
 Périphériques technologiques
IA
La première reconstruction purement visuelle et statique de la conduite autonome
Périphériques technologiques
IA
La première reconstruction purement visuelle et statique de la conduite autonome
La première reconstruction purement visuelle et statique de la conduite autonome

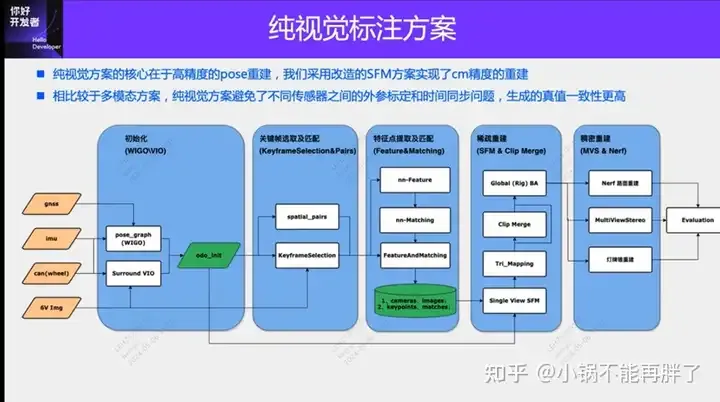
Une solution d'annotation purement visuelle utilise principalement la vision ainsi que certaines données du GPS, de l'IMU et des capteurs de vitesse de roue pour l'annotation dynamique. Bien entendu, pour les scénarios de production de masse, il n’est pas nécessaire que cela soit purement visuel. Certains véhicules produits en série seront équipés de capteurs comme le radar à semi-conducteurs (AT128). Si nous créons une boucle fermée de données dans la perspective d'une production de masse et utilisons tous ces capteurs, nous pouvons résoudre efficacement le problème de l'étiquetage des objets dynamiques. Mais notre plan ne prévoit pas de radar à semi-conducteurs. Par conséquent, nous présenterons cette solution d’étiquetage de production de masse la plus courante.
Le cœur de la solution d'annotation purement visuelle réside dans la reconstruction de pose de haute précision. Nous utilisons le schéma de reconstruction de pose Structure from Motion (SFM) pour garantir la précision de la reconstruction. Cependant, le SFM traditionnel, en particulier le SFM incrémentiel, est très lent et coûteux en termes de complexité de calcul. La complexité de calcul est O(n^4), où n est le nombre d'images. Ce type d'efficacité de reconstruction est inacceptable pour l'annotation de données de modèles à grande échelle. Nous avons apporté quelques améliorations à la solution SFM.
La reconstruction améliorée du clip est principalement divisée en trois modules : 1) Utilisez les données multi-capteurs, le GNSS, l'IMU et le compteur de vitesse de roue pour construire l'optimisation pose_graph et obtenir la pose initiale. Cet algorithme est appelé Wheel-Imu-GNSS -Odometry ( WIGO) ; 2) Extraction et mise en correspondance des caractéristiques de l'image, et triangulation directement en utilisant la pose initialisée pour obtenir les points 3D initiaux ; 3) Enfin, un BA (Bundle Adjustment) global est effectué ; D'une part, notre solution évite le SFM incrémental, et d'autre part, des opérations parallèles peuvent être réalisées entre différents clips, améliorant ainsi considérablement l'efficacité de la reconstruction de pose. Par rapport à la reconstruction incrémentale existante, elle peut être réalisée de 10 à 20. fois l'amélioration de l'efficacité.
Au cours du processus de reconstruction unique, notre solution a également apporté quelques optimisations. Par exemple, nous avons utilisé des fonctionnalités basées sur l'apprentissage (Superpoint et Superglue), l'une est le point caractéristique et l'autre est la méthode de correspondance , pour remplacer les points clés SIFT traditionnels. L'avantage de l'apprentissage de NN-Features est que d'une part, les règles peuvent être conçues de manière basée sur les données pour répondre à certains besoins personnalisés et améliorer la robustesse dans certaines textures faibles et situations d'éclairage sombre, d'autre part, cela peut s'améliorer ; Efficacité de la détection et de la correspondance des points clés. Nous avons réalisé quelques expériences comparatives et constaté que le taux de réussite des fonctionnalités NN dans les scènes de nuit sera environ 4 fois supérieur à celui de SFIT, de 20 % à 80 %.
Après avoir obtenu le résultat de la reconstruction d'un seul clip, nous regrouperons plusieurs clips. Différent du schéma de correspondance de structure de mappage HDmap existant, afin de garantir la précision de l'agrégation, nous adoptons l'agrégation au niveau des points caractéristiques, c'est-à-dire que les contraintes d'agrégation entre les clips sont mises en œuvre via la correspondance des points caractéristiques. Cette opération est similaire à la détection de fermeture de boucle dans SLAM. Premièrement, le GPS est utilisé pour déterminer certaines trames de correspondance candidates ; puis, les points caractéristiques et les descriptions sont utilisés pour faire correspondre les images. Enfin, ces contraintes de fermeture de boucle sont combinées pour construire un BA (Bundle) global ; Ajustement) et optimiser. À l'heure actuelle, la précision et l'indice RTE de notre solution dépassent de loin certaines solutions de SLAM visuel ou de cartographie existantes. Expérience : utilisez la version colmap cuda, utilisez 180 images, une résolution de 3848*2168, définissez manuellement les paramètres internes et utilisez les paramètres par défaut pour le reste. La reconstruction clairsemée prend environ 15 minutes et l'ensemble de la reconstruction dense prend extrêmement longtemps. temps (1-2h)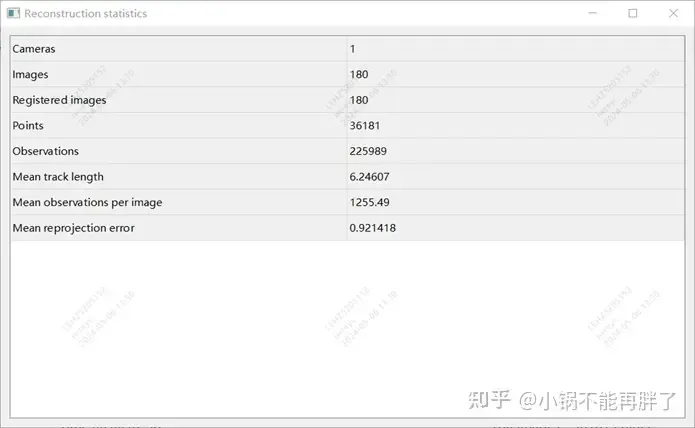
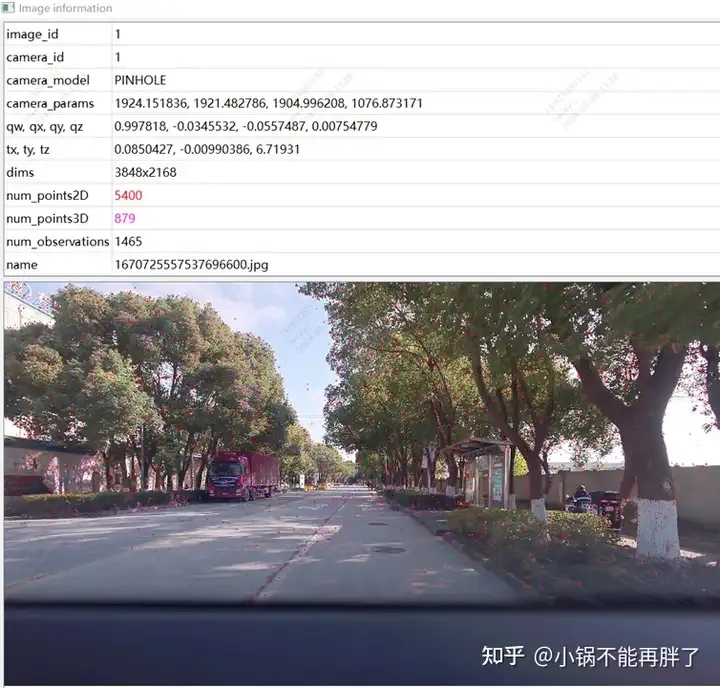





Utilisez des multi-caméras circonférentielles et panoramiques : optimisation de la carte de correspondance des points caractéristiques, éléments d'optimisation des paramètres internes et externes et utilisation de l'odom existant.
https://github.com/colmap/colmap/blob/main/pycolmap/custom_bundle_adjustment.py
pyceres.solve(solver_options, bundle_adjuster.problem, summary)
3DGS accélère la reconstruction dense, sinon cela prendra trop de temps accepter
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
