

Lisez GPT-4o vs GPT-4 Turbo dans un seul article

Bonjour les gens, je m'appelle Luga, aujourd'hui nous parlerons des technologies liées au domaine écologique de l'intelligence artificielle (IA) - modèle GPT-4o.
Le 13 mai 2024, OpenAI a lancé de manière innovante son modèle le plus avancé et le plus avant-gardiste, GPT-4o, ce qui marque une avancée majeure dans le domaine des chatbots d'intelligence artificielle et des modèles de langage à grande échelle. Annonciateur d'une nouvelle ère de capacités d'intelligence artificielle, GPT-4o bénéficie d'améliorations significatives de performances qui surpassent son prédécesseur, GPT-4, en termes de vitesse et de polyvalence.
Cette avancée révolutionnaire résout les problèmes de latence qui affligeaient souvent son prédécesseur, garantissant une expérience utilisateur transparente et réactive.

Qu'est-ce que GPT-4o ?
Le 13 mai 2024, OpenAI a publié son dernier et le plus avancé modèle d'intelligence artificielle GPT-4o, où le « o » signifie « omni », ce qui signifie « tout » ou "universel". Ce modèle est une nouvelle génération de modèle de grand langage basé sur GPT-4 Turbo. Par rapport aux modèles précédents, GPT-4o s'est considérablement amélioré en termes de vitesse de sortie, de qualité de réponse et de langues prises en charge, et a apporté des innovations révolutionnaires dans le format de traitement des données d'entrée.
L'innovation la plus remarquable du modèle GPT-4o+ est qu'il abandonne la pratique du modèle précédent consistant à utiliser des réseaux de neurones indépendants pour traiter différents types de données d'entrée, et utilise à la place un seul réseau de neurones unifié pour traiter toutes les entrées. Cette conception innovante confère au GPT-4o+ des capacités de fusion multimodale sans précédent. La fusion multimodale fait référence à l'intégration de différents types de données d'entrée (telles que des images, du texte, de l'audio, etc.) pour le traitement afin d'obtenir des résultats plus complets et plus précis. Les modèles précédents nécessitaient de concevoir différentes structures de réseau lors du traitement de données multimodales, ce qui consommait beaucoup de ressources informatiques et de temps. En utilisant un réseau neuronal unifié, GPT-4o+ permet une connexion transparente de différents types de données d'entrée, améliorant considérablement l'efficacité du traitement. Les modèles de langage traditionnels ne peuvent généralement gérer que la saisie de texte brut et ne peuvent pas gérer des données non textuelles telles que la parole et les images. Cependant, GPT-4o est inhabituel dans le sens où il peut simultanément détecter et analyser des signaux non textuels tels que le bruit de fond, plusieurs sources sonores et les couleurs émotionnelles dans la saisie vocale, et fusionner ces informations multimodales dans le processus de compréhension et de génération sémantique pour produire une sortie plus riche et plus contextuelle.
En plus du traitement des entrées multimodales, GPT-4o+ démontre également d'excellentes capacités de sortie lors de la génération de sorties multilingues. Non seulement il produit des expressions de meilleure qualité, plus grammaticalement correctes et plus concises dans les langues courantes telles que l'anglais, mais GPT-4o+ peut également maintenir le même niveau de sortie dans des scénarios de langues autres que l'anglais. Cela garantit que les utilisateurs de l’anglais et d’autres langues peuvent profiter des capacités supérieures de génération de langage naturel de GPT-4o+.
En général, le plus grand point fort de GPT-4o+ est qu'il dépasse les limites d'une modalité unique et permet d'atteindre une compréhension globale et des capacités de génération multimodales. Grâce à une architecture de réseau neuronal innovante et à un mécanisme de formation, GPT-4o+ peut non seulement obtenir des informations provenant de plusieurs canaux sensoriels, mais également les intégrer lors de la génération pour produire une réponse plus contextuelle et plus personnalisée.
Performances GPT-4o et GPT-4 Turbo ?
GPT-4 est le dernier grand modèle multimodal lancé par OpenAI. Ses performances constituent un saut qualitatif par rapport à la génération précédente GPT-4 Turbo. Ici, nous pouvons mener une analyse comparative des deux dans les aspects clés suivants. Premièrement, il existe une différence de taille de modèle entre le GPT-4 et le GPT-4 Turbo. GPT-4 possède un plus grand nombre de paramètres que GPT-4 Turbo, ce qui signifie qu'il peut gérer des tâches plus complexes et des ensembles de données plus volumineux. Cela permet à GPT-4 d'avoir une plus grande précision et une plus grande maîtrise de la compréhension sémantique, de la génération de texte, etc. C'est
1. Vitesse d'inférence
Selon les données publiées par OpenAI, dans les mêmes conditions matérielles, la vitesse d'inférence de GPT-4o est le double de celle de GPT-4 Turbo. Cette amélioration significative des performances est principalement attribuée à son architecture innovante à modèle unique, qui évite la perte d'efficacité causée par la commutation de mode. L'architecture à modèle unique simplifie non seulement le processus de calcul, mais réduit également considérablement la surcharge en ressources, permettant à GPT-4o de traiter les demandes plus rapidement. Une vitesse d'inférence plus élevée signifie que GPT-4o peut fournir aux utilisateurs des réponses avec une latence plus faible, améliorant considérablement l'expérience interactive. Qu'il s'agisse de conversations en temps réel, de traitement de tâches complexes ou d'applications dans des environnements à forte concurrence, les utilisateurs peuvent bénéficier de réponses de service plus fluides et plus immédiates. Cette optimisation des performances améliore non seulement l'efficacité globale du système, mais fournit également une prise en charge plus fiable et plus efficace pour divers scénarios d'application.
 Comparaison de latence Turbo GPT-4o et GPT-4
Comparaison de latence Turbo GPT-4o et GPT-4
2 Débit
On sait que les premiers modèles GPT sont un peu à la traîne en termes de débit. Par exemple, le dernier GPT-4 Turbo ne peut générer que 20 jetons par seconde. Cependant, GPT-4o a réalisé une avancée majeure à cet égard, étant capable de générer 109 jetons par seconde. Cette amélioration a considérablement amélioré la vitesse de traitement de GPT-4o, offrant ainsi une plus grande efficacité pour divers scénarios d'application.
Malgré cela, le GPT-4o n'est toujours pas le modèle le plus rapide. En prenant comme exemple Llama hébergé sur Groq, il peut générer 280 jetons par seconde, dépassant de loin GPT-4o. Cependant, les avantages de GPT-4o vont au-delà de la vitesse. Ses fonctionnalités avancées et ses capacités de raisonnement le distinguent des applications d’IA en temps réel. L'architecture de modèle unique et l'algorithme d'optimisation de GPT-4o améliorent non seulement l'efficacité informatique, mais réduisent également considérablement le temps de réponse, ce qui lui confère des avantages uniques en matière d'expérience interactive.

Comparaison des débits GPT-4o et GPT-4 Turbo
Analyse comparative dans différents scénarios
De manière générale, lorsque GPT-4o et GPT-4 Turbo gèrent différents types de tâches, en raison de l'architecture et du mode La différence Les capacités de fusion entraînent des différences de performances significatives. Ici, nous analysons principalement les différences entre les deux à partir de trois types de tâches représentatifs : l'extraction de données, la classification et le raisonnement.
1. Extraction de données
Dans les tâches d'extraction de données textuelles, GPT-4 Turbo s'appuie sur ses puissantes capacités de compréhension du langage naturel pour obtenir de bonnes performances. Mais face à des scènes contenant des données non structurées telles que des images et des tableaux, ses capacités deviennent quelque peu limitées.
En revanche, GPT-4o peut intégrer de manière transparente des données de différentes modalités, qu'il s'agisse de texte structuré ou de données non structurées telles que des images et des PDF, il peut identifier et extraire efficacement les informations requises. Cet avantage rend GPT-4o plus compétitif lors du traitement de données mixtes complexes.
Ici, nous prenons comme exemple le scénario contractuel d'une certaine entreprise. L'ensemble de données comprend le contrat-cadre de service (MSA) entre l'entreprise et le client. La longueur des contrats varie, certains ne dépassant pas 5 pages et d’autres dépassant 50 pages.
Dans cette évaluation, nous extrairons un total de 12 champs, tels que le titre du contrat, le nom du client, le nom du fournisseur, les détails de la clause de résiliation, s'il y a un cas de force majeure, etc. Grâce à une collecte de données réelles sur 10 contrats, 12 indicateurs d'évaluation personnalisés ont été mis en place. Ces métriques sont utilisées pour comparer nos données réelles à la sortie LLM pour chaque paramètre du JSON généré par le modèle. Par la suite, nous avons testé GPT-4 Turbo et GPT-4o, et voici les résultats de notre rapport d'évaluation :

Résultats d'évaluation pour les 12 indicateurs correspondant à chaque invite
Dans les résultats de comparaison ci-dessus, nous pouvons conclure que parmi ces 12 champs, GPT-4o est plus performant que GPT-4 Turbo sur 6 champs, a les mêmes résultats sur 5 champs et est légèrement moins performant sur 1 champ.
D'un point de vue absolu, GPT-4 et GPT-4o n'identifient correctement que 60 à 80 % des données dans la plupart des champs. Les deux modèles ont réalisé des performances médiocres dans des tâches d’extraction de données complexes qui nécessitent une grande précision. De meilleurs résultats peuvent être obtenus en utilisant des techniques d'invite avancées telles que des invites de tir ou des invites de réflexion en chaîne.
De plus, GPT-4o est 50 à 80 % plus rapide que GPT-4 Turbo en TTFT (temps jusqu'au premier jeton), ce qui donne à GPT-4o un avantage en comparaison directe. La conclusion finale est que GPT-4o surpasse GPT-4 Turbo en raison de sa qualité supérieure et de sa latence plus faible.
2. Classification
Les tâches de classification nécessitent souvent d'extraire des caractéristiques d'informations multimodales telles que du texte et des images, puis d'effectuer une compréhension et un jugement au niveau sémantique. À ce stade, étant donné que GPT-4 Turbo est limité au traitement d’une seule modalité de texte, ses capacités de classification sont relativement limitées.
GPT-4o peut fusionner des informations multimodales pour former une représentation sémantique plus complète, montrant ainsi d'excellentes capacités de classification dans la classification de texte, la classification d'images, l'analyse des sentiments et d'autres domaines, en particulier dans certaines tâches multimodales difficiles dans la classification dynamique. scénario.
Dans nos conseils, nous fournissons des instructions claires sur le moment où les tickets clients sont clôturés et ajoutons plusieurs exemples pour aider à résoudre les cas les plus difficiles.
En exécutant l'évaluation pour vérifier si la sortie du modèle correspond aux données de vérité terrain pour 100 cas de test étiquetés, voici les résultats pertinents :
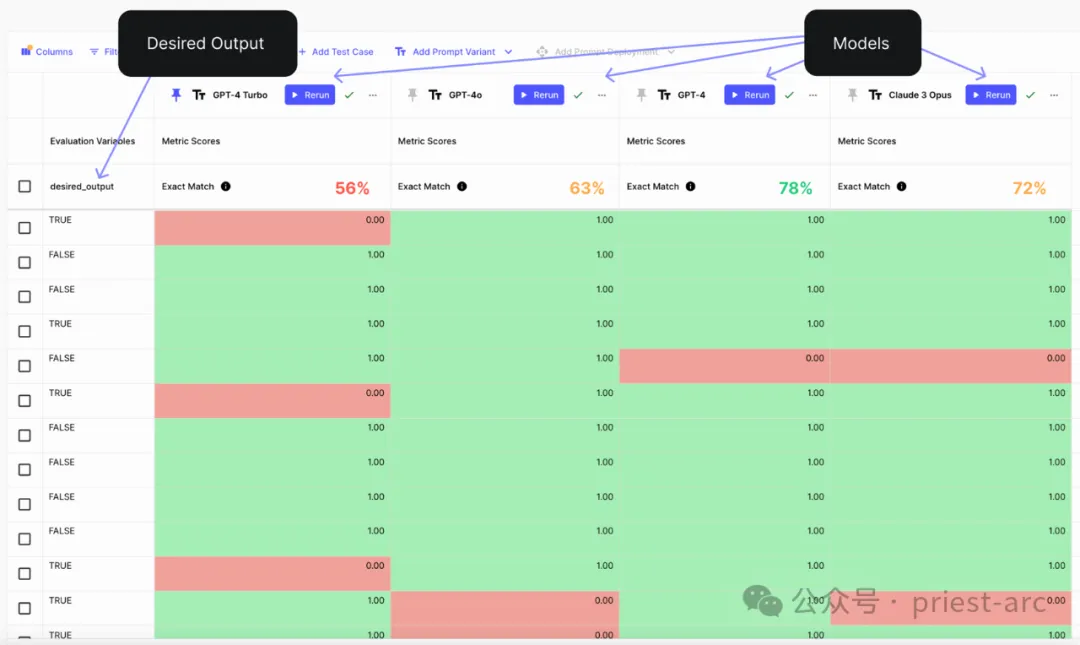
Référence d'évaluation de l'analyse de classification
GPT-4o a sans aucun doute démontré un avantage sexuel écrasant. Grâce à une série de tests et de comparaisons sur diverses tâches complexes, nous pouvons constater que le GPT-4o dépasse de loin les autres modèles concurrents en termes de précision globale, ce qui en fait le premier choix dans de nombreux domaines d'application.
Cependant, tout en nous tournant vers GPT-4o comme solution générale, nous devons également garder à l'esprit que le choix du meilleur modèle d'IA n'est pas un processus décisionnel du jour au lendemain. Après tout, les performances des modèles d’IA dépendent souvent de scénarios d’application spécifiques et de préférences de compromis pour différents indicateurs tels que la précision, le rappel et l’efficacité du temps.
3. Raisonnement
Le raisonnement est une capacité cognitive de haut niveau des systèmes d'intelligence artificielle, qui nécessite que le modèle déduise des conclusions raisonnables à partir de conditions préalables données. Ceci est crucial pour des tâches telles que le raisonnement logique et le raisonnement par questions et réponses.
GPT-4 Turbo a bien fonctionné dans les tâches de raisonnement textuel, mais ses capacités sont limitées face à des situations nécessitant une fusion d'informations multimodales.
GPT-4o n'a pas cette limitation. Il peut intégrer librement des informations sémantiques provenant de multiples modalités telles que le texte, les images et la parole, et mener un raisonnement logique, un raisonnement causal et un raisonnement inductif plus complexes sur cette base, donnant ainsi au système d'intelligence artificielle des capacités de raisonnement et de jugement plus « humanisées ». .
Toujours sur la base du scénario ci-dessus, jetons un coup d'œil à la comparaison entre les deux au niveau de l'inférence. La référence spécifique est la suivante :

Référence d'évaluation pour 16 tâches d'inférence
Selon l'exemple de test de. le modèle GPT-4o, nous pouvons observer qu'il fonctionne de mieux en mieux dans les tâches d'inférence suivantes, comme suit :
- Calculs de calendrier : GPT-4o est capable d'identifier avec précision les heures récurrentes pour des dates spécifiques, ce qui signifie qu'il peut gérer les dates- calculs et raisonnements associés.
- Calculs de temps et d'angles : GPT-4o est capable de calculer avec précision les angles sur les horloges, ce qui est très utile lorsqu'il s'agit de problèmes liés à l'horloge et aux angles.
- Vocabulaire (reconnaissance des antonymes) : GPT-4o peut identifier efficacement les antonymes et comprendre le sens des mots, ce qui est très important pour la compréhension sémantique et le raisonnement lexical.
Bien que GPT-4o s'améliore dans certaines tâches de raisonnement, il reste confronté à des défis dans des tâches telles que la manipulation de mots, la reconnaissance de formes, le raisonnement analogique et le raisonnement spatial. Des améliorations et optimisations futures pourraient améliorer encore les performances du modèle dans ces domaines.
Pour résumer, GPT-4o basé sur une limite de débit allant jusqu'à 10 millions de jetons par minute est 5 fois supérieur à celui de GPT-4. Cet indicateur de performance passionnant accélérera sans aucun doute la vulgarisation de l'intelligence artificielle dans de nombreux scénarios de calcul intensif, en particulier dans des domaines tels que l'analyse vidéo en temps réel et l'interaction vocale intelligente. La capacité de réponse à haute concurrence du GPT-4o présentera des avantages inégalés.
L'innovation la plus brillante de GPT-4o est sans aucun doute sa conception révolutionnaire qui intègre de manière transparente le texte, l'image, la voix et d'autres entrées et sorties multimodales. En intégrant et en traitant directement les données de chaque modalité via un réseau neuronal unique, GPT-4o résout fondamentalement l'expérience fragmentée du basculement entre les modèles précédents, ouvrant la voie à la création d'applications d'IA unifiées.
Après avoir réalisé la fusion modale, GPT-4o aura des perspectives sans précédent dans les scénarios d'application. Qu'il s'agisse de combiner la technologie de vision par ordinateur pour créer des outils d'analyse d'images intelligents, de s'intégrer de manière transparente aux cadres de reconnaissance vocale pour créer des assistants virtuels multimodaux, ou de générer des publicités graphiques haute fidélité basées sur la double modalité texte et image, tout ne peut être réalisé qu'en intégrant des sous-modèles indépendants Les tâches accomplies, pilotées par la grande intelligence de GPT-4o, disposeront d'une nouvelle solution unifiée et efficace.
Référence :
- [1] https://openai.com/index/hello-gpt-4o/?ref=blog.roboflow.com
- [2] https://blog.roboflow.com/gpt -4-vision/
- [3] https://www.vellum.ai/blog/analysis-gpt-4o-vs-gpt-4-turbo#task1
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1664
1664
 14
1421
52
1315
25
1266
29
1239
24
14
1421
52
1315
25
1266
29
1239
24

 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Une nouvelle ère de développement front-end VSCode : 12 assistants de code IA hautement recommandés
Jun 11, 2024 pm 07:47 PM
Une nouvelle ère de développement front-end VSCode : 12 assistants de code IA hautement recommandés
Jun 11, 2024 pm 07:47 PM
Dans le monde du développement front-end, VSCode est devenu l'outil de choix pour d'innombrables développeurs grâce à ses fonctions puissantes et son riche écosystème de plug-ins. Ces dernières années, avec le développement rapide de la technologie de l'intelligence artificielle, des assistants de code IA sur VSCode ont vu le jour, améliorant considérablement l'efficacité du codage des développeurs. Les assistants de code IA sur VSCode ont poussé comme des champignons après la pluie, améliorant considérablement l'efficacité du codage des développeurs. Il utilise la technologie de l'intelligence artificielle pour analyser intelligemment le code et fournir une complétion précise du code, une correction automatique des erreurs, une vérification grammaticale et d'autres fonctions, ce qui réduit considérablement les erreurs des développeurs et le travail manuel fastidieux pendant le processus de codage. Aujourd'hui, je recommanderai 12 assistants de code d'IA de développement frontal VSCode pour vous aider dans votre parcours de programmation.
