
 Périphériques technologiques
IA
Sélection de fonctionnalités via des stratégies d'apprentissage par renforcement
Périphériques technologiques
IA
Sélection de fonctionnalités via des stratégies d'apprentissage par renforcement
Sélection de fonctionnalités via des stratégies d'apprentissage par renforcement

La sélection des fonctionnalités est une étape clé dans le processus de création d'un modèle d'apprentissage automatique. Choisir de bonnes fonctionnalités pour le modèle et la tâche que nous voulons accomplir peut améliorer les performances.

Si nous avons affaire à des ensembles de données de grande dimension, la sélection des caractéristiques est particulièrement importante. Cela permet au modèle d’apprendre plus rapidement et mieux. L’idée est de trouver le nombre optimal de fonctionnalités et les fonctionnalités les plus significatives.
Dans cet article, nous présenterons et mettrons en œuvre une nouvelle sélection de fonctionnalités grâce à une stratégie d'apprentissage par renforcement. Nous commençons par discuter de l’apprentissage par renforcement, en particulier des processus de décision markoviens. Il s'agit d'une méthode très nouvelle dans le domaine de la science des données, particulièrement adaptée à la sélection de fonctionnalités. Ensuite, il présente son implémentation et comment installer et utiliser la bibliothèque python (FSRLearning). Enfin, un exemple simple est utilisé pour démontrer ce processus.
Apprentissage par renforcement : problème de décision de Markov pour la sélection des fonctionnalités
Les techniques d'apprentissage par renforcement (RL) peuvent être très efficaces pour résoudre des problèmes tels que la résolution de jeux. Le concept d'apprentissage par renforcement est basé sur le processus de décision de Markov (MDP). Le but ici n’est pas d’entrer dans une définition approfondie mais d’avoir une compréhension générale de son fonctionnement et de la manière dont il peut être utile pour notre problème. En apprentissage par renforcement, un agent apprend en interagissant avec son environnement. Il prend des décisions en observant l'état actuel et les signaux de récompense, et recevra des commentaires positifs ou négatifs en fonction de l'action choisie. L'objectif de l'agent est de maximiser la récompense cumulée en essayant différentes actions. Un concept important de l'apprentissage par renforcement
L'idée derrière l'apprentissage par renforcement est que l'agent part d'un environnement inconnu. Opérations de recherche pour terminer la mission. L’agent sera plus enclin à choisir certaines actions sous l’influence de son état actuel et des actions précédemment sélectionnées. Chaque fois qu’un nouvel état est atteint et qu’une action est entreprise, l’agent reçoit une récompense. Voici les principaux paramètres que nous devons définir pour la sélection des fonctionnalités :
État, action, récompense, comment choisir l'action
Tout d'abord, le sous-ensemble de fonctionnalités présentes dans l'ensemble de données. Par exemple, si l'ensemble de données comporte trois caractéristiques (âge, sexe, taille) plus une étiquette, les états possibles sont les suivants :
[] --> Empty set [Age], [Gender], [Height] --> 1-feature set [Age, Gender], [Gender, Height], [Age, Height] --> 2-feature set [Age, Gender, Height] --> All-feature set
Dans un état, l'ordre des caractéristiques n'a pas d'importance, il faut regarder faites-en une collection, pas une liste de fonctionnalités.
Concernant les actions, on peut passer d'un sous-ensemble à n'importe quel sous-ensemble de fonctionnalités inexplorées. Dans un problème de sélection de fonctionnalités, l’action consiste à sélectionner des fonctionnalités qui n’ont pas encore été explorées dans l’état actuel et à les ajouter à l’état suivant. Voici quelques actions possibles :
[Age] -> [Age, Gender] [Gender, Height] -> [Age, Gender, Height]
Voici un exemple d'action impossible :
[Age] -> [Age, Gender, Height] [Age, Gender] -> [Age] [Gender] -> [Gender, Gender]
Nous avons défini l'état et l'action, pas encore la récompense. La récompense est un nombre réel utilisé pour évaluer la qualité de l’État.
Dans les problèmes de sélection de fonctionnalités, une récompense possible est d'améliorer la métrique de précision du même modèle en ajoutant de nouvelles fonctionnalités. Voici un exemple de la façon dont la récompense est calculée :
[Age] --> Accuracy = 0.65 [Age, Gender] --> Accuracy = 0.76 Reward(Gender) = 0.76 - 0.65 = 0.11
Pour chaque état que nous visitons pour la première fois, un classificateur (modèle) est formé à l'aide d'un ensemble de fonctionnalités. Cette valeur est stockée dans l'état et le classificateur correspondant. Le processus de formation du classificateur prend du temps et est laborieux, nous ne le formons donc qu'une seule fois. Étant donné que le classificateur ne prend pas en compte l’ordre des caractéristiques, nous pouvons traiter ce problème comme un graphique plutôt que comme un arbre. Dans cet exemple, la récompense pour la sélection du « genre » comme nouvelle fonctionnalité du modèle est la différence de précision entre l’état actuel et l’état suivant.
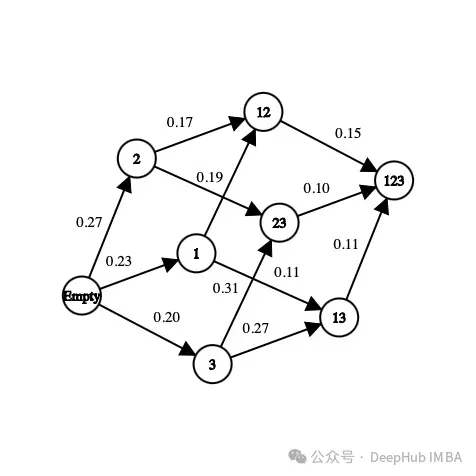
Dans l'image ci-dessus, chaque caractéristique est mappée à un nombre ("Âge" est 1, "Sexe" est 2 et "Taille" est 3). Comment choisir le prochain état à partir de l’état actuel ou comment explorer l’environnement ?
Nous devons trouver la manière optimale car si nous explorons tous les ensembles de fonctionnalités possibles dans un problème avec 10 fonctionnalités, le nombre d'états sera
10! + 2 = 3 628 802
这里的+2是因为考虑一个空状态和一个包含所有可能特征的状态。我们不可能在每个状态下都训练一个模型,这是不可能完成的,而且这只是有10个特征,如果有100个特征那基本上就是无解了。
但是在强化学习方法中,我们不需要在所有的状态下都去训练一个模型,我们要为这个问题确定一些停止条件,比如从当前状态随机选择下一个动作,概率为epsilon(介于0和1之间,通常在0.2左右),否则选择使函数最大化的动作。对于特征选择是每个特征对模型精度带来的奖励的平均值。
这里的贪心算法包含两个步骤:
1、以概率为epsilon,我们在当前状态的可能邻居中随机选择下一个状态
2、选择下一个状态,使添加到当前状态的特征对模型的精度贡献最大。为了减少时间复杂度,可以初始化了一个包含每个特征值的列表。每当选择一个特性时,此列表就会更新。使用以下公式,更新是非常理想的:
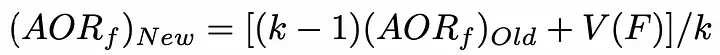
AORf:特征“f”带来的奖励的平均值
K: f被选中的次数
V(F):特征集合F的状态值(为了简单描述,本文不详细介绍)
所以我们就找出哪个特征给模型带来了最高的准确性。这就是为什么我们需要浏览不同的状态,在在许多不同的环境中评估模型特征的最全局准确值。
因为目标是最小化算法访问的状态数,所以我们访问的未访问过的状态越少,需要用不同特征集训练的模型数量就越少。因为从时间和计算能力的角度来看,训练模型以获得精度是最昂贵方法,我们要尽量减少训练的次数。
最后在任何情况下,算法都会停止在最终状态(包含所有特征的集合)而我们希望避免达到这种状态,因为用它来训练模型是最昂贵的。
上面就是我们针对于特征选择的强化学习描述,下面我们将详细介绍在python中的实现。
用于特征选择与强化学习的python库
有一个python库可以让我们直接解决这个问题。但是首先我们先准备数据
我们直接使用UCI机器学习库中的数据:
#Get the pandas DataFrame from the csv file (15 features, 690 rows) australian_data = pd.read_csv('australian_data.csv', header=None) #DataFrame with the features X = australian_data.drop(14, axis=1) #DataFrame with the labels y = australian_data[14]然后安装我们用到的库
pip install FSRLearning
直接导入
from FSRLearning import Feature_Selector_RL
Feature_Selector_RL类就可以创建一个特性选择器。我们需要以下的参数
feature_number (integer): DataFrame X中的特性数量
feature_structure (dictionary):用于图实现的字典
eps (float [0;1]):随机选择下一状态的概率,0为贪婪算法,1为随机算法
alpha (float [0;1]):控制更新速率,0表示不更新状态,1表示经常更新状态
gamma (float[0,1]):下一状态观察的调节因子,0为近视行为状态,1为远视行为
nb_iter (int):遍历图的序列数
starting_state (" empty "或" random "):如果" empty ",则算法从空状态开始,如果" random ",则算法从图中的随机状态开始
所有参数都可以机型调节,但对于大多数问题来说,迭代大约100次就可以了,而epsilon值在0.2左右通常就足够了。起始状态对于更有效地浏览图形很有用,但它非常依赖于数据集,两个值都可以测试。
我们可以用下面的代码简单地初始化选择器:
fsrl_obj = Feature_Selector_RL(feature_number=14, nb_iter=100)
与大多数ML库相同,训练算法非常简单:
results = fsrl_obj.fit_predict(X, y)
下面是输出的一个例子:
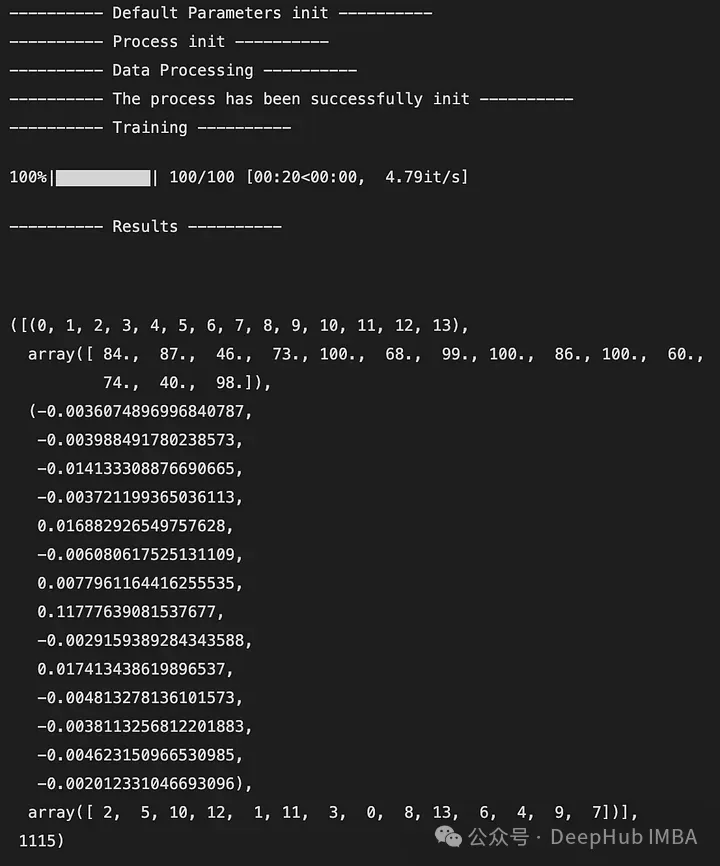
输出是一个5元组,如下所示:
DataFrame X中特性的索引(类似于映射)
特征被观察的次数
所有迭代后特征带来的奖励的平均值
从最不重要到最重要的特征排序(这里2是最不重要的特征,7是最重要的特征)
全局访问的状态数
还可以与Scikit-Learn的RFE选择器进行比较。它将X, y和选择器的结果作为输入。
fsrl_obj.compare_with_benchmark(X, y, results)
输出是在RFE和FSRLearning的全局度量的每一步选择之后的结果。它还输出模型精度的可视化比较,其中x轴表示所选特征的数量,y轴表示精度。两条水平线是每种方法的准确度中值。
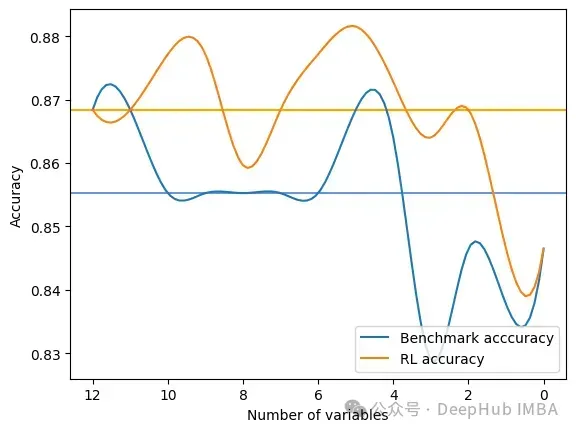
Average benchmark accuracy : 0.854251012145749, rl accuracy : 0.8674089068825909 Median benchmark accuracy : 0.8552631578947368, rl accuracy : 0.868421052631579 Probability to get a set of variable with a better metric than RFE : 1.0 Area between the two curves : 0.17105263157894512
可以看到RL方法总是为模型提供比RFE更好的特征集。
另一个有趣的方法是get_plot_ratio_exploration。它绘制了一个图,比较一个精确迭代序列中已经访问节点和访问节点的数量。
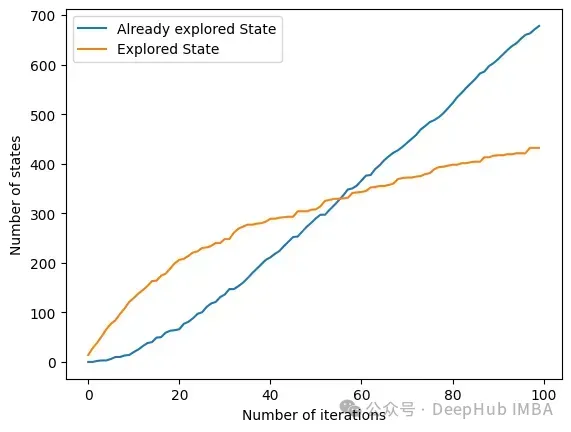
由于设置了停止条件,算法的时间复杂度呈指数级降低。即使特征的数量很大,收敛性也会很快被发现。下面的图表示一定大小的集合被访问的次数。
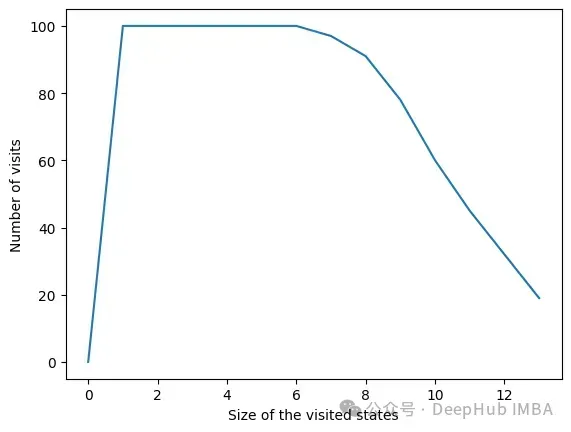
在所有迭代中,算法访问包含6个或更少变量的状态。在6个变量之外,我们可以看到达到的状态数量正在减少。这是一个很好的行为,因为用小的特征集训练模型比用大的特征集训练模型要快。
总结
我们可以看到RL方法对于最大化模型的度量是非常有效的。它总是很快地收敛到一个有趣的特性子集。该方法在使用FSRLearning库的ML项目中非常容易和快速地实现。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
L'annotation d'images est le processus consistant à associer des étiquettes ou des informations descriptives à des images pour donner une signification et une explication plus profondes au contenu de l'image. Ce processus est essentiel à l’apprentissage automatique, qui permet d’entraîner les modèles de vision à identifier plus précisément les éléments individuels des images. En ajoutant des annotations aux images, l'ordinateur peut comprendre la sémantique et le contexte derrière les images, améliorant ainsi la capacité de comprendre et d'analyser le contenu de l'image. L'annotation d'images a un large éventail d'applications, couvrant de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel et les modèles de vision graphique. Elle a un large éventail d'applications, telles que l'assistance aux véhicules pour identifier les obstacles sur la route, en aidant à la détection. et le diagnostic des maladies grâce à la reconnaissance d'images médicales. Cet article recommande principalement de meilleurs outils d'annotation d'images open source et gratuits. 1.Makesens
 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
MetaFAIR s'est associé à Harvard pour fournir un nouveau cadre de recherche permettant d'optimiser le biais de données généré lors de l'apprentissage automatique à grande échelle. On sait que la formation de grands modèles de langage prend souvent des mois et utilise des centaines, voire des milliers de GPU. En prenant comme exemple le modèle LLaMA270B, sa formation nécessite un total de 1 720 320 heures GPU. La formation de grands modèles présente des défis systémiques uniques en raison de l’ampleur et de la complexité de ces charges de travail. Récemment, de nombreuses institutions ont signalé une instabilité dans le processus de formation lors de la formation des modèles d'IA générative SOTA. Elles apparaissent généralement sous la forme de pics de pertes. Par exemple, le modèle PaLM de Google a connu jusqu'à 20 pics de pertes au cours du processus de formation. Le biais numérique est à l'origine de cette imprécision de la formation,
