
 Périphériques technologiques
IA
Pratique de démarrage à froid des ressources recommandée par Baidu
Périphériques technologiques
IA
Pratique de démarrage à froid des ressources recommandée par Baidu
Pratique de démarrage à froid des ressources recommandée par Baidu

1. Concept et défis du démarrage à froid du contenu

Baidu Feed Recommendation est une plate-forme complète de recommandation de flux d'informations avec des centaines de millions d'utilisateurs par mois. La plateforme couvre une variété de types de contenu tels que des graphiques, des vidéos, des mises à jour, des mini-programmes, des questions-réponses, etc. Il fournit non seulement des recommandations clic-clic similaires aux colonnes simples ou doubles, mais comprend également diverses formes de recommandation telles que l'immersion vidéo. Dans le même temps, le système de recommandation est un système multipartite qui n’inclut pas seulement l’expérience utilisateur côté C. Les producteurs de contenu jouent un rôle important dans le système de recommandation. Baidu Feed compte un grand nombre de praticiens actifs, produisant des quantités massives de contenu chaque jour.
L'essence du système de recommandation de la plateforme de contenu est de parvenir à une situation gagnant-gagnant pour toutes les parties. Du côté des utilisateurs : la plateforme doit continuer à recommander des contenus de haute qualité, frais et diversifiés aux utilisateurs, et en attirer davantage. les utilisateurs et consacrent plus de temps ; Du côté de l'auteur : Les incitations positives des utilisateurs encouragent les auteurs à produire davantage de contenu de haute qualité. Au contraire, si le contenu frais et de haute qualité publié par l'auteur ne bénéficie pas d'une exposition rapide et suffisante. , l'auteur choisira de quitter la plateforme, ce qui n'est pas propice au développement durable. Sur la base de la discussion ci-dessus, plusieurs mots-clés peuvent être extraits : fraîcheur, haute qualité, variété, publication par l'auteur et rétention. Ceci est étroitement lié à ce dont parlera cet article, le démarrage à froid. Tout d'abord, davantage de ressources devraient pouvoir obtenir un affichage suffisant, et en collectant davantage de commentaires sur le contenu, la quantité de contenu pouvant être recommandée par le système peut être augmentée, augmentant ainsi la diversité des ressources de consommation des utilisateurs. Deuxièmement, de nouvelles ressources peuvent être créées. être produit rapidement pour augmenter le nombre d'utilisateurs. La fraîcheur du contenu déterminera à son tour la durée du marché, le DAU et le CTR du côté de l'auteur, cela augmentera le nombre d'auteurs actifs et la quantité de contenu publié en stimulant le ; l'enthousiasme de l'auteur.

Il existe certaines différences entre le démarrage à froid de nouvelles ressources et les algorithmes de recommandation réguliers. Les défis rencontrés par le démarrage à froid peuvent être résumés en trois aspects principaux : 1. Rareté des données : les nouvelles ressources ne disposent souvent pas de suffisamment de données sur le comportement des utilisateurs pour prendre en charge des recommandations personnalisées dès la phase initiale. Cela rend l'algorithme de recommandation inexact
Le premier est le défi d'une recommandation précise. Avec le développement des algorithmes de recommandation au cours de la dernière décennie, depuis la décomposition matricielle initiale jusqu'à l'application généralisée ultérieure de l'apprentissage profond, le rôle des fonctionnalités de type ID dans le modèle est progressivement devenu plus important. Cependant, comme le nombre d’échantillons de démarrage à froid de nouvelles ressources est rare ou inexistant, les fonctionnalités de type ID ne sont pas suffisamment entraînées sur les échantillons de démarrage à froid, affectant ainsi la précision des recommandations.
Deuxièmement, l'effet Matthew est courant dans les systèmes de recommandation, c'est-à-dire que les ressources qui ont été reconnues par les utilisateurs sont plus susceptibles d'être recommandées, obtenant ainsi plus de visibilité et de clics, consolidant davantage leur statut. À l’inverse, les nouvelles ressources peinent à obtenir des recommandations et peuvent même être totalement ignorées. Par conséquent, les systèmes de recommandation doivent être continuellement optimisés pour les rendre plus équitables et objectifs.
Enfin, Nous devons fournir un certain support de démarrage à froid aux nouvelles ressources, alors comment prendre en charge les nouvelles ressources plus efficacement et plus équitablement ? Cela introduit les deux concepts d'équité et d'impartialité auxquels fait référence l'équité : chaque produit de contenu peut obtenir certaines opportunités d'exposition au début du démarrage à froid et avoir une chance de rivaliser équitablement. L'équité signifie : nous devons refléter la valeur d'un contenu de haute qualité, et la qualité du contenu doit pouvoir affecter le poids du soutien de Lengqi. Par conséquent, lorsqu’il s’agit de nouvelles ressources, il est également difficile de trouver le juste équilibre entre équité et justice afin que les ressources de haute qualité puissent se démarquer et maximiser les bénéfices globaux.
2. Pratique de l'algorithme de démarrage à froid du contenu
1. Démarrage à froid basé sur le contenu

Les méthodes de rappel suivantes sont couramment utilisées pour les nouvelles ressources, en raison de l'interaction entre nouvelles ressources et utilisateurs Le nombre de fois est faible et les méthodes traditionnelles de rappel i-to-i (article à article) et u-to-i (utilisateur à article) ne sont pas applicables. Le démarrage à froid repose donc principalement sur des méthodes de recommandation de contenu. Par exemple, les méthodes de rappel direct basées sur les portraits d’utilisateurs, les balises de contenu et les classifications les plus élémentaires ont un faible degré de personnalisation et une précision de rappel relativement médiocre.
DeuxièmementAlors que de plus en plus d'auteurs disposent d'attributs personnalisés sur les principales plateformes de contenu, le démarrage à froid basé sur les relations d'attention est devenu une méthode efficace. Cependant, l'attention est relativement rare et ne peut pas satisfaire les messages de nombreux auteurs peu suivis par les fans. Nous allons donc plus loin et utilisons des algorithmes pour exploiter les fans potentiels des auteurs afin d'étendre l'influence du démarrage à froid en fonction de l'attention. Par exemple, les utilisateurs qui consomment souvent l'auteur mais ne le suivent pas, et en fonction de la composition de la relation d'attention utilisateur-auteur, calculent les relations d'attention potentielles.
De plus, le rappel multimodal est également une méthode efficace. Avec le développement de la technologie multimodale, multimodèle et grand modèle, l'intégration de diverses informations modales de contenu dans les systèmes de recommandation a des effets significatifs, en particulier dans les systèmes de recommandation à démarrage à froid. CLIP est une méthode de pré-formation basée sur la comparaison de texte et d'images. Elle comprend principalement deux modules : un encodeur de texte et un encodeur d'image. Elle mappe les informations de texte et d'image sur le même espace, offrant une meilleure aide pour les tâches en aval. Il y aura certains problèmes en utilisant directement ce vecteur pour le rappel. Ce vecteur représente les informations préalables du contenu. La similarité préalable ne signifie pas nécessairement que les utilisateurs l'apprécieront. Nous devons combiner la représentation préalable et les données comportementales apprises dans la recommandation. Des représentations postérieures sont associées.
La méthode de cartographie spécifique est basée sur la distribution d'une intégration suffisante et de ressources d'apprentissage suffisantes. Certains échantillons peuvent être collectés et utilisés comme étiquettes pour former le réseau de projection. Ce réseau de projection mappe la représentation antérieure intermodale à la représentation comportementale postérieure du système de recommandation. L'un des avantages de cette approche est que les modèles de rappel et de classement existants dans le système de recommandation peuvent être utilisés de manière transparente sans ajouter de modèles. Par exemple, pour le modèle Twin Towers, il suffit d'utiliser les vecteurs côté utilisateur existants sans apporter de modifications, puis d'utiliser le réseau de projection pour projeter les nouvelles ressources dans l'espace de représentation postérieur du modèle Twin Towers, afin que nous puissions peut simplement et rapidement Un rappel Twin Towers est en ligne. De même, le rappel graphique et le rappel arborescent existants peuvent également être mis en œuvre à faible coût.Bien sûr, cette méthode de cartographie présente un petit inconvénient, c'est-à-dire que la régression est plus difficile. Dans CB2CF, il s'agit d'un problème de régression, et la régression est généralement difficile à apprendre. Par conséquent, nous pouvons également utiliser une approche par paires pour apprendre les relations cartographiques. Plus précisément, les échantillons positifs peuvent être définis sur des paires d'éléments similaires apprises par l'élément CF. Les échantillons négatifs peuvent être obtenus par échantillonnage négatif global, etc. L'entrée comprend également certaines informations préalables et dynamiques sur l'élément, puis un tel mappage.
En utilisant les informations préalables du contenu, il est fondamentalement possible de mettre en œuvre efficacement les méthodes de rappel couramment utilisées sur le marché lors du démarrage à froid.
2. Démarrage à froid basé sur les utilisateurs de seed

Un avantage important de Lookalike est qu'il est extrêmement en temps réel. Cette méthode provient principalement du domaine de la publicité sur Internet. Dans le passé, les annonceurs sélectionnaient certains utilisateurs potentiellement intéressés comme utilisateurs de départ, puis le système recherchait des utilisateurs similaires à ces utilisateurs de départ pour se propager. Dans le système de recommandation, nous pouvons nous abonner à des journaux de streaming en ligne et en temps réel pour obtenir des commentaires positifs sur les ressources collectées lors de précédents démarrages à froid, tels que les clics, les jeux, les interactions, l'attention, etc., et même des commentaires négatifs, comme les utilisateurs qui swipent. rapidement. Ensuite, sur la base de ces utilisateurs de départ, le système peut obtenir la représentation de l'élément via l'intégration de l'utilisateur et via diverses méthodes d'agrégation ou en ajoutant des mécanismes d'auto-attention. Cette représentation peut être mise à jour très rapidement, puis diffusée vers l'extérieur sur la base de cette représentation, qui a une très grande actualité.
3. Système expérimental de démarrage à froid du contenu
1. Optimisation des fonctionnalités d'identification

Pour l'optimisation de la suppression des identifiants, en raison du petit nombre d'échantillons de ressources globaux, le modèle s'adresse facilement aux ressources principales. Par conséquent, l'apprentissage de l'identification des ressources principales est très suffisant, et l'importance des fonctionnalités dans le modèle l'est également. particulièrement élevé. Cependant, l'occurrence de ressources de démarrage à froid est moindre et l'apprentissage de l'identification est insuffisant. Il existe deux manières d’aborder ce problème : l’une consiste à éviter autant que possible d’utiliser les identifiants et l’autre est de savoir comment mieux utiliser les identifiants.
Le premier paradigme est l'optimisation des abandons, et l'une des méthodes classiques est DropoutNet. Au cours du processus de formation, DropoutNet supprimera de manière aléatoire les fonctionnalités d'ID d'élément et d'ID d'utilisateur pour maximiser l'accent mis par le modèle sur les fonctionnalités non-ID et améliorer la capacité de généralisation du modèle. Cela peut réellement améliorer l’effet de démarrage à froid des nouveaux utilisateurs ou des nouvelles ressources.
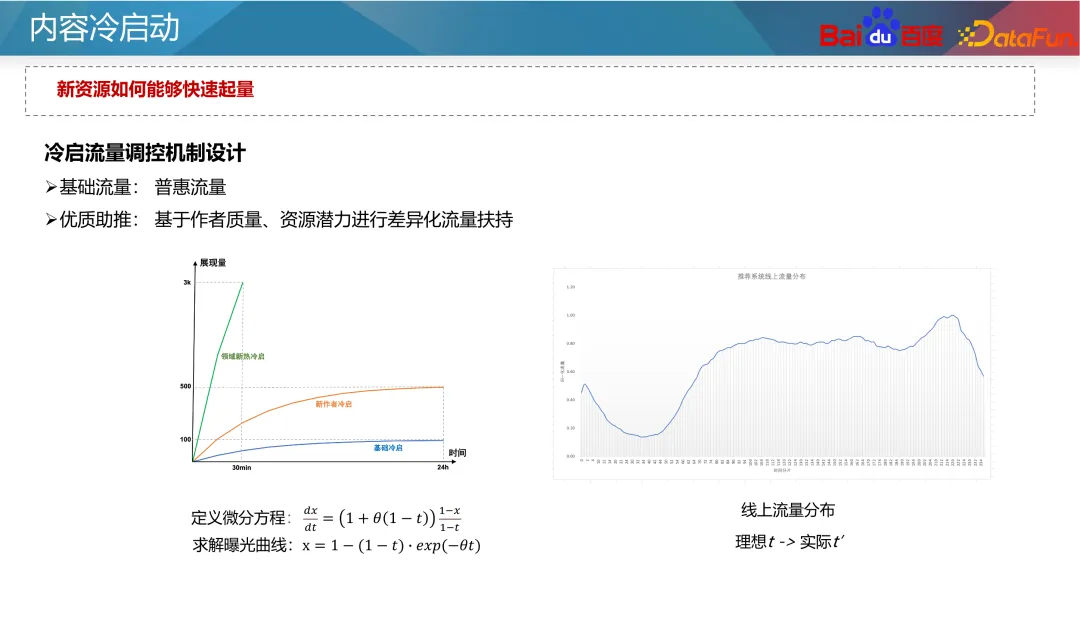
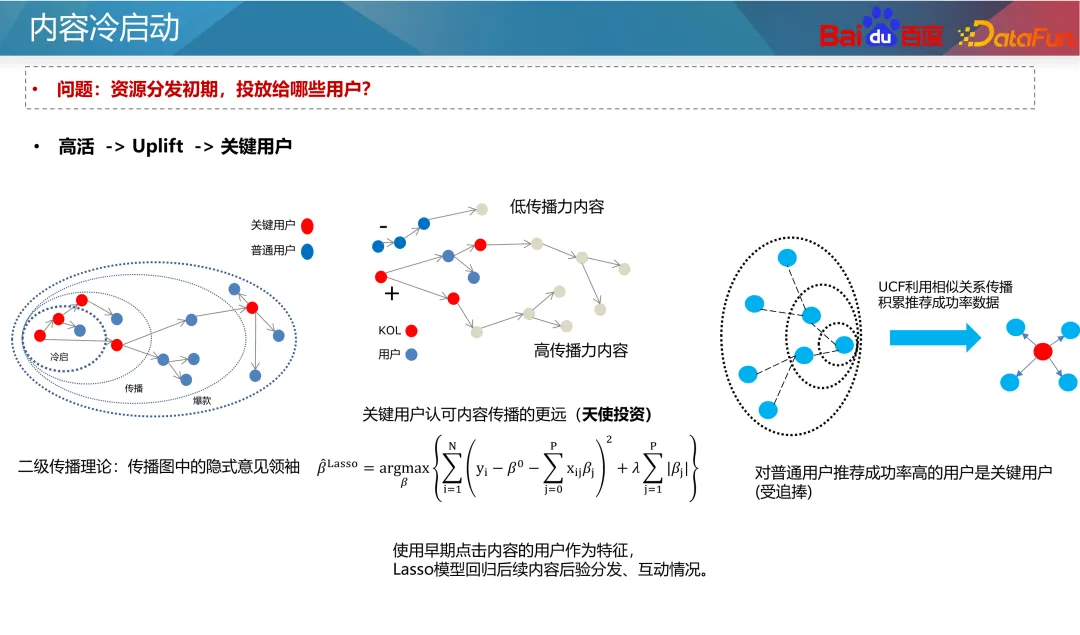
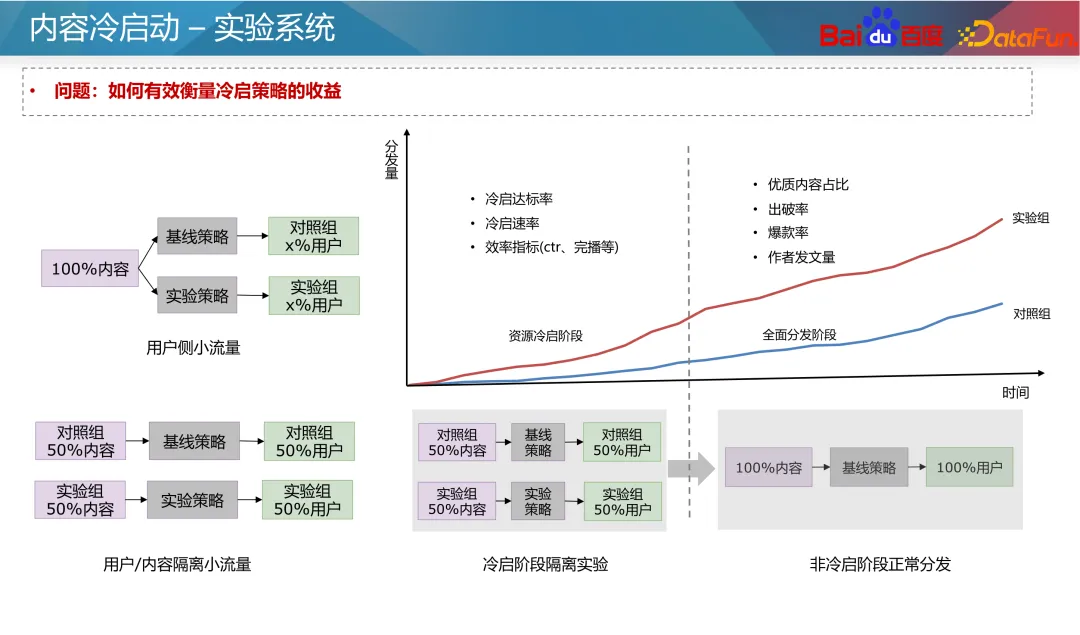
Par ailleurs, certaines méthodes d'apprentissage comparatif sont également apparues ces dernières années. L'apprentissage contrastif est une méthode d'apprentissage auto-supervisée qui ne repose pas sur l'annotation manuelle et peut construire un grand nombre d'échantillons, ce qui permet d'optimiser le problème de démarrage à froid multibande car nous pouvons construire des échantillons supplémentaires pour renforcer l'état des données de démarrage à froid. . Par exemple, dans le modèle à deux tours, une perte de contraste auxiliaire peut être ajoutée côté article. Les paramètres des deux tours sont partagés.L'utilisation d'une perte d'apprentissage contrastée peut affecter les paramètres du réseau et les fonctionnalités intégrées de la tour de ressources. Grâce à la méthode de masquage, les échantillons avec des fonctionnalités d'identification et d'autres fonctionnalités de démarrage à froid sont masqués dans des proportions différentes, prenant ainsi. en compte La capacité de généralisation du modèle et la spécificité des ressources de démarrage à froid. La prochaine étape est l'optimisation générative. Comme mentionné précédemment, les fonctionnalités d'identification peu fiables doivent être utilisées le moins possible, mais actuellement la meilleure approche consiste à les rendre plus fiables. L’idée conventionnelle est d’initialiser l’intégration de l’ID en fonction des caractéristiques antérieures de l’ID. Grâce à une initialisation raisonnable, la prédiction des nouvelles ressources peut être plus précise et converger plus rapidement. En prenant comme exemple le modèle des tours jumelles, les nouvelles fonctionnalités seront généralement initialisées de manière aléatoire ou initialisées avec des zéros, ce qui conduira à la prédiction de nouvelles ressources. Imprécis et lent à converger. Par conséquent, vous pouvez utiliser certaines fonctionnalités a priori du contenu, telles que les balises, les balises de contenu, les balises d'auteur, etc., ainsi que certains identifiants similaires (tels que les identifiants populaires), pour sélectionner certaines intégrations d'identifiants avec une valeur a posteriori et une valeur suffisamment élevées. ressources de distribution sous forme de balises, puis entraînez un générateur pour générer une intégration de l'ID pour remplacer la valeur initiale. Bien sûr, vous pouvez également faire la moyenne directe des intégrations d'ID de la nouvelle ressource et des K ressources populaires les plus similaires lors de l'initialisation de l'intégration de la nouvelle ressource. Cette méthode est relativement stable et le coût est très faible. industrie. Pour le problème selon lequel les identifiants populaires dominent le modèle et que le modèle repose davantage sur les fonctionnalités d'identification, nous pouvons utiliser des idées multitâches et multi-scénarios pour optimiser. Toujours en prenant comme exemple le modèle à deux tours, la prédiction des ressources de démarrage à froid et des ressources de démarrage non à froid peut être divisée en deux objectifs indépendants. Grâce à des modèles multi-objectifs communs, le modèle accorde davantage d’attention aux nouveaux contenus. Une approche classique est le réseau CGC, illustré à gauche dans la figure ci-dessus. Dans ce type de réseau, toutes les tâches partagent la couche d'intégration, puis les réseaux d'experts indépendants sont appris respectivement via des tâches de démarrage à froid et des tâches de démarrage non à froid pour améliorer la capacité de prédiction du démarrage à froid. Une autre méthode consiste à ajuster les pondérations des paramètres des différents types de ressources du réseau via des pondérations dynamiques, comme indiqué dans la partie droite de la figure ci-dessus. Dans ce réseau, le réseau le plus à droite est un indicateur de démarrage à froid, qui reçoit des informations sur les ressources de démarrage à froid (telles que le nombre actuel d'impressions de clics et les types de ressources), puis génère les pondérations de chaque couche du réseau pour contrôler les informations sous différents types de ressources. Le canal de transmission dans le réseau permet au modèle de prédire avec plus de précision dans des conditions de démarrage à froid. De nouvelles ressources doivent être lancées dès que possible pour améliorer l'expérience de publication de l'auteur et la mise en œuvre des recommandations, mais en raison de l'effet Matthew, nous devons donner un certain penchant pour les nouvelles ressources. L'inclinaison générale du démarrage à froid peut être divisée en deux flux : le flux de base et le flux de suralimentation. Le trafic de base est synonyme d'équité, et nous devons donner à toutes les ressources un trafic inclusif pour les tests. La stimulation du trafic offre un accompagnement différencié basé sur le potentiel estimé des ressources de qualité de l'auteur et les performances du trafic primaire. Le mécanisme de support du démarrage à froid a deux paramètres à un niveau abstrait : le temps et le volume de distribution, c'est-à-dire que grâce à l'insertion forcée, à l'ajustement de la puissance et à d'autres moyens, les ressources peuvent atteindre un objectif de volume de distribution donné dans un temps donné. Pour différentes entreprises, nous fixerons différents volumes de distribution et délais requis. Par exemple, pour les ressources ordinaires, 100 impressions peuvent suffire en 24 heures ; pour les ressources nouvelles et chaudes, cela peut être plus rapide, comme 3 000 impressions en une demi-heure. Dans le même temps, un quota de démarrage à froid plus important peut être fixé pour les nouveaux auteurs. Plus précisément en ce qui concerne la formule, t dans la formule représente la normalisation du temps de sortie actuel divisé par le temps requis pour la cible, c'est-à-dire la progression du temps actuel, et x représente la progression de la distribution actuelle. Nous voulons que t et x soient égaux, ce qui signifie une distribution à progression normale. Si x est inférieur à t, cela signifie que la vitesse actuelle de démarrage à froid est lente et qu'il faut augmenter le poids ou forcer le coefficient. θ dans la formule peut contrôler le degré d'inclinaison de l'allocation des ressources à un stade précoce. Cependant, le principe de cette formule est que le trafic du produit au cours des différentes périodes est uniforme, mais la situation réelle ne répond pas à cette hypothèse. La répartition du trafic des produits Internet généraux présente des différences entre les pics et les creux, elle doit donc être ajustée en fonction de la situation réelle. Par exemple, si un contenu est publié à 2 heures du matin, il se peut qu’il ne nécessite que 25 livraisons avant 8 heures du matin car il y a moins de trafic tôt le matin. Par conséquent, t dans la formule doit être intégré en fonction de la distribution réelle du débit. Un autre problème clé est de savoir à quels utilisateurs les ressources doivent être livrées dans les premières étapes de la distribution des ressources ? L'approche la plus courante consiste à essayer de recommander de nouvelles ressources aux anciens utilisateurs plutôt qu'aux nouveaux utilisateurs, car les anciens utilisateurs sont généralement plus tolérants et peuvent éviter des recommandations de nouvelles ressources inexactes qui pourraient nuire aux nouveaux utilisateurs. De plus, si l'amélioration des ressources de démarrage à froid est considérée comme une intervention, basée sur l'idée Uplift, l'impact de l'intervention sur la durée et la rétention des utilisateurs peut être appris, et les utilisateurs qui n'auront pas d'impact négatif sur l'intervention peuvent être sélectionnés. pour un démarrage à froid. Les deux points ci-dessus sont basés sur l'impact des utilisateurs du côté C. Cependant, la sélection des publics à démarrage froid affectera également le développement ultérieur des ressources en matière de communication. Du point de vue de la diffusion de l'information, la théorie de la communication à deux niveaux divise la diffusion de l'information en deux étapes. Tout d’abord, parmi la grande quantité d’informations générées chaque jour, certains groupes de personnes ont la capacité de filtrer et de promouvoir l’information, que nous appelons leaders d’opinion. Ensuite, les ressources amplifiées et promues par ces leaders d’opinion se diffuseront à grande échelle. À l'ère actuelle, le rôle des leaders d'opinion existe également sur les plateformes sociales, les médias connus, les chaînes de télévision, etc. Pour les systèmes de recommandation, il existe également le concept de ressources utilisateur de nœuds clés. Ils filtrent les ressources de haute qualité et font des recommandations, affectant ainsi le comportement de consommation des autres utilisateurs. Alors, comment exploiter ces utilisateurs clés ? D'après la discussion ci-dessus, les utilisateurs clés présentent deux caractéristiques : premièrement, ils ont une grande capacité à identifier la qualité des ressources, et deuxièmement, le contenu qu'ils recommandent a une forte probabilité d'être accepté par les autres utilisateurs. Il existe donc deux méthodes d'extraction : Premièrement, les ressources sont divisées en ressources de haute qualité et de mauvaise qualité en fonction de leurs conditions postérieures et utilisées comme étiquettes. Ensuite, les identifiants des utilisateurs qui ont initialement cliqué sur ces ressources sont utilisés comme caractéristiques pour prédire la situation postérieure des ressources. Le poids de chaque identifiant utilisateur appris par le modèle peut être considéré comme l'indice clé de l'utilisateur. Deuxièmement, grâce au système de recommandation de filtrage collaboratif des utilisateurs en ligne, explorez le taux de réussite des recommandations entre les utilisateurs. Les utilisateurs ayant un taux de réussite des recommandations plus élevé peuvent être considérés comme des utilisateurs clés du système de recommandation. Grâce à ces deux méthodes, les utilisateurs clés du graphique sont exploités et recommandés en premier lorsque les ressources sont démarrées à froid. Le système expérimental pour le contenu de démarrage à froid doit prêter attention à certaines fonctionnalités spéciales lors de la conception, car les échantillons du système de recommandation sont partagés, ce qui entraîne les commentaires collectés par le Le groupe expérimental sera également comparé aux apprentissages du groupe, ce qui rend difficile la mesure précise de l'effet de la stratégie de démarrage à froid. Par conséquent, nous devons mener des expériences d’isolation de contenu pour évaluer l’impact de la stratégie de démarrage à froid sur l’ensemble du système. Une conception expérimentale courante consiste à isoler complètement les utilisateurs et les ressources, comme indiqué dans la partie inférieure gauche de la figure ci-dessus. Parmi eux, 50 % des utilisateurs ne peuvent voir que 50 % du contenu, et différents groupes de ressources utilisent différentes stratégies de démarrage à froid. Cela vous permet d'évaluer l'impact de la stratégie de démarrage à froid sur l'ensemble du système. Cependant, cette méthode peut avoir un impact plus important sur l’expérience des utilisateurs du côté C, car ils ne peuvent voir qu’une partie du contenu. Une autre méthode douce consiste à isoler complètement les utilisateurs et les ressources pendant la phase de démarrage à froid, comme les 3 000 premières fois, puis à mettre en œuvre différentes stratégies de démarrage à froid pour différents groupes. Après un démarrage à froid, les ressources peuvent être distribuées à tous les utilisateurs. Une telle conception peut réduire l’impact sur l’expérience utilisateur côté C. Grâce à des expérimentations, nous pouvons analyser les indicateurs suivants : A1 : Le jugement des tours chaudes et froides repose généralement sur la répartition des ressources. De manière générale, les ressources avec des volumes de distribution inférieurs sont considérées comme des tours froides, tandis que les ressources avec des volumes de distribution plus élevés sont considérées comme des tours chaudes. Par exemple, une ressource qui a été distribuée moins de 100 fois peut être considérée comme une ressource de démarrage à froid. Bien entendu, il est nécessaire d'analyser en fonction de la précision des prévisions du modèle en ligne et de déterminer des normes de jugement spécifiques basées sur la situation réelle. A2 : L'amélioration de la qualité du trafic de démarrage à froid implique généralement une évaluation du potentiel des ressources. L’évaluation du potentiel des ressources peut combiner plusieurs sources de signaux. Par exemple, pour déterminer s'il s'agit d'un nouveau sujet d'actualité dans le domaine, vous pouvez examiner de manière exhaustive les informations de l'ensemble du réseau, y compris les informations de la liste d'actualité de chaque produit, ainsi que les discussions sur les sujets et l'attention dans des domaines connexes, etc. Pour l'évaluation de la valeur des ressources, la qualité de l'auteur peut être prise en compte, y compris des facteurs tels que sa performance dans les premières étapes et ses interactions. En utilisant globalement ces informations, une estimation plus complète du potentiel des ressources peut être réalisée. A3 : Lors de la résolution du t idéal et du t réel, cela peut être reflété en observant la courbe d'exposition. La courbe d'exposition montre l'exposition des ressources sur différentes périodes de temps. Le t idéal fait référence à la progression de l'exposition théorique calculée sur la base du temps cible défini, tandis que le t réel est déterminé sur la base de la progression de l'exposition réelle actuelle. Afin de garantir que l'exposition réelle est cohérente avec la tendance globale du marché, la proportion du trafic global doit être surveillée de manière stable afin de garantir que la progression du démarrage à froid est cohérente avec la tendance globale du trafic. Si la progression du démarrage à froid est lente, vous devrez peut-être augmenter l'exposition ou ajuster d'autres stratégies recommandées pour accélérer la progression. Si la progression est trop rapide, vous devrez peut-être ralentir la vitesse d'exposition pour éviter une surexposition des ressources. A4 : Concernant le problème du démarrage à froid, il est effectivement très difficile de mesurer avec précision la valeur exacte de l'effet. De nos jours, nous comparons généralement le groupe expérimental et le groupe témoin pour voir lequel est le meilleur. 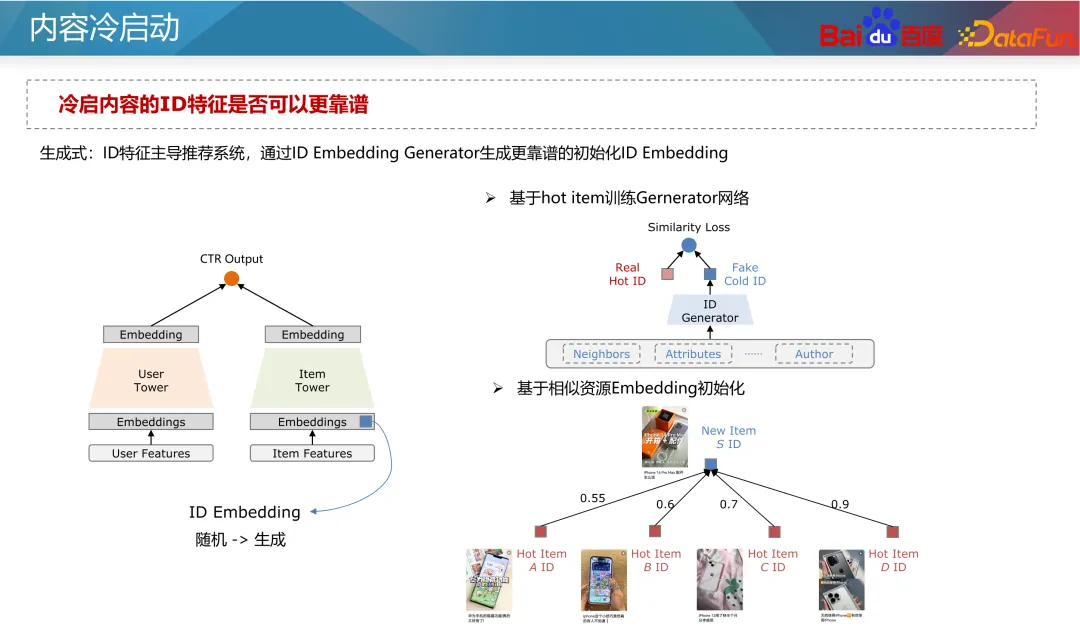
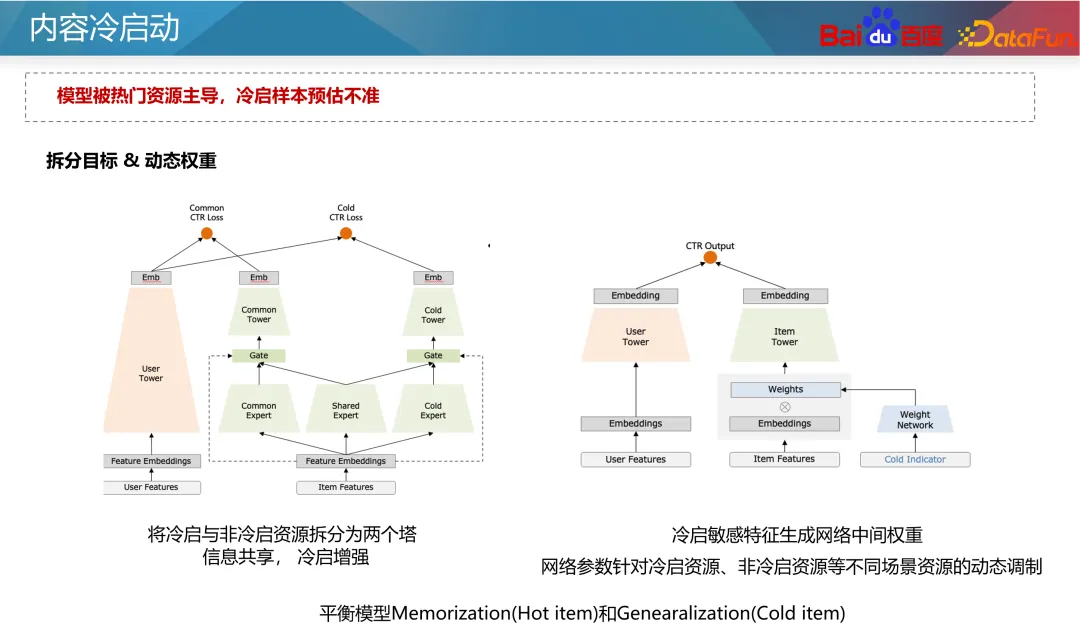
2. Conception du mécanisme de contrôle du trafic
3. Sélection des utilisateurs de livraison
4. Système expérimental
4. Q&A
Q1 : Comment juger les tours jumelles chaudes et froides ? L’une est une tour chaude et l’autre une tour froide.
Q2 : Comment juger du potentiel des ressources lorsque le trafic de démarrage à froid est boosté avec une haute qualité ? Utilisez-vous des modèles de valeur pour estimer s’il s’agit d’un nouveau sujet d’actualité dans le domaine ?
Q3 : Comment résoudre le t idéal et le t réel ? Est-ce que cela se reflète dans la courbe d’exposition ? Comment s'assurer que l'exposition réelle est cohérente avec la tendance du marché.
Q4 : Les utilisateurs ne peuvent voir que 50 % du contenu pendant l'expérience et 100 % du contenu à pleine capacité. Comment prouver que l’expérience est cohérente avec le plein effet ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Comment implémenter un système de recommandation en utilisant le langage Go et Redis
Oct 27, 2023 pm 12:54 PM
Comment implémenter un système de recommandation en utilisant le langage Go et Redis
Oct 27, 2023 pm 12:54 PM
Comment utiliser le langage Go et Redis pour mettre en œuvre un système de recommandation. Le système de recommandation est un élément important de la plate-forme Internet moderne. Il aide les utilisateurs à découvrir et à obtenir des informations intéressantes. Le langage Go et Redis sont deux outils très populaires qui peuvent jouer un rôle important dans le processus de mise en œuvre de systèmes de recommandation. Cet article expliquera comment utiliser le langage Go et Redis pour implémenter un système de recommandation simple et fournira des exemples de code spécifiques. Redis est une base de données open source en mémoire qui fournit une interface de stockage de paires clé-valeur et prend en charge une variété de données
 Exemple d'application : utilisez go-micro pour créer un système de recommandation de microservices
Jun 18, 2023 pm 12:43 PM
Exemple d'application : utilisez go-micro pour créer un système de recommandation de microservices
Jun 18, 2023 pm 12:43 PM
Avec la popularité des applications Internet, l’architecture des microservices est devenue une méthode d’architecture populaire. Parmi eux, la clé de l'architecture des microservices est de diviser l'application en différents services et de communiquer via RPC pour obtenir une architecture de services faiblement couplée. Dans cet article, nous présenterons comment utiliser go-micro pour créer un système de recommandation de microservices basé sur des cas réels. 1. Qu'est-ce qu'un système de recommandation de microservices ? Un système de recommandation de microservices est un système de recommandation basé sur une architecture de microservices qui intègre différents modules dans le système de recommandation (tels que l'ingénierie des fonctionnalités, la classification).
 Le secret d'une recommandation précise : explication détaillée du modèle de rappel impartial d'adaptation de domaine découplé d'Alibaba
Jun 05, 2023 am 08:55 AM
Le secret d'une recommandation précise : explication détaillée du modèle de rappel impartial d'adaptation de domaine découplé d'Alibaba
Jun 05, 2023 am 08:55 AM
1. Introduction au scénario Tout d’abord, introduisons le scénario impliqué dans cet article : le scénario « de bons produits sont disponibles ». Son emplacement se trouve dans la grille à quatre carrés de la page d'accueil de Taobao, qui est divisée en une page de sélection à un saut et une page d'acceptation à deux sauts. Il existe deux formes principales de pages d'hébergement, l'une est une page d'hébergement de graphiques et de textes, et l'autre est une courte page d'hébergement de vidéos. L’objectif de ce scénario est principalement de fournir aux utilisateurs des biens satisfaisants et de stimuler la croissance du GMV, exploitant ainsi davantage l’offre d’experts. 2. Qu'est-ce que le biais de popularité et pourquoi nous abordons ensuite le sujet de cet article, le biais de popularité. Qu’est-ce que le biais de popularité ? Pourquoi un biais de popularité se produit-il ? 1. Qu'est-ce que le biais de popularité ? Le biais de popularité a de nombreux alias, tels que l'effet Matthew et le cocon d'information. Intuitivement, il s'agit d'un carnaval de produits hautement explosifs. Cela entraînera
 Algorithmes et applications du système de recommandation implémentés en Java
Jun 19, 2023 am 09:06 AM
Algorithmes et applications du système de recommandation implémentés en Java
Jun 19, 2023 am 09:06 AM
Avec le développement et la vulgarisation continus de la technologie Internet, les systèmes de recommandation, en tant que technologie importante de filtrage des informations, sont de plus en plus largement utilisés et pris en compte. En termes de mise en œuvre d'algorithmes de système de recommandation, Java, en tant que langage de programmation rapide et fiable, a été largement utilisé. Cet article présentera les algorithmes et les applications du système de recommandation implémentés en Java, et se concentrera sur trois algorithmes de système de recommandation courants : l'algorithme de filtrage collaboratif basé sur l'utilisateur, l'algorithme de filtrage collaboratif basé sur les éléments et l'algorithme de recommandation basé sur le contenu. L'algorithme de filtrage collaboratif basé sur l'utilisateur est basé sur le filtrage collaboratif basé sur l'utilisateur
 Système de recommandation pour la technologie de démarrage à froid NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
Système de recommandation pour la technologie de démarrage à froid NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
1. Contexte du problème : la nécessité et l'importance de la modélisation du démarrage à froid. En tant que plate-forme de contenu, Cloud Music propose chaque jour une grande quantité de nouveaux contenus. Bien que la quantité de nouveau contenu sur la plate-forme musicale cloud soit relativement faible par rapport à d'autres plates-formes telles que les courtes vidéos, la quantité réelle peut dépasser de loin l'imagination de chacun. Dans le même temps, le contenu musical est très différent des courtes vidéos, des actualités et des recommandations de produits. Le cycle de vie de la musique s’étend sur des périodes extrêmement longues, souvent mesurées en années. Certaines chansons peuvent exploser après avoir été inactives pendant des mois ou des années, et les chansons classiques peuvent encore avoir une forte vitalité même après plus de dix ans. Par conséquent, pour le système de recommandation des plateformes musicales, il est plus important de découvrir des contenus impopulaires et de longue traîne de haute qualité et de les recommander aux bons utilisateurs que de recommander d'autres catégories.
 Comment le langage Go implémente-t-il les systèmes de recherche et de recommandation dans le cloud ?
May 16, 2023 pm 11:21 PM
Comment le langage Go implémente-t-il les systèmes de recherche et de recommandation dans le cloud ?
May 16, 2023 pm 11:21 PM
Avec le développement et la vulgarisation continus de la technologie du cloud computing, les systèmes de recherche et de recommandation dans le cloud deviennent de plus en plus populaires. En réponse à cette demande, le langage Go apporte également une bonne solution. Dans le langage Go, nous pouvons utiliser ses capacités de traitement simultané à grande vitesse et ses riches bibliothèques standard pour mettre en œuvre un système efficace de recherche et de recommandation dans le cloud. Ce qui suit présentera comment le langage Go implémente un tel système. 1. Recherche sur le cloud Tout d'abord, nous devons comprendre la posture et les principes de la recherche. La posture de recherche fait référence aux pages correspondantes du moteur de recherche en fonction des mots-clés saisis par l'utilisateur.
 Conseils sur l'utilisation du cache pour gérer les algorithmes d'optimisation du système de recommandation dans Golang.
Jun 20, 2023 pm 06:28 PM
Conseils sur l'utilisation du cache pour gérer les algorithmes d'optimisation du système de recommandation dans Golang.
Jun 20, 2023 pm 06:28 PM
Le système de recommandation est un algorithme largement utilisé dans les produits Internet et joue un rôle important dans l'amélioration de l'expérience utilisateur et l'augmentation de la valeur du produit. Dans les systèmes de recommandation, l’optimisation des algorithmes peut améliorer la précision des recommandations et la satisfaction des utilisateurs. L'utilisation de la mise en cache pour traiter l'algorithme d'optimisation du système de recommandation dans Golang peut améliorer les performances et l'efficacité. Voici quelques conseils. 1. Notions de base de la mise en cache : qu'est-ce que la mise en cache ? Le cache consiste à stocker certaines données fréquemment réutilisées dans une zone de mémoire temporaire lors de l'utilisation d'un programme ou d'une application afin que le programme puisse
 Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Jan 13, 2024 pm 12:15 PM
Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Jan 13, 2024 pm 12:15 PM
1. Contexte de la correction de cause à effet 1. Un écart se produit dans le système de recommandation. Des données sont collectées pour entraîner le modèle de recommandation à recommander les éléments appropriés aux utilisateurs. Lorsque les utilisateurs interagissent avec les éléments recommandés, les données collectées sont utilisées pour entraîner davantage le modèle, formant ainsi une boucle fermée. Cependant, il peut y avoir divers facteurs d'influence dans cette boucle fermée, entraînant des erreurs. La principale raison de l'erreur est que la plupart des données utilisées pour entraîner le modèle sont des données d'observation plutôt que des données d'entraînement idéales, qui sont affectées par des facteurs tels que la stratégie d'exposition et la sélection des utilisateurs. L’essence de ce biais réside dans la différence entre les attentes des estimations empiriques du risque et les attentes des véritables estimations du risque idéal. 2. Biais courants Il existe trois principaux types de biais courants dans les systèmes de marketing de recommandation : Biais sélectif : il est dû à la racine de l'utilisateur.
