
 Périphériques technologiques
IA
1,5 fois au-delà de la limite de diffraction, les conditions d'imagerie sont 10 fois inférieures, l'Université Tsinghua et l'Académie chinoise des sciences utilisent des méthodes d'IA pour améliorer la résolution du microscope
Périphériques technologiques
IA
1,5 fois au-delà de la limite de diffraction, les conditions d'imagerie sont 10 fois inférieures, l'Université Tsinghua et l'Académie chinoise des sciences utilisent des méthodes d'IA pour améliorer la résolution du microscope
1,5 fois au-delà de la limite de diffraction, les conditions d'imagerie sont 10 fois inférieures, l'Université Tsinghua et l'Académie chinoise des sciences utilisent des méthodes d'IA pour améliorer la résolution du microscope

Éditeur | Radis Skin
Les méthodes informatiques de super-résolution, y compris les algorithmes d'analyse traditionnels et les modèles d'apprentissage profond, ont considérablement amélioré la microscopie optique. Parmi eux, les réseaux neuronaux profonds supervisés ont montré d'excellentes performances, mais en raison de la dynamique élevée des cellules vivantes, une grande quantité de données d'entraînement de haute qualité est nécessaire, et l'obtention de ces données est très laborieuse et peu pratique.
Dans les dernières recherches, des chercheurs de l'Université Tsinghua et de l'Académie chinoise des sciences ont développé des réseaux de déconvolution sans tir (ZS-DeconvNet) qui peuvent augmenter instantanément la résolution des images microscopiques de 1,5 fois au-delà de la limite de diffraction ci-dessus, tandis que la fluorescence est 10 fois inférieure aux conditions d'imagerie super-résolution ordinaires, est réalisée de manière non supervisée sans avoir besoin d'expériences au sol ou de collecte de données supplémentaires.
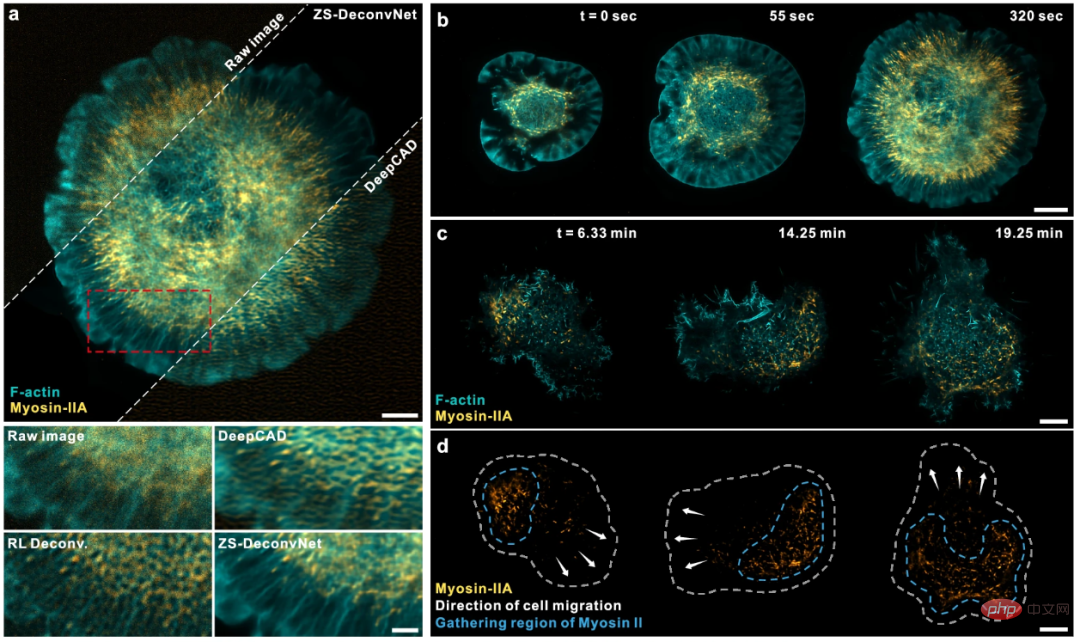
Les chercheurs ont également démontré l'applicabilité polyvalente de ZS-DeconvNet sur plusieurs modalités d'imagerie, notamment la microscopie à fluorescence par réflexion interne totale, la microscopie à grand champ 3D, la microscopie confocale, la microscopie à deux photons, la microscopie à feuille de lumière en réseau et la microscopie à éclairage structuré modal multiple. ; qui permet une imagerie 2D/3D multicolore, à long terme et en super-résolution, d'organismes embryonnaires multicellulaires, des cellules uniques mitotiques à la souris et à Caenorhabditis elegans.
La recherche s'intitulait « L'apprentissage zéro permet un débruitage instantané et une super-résolution en microscopie optique à fluorescence » et a été publiée dans « Nature Communications » le 16 mai 2024.

La microscopie optique à fluorescence est cruciale pour la recherche biologique. Les progrès de la technologie de super-résolution ont amélioré les détails de l'imagerie, mais l'amélioration de la résolution spatiale entraîne un compromis sur d'autres paramètres d'imagerie. Les méthodes informatiques de super-résolution sont devenues un point chaud de la recherche en raison de leur capacité à améliorer la qualité des images en ligne, à renforcer les capacités des équipements existants et à élargir la portée des applications.
Ces méthodes sont divisées en deux catégories : les techniques telles que la déconvolution basées sur des modèles analytiques et les réseaux super-résolution (SR) basés sur le deep learning. Le premier est limité par le réglage des paramètres et une faible adaptabilité aux environnements d’imagerie complexes. Le second peut apprendre des transformations d’images complexes grâce au Big Data, mais est confronté à des défis tels que des difficultés d’acquisition et une forte dépendance à l’égard de la qualité des données de formation. Cela limite la popularité de la technologie d’apprentissage profond à super-résolution dans les applications quotidiennes de la recherche biologique.
Ici, une équipe de recherche de l'Université Tsinghua et de l'Académie chinoise des sciences a proposé un cadre de réseau neuronal profond à déconvolution zéro, ZS-DeconvNet, capable d'entraîner de manière non supervisée des réseaux DLSR en utilisant uniquement une faible résolution et un faible signal vers. -rapport de bruit Une pile d'images planaires ou d'images volumétriques, permettant une mise en œuvre sans prise de vue.
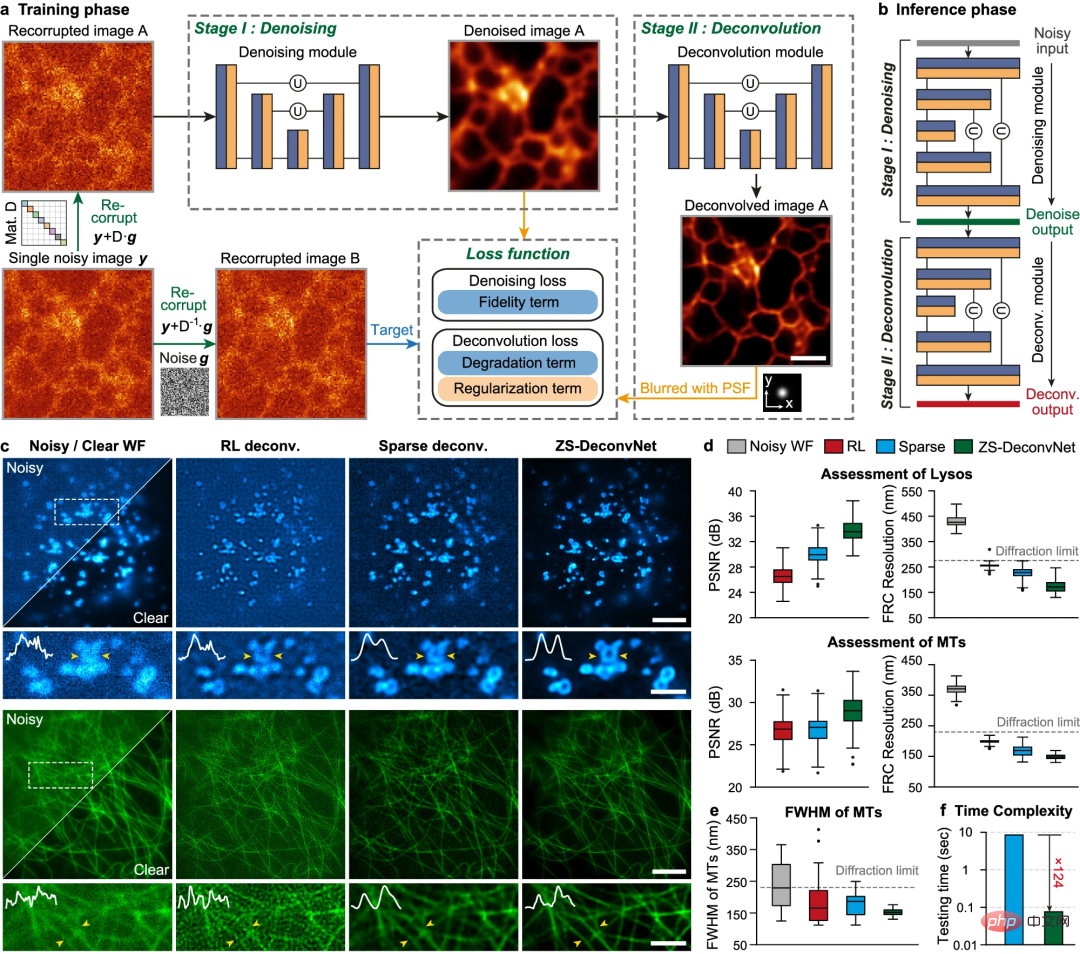
Ainsi, par rapport aux méthodes DLSR de pointe, ZS-DeconvNet peut s'adapter à différents environnements d'imagerie biologique, où les processus biologiques sont trop dynamiques, trop sensibles à la lumière pour acquérir de véritables images SR, ou Les processus d'acquisition d'images sont affectés par des facteurs inconnus et non idéaux.
Les chercheurs affirment que même lorsqu'il est formé sur une seule image d'entrée à faible rapport signal/bruit, ZS-DeconvNet peut améliorer la résolution de plus de 1,5 fois au-delà de la limite de diffraction avec une haute fidélité et une quantification, et sans avoir besoin d'une image spécifique. réglage des paramètres.
ZS-DeconvNet convient à une variété de modalités d'imagerie, de la microscopie à balayage à la microscopie à détection grand champ, et a démontré ses capacités dans une variété d'échantillons et de configurations de microscope.
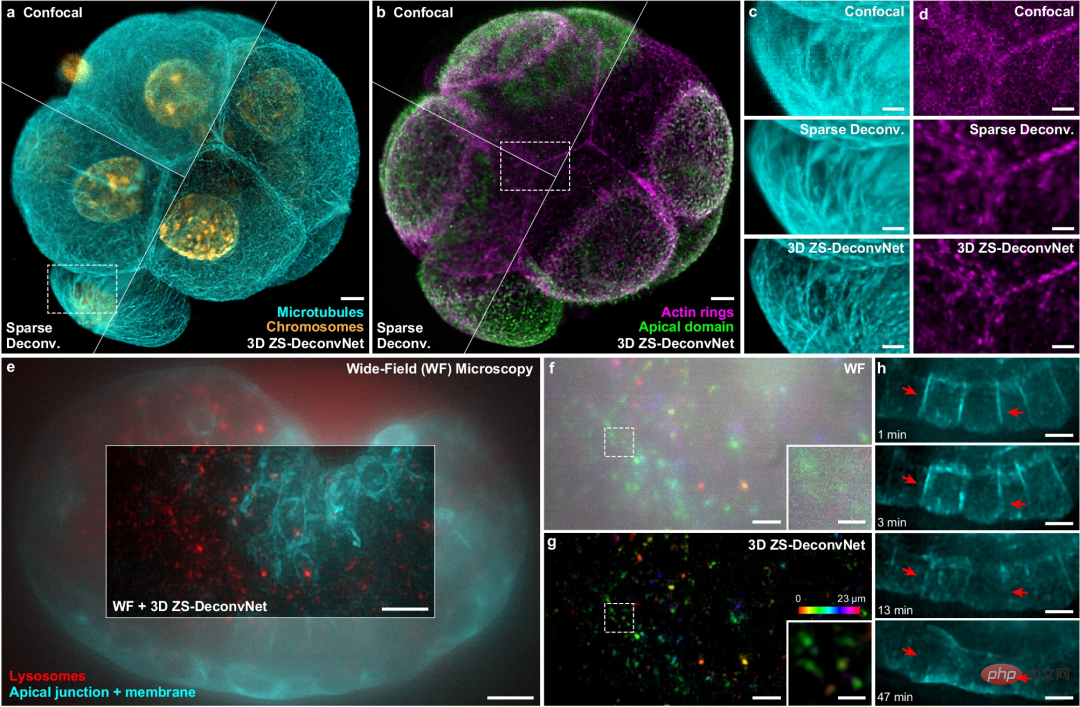
Illustration : Généralisation de ZS-DeconvNet à plusieurs modalités d'imagerie. (Source : article)
Les chercheurs démontrent que ZS-DeconvNet correctement formé peut déduire des images haute résolution sur des échelles de temps de la milliseconde, permettant un cytosquelette sensible à la lumière lors de multiples interactions d'organites, de la migration et de la mitose et de la dynamique des organites, ainsi qu'un long débit à haut débit. -imagerie SR 2D/3D des structures et de la dynamique subcellulaires dans le développement d'embryons de C. elegans et de souris.
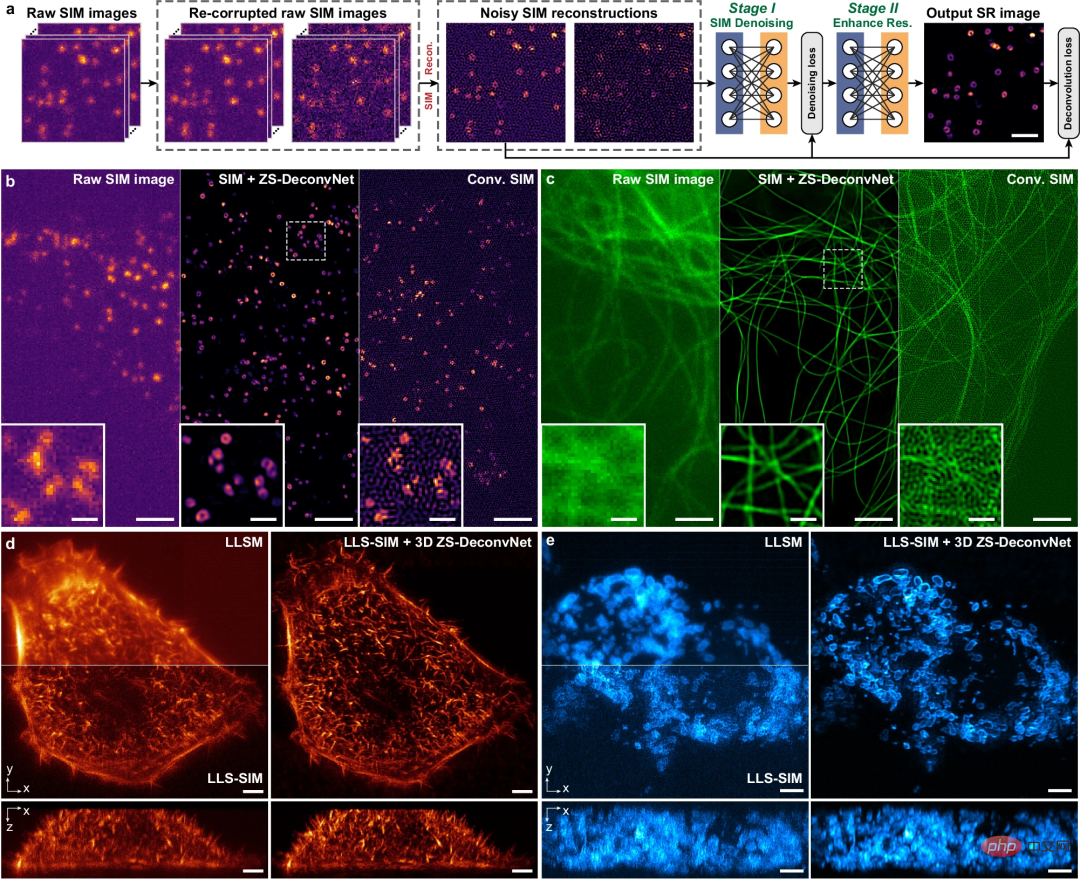
Illustration : Débruitage sans échantillon et amélioration de la résolution dans les données SIM multimodales. (Source : article)
De plus, afin que ZS-DeconvNet soit largement utilisé par la communauté de recherche en biologie, l'équipe a créé une boîte à outils de plug-ins Fidji et une page d'accueil de tutoriels sur la méthode ZS-DeconvNet, qui peuvent être facilement utilisées. par des utilisateurs sans connaissances en apprentissage profond.
Malgré sa large applicabilité et sa robustesse, il est conseillé aux utilisateurs de ZS-DeconvNet d'être conscients de la génération potentielle de fantômes et de ses limites, telles qu'une mauvaise identification des signaux à faible fluorescence, une dégradation des performances lorsqu'ils sont appliqués à des images de différents modes d'imagerie, des problèmes causés par un PSF inapproprié. correspondance, et L'amélioration de la résolution sous apprentissage non supervisé n'est pas aussi évidente que celle sous apprentissage supervisé.
À l'avenir, en combinant des architectures de réseau plus avancées, en s'étendant à d'autres technologies optiques de super-résolution, en adoptant des technologies d'adaptation ou de généralisation de domaine et en traitant des PSF spatialement variables, les fonctions et la portée d'application de ZS-DeconvNet seront encore élargies.
Lien papier : https://www.nature.com/articles/s41467-024-48575-9
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données « DefectSpectrum », qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données « DefectSpectrum » fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX À ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angströms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus tôt ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
 PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention ?
Aug 07, 2024 pm 07:08 PM
PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention ?
Aug 07, 2024 pm 07:08 PM
En 2023, presque tous les domaines de l’IA évoluent à une vitesse sans précédent. Dans le même temps, l’IA repousse constamment les limites technologiques de domaines clés tels que l’intelligence embarquée et la conduite autonome. Sous la tendance multimodale, le statut de Transformer en tant qu'architecture dominante des grands modèles d'IA sera-t-il ébranlé ? Pourquoi l'exploration de grands modèles basés sur l'architecture MoE (Mixture of Experts) est-elle devenue une nouvelle tendance dans l'industrie ? Les modèles de grande vision (LVM) peuvent-ils constituer une nouvelle avancée dans la vision générale ? ...Dans la newsletter des membres PRO 2023 de ce site publiée au cours des six derniers mois, nous avons sélectionné 10 interprétations spéciales qui fournissent une analyse approfondie des tendances technologiques et des changements industriels dans les domaines ci-dessus pour vous aider à atteindre vos objectifs dans le nouveau année. Cette interprétation provient de la Week50 2023
 AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
Editeur | Radis Skin Depuis la sortie du puissant AlphaFold2 en 2021, les scientifiques utilisent des modèles de prédiction de la structure des protéines pour cartographier diverses structures protéiques dans les cellules, découvrir des médicaments et dresser une « carte cosmique » de chaque interaction protéique connue. Tout à l'heure, Google DeepMind a publié le modèle AlphaFold3, capable d'effectuer des prédictions de structure conjointe pour des complexes comprenant des protéines, des acides nucléiques, de petites molécules, des ions et des résidus modifiés. La précision d’AlphaFold3 a été considérablement améliorée par rapport à de nombreux outils dédiés dans le passé (interaction protéine-ligand, interaction protéine-acide nucléique, prédiction anticorps-antigène). Cela montre qu’au sein d’un cadre unique et unifié d’apprentissage profond, il est possible de réaliser
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
