

Appelez CLIP en boucle pour segmenter efficacement d'innombrables concepts sans formation supplémentaire.
Toute phrase comprenant des personnages de films, des monuments, des marques et des catégories générales.
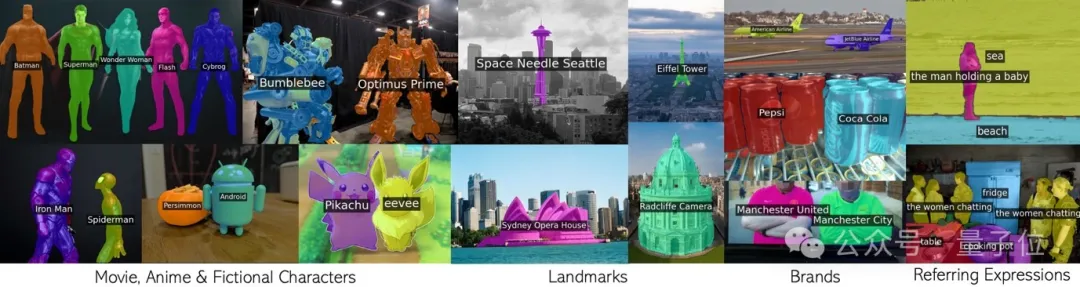
Ce nouveau résultat de l'équipe conjointe de l'Université d'Oxford et de Google Research a été accepté par le CVPR 2024 et le code est open source.

L'équipe a proposé une nouvelle technologie appelée CLIP as RNN (CaR en abrégé), qui résout plusieurs problèmes clés dans le domaine de la segmentation d'images de vocabulaire ouvert :
Pour comprendre le principe de CaR, vous devez d'abord revoir le réseau neuronal récurrent RNN .
RNN introduit le concept d'état caché, qui est comme une « mémoire » qui stocke les informations des pas de temps passés. Et chaque pas de temps partage le même ensemble de poids, ce qui permet de bien modéliser les données de séquence.
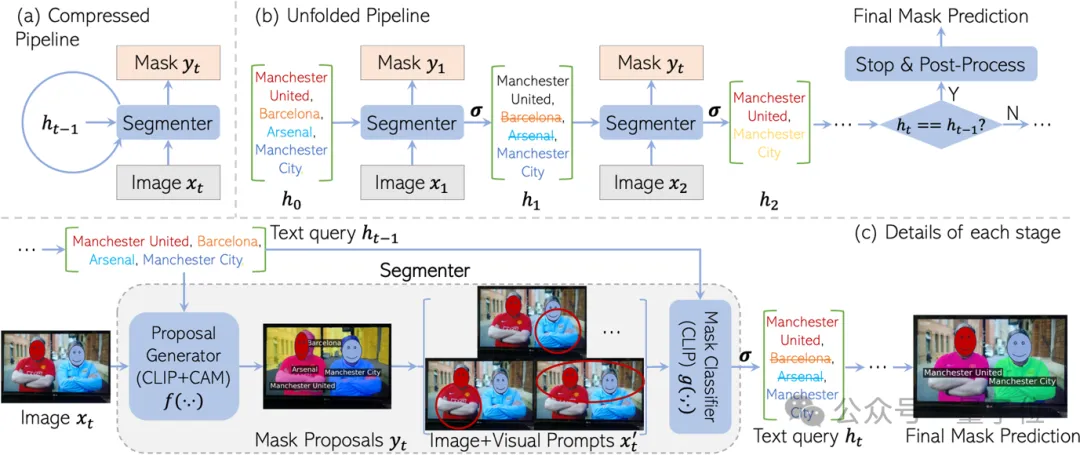
Inspiré de RNN, CaR est également conçu comme un framework cyclique, composé de deux parties :
En continuant à itérer ainsi, la requête textuelle deviendra de plus en plus précise et la qualité du masque deviendra de plus en plus élevée.
Enfin, lorsque l'ensemble de requêtes ne change plus, le résultat final de la segmentation peut être généré.

La raison pour laquelle ce framework récursif est conçu est de conserver au maximum les "connaissances" de la pré-formation CLIP.
De nombreux concepts sont abordés dans la pré-formation CLIP, couvrant tout, des célébrités aux monuments en passant par les personnages d'anime. Si vous affinez un ensemble de données fractionné, le vocabulaire est voué à diminuer considérablement.
Par exemple, le modèle SAM « diviser tout » ne peut reconnaître qu'une bouteille de Coca-Cola, mais pas même une bouteille de Pepsi-Cola.

Mais en utilisant CLIP directement pour la segmentation, l'effet n'est pas satisfaisant.
C'est parce que l'objectif de pré-entraînement de CLIP n'a pas été conçu à l'origine pour une prédiction dense. Surtout lorsque certaines requêtes de texte n'existent pas dans l'image, CLIP peut facilement générer des masques erronés.
CaR résout intelligemment ce problème grâce à une itération de style RNN. En évaluant et en filtrant à plusieurs reprises les requêtes tout en améliorant le masque, une segmentation de vocabulaire ouvert de haute qualité est enfin obtenue.
Enfin, suivons l’interprétation de l’équipe et découvrons les détails du cadre CaR.
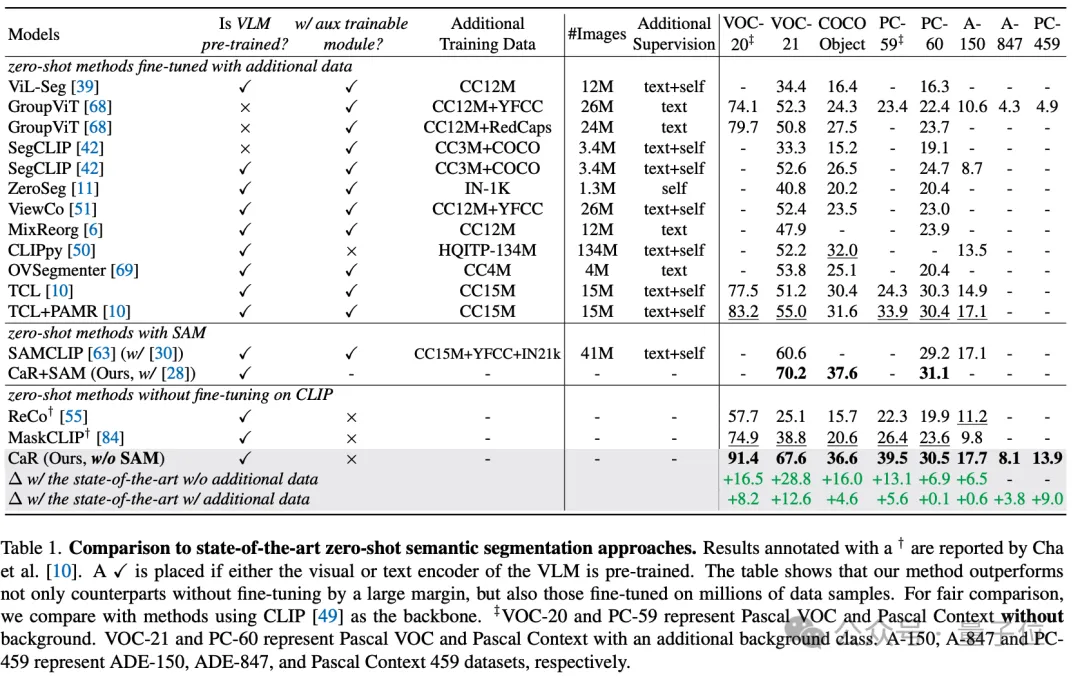
Grâce à ces moyens techniques, la technologie CaR a obtenu des améliorations significatives des performances sur plusieurs ensembles de données standard, surpassant les méthodes traditionnelles d'apprentissage sans tir, et a également démontré des performances supérieures par rapport aux modèles qui ont fait l'objet d'un ajustement approfondi des données et d'une compétitivité accrue. Comme le montre le tableau ci-dessous, bien qu'aucune formation ni ajustement supplémentaire ne soit requis, CaR affiche de meilleures performances sur huit indicateurs différents de segmentation sémantique sans tir que les méthodes précédentes affinées sur des données supplémentaires.
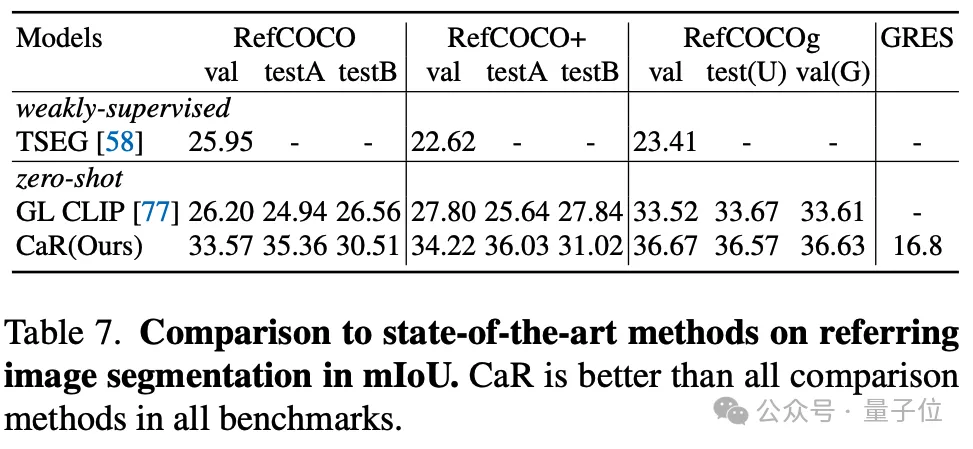
L'auteur a également testé l'effet de CaR sur la segmentation de référence à échantillon nul. CaR a également montré de meilleures performances que la méthode précédente à échantillon nul.
En résumé, CaR (CLIP as RNN) est un cadre de réseau neuronal récurrent innovant qui peut effectuer efficacement des tâches de segmentation d'images sémantiques et référentielles sans données de formation supplémentaires. Il améliore considérablement la qualité de la segmentation en préservant le large espace de vocabulaire des modèles de langage visuel pré-entraînés et en tirant parti d'un processus itératif pour optimiser en permanence l'alignement des requêtes de texte avec les propositions de masques.
Les avantages de CaR sont sa capacité à gérer des requêtes de texte complexes sans réglage fin et son évolutivité dans le domaine vidéo, apportant des progrès révolutionnaires dans le domaine de la segmentation d'images à vocabulaire ouvert.
Lien papier : https://arxiv.org/abs/2312.07661.
Page d'accueil du projet : https://torrvision.com/clip_as_rnn/.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que peuvent faire les amis de TikTok ?
Que peuvent faire les amis de TikTok ?
 Plateforme de trading de devises numériques
Plateforme de trading de devises numériques
 Introduction à la signification de += en langage C
Introduction à la signification de += en langage C
 Liste de prix du niveau Douyin 1-75
Liste de prix du niveau Douyin 1-75
 utilisation du nœud parent
utilisation du nœud parent
 Annuler le mot de passe de mise sous tension sous XP
Annuler le mot de passe de mise sous tension sous XP
 Comment couper de longues photos sur les téléphones mobiles Huawei
Comment couper de longues photos sur les téléphones mobiles Huawei
 Logiciel de création de site internet
Logiciel de création de site internet
 Comment utiliser la fonction fréquence
Comment utiliser la fonction fréquence








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



