
 Périphériques technologiques
IA
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Périphériques technologiques
IA
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Yolov10 : explication détaillée, déploiement et application en un seul endroit !

1. Avant-propos
Au cours des dernières années, les YOLO sont devenus le paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de son équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont exploré la conception architecturale de YOLO, les objectifs d'optimisation, les stratégies d'expansion des données, etc., et ont réalisé des progrès significatifs. Dans le même temps, le recours à la suppression non maximale (NMS) pour le post-traitement entrave le déploiement de bout en bout de YOLO et affecte négativement la latence d'inférence.
Dans les YOLO, la conception de divers composants manque d'une inspection complète et approfondie, ce qui entraîne une redondance informatique importante et limite les capacités du modèle. Il offre une efficacité sous-optimale et un potentiel d’amélioration des performances relativement important. Dans ce travail, l'objectif est d'améliorer encore les limites d'efficacité des performances de YOLO à la fois en post-traitement et en architecture de modèle. À cette fin, nous proposons d’abord une double allocation cohérente pour la formation des YOLO sans NMS, qui apporte simultanément des performances compétitives et une faible latence d’inférence. En outre, la stratégie globale de conception de modèles axée sur l’efficacité et la précision de YOLO est également présentée.
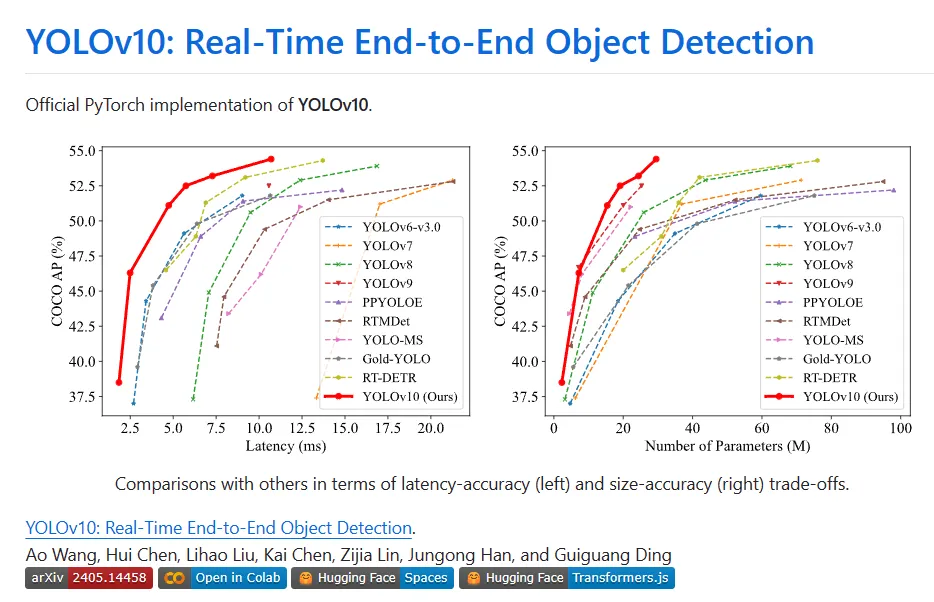
Divers composants de YOLO ont été entièrement optimisés dans les deux perspectives d'amélioration de l'efficacité et de la précision, de réduction considérablement des frais de calcul et d'amélioration des capacités. Le résultat de ces travaux est une nouvelle génération de série YOLO pour la détection de cibles de bout en bout en temps réel, appelée YOLOv10. Des expériences approfondies montrent que YOLOv10 atteint des performances et une efficacité de pointe à différentes échelles de modèle. Par exemple, sous un AP similaire sur COCO, YOLOv10-Sis1.8 est 1,8 fois plus rapide que RT-DETR-R18, et le nombre de paramètres et de FLOP partagés en même temps est 2,8 fois. Par rapport à YOLOv9-C, avec les mêmes performances, YOLOv10-B présente une réduction de 46 % de la latence et une réduction de 25 % des paramètres.
II. Contexte
La détection d'objets en temps réel a toujours été un point chaud de la recherche dans le domaine de la vision par ordinateur. Son objectif est de prédire avec précision la catégorie et l'emplacement des objets dans les images sous une faible latence. . Il est largement utilisé dans diverses applications pratiques, notamment la conduite autonome, la navigation robotisée et le suivi d’objets. Ces dernières années, les chercheurs se sont concentrés sur la conception de détecteurs d’objets basés sur CNN pour permettre une détection en temps réel. Les détecteurs d'objets en temps réel peuvent être divisés en deux catégories : les détecteurs à un étage et les détecteurs à deux étages. Les détecteurs à un étage effectuent des prédictions denses directement sur l'image d'entrée, tandis que les détecteurs à deux étages génèrent d'abord des boîtes candidates, puis effectuent une classification et une régression de localisation sur ces boîtes candidates.
Parmi eux, les YOLO deviennent de plus en plus populaires en raison de leur savant équilibre entre performance et efficacité. Le pipeline de détection de YOLO se compose de deux parties : le traitement ultérieur du modèle et le post-traitement NMS. Cependant, les deux méthodes présentent encore des défauts, ce qui se traduit par des limites de précision et de latence sous-optimales. Plus précisément, YOLO adopte généralement une stratégie d'attribution d'étiquettes un à plusieurs pendant la formation, dans laquelle un objet de mise en œuvre de base correspond à plusieurs exemples de livres. Malgré des performances supérieures, cette approche nécessite que NMS sélectionne la meilleure prédiction positive lors de l'inférence. Cela ralentit l'inférence et rend les performances sensibles aux hyperparamètres de NMS, empêchant YOLO de réaliser un déploiement optimal de bout en bout. Une façon de résoudre ce problème consiste à adopter l’architecture DETR de bout en bout récemment introduite. Par exemple, RT-DETR fournit un encodeur hybride efficace et une sélection de requêtes avec une incertitude minimale, poussant DETR dans les applications en temps réel. Cependant, la complexité inhérente au déploiement du DETR entrave sa capacité à atteindre un équilibre optimal entre précision et vitesse. Une autre ligne explore la détection de bout en bout des détecteurs basés sur CNN, qui utilisent généralement une stratégie d'allocation individuelle pour supprimer les prédictions redondantes.
Cependant, ils introduisent souvent une surcharge d'inférence supplémentaire ou atteignent des performances sous-optimales. De plus, la conception de l’architecture des modèles reste un défi fondamental pour YOLO, qui a un impact significatif sur la précision et la rapidité. Pour obtenir des architectures de modèles plus efficientes et efficaces, les chercheurs ont exploré différentes stratégies de conception. Pour améliorer les capacités d'extraction de fonctionnalités, diverses unités de calcul principales sont fournies pour le backbone, notamment DarkNet, CSPNet, EfficientRep et ELAN. Pour le cou, PAN, BiC, GD, RepGFPN, etc. sont explorés pour améliorer la fusion de fonctionnalités multi-échelles. De plus, les stratégies de mise à l'échelle du modèle et les techniques de reparamétrage sont étudiées. Bien que ces efforts aient réalisé des progrès significatifs, il reste encore de la place pour un examen complet des différents composants de YOLO du point de vue de l'efficacité et de la précision. Par conséquent, la capacité qui en résulte à contraindre le modèle conduit également à des performances différentielles, laissant largement place à l’amélioration de la précision.
3. Nouvelle technologie
Double mission cohérente pour une formation sans NMS
Pendant la formation, les YOLO utilisent généralement TAL pour attribuer plusieurs échantillons positifs par instance. L'adoption de l'allocation un-à-plusieurs génère des signaux de surveillance riches qui aident à optimiser et à atteindre des performances supérieures. Cependant, YOLO doit s'appuyer sur le post-traitement NMS, ce qui entraîne une efficacité d'inférence de déploiement insatisfaisante. Alors que les travaux antérieurs explorent l'appariement biunivoque pour supprimer les prédictions redondantes, ils introduisent souvent une surcharge d'inférence supplémentaire ou produisent des performances sous-optimales. Dans ce travail, YOLO propose une stratégie de formation sans NMS avec une attribution à double étiquette et des mesures de correspondance cohérentes, permettant d'obtenir une efficacité élevée et des performances compétitives.
- Assignations à double étiquette
Contrairement aux affectations un-à-plusieurs, la correspondance un-à-un n'attribue qu'une seule prédiction à chaque vérité terrain, évitant ainsi le post-traitement par NMS . Cependant, cela entraîne une mauvaise supervision, ce qui se traduit par une précision et une vitesse de convergence sous-optimales. Heureusement, cette lacune peut être corrigée par une allocation un-à-plusieurs. Pour y parvenir, YOLO introduit une allocation double label pour combiner le meilleur des deux stratégies. Plus précisément, comme le montre la figure (a) ci-dessous.
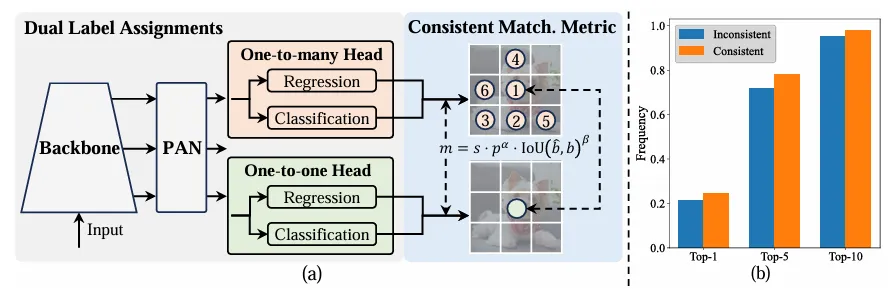
Présentation d'un autre en-tête individuel pour YOLO. Elle conserve la même structure et adopte les mêmes objectifs d'optimisation que la branche un-à-plusieurs d'origine, mais utilise une correspondance un-à-un pour obtenir des attributions d'étiquettes. Pendant le processus d'entraînement, les deux têtes sont optimisées avec le modèle, permettant à la colonne vertébrale et au cou de profiter de la riche supervision fournie par les tâches un à plusieurs. Lors de l'inférence, l'en-tête un-à-plusieurs est ignoré et l'en-tête un-à-un est utilisé pour la prédiction. Cela permet à YOLO d'être déployé de bout en bout sans encourir de coûts d'inférence supplémentaires. De plus, dans l'appariement individuel, le choix précédent est adopté, obtenant les mêmes performances que l'appariement hongrois avec moins de temps de formation supplémentaire.
- Métrique de correspondance cohérente
Pendant le processus d'allocation, les méthodes un-à-un et un-à-plusieurs utilisent une métrique pour évaluer quantitativement le niveau de cohérence entre les prédictions et les instances. Pour obtenir une correspondance basée sur la prédiction de deux branches, une métrique de correspondance unifiée est utilisée :
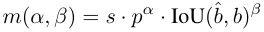
Dans l'affectation à double étiquette, les branches une-à-plusieurs fournissent des signaux de surveillance plus riches que les branches un-à-un. Intuitivement, si la supervision des en-têtes un-à-un peut être coordonnée avec la supervision des en-têtes un-à-plusieurs, les en-têtes un-à-un peuvent être optimisés dans le sens d'une optimisation des en-têtes un-à-plusieurs. Par conséquent, les têtes un à un peuvent améliorer la qualité des échantillons pendant l’inférence, ce qui se traduit par de meilleures performances. À cette fin, l’écart réglementaire entre les deux est d’abord analysé. En raison du caractère aléatoire du processus de formation, démarrer l'inspection avec deux têtes initialisées avec les mêmes valeurs et produire les mêmes prédictions, c'est-à-dire une tête un-à-un et une tête un-à-plusieurs produisent la même chose pour chaque prédit. paire d'instances p et IoU. Notez les objectifs de régression pour les deux branches.
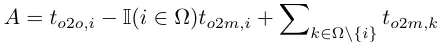
Quand to2m, i=u*, il atteint la valeur minimale, c'est-à-dire que i est le meilleur échantillon positif en Ω, comme indiqué en (a) ci-dessus. Pour y parvenir, des métriques d'appariement cohérentes sont proposées, à savoir αo2o=r·αo2m et βo2o=r·βo2m, ce qui signifie mo2o=mro2m. Par conséquent, le meilleur échantillon positif pour une tête un-à-plusieurs est également le meilleur échantillon pour une tête un-à-un. Les deux têtes peuvent ainsi être optimisées de manière cohérente et harmonieuse. Par souci de simplicité, r=1 est pris par défaut, c'est-à-dire αo2o=αo2m et βo2o=βo2m. Pour vérifier l'alignement supervisé amélioré, le nombre de paires correspondantes un à un dans le premier 1/5/10 des résultats un à plusieurs est calculé après l'entraînement. Comme le montre (b) ci-dessus, l'alignement est amélioré grâce au procédé de correspondance cohérente.
En raison de l'espace limité, une innovation majeure de YOLOv10 est l'introduction d'une stratégie d'attribution de double étiquette. L'idée principale est d'utiliser des têtes de détection une à plusieurs pour fournir plus d'échantillons positifs pendant la phase de formation afin d'enrichir le modèle. . Formation : lors de la phase d'inférence, la troncature du gradient est utilisée pour passer aux têtes de détection un-à-un. Cela élimine le besoin de post-traitement NMS, réduisant ainsi la surcharge d'inférence tout en maintenant les performances. Le principe n'est effectivement pas difficile, vous pouvez regarder le code pour comprendre :
#https://github.com/THU-MIG/yolov10/blob/main/ultralytics/nn/modules/head.pyclass v10Detect(Detect):max_det = -1def __init__(self, nc=80, ch=()):super().__init__(nc, ch)c3 = max(ch[0], min(self.nc, 100))# channelsself.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(Conv(x, x, 3, g=x), Conv(x, c3, 1)), \ nn.Sequential(Conv(c3, c3, 3, g=c3), Conv(c3, c3, 1)), \nn.Conv2d(c3, self.nc, 1)) for i, x in enumerate(ch))self.one2one_cv2 = copy.deepcopy(self.cv2)self.one2one_cv3 = copy.deepcopy(self.cv3)def forward(self, x):one2one = self.forward_feat([xi.detach() for xi in x], self.one2one_cv2, self.one2one_cv3)if not self.export:one2many = super().forward(x)if not self.training:one2one = self.inference(one2one)if not self.export:return {'one2many': one2many, 'one2one': one2one}else:assert(self.max_det != -1)boxes, scores, labels = ops.v10postprocess(one2one.permute(0, 2, 1), self.max_det, self.nc)return torch.cat([boxes, scores.unsqueeze(-1), labels.unsqueeze(-1)], dim=-1)else:return {'one2many': one2many, 'one2one': one2one}def bias_init(self):super().bias_init()'''Initialize Detect() biases, WARNING: requires stride availability.'''m = self# self.model[-1]# Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum())# nominal class frequencyfor a, b, s in zip(m.one2one_cv2, m.one2one_cv3, m.stride):# froma[-1].bias.data[:] = 1.0# boxb[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2)# cls (.01 objects, 80 classes, 640 img)Holistic Efficiency-Accuracy Driven Model Design
架构改进:
- Backbone & Neck:使用了先进的结构如 CSPNet 作为骨干网络,和 PAN 作为颈部网络,优化了特征提取和多尺度特征融合。
- 大卷积核与分区自注意力:这些技术用于增强模型从大范围上下文中学习的能力,提高检测准确性而不显著增加计算成本。
- 整体效率:引入空间-通道解耦下采样和基于秩引导的模块设计,减少计算冗余,提高整体模型效率。
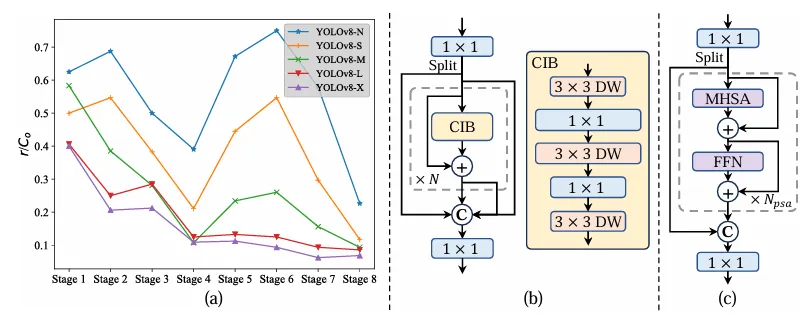
四、实验
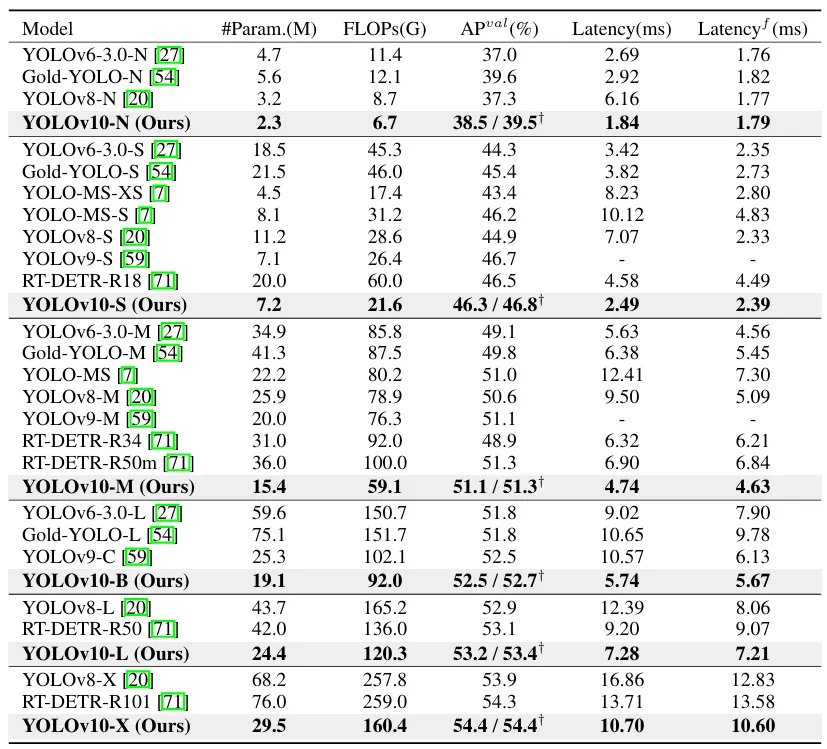
与最先进的比较。潜伏性是通过官方预训练的模型来测量的。潜在的基因测试在具有前处理的模型的前处理中保持了潜在性。†是指YOLOv10的结果,其本身对许多训练NMS来说都是如此。以下是所有结果,无需添加先进的训练技术,如知识提取或PGI或公平比较:

五、部署测试
首先,按照官方主页将环境配置好,注意这里 python 版本至少需要 3.9 及以上,torch 版本可以根据自己本地机器安装合适的版本,默认下载的是 2.0.1:
conda create -n yolov10 pythnotallow=3.9conda activate yolov10pip install -r requirements.txtpip install -e .
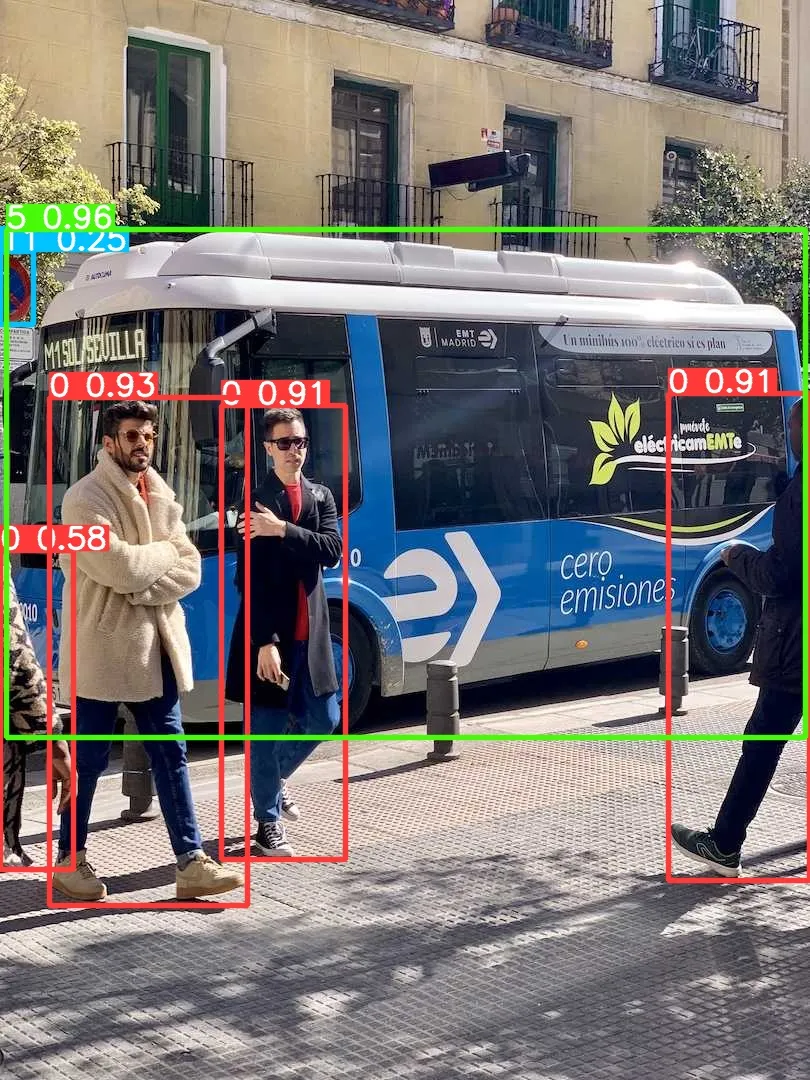
安装完成之后,我们简单执行下推理命令测试下效果:
yolo predict model=yolov10s.pt source=ultralytics/assets/bus.jpg
让我们尝试部署一下,譬如先导出个 onnx 模型出来看看:
yolo export model=yolov10s.pt format=onnx opset=13 simplify
好了,接下来通过执行 pip install netron 安装个可视化工具来看看导出的节点信息:
# run python fisrtimport netronnetron.start('/path/to/yolov10s.onnx')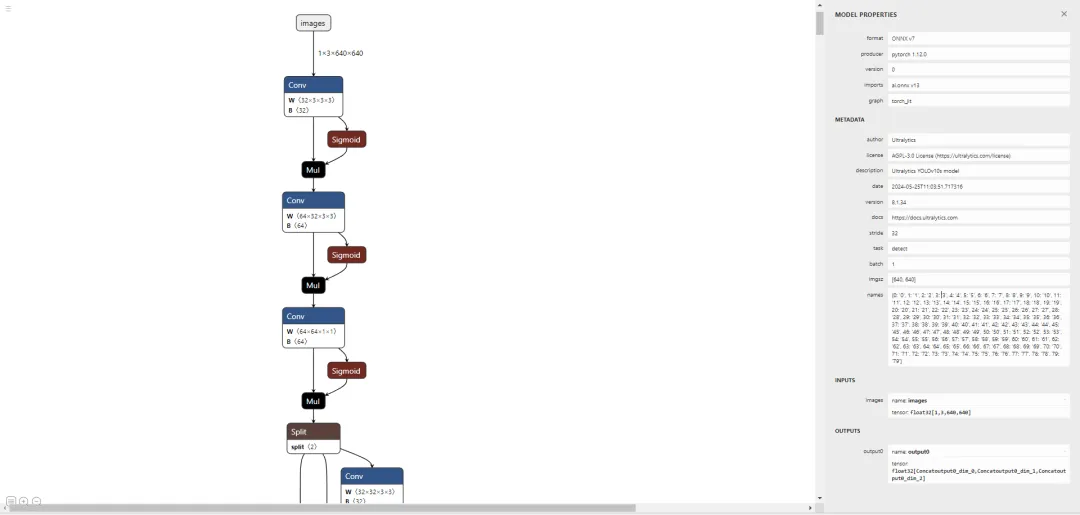
先直接通过 Ultralytics 框架预测一个测试下能否正常推理:
yolo predict model=yolov10s.onnx source=ultralytics/assets/bus.jpg

大家可以对比下上面的运行结果,可以看出 performance 是有些许的下降。问题不大,让我们基于 onnxruntime 写一个简单的推理脚本,代码地址如下,有兴趣的可以自行查看:
# 推理脚本https://github.com/CVHub520/X-AnyLabeling/blob/main/tools/export_yolov10_onnx.py# onnx 模型权重https://github.com/CVHub520/X-AnyLabeling/releases/tag/v2.3.6

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
