pour l'encodage (BPE). Ce tokenizer est conçu pour traiter des données textuelles, en particulier pour une utilisation dans les modèles de traitement du langage naturel et d'apprentissage automatique.
Nous entrons dans Hello World et voyons comment le segmenteur de mots effectue la segmentation des mots.
from pathlib import Pathimport tiktokenfrom tiktoken.load import load_tiktoken_bpeimport torchimport jsonimport matplotlib.pyplot as plttokenizer_path = "Meta-Llama-3-8B/tokenizer.model"special_tokens = ["<|begin_of_text|>","<|end_of_text|>","<|reserved_special_token_0|>","<|reserved_special_token_1|>","<|reserved_special_token_2|>","<|reserved_special_token_3|>","<|start_header_id|>","<|end_header_id|>","<|reserved_special_token_4|>","<|eot_id|>",# end of turn] + [f"<|reserved_special_token_{i}|>" for i in range(5, 256 - 5)]mergeable_ranks = load_tiktoken_bpe(tokenizer_path)tokenizer = tiktoken.Encoding(name=Path(tokenizer_path).name,pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+",mergeable_ranks=mergeable_ranks,special_tokens={token: len(mergeable_ranks) + i for i, token in enumerate(special_tokens)},)tokenizer.decode(tokenizer.encode("hello world!")) Photos
Photos
Lire le fichier modèle

Afficher les noms des 20 premiers paramètres ou poids contenus dans le fichier modèle chargé.
model = torch.load("Meta-Llama-3-8B/consolidated.00.pth")print(json.dumps(list(model.keys())[:20], indent=4)) Pictures
Pictures
- "tok_embeddings.weight": Cela indique que le modèle dispose d'une couche d'intégration de mots qui convertit les mots d'entrée (ou plus généralement, les jetons) en vecteurs de dimension fixe. Il s'agit de la première étape dans la plupart des modèles de traitement du langage naturel.
- "layers.0.attention..." et "layers.1.attention..." : Ces paramètres représentent plusieurs couches, chaque couche contenant un module de mécanisme d'attention. Dans ce module, wq, wk, wv et wo représentent respectivement les matrices de poids de la requête, de la clé, de la valeur et de la sortie. Il s'agit du composant principal du modèle Transformer et est utilisé pour capturer la relation entre les différentes parties de la séquence d'entrée.
- "layers.0.feed_forward..." et "layers.1.feed_forward..." : Ces paramètres indiquent que chaque couche contient également un réseau de rétroaction (Feed Forward Network), qui se compose généralement de deux transformations linéaires, il y a une fonction d'activation non linéaire au milieu. w1, w2 et w3 peuvent représenter les poids de différentes couches linéaires dans ce réseau à action directe.
- "layers.0.attention_norm.weight" et "layers.1.attention_norm.weight" : ces paramètres indiquent qu'il existe une couche de normalisation (éventuellement Layer Normalization) derrière le module d'attention dans chaque couche pour le processus de formation à la stabilisation.
- "layers.0.ffn_norm.weight" et "layers.1.ffn_norm.weight" : Ces paramètres indiquent qu'il existe également une couche de normalisation derrière le réseau feedforward. Le contenu de sortie du code ci-dessus est le même que celui de l'image ci-dessous, qui est un bloc de transformateur dans Llama3.
 Pictures
Pictures
Dans l'ensemble, cette sortie révèle les composants clés d'un modèle d'apprentissage en profondeur basé sur l'architecture Transformer. Ce modèle est largement utilisé dans les tâches de traitement du langage naturel, telles que la classification de textes, la traduction automatique, les systèmes de questions-réponses, etc. La structure de chaque couche est presque la même, y compris le mécanisme d'attention, le réseau de rétroaction et la couche de normalisation, ce qui aide le modèle à capturer les caractéristiques complexes de la séquence d'entrée.
Voir la configuration des paramètres du modèle Llama3 :
with open("Meta-Llama-3-8B/params.json", "r") as f:config = json.load(f)config 图片
图片
- 'dim': 4096 - 表示模型中的隐藏层维度或特征维度。这是模型处理数据时每个向量的大小。
- 'n_layers': 32 - 表示模型中层的数量。在基于Transformer的模型中,这通常指的是编码器和解码器中的层的数量。
- 'n_heads': 32 - 表示在自注意力(Self-Attention)机制中,头(head)的数量。多头注意力机制是Transformer模型的关键特性之一,它允许模型在不同的表示子空间中并行捕获信息。
- 'n_kv_heads': 8 - 这个参数不是标准Transformer模型的常见配置,可能指的是在某些特定的注意力机制中,用于键(Key)和值(Value)的头的数量。
- 'vocab_size': 128256 - 表示模型使用的词汇表大小。这是模型能够识别的不同单词或标记的总数。
- 'multiple_of': 1024 - 这可能是指模型的某些维度需要是1024的倍数,以确保模型结构的对齐或优化。
- 'ffn_dim_multiplier': 1.3 - 表示前馈网络(Feed-Forward Network, FFN)的维度乘数。在Transformer模型中,FFN是每个注意力层后的一个网络,这个乘数可能用于调整FFN的大小。
- 'norm_eps': 1e-05 - 表示在归一化层(如Layer Normalization)中使用的epsilon值,用于防止除以零的错误。这是数值稳定性的一个小技巧。
- 'rope_theta': 500000.0 - 这个参数不是标准Transformer模型的常见配置,可能是指某种特定于模型的技术或优化的参数。它可能与位置编码或某种正则化技术有关。
我们使用这个配置来推断模型的细节,比如:
- 模型有32个Transformer层
- 每个多头注意力块有32个头
- 词汇表的大小等等
dim = config["dim"]n_layers = config["n_layers"]n_heads = config["n_heads"]n_kv_heads = config["n_kv_heads"]vocab_size = config["vocab_size"]multiple_of = config["multiple_of"]ffn_dim_multiplier = config["ffn_dim_multiplier"]norm_eps = config["norm_eps"]rope_theta = torch.tensor(config["rope_theta"])
 图片
图片
将Text转化为Token
代码如下:
prompt = "the answer to the ultimate question of life, the universe, and everything is "tokens = [128000] + tokenizer.encode(prompt)print(tokens)tokens = torch.tensor(tokens)prompt_split_as_tokens = [tokenizer.decode([token.item()]) for token in tokens]print(prompt_split_as_tokens)
[128000, 1820, 4320, 311, 279, 17139, 3488, 315, 2324, 11, 279, 15861, 11, 323, 4395, 374, 220]['<|begin_of_text|>', 'the', ' answer', ' to', ' the', ' ultimate', ' question', ' of', ' life', ',', ' the', ' universe', ',', ' and', ' everything', ' is', ' ']
将令牌转换为它们的嵌入表示
截止到目前,我们的[17x1]令牌现在变成了[17x4096],即长度为4096的17个嵌入(每个令牌一个)。
下图是为了验证我们输入的这句话,是17个token。
 图片
图片
代码如下:
embedding_layer = torch.nn.Embedding(vocab_size, dim)embedding_layer.weight.data.copy_(model["tok_embeddings.weight"])token_embeddings_unnormalized = embedding_layer(tokens).to(torch.bfloat16)token_embeddings_unnormalized.shape
 图片
图片
三、构建Transformer的第一层
我们接着使用 RMS 归一化对嵌入进行归一化,也就是图中这个位置:
 图片
图片
使用公式如下:
 图片
图片
代码如下:
# def rms_norm(tensor, norm_weights):# rms = (tensor.pow(2).mean(-1, keepdim=True) + norm_eps)**0.5# return tensor * (norm_weights / rms)def rms_norm(tensor, norm_weights):return (tensor * torch.rsqrt(tensor.pow(2).mean(-1, keepdim=True) + norm_eps)) * norm_weights
这段代码定义了一个名为 rms_norm 的函数,它实现了对输入张量(tensor)的RMS(Root Mean Square,均方根)归一化处理。这个函数接受两个参数:tensor 和 norm_weights。tensor 是需要进行归一化处理的输入张量,而 norm_weights 是归一化时使用的权重。
函数的工作原理如下:
- 首先,计算输入张量每个元素的平方(tensor.pow(2))。
- 然后,对平方后的张量沿着最后一个维度(-1)计算均值(mean),并保持维度不变(keepdim=True),这样得到每个元素的均方值。
- 接着,将均方值加上一个很小的正数 norm_eps(为了避免除以零的情况),然后计算其平方根的倒数(torch.rsqrt),得到RMS的倒数。
- 最后,将输入张量与RMS的倒数相乘,再乘以归一化权重 norm_weights,得到归一化后的张量。
在进行归一化处理后,我们的数据形状仍然保持为 [17x4096],这与嵌入层的形状相同,只不过数据已经过归一化。
token_embeddings = rms_norm(token_embeddings_unnormalized, model["layers.0.attention_norm.weight"])token_embeddings.shape
 图片
图片
 图片
图片
接下来,我们介绍注意力机制的实现,也就是下图中的红框标注的位置:
 图片
图片
 图片
图片
1. 输入句子
- 描述:这是我们的输入句子。
- 解释:输入句子被表示为一个矩阵 ( X ),其中每一行代表一个词的嵌入向量。
2. 嵌入每个词
- 描述:我们对每个词进行嵌入。
- 解释:输入句子中的每个词被转换为一个高维向量,这些向量组成了矩阵 ( X )。
3. 分成8个头
- 描述:将矩阵 ( X ) 分成8个头。我们用权重矩阵 ( W^Q )、( W^K ) 和 ( W^V ) 分别乘以 ( X )。
- 解释:多头注意力机制将输入矩阵 ( X ) 分成多个头(这里是8个),每个头有自己的查询(Query)、键(Key)和值(Value)矩阵。具体来说,输入矩阵 ( X ) 分别与查询权重矩阵 ( W^Q )、键权重矩阵 ( W^K ) 和值权重矩阵 ( W^V ) 相乘,得到查询矩阵 ( Q )、键矩阵 ( K ) 和值矩阵 ( V )。
4. 计算注意力
- 描述:使用得到的查询、键和值矩阵计算注意力。
- 解释:对于每个头,使用查询矩阵 ( Q )、键矩阵 ( K ) 和值矩阵 ( V ) 计算注意力分数。具体步骤包括:
计算 ( Q ) 和 ( K ) 的点积。
对点积结果进行缩放。
应用softmax函数得到注意力权重。
用注意力权重乘以值矩阵 ( V ) 得到输出矩阵 ( Z )。
5. 拼接结果矩阵
- 描述:将得到的 ( Z ) 矩阵拼接起来,然后用权重矩阵 ( W^O ) 乘以拼接后的矩阵,得到层的输出。
- 解释:将所有头的输出矩阵 ( Z ) 拼接成一个矩阵,然后用输出权重矩阵 ( W^O ) 乘以这个拼接后的矩阵,得到最终的输出矩阵 ( Z )。
额外说明
- 查询、键、值和输出向量的形状:在加载查询、键、值和输出向量时,注意到它们的形状分别是 [4096x4096]、[1024x4096]、[1024x4096]、[1024x4096] 和 [4096x4096]。
- 并行化注意力头的乘法:将它们捆绑在一起有助于并行化注意力头的乘法。
这张图展示了Transformer模型中多头注意力机制的实现过程,从输入句子的嵌入开始,经过多头分割、注意力计算,最后拼接结果并生成输出。每个步骤都详细说明了如何从输入矩阵 ( X ) 生成最终的输出矩阵 ( Z )。
当我们从模型中加载查询(query)、键(key)、值(value)和输出(output)向量时,我们注意到它们的形状分别是 [4096x4096]、[1024x4096]、[1024x4096]、[4096x4096]
乍一看这很奇怪,因为理想情况下我们希望每个头的每个q、k、v和o都是单独的
print(model["layers.0.attention.wq.weight"].shape,model["layers.0.attention.wk.weight"].shape,model["layers.0.attention.wv.weight"].shape,model["layers.0.attention.wo.weight"].shape)
 Image
Image
La forme de la matrice de poids de requête (wq.weight) est [4096, 4096]. La forme de la matrice de poids clé (wk.weight) est [1024, 4096]. La forme de la matrice de pondération des valeurs (wv.weight) est [1024, 4096]. La forme de la matrice de poids de sortie (Output) (wo.weight) est [4096, 4096]. Les résultats de sortie montrent que les formes des matrices de poids de requête (Q) et de sortie (O) sont les mêmes [4096, 4096]. Cela signifie que la fonctionnalité d'entrée et la fonctionnalité de sortie ont des dimensions de 4 096 pour la requête et la sortie. Les formes des matrices de poids clé (K) et valeur (V) sont également les mêmes, toutes deux [1024, 4096]. Cela montre que les dimensions des fonctionnalités d'entrée pour les clés et les valeurs sont 4096, mais que les dimensions des fonctionnalités de sortie sont compressées à 1024. La forme de ces matrices de poids reflète la manière dont le concepteur du modèle définit les dimensions des différentes parties du mécanisme d'attention. En particulier, les dimensions des clés et des valeurs sont probablement réduites pour réduire la complexité de calcul et la consommation de mémoire, tandis que conserver les requêtes et les sorties en dimensionnalité plus élevée peut permettre de conserver plus d'informations. Ce choix de conception dépend de l'architecture du modèle spécifique et du scénario d'application
Utilisons la phrase « J'admire Li Hongzhang » comme exemple pour simplifier le processus de mise en œuvre consistant à expliquer le mécanisme d'attention dans cette figure. Entrez la phrase : Tout d'abord, nous avons la phrase « J'admire Li Hongzhang ». Avant de traiter cette phrase, nous devons convertir chaque mot de la phrase en une forme mathématiquement traitable, c'est-à-dire un vecteur de mots. Ce processus est appelé intégration de mots.
Intégration de mots : chaque mot, tel que "Je", "appréciation", "Li Hongzhang", sera converti en un vecteur de taille fixe. Ces vecteurs contiennent les informations sémantiques des mots.
Divisé en plusieurs têtes : Afin de permettre au modèle de comprendre la phrase sous différentes perspectives, nous divisons le vecteur de chaque mot en plusieurs parties, voici 8 têtes. Chaque tête se concentre sur un aspect différent de la phrase.
Calculer l'attention : Pour chaque tête, nous calculons quelque chose appelé attention. Ce processus comporte trois étapes : Prenons l'exemple de « J'apprécie Li Hongzhang ». Si nous voulons nous concentrer sur le mot « appréciation », alors « appréciation » est la requête, et d'autres mots tels que « Je » et « Li Hongzhang ». sont des clés. Le vecteur de est la valeur.
Requête (Q) : C'est la partie où nous voulons trouver des informations. Clé (K) : C'est la partie qui contient l'information. Valeur (V) : Il s'agit du contenu réel de l'information. Épissage et sortie : Après avoir calculé l'attention de chaque tête, nous concaténons ces résultats et générons la sortie finale via une matrice de poids Wo. Cette sortie sera utilisée dans la couche de traitement suivante ou dans le cadre du résultat final.
Le problème de forme mentionné dans les commentaires sur la figure concerne la manière de stocker et de traiter efficacement ces vecteurs dans un ordinateur. Dans l'implémentation réelle du code, afin d'améliorer l'efficacité, les développeurs peuvent regrouper les vecteurs de requête, de clé et de valeur de plusieurs en-têtes ensemble au lieu de traiter chaque en-tête individuellement. Cela permet de tirer parti des capacités de traitement parallèle des ordinateurs modernes pour accélérer les calculs.
- La forme de la matrice de poids de requête (wq.weight) est [4096, 4096].
- La forme de la matrice de poids clé (wk.weight) est [1024, 4096]. La forme de la matrice de poids
- Value (wv.weight) est [1024, 4096].
- La forme de la matrice de poids de sortie (Output) (wo.weight) est [4096, 4096].
Les résultats de sortie montrent que :
- Les formes des matrices de poids de requête (Q) et de sortie (O) sont les mêmes, toutes deux [4096, 4096]. Cela signifie que la fonctionnalité d'entrée et la fonctionnalité de sortie ont des dimensions de 4 096 pour la requête et la sortie.
- Les formes des matrices de poids clé (K) et valeur (V) sont également les mêmes, toutes deux [1024, 4096]. Cela montre que les dimensions des fonctionnalités d'entrée pour les clés et les valeurs sont de 4 096, mais que les dimensions des fonctionnalités de sortie sont compressées à 1 024.
La forme de ces matrices de poids reflète la façon dont le concepteur du modèle définit les dimensions des différentes parties du mécanisme d'attention. En particulier, les dimensions des clés et des valeurs sont probablement réduites pour réduire la complexité de calcul et la consommation de mémoire, tandis que conserver les requêtes et les sorties en dimensionnalité plus élevée peut permettre de conserver plus d'informations. Ce choix de conception dépend de l'architecture du modèle spécifique et du scénario d'application
Utilisons la phrase « J'admire Li Hongzhang » comme exemple pour simplifier le processus de mise en œuvre consistant à expliquer le mécanisme d'attention dans cette figure.
- Entrez la phrase : Tout d'abord, nous avons la phrase « J'admire Li Hongzhang ». Avant de traiter cette phrase, nous devons convertir chaque mot de la phrase en une forme mathématiquement traitable, c'est-à-dire un vecteur de mots. Ce processus est appelé intégration de mots.
- Intégration de mots : chaque mot, tel que "Je", "appréciation", "Li Hongzhang", sera converti en un vecteur de taille fixe. Ces vecteurs contiennent les informations sémantiques des mots.
- Divisé en plusieurs têtes : Afin de permettre au modèle de comprendre la phrase sous différents angles, nous divisons le vecteur de chaque mot en plusieurs parties, voici 8 têtes. Chaque tête se concentre sur un aspect différent de la phrase.
- Calculer l'attention : Pour chaque tête, nous calculons quelque chose appelé attention. Ce processus comporte trois étapes : Prenons l'exemple de « J'apprécie Li Hongzhang ». Si nous voulons nous concentrer sur le mot « appréciation », alors « appréciation » est la requête, et d'autres mots tels que « Je » et « Li Hongzhang ». sont des clés. Le vecteur de est la valeur.
Requête (Q) : C'est la partie où nous voulons trouver des informations.
Clé (K) : C'est la partie qui contient des informations.
Valeur (V) : Il s'agit du contenu réel de l'information.
- Épissage et sortie : après avoir calculé l'attention de chaque tête, nous assemblons ces résultats et générons le résultat final via une matrice de poids Wo. Cette sortie sera utilisée dans la couche de traitement suivante ou dans le cadre du résultat final.
Le problème de forme mentionné dans les commentaires sur la figure concerne la manière de stocker et de traiter efficacement ces vecteurs dans un ordinateur. Dans l'implémentation réelle du code, afin d'améliorer l'efficacité, les développeurs peuvent regrouper les vecteurs de requête, de clé et de valeur de plusieurs en-têtes ensemble au lieu de traiter chaque en-tête individuellement. Cela permet de tirer parti des capacités de traitement parallèle des ordinateurs modernes pour accélérer les calculs.
Nous continuons à utiliser la phrase « J'apprécie Li Hongzhang » pour expliquer le rôle des matrices de poids WQ, WK, WV et WO.
Dans le modèle Transformer, chaque mot est converti en vecteur grâce à l'intégration de mots. Ces vecteurs subissent ensuite une série de transformations linéaires pour calculer les scores d’attention. Ces transformations linéaires sont implémentées à travers les matrices de poids WQ, WK, WV et WO.
- WQ (matrice de poids Q) : Cette matrice permet de convertir le vecteur de chaque mot en un vecteur « requête ». Dans notre exemple, si nous voulons nous concentrer sur le mot « appréciation », nous multiplierons le vecteur « appréciation » par WQ pour obtenir le vecteur de requête.
- WK (matrice de poids K) : Cette matrice permet de convertir le vecteur de chaque mot en un vecteur « Clé ». De même, nous multiplierons le vecteur de chaque mot, y compris « I » et « Li Hongzhang », par WK pour obtenir le vecteur clé.
- WV (matrice de poids V) : Cette matrice permet de convertir le vecteur de chaque mot en un vecteur « valeur ». Après avoir multiplié chaque vecteur de mot par WV, nous obtenons un vecteur de valeur. Ces trois matrices (WQ, WK, WV) sont utilisées pour générer différents vecteurs de requête, de clé et de valeur pour chaque en-tête. Cela permet à chaque tête de se concentrer sur un aspect différent de la phrase.
- WQ (matrice de poids Q), WK (matrice de poids K), WV (matrice de poids V) et WO (matrice de poids O). Ces matrices sont des paramètres du modèle Transformer. Elles sont passées par l'algorithme de rétropropagation lors de la formation du modèle. processus. Il s’apprend des méthodes d’optimisation telles que la descente de gradient.
Dans l'ensemble du processus, WQ, WK, WV et WO sont appris grâce à la formation. Ils déterminent comment le modèle convertit les vecteurs de mots d'entrée en différentes représentations et comment combiner ces représentations pour obtenir le résultat final. Ces matrices constituent l'élément central du mécanisme d'attention dans le modèle Transformer et permettent au modèle de capturer la relation entre les différents mots de la phrase.
WQ (matrice de poids Q), WK (matrice de poids K), WV (matrice de poids V) et WO (matrice de poids O). Ces matrices sont des paramètres du modèle Transformer. Elles sont transmises par rétro-propagation pendant le processus de formation du modèle. . Cela s'apprend des méthodes d'optimisation telles que les algorithmes et la descente de gradient.
Voyons comment fonctionne ce processus d'apprentissage :
- 初始化:在训练开始之前,这些矩阵通常会被随机初始化。这意味着它们的初始值是随机选取的,这样可以打破对称性并开始学习过程。
- 前向传播:在模型的训练过程中,输入数据(如句子“我欣赏李鸿章”)会通过模型的各个层进行前向传播。在注意力机制中,输入的词向量会与WQ、WK、WV矩阵相乘,以生成查询、键和值向量。
- 计算损失:模型的输出会与期望的输出(通常是训练数据中的标签)进行比较,计算出一个损失值。这个损失值衡量了模型的预测与实际情况的差距。
- 反向传播:损失值会通过反向传播算法传回模型,计算每个参数(包括WQ、WK、WV和WO)对损失的影响,即它们的梯度。
- 参数更新:根据计算出的梯度,使用梯度下降或其他优化算法来更新这些矩阵的值。这个过程会逐渐减小损失值,使模型的预测更加准确。
- 迭代过程:这个前向传播、损失计算、反向传播和参数更新的过程会在训练数据上多次迭代进行,直到模型的性能达到一定的标准或者不再显著提升。
通过这个训练过程,WQ、WK、WV和WO这些矩阵会逐渐调整它们的值,以便模型能够更好地理解和处理输入数据。在训练完成后,这些矩阵将固定下来,用于模型的推理阶段,即对新的输入数据进行预测。
四、展开查询向量
在本小节中,我们将从多个注意力头中展开查询向量,得到的形状是 [32x128x4096] 这里,32 是 llama3 中注意力头的数量,128 是查询向量的大小,而 4096 是令牌嵌入的大小。
q_layer0 = model["layers.0.attention.wq.weight"]head_dim = q_layer0.shape[0] // n_headsq_layer0 = q_layer0.view(n_heads, head_dim, dim)q_layer0.shape
 图片
图片
这段代码通过对模型中第一层的查询(Q)权重矩阵进行重塑(reshape),将其分解为多个注意力头的形式,从而揭示了32和128这两个维度。
- q_layer0 = model["layers.0.attention.wq.weight"]:这行代码从模型中提取第一层的查询(Q)权重矩阵。
- head_dim = q_layer0.shape[0] // n_heads:这行代码计算每个注意力头的维度大小。它通过将查询权重矩阵的第一个维度(原本是4096)除以注意力头的数量(n_heads),得到每个头的维度。如果n_heads是32(即模型设计为有32个注意力头),那么head_dim就是4096 // 32 = 128。
- q_layer0 = q_layer0.view(n_heads, head_dim, dim):这行代码使用.view()方法重塑查询权重矩阵,使其形状变为[n_heads, head_dim, dim]。这里dim很可能是原始特征维度4096,n_heads是32,head_dim是128,因此重塑后的形状是[32, 128, 4096]。
- q_layer0.shape 输出:torch.Size([32, 128, 4096]):这行代码打印重塑后的查询权重矩阵的形状,确认了其形状为[32, 128, 4096]。
之所以在这段代码中出现了32和128这两个维度,而在之前的代码段中没有,是因为这段代码通过重塑操作明确地将查询权重矩阵分解为多个注意力头,每个头具有自己的维度。32代表了模型中注意力头的数量,而128代表了分配给每个头的特征维度大小。这种分解是为了实现多头注意力机制,其中每个头可以独立地关注输入的不同部分,最终通过组合这些头的输出来提高模型的表达能力。
实现第一层的第一个头
访问了第一层第一个头的查询(query)权重矩阵,这个查询权重矩阵的大小是 [128x4096]。
q_layer0_head0 = q_layer0[0]q_layer0_head0.shape
 图片
图片
我们现在将查询权重与令牌嵌入相乘,以获得令牌的查询
在这里,你可以看到结果形状是 [17x128],这是因为我们有17个令牌,每个令牌都有一个长度为128的查询(每个令牌在一个头上方的查询)。
br
 Picture
Picture
Ce code effectue une opération de multiplication matricielle, en comparant les intégrations de jetons (token_embeddings) avec la transposition (.T) de la matrice de poids de requête (q_layer0_head0) de la première tête de la première couche Multipliez pour générer un par -vecteur de requête de jeton (q_per_token).
- q_per_token = torch.matmul(token_embeddings, q_layer0_head0.T) :
torch.matmul est la fonction de multiplication matricielle de PyTorch, qui peut gérer la multiplication de deux tenseurs.
token_embeddings doit être un tenseur de forme [17, 4096], représentant 17 jetons, chacun représenté par un vecteur d'intégration de 4096 dimensions.
q_layer0_head0 est la matrice de poids de requête de la première tête de la première couche, et sa forme originale est [128, 4096]. .T est l'opération de transposition dans PyTorch, qui transpose la forme de q_layer0_head0 en [4096, 128].
De cette façon, la multiplication matricielle de token_embeddings et q_layer0_head0.T est la multiplication de [17, 4096] et [4096, 128], et le résultat est un tenseur de forme [17, 128].
- q_per_token.shape et sortie : torch.Size([17, 128]) :
Cette ligne de code imprime la forme du tenseur q_per_token, confirmant qu'il s'agit bien de [17, 128].
Cela signifie que pour chaque jeton saisi (17 au total), nous disposons désormais d'un vecteur de requête à 128 dimensions. Ce vecteur de requête à 128 dimensions est obtenu en multipliant l'intégration de jetons et la matrice de poids de requête et peut être utilisé pour les calculs ultérieurs du mécanisme d'attention.
En résumé, ce code convertit le vecteur d'intégration de chaque jeton en un vecteur de requête par multiplication matricielle, préparant ainsi la prochaine étape de mise en œuvre du mécanisme d'attention. Chaque jeton possède désormais un vecteur de requête qui lui correspond, et ces vecteurs de requête seront utilisés pour calculer les scores d'attention avec d'autres jetons.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Le concept d'apprentissage profond est né de la recherche sur les réseaux de neurones artificiels. Un perceptron multicouche contenant plusieurs couches cachées est une structure d'apprentissage profond. L'apprentissage profond combine des fonctionnalités de bas niveau pour former des représentations de haut niveau plus abstraites afin de caractériser des catégories ou des caractéristiques de données. Il est capable de découvrir des représentations de fonctionnalités distribuées de données. L'apprentissage profond est un type d'apprentissage automatique, et l'apprentissage automatique est le seul moyen d'atteindre l'intelligence artificielle. Alors, quelles sont les différences entre les différentes architectures de systèmes d’apprentissage profond ? 1. Réseau entièrement connecté (FCN) Un réseau entièrement connecté (FCN) se compose d'une série de couches entièrement connectées, chaque neurone de chaque couche étant connecté à chaque neurone d'une autre couche. Son principal avantage est qu'il est « indépendant de la structure », c'est-à-dire qu'aucune hypothèse particulière concernant l'entrée n'est requise. Bien que cette agnostique structurelle rende la
 « AI Factory » favorisera la refonte de l'ensemble de la pile logicielle, et NVIDIA fournit des conteneurs Llama3 NIM que les utilisateurs peuvent déployer
Jun 08, 2024 pm 07:25 PM
« AI Factory » favorisera la refonte de l'ensemble de la pile logicielle, et NVIDIA fournit des conteneurs Llama3 NIM que les utilisateurs peuvent déployer
Jun 08, 2024 pm 07:25 PM
Selon les informations de ce site le 2 juin, lors du discours d'ouverture du Huang Renxun 2024 Taipei Computex, Huang Renxun a présenté que l'intelligence artificielle générative favoriserait la refonte de l'ensemble de la pile logicielle et a démontré ses microservices cloud natifs NIM (Nvidia Inference Microservices). . Nvidia estime que « l'usine IA » déclenchera une nouvelle révolution industrielle : en prenant comme exemple l'industrie du logiciel lancée par Microsoft, Huang Renxun estime que l'intelligence artificielle générative favorisera sa refonte complète. Pour faciliter le déploiement de services d'IA par les entreprises de toutes tailles, NVIDIA a lancé les microservices cloud natifs NIM (Nvidia Inference Microservices) en mars de cette année. NIM+ est une suite de microservices cloud natifs optimisés pour réduire les délais de commercialisation
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA est basé sur l'architecture JPA et interagit avec la base de données via le mappage, l'ORM et la gestion des transactions. Son référentiel fournit des opérations CRUD et les requêtes dérivées simplifient l'accès à la base de données. De plus, il utilise le chargement paresseux pour récupérer les données uniquement lorsque cela est nécessaire, améliorant ainsi les performances.
 Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Il y a quelque temps, un tweet soulignant l'incohérence entre le schéma d'architecture du Transformer et le code de l'article de l'équipe Google Brain "AttentionIsAllYouNeed" a déclenché de nombreuses discussions. Certains pensent que la découverte de Sebastian était une erreur involontaire, mais elle est aussi surprenante. Après tout, compte tenu de la popularité du document Transformer, cette incohérence aurait dû être mentionnée mille fois. Sebastian Raschka a déclaré en réponse aux commentaires des internautes que le code « le plus original » était effectivement cohérent avec le schéma d'architecture, mais que la version du code soumise en 2017 a été modifiée, mais que le schéma d'architecture n'a pas été mis à jour en même temps. C’est aussi la cause profonde des discussions « incohérentes ».
 Docker achève le déploiement local du grand modèle open source LLama3 en trois minutes
Apr 26, 2024 am 10:19 AM
Docker achève le déploiement local du grand modèle open source LLama3 en trois minutes
Apr 26, 2024 am 10:19 AM
LLaMA-3 (LargeLanguageModelMetaAI3) est un modèle d'intelligence artificielle générative open source à grande échelle développé par Meta Company. Il ne présente aucun changement majeur dans la structure du modèle par rapport à la génération précédente LLaMA-2. Le modèle LLaMA-3 est divisé en différentes versions, notamment petite, moyenne et grande, pour répondre aux différents besoins d'application et ressources informatiques. La taille des paramètres des petits modèles est de 8B, la taille des paramètres des modèles moyens est de 70B et la taille des paramètres des grands modèles atteint 400B. Cependant, lors de la formation, l'objectif est d'atteindre une fonctionnalité multimodale et multilingue, et les résultats devraient être comparables à GPT4/GPT4V. Installer OllamaOllama est un grand modèle de langage open source (LL
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
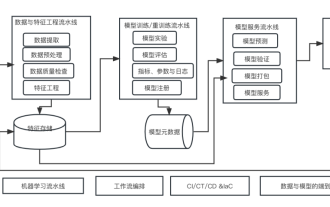 Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Nous vivons une ère d’autonomisation de l’IA, et l’apprentissage automatique est un moyen technique important pour y parvenir. Alors, existe-t-il une architecture universelle de système d’apprentissage automatique ? Dans le champ cognitif des programmeurs expérimentés, tout n'est rien, notamment pour l'architecture système. Cependant, il est possible de créer une architecture de système d'apprentissage automatique évolutive et fiable si elle est applicable à la plupart des systèmes ou cas d'utilisation basés sur l'apprentissage automatique. Du point de vue du cycle de vie du machine learning, cette architecture dite universelle couvre les étapes clés du machine learning, du développement de modèles de machine learning au déploiement de systèmes de formation et de systèmes de services dans des environnements de production. Nous pouvons essayer de décrire une telle architecture de système d’apprentissage automatique à partir des dimensions de 10 éléments. 1.
